@w460461339
2019-02-18T09:42:28.000000Z
字数 1774
阅读 4791
CRNN:网络结构和CTC loss
MachineLearning
CRNN是目前OCR领域比较火的一个方法,下面分网络结构和loss来分别介绍一下。
CRNN结构参考:
https://blog.csdn.net/quincuntial/article/details/77679463
CTC LOSS参考:
https://distill.pub/2017/ctc/
https://www.jianshu.com/p/34cfde8bab29
这个csdn的效果也不错
https://blog.csdn.net/left_think/article/details/76370453
这两篇知乎的讲的不错
https://zhuanlan.zhihu.com/p/27345171
https://zhuanlan.zhihu.com/p/27593978
1、模型
1)这个是理论上的模型:
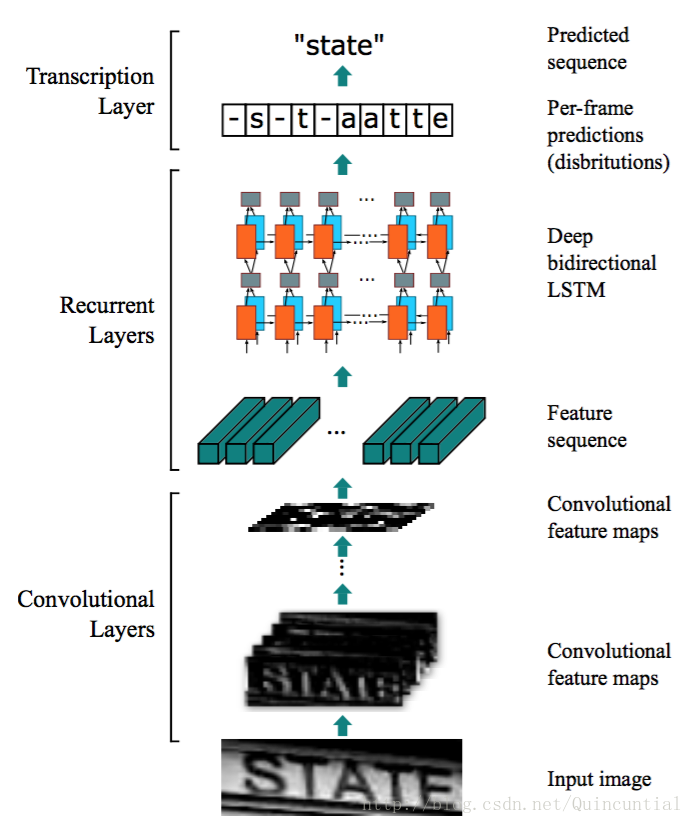
2)这个是运用到实际项目里的模型,可以看到,为了让CNN的效果拔群,这里还加入了BatchNormalization:
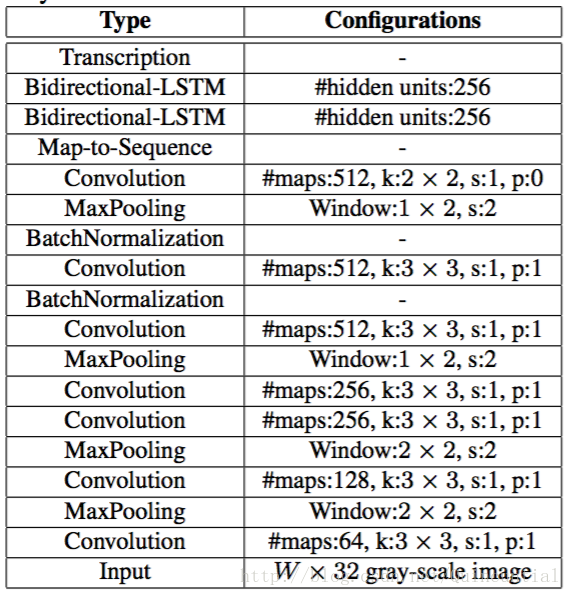
下面用语言解释一下模型:
1)CNN用来识别图像中的特征,假设一开始输入的图片是32*128*3【height*widht*channel】
2)经过若干层CNN后,我们把它压缩为:1*64*512【height*width*channel】。相当于把高给压缩没了,宽也适当的压缩。效果就是下面那个样子。
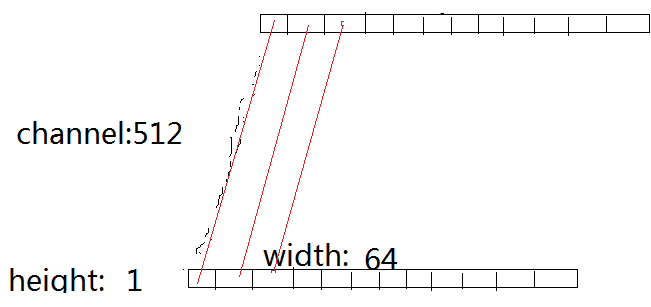
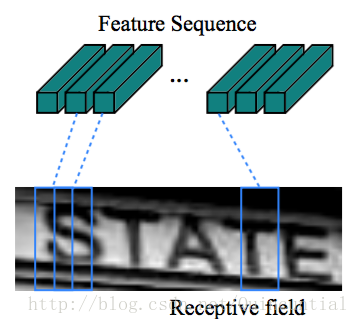
3)在那之后,我们需要把每个channel的图像链接起来,形成一个512*64的‘特征图像’,这个‘特征图像’的每一行,就只之前的每一个channel。而它的每一列,就是要输入进RNN的每一个时间步的xi.(我们称每一列为特征向量)
4)这样每一个特征向量(在我们这里是512*1),它在原图中,对应一个矩形。
5)然后通过RNN进行处理,得到输出。至于RNN的作用,我们结合后面的loss一起说。
2、CTC_LOSS
在seq2seq的模型中,无论是词级别,还是字符级别,我们都有一个假设:
target的第i位,是由某一个时间步的输出决定的;
同时,我们不存在两个时间步的输出共同决定同一个target的第i位的情况。
但是,对于OCR,或者语音问题中,我们需要观察比较大的一部分(多个特征向量对应的矩阵组合起来)或者听一段时间,才能够确定这一位。
这意味着,RNN每一个时间步的输出,不再和target一一对应。
2.1 对应问题
而CTC的第一步,就是解决这个对应问题。
1)解决输出Y和target之间的对应问题。
1、在字典中加入‘空格’这一key,我们用ϵ表示。
2、重复字符间如果没有ϵ隔开,那么就归一成一个。
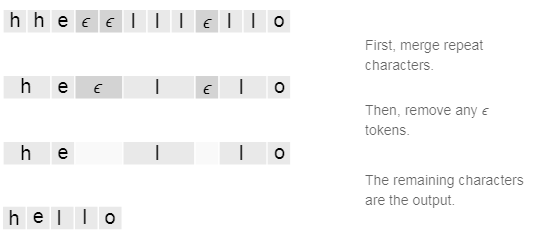
2.2 计算P(Y|X)
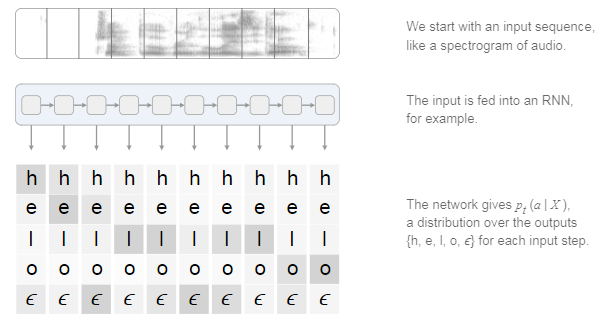
在知道了这个对应方法之后,我们有以下操作。
1)首先保证RNN的时间步长度T要大于等于target的长度L。
2)设字典长度为D,那么每个时间步的输出是一个D*1的向量,每个位置表示每个值出现的概率。(一个简单的办法就是用softmax处理)
图片中,不同的灰度表示概率的大小
3)字典长度为D,而时间步长度为T,按照遍历所有可能性的情况下,我们会有D*T个输出字符串L。但是由于之前讲的对应策略,实际上,这些D*T字符串在去掉ϵ以及合并重复字符后,会有很多相似的。

4)对于用对应策略处理过的字符串Si,我们计算它的概率,而
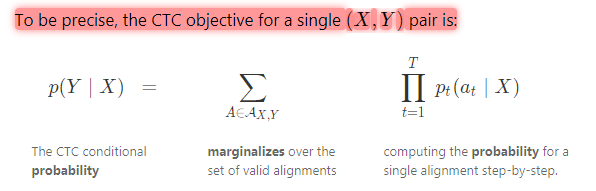
5)这样,对于每一个Si,我们都能够计算出一个P,然后就可以使用cross_entropy之类的方法处理了。

2.3 CTC LOSS计算
当我们知道如何计算Si的概率之后,我们如果粗暴的计算每个Si的概率,然后算loss的话,计算量太大了,因此就需要一个简单的方法来计算。
参考:
https://blog.csdn.net/left_think/article/details/76370453
一定好好看看楼上这篇参考
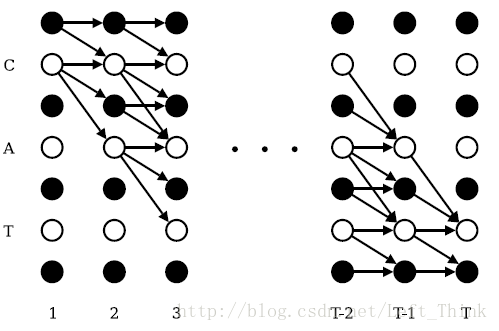
首先要对label做一个处理。即在首位和每个字符间都加上一个blank。
大概的说,我认为总体思路是这样的:
1、对于第t个时间步,它输出是oti,我们计算前面的t-1步,能够使得第t步输出oti的概率之和。
简单点说,前面t-1步有很多种可能使得第t步得到这个值,并且由于递归的效应,可以认为前面t-1步的输出,哪怕li不同,但是经过去掉blank和去重后,最后会生成相同的si。

