@w460461339
2018-05-25T02:49:06.000000Z
字数 957
阅读 3810
模型修改:CRNN+ATTENTION
顺丰工作
1、现有模型
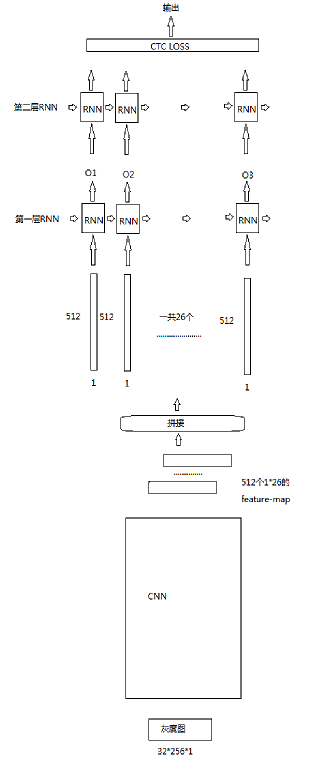
现在用来做OCR的模型是CRNN,具体参考:
https://blog.csdn.net/quincuntial/article/details/77679463
从结构上而言,它分为以下几步:
1、CNN对图片进行提取,直到feature-map的高为1.对于32*256的图片,cnn处理后,得到大小为1*26的feature-map共512个。
2、拼接feature-map,得到26个feature vector,每个vector对应每个原图中的一个小区域。
3、26*512输入一个双向LSTM,得到26个时间步的输出,每个时间步输出的size是512.
4、26*512再输入一个双向LSTM,得到26个时间步的输出,每个时间步的输出size是class数目。
5、对每个时间步的输出做softmax or CTC-LOSS(不记得了),得到最终结果。
模型
2、模型改进
attention的设计参考:
https://arxiv.org/pdf/1409.0473.pdf
https://github.com/spro/practical-pytorch/blob/master/seq2seq-translation/seq2seq-translation.ipynb
https://blog.csdn.net/mpk_no1/article/details/72862348
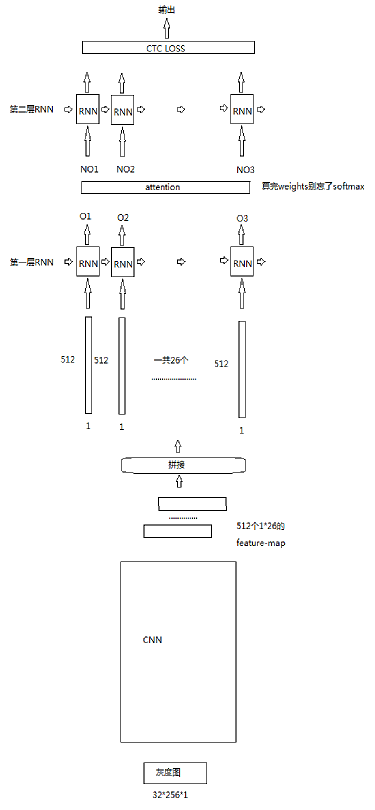
模型现在的改进主要是在两层RNN之间加了一个attention。
这里要注意,由于RNN之间并没有中间向量传播,attention模块在这里是这样设计的。
1、对于第一层RNN每个时间步的输出O1,O2...O26,计算Oi和其他所有Oj(包括自己)的距离dij,
2、这样可以得到一个26*26的距离矩阵D。
3、那么对应于第二层RNN的新的输入,有NOi=Di*[O1,O2..O26],Di表示D的第i行,也就是第Oi个向量计算出来的weights。
3、改进计划
1)呃,之前算weights的忘记加softmax了,这里记得加上。
2)现在的attention用的只是dot,尝试用其他不同的attention中weights的计算方法。
3)去了解一下self-attention的运行原理。
