@w460461339
2018-11-30T07:03:32.000000Z
字数 2392
阅读 2708
通用OCR-文本检测:DMPNET,RRPN,SegLink
MachineLearning
1、DMPNET
1.1 参考
https://blog.csdn.net/Jean_0724/article/details/78011800
https://blog.csdn.net/yaoqi_isee/article/details/73432759
1.2 原理
论文里也没有说网络结构,感觉和anchors-based的网络结构不会有太大的创新点。
我猜是基于SSD的方法,来进行的改进?
主要创新点在以下几个方面:
1)更加细致的default-boxes,除了正方形长方形,还有一些平行四边形。

2)计算IOU的方法,采用撒点法来计算IOU(美其名曰:共享的蒙特卡洛方法):
(1)首先,在ground truth的外接矩形内均匀采10000个点,则ground-truth的面积为重叠点在所有点中的比例乘以外接矩形的面积。在此步骤中,为了共享计算,所有ground truth内的点都被存储下来。
(2)当滑窗的外接矩形与ground truth的外接矩形不相交时,滑窗与ground truth的重叠区域为空,不需要进行计算。当其相交时,可用(1)中的方法计算滑窗的面积,而重叠区域的面积则为重叠点在所有ground truth点中的比例乘以外接矩形(我觉得这里应该是ground truth才对)的面积。这一步可以使用GPU并行计算,可以令一个线程负责计算一个滑窗与ground truth的重叠区域,这样便可以在短时间内处理成千上万个滑窗。
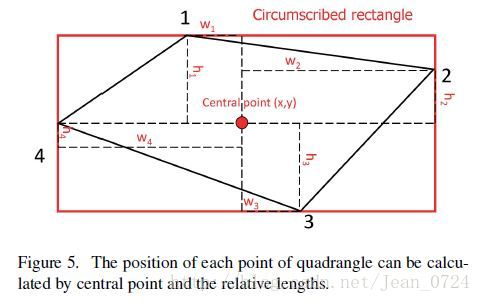
3)构造文本区域的方法不同,采用10个点来进行构造,为的是保留相对信息。
4)提出了新的损失函数:smoothLn。
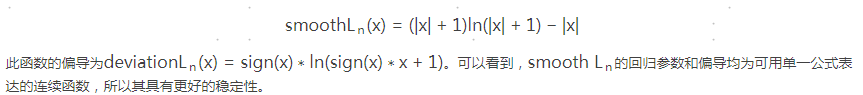
2、RRPN
2.1 参考
https://zhuanlan.zhihu.com/p/39717302
2.2 原理
1)FASTER-RCNN-based的模型。
2)对RPN网络进行修改,让其能够预测有旋转角度的区域。
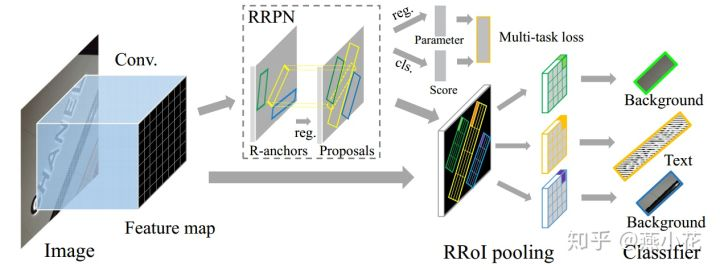
3)对RoI-pooling网络进行修改,让其可以对倾斜区域进行提取。
4)数据增广,对原始图像进行旋转来进行数据增广。
5)采用三角形剖分法来计算IoU。(感觉撒点快一些啊)
别人的总结:
1、本文基于Faster-RCNN框架的RPN的改进的,提出了RRPN,使其适应任意方向的文本行检测
2、与CTPN相比,RRPN采用的是旋转anchor,用于检测任意方向的文本行;而CTPN采用的是垂直anchor,用于检测水平方向的文本
3、与TextBoxes++相比,同样采用的是旋转矩形框实现任意方向的文本行检测,但是其表示方法不一样;对于RRPN,其旋转矩形框是用 (x,y,h,w,\theta) 表示,而TextBoxes++的旋转矩形框用 (x_1,y_1,x_2,y_2,h) 表示
3、SegLink
3.1 参考
https://zhuanlan.zhihu.com/p/37781277
思路清奇
3.2 原理
一次性定位整个文本区域有困难,那么就分块定位,然后把属于同一个文本的内容链接起来就好了。
1)这是一个SSD-based-model。
2)提取不同不同层的feature-map,不同层feature-map分别计算seg和link,然后融合。
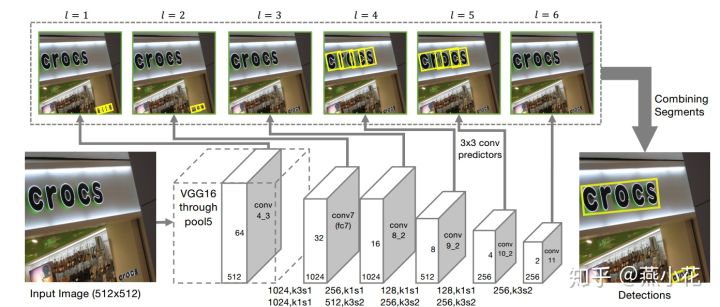
Seg预测:
3)default-box用(x,y,w,h,θ)来表示,同时,feature-map上每个中心只预测一个default-box。
4)feature-map上每个中心还会预测一个二分类,即是文字区域的概率。
link预测:
5)层内预测。预测当前中心点对应的Seg和周围8个连通域的Seg之间是否属于同一个文字区域(一样也是二分类问题。)
6)层间预测。之和自己上一层预测。比如conv5只预测和conv4之间的关系,不管conv6.
1、细节:conv4的size是conv5的size的两倍(长宽各两倍)。因此conv5上的一个点对应到conv4上是4个点。
2、那么层间link就是计算conv5上一个点预测的Seg和conv4上这4个点对应的Seg之间是否属于同一个文字区域(一样也是二分类问题)
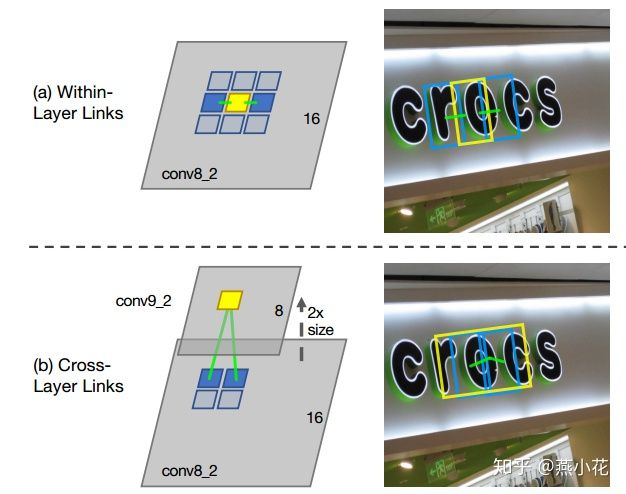
7)如何通过Link来连接Seg的。
1、首先通过人工设定的α和β(这两个值是采用网格搜索找到最优),对网络预测的segments和links进行滤除。
2、将每个segment看成node,link看成edge,建立图模型,再用DFS(depth-first-search)找到连通分量,每个连通分量包含一系列segments(用B表示),用下面的Alg1进行融合输出单词的box。
3、Alg1算法其实就是一个平均的过程.先计算所有的segment的平均θ作为文本行的θ,再根据已求的θ为已知条件,求出最可能过每个segment的直线(线段,这里线段就是以segment最左和最右的为边界),以线段中点作为word的中心点(x,y),最后用线段长度加上首尾segment的平均宽度作为word的宽度,用所有segment的高度的平均作为word的高度。
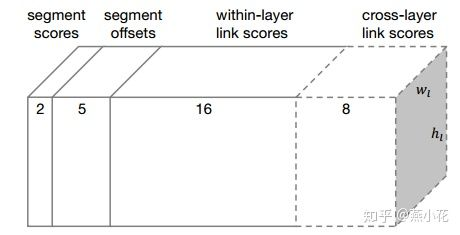
输出维度:
1、对于conv4_3:其预测输出维度为: 2+5+2\times8=23 ,因为该层没有cross-layer link
2、对于conv7, conv8_2, conv9_2, conv10_2, conv11,其预测输出维度为: 2+5+2*8+2*4=31