@w460461339
2019-04-25T13:25:52.000000Z
字数 6883
阅读 1708
Tensorflow Day7:Yolo1
Tensorflow
0、参考:
原理:https://zhuanlan.zhihu.com/p/32525231
梳理:https://zhuanlan.zhihu.com/p/37850811
本篇参考的实现:https://github.com/TowardsNorth/yolo_v1_tensorflow_guiyu
另外一个实现:https://github.com/lesliejackson/YOLOv1_tensorflow/blob/master/yolo_v1.py
我之前的笔记:https://www.zybuluo.com/w460461339/note/1172224
1、YOLOV1基本原理
参考我之前写的吧:
https://www.zybuluo.com/w460461339/note/1172224
yolo的基本原理很简单:
1、对于任何一张图,我们将其resize到448*448.(尺度比较大,容易看到更小的东西)
2、将其卷积到【7,7,20+2*(4+1)】的尺寸。
2.1 7*7表示我们将这张图划成7*7份,
2.2 每份需要提取一个长为(20+2(4+1))的向量。
其中,20表示类别概率,2表示两个bbox;4表示一个bbox的坐标;1表示一个bbox的置信度。
3、三个概念:
3.1 下图中每一个黑色的正方形框是 cell。
3.2 下图第三幅图中密密麻麻的长方形框是 bbox,预测框,每个cell有两个。
3.3 gt,ground_truth,就是label,测试时候没有的。

2、数据准备(训练)
这里比较奇怪,可能是为了简化操作吧,网络的输出是【7,7,30】,但是
1)将原始图片resize成448*448*3的图片。
2)对于每一个gt:
1、标记它在哪个cell内,那么对应的cell位置写1=》得到 【7,7,1】的向量。
2、将gt的坐标记录,得到【7,7,4】的向量。【x_center,y_center,w,h】
3、将gt的类别记录,得到【7,7,20】的向量。
20+2*(4+1)、、、、、、、、、、、、、、、、
3、YOLO网络(训练)
网络主要分为:
1、主干网络
2、loss设计
3.1 主干网络
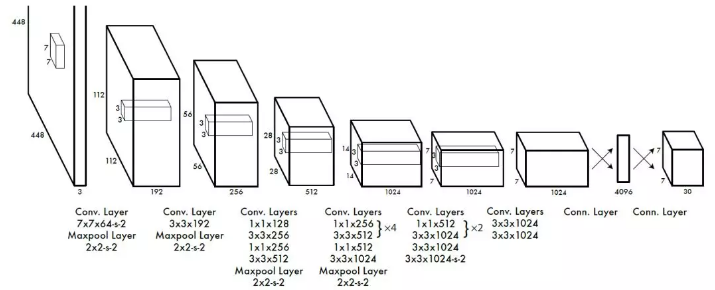
但这篇实现中和上面的有些不一样:
该实现中,最后几层都是用FC来实现的,所以最后的输出,是一个7*7*30长的向量,而不是【7,7,30】的feature-map。
def build_network(self, #用slim构建网络,简单高效images,num_outputs,alpha,keep_prob=0.5,is_training=True,scope='yolo'):with tf.variable_scope(scope):with slim.arg_scope([slim.conv2d, slim.fully_connected], #卷积层加上全连接层activation_fn=leaky_relu(alpha), #用的是leaky_relu激活函数weights_regularizer=slim.l2_regularizer(0.0005), #L2正则化,防止过拟合weights_initializer=tf.truncated_normal_initializer(0.0, 0.01) #权重初始化):net = tf.pad(images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),name='pad_1').....一大堆卷积+池化net = tf.pad(net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),name='pad_27') #padding, 第一个维度batch和第四个维度channels不用管,只padding卷积核的高度和宽度net = slim.conv2d(net, 1024, 3, 2, padding='VALID', scope='conv_28') #1024卷积核,大小3*3,步长为2net = slim.conv2d(net, 1024, 3, scope='conv_29') #1024卷积核,大小为3*3,默认步长为1net = slim.conv2d(net, 1024, 3, scope='conv_30') #1024卷积核,大小为3*3,默认步长为1net = tf.transpose(net, [0, 3, 1, 2], name='trans_31') #转置,由[batch, image_height,image_width,channels]变成[bacth, channels, image_height,image_width]net = slim.flatten(net, scope='flat_32') #将输入扁平化,但保留batch_size, 假设第一位是batch,实际上第一维也是batch'''可以看到,这里直到最后也是用FC实现的,因此输出并不是【7,7,30】的feature_map而是一个7*7*30长的向量。'''net = slim.fully_connected(net, 512, scope='fc_33') #全连接层,神经元个数net = slim.fully_connected(net, 4096, scope='fc_34') #全连接层,神经元个数net = slim.dropout( #dropout,防止过拟合net, keep_prob=keep_prob, is_training=is_training,scope='dropout_35')net = slim.fully_connected( #全连接层 输出维度是 7*7*(20+2*(4+1))net, num_outputs, activation_fn=None, scope='fc_36')return net
另外,这个Net最后一层有问题啊,好歹加一个Sigmoid作为激活函数啊…
3.2 LOSS设计
在往下看之前,我们需要明确,对于YOLOV1而言,它不像依赖anchors的网络,在训练阶段时,准备数据的时候就需要确定每个anchors的偏移量(Faster_RCNN)/由哪个anchors来负责预测(Yolo_V3)。
由于yolo_v1并不是anchors依赖的,所以只有当预测结果出来的时候,我们才知道哪个bbox负责预测。因此,在准备数据的时候,不能,也不必要,指定由哪个bbox来计算某方面的loss。

可以看到,这里主要是由4部分loss组成:
1、坐标loss:
1.1 中心点偏移loss
1.2 宽高loss
2、置信度loss:
2.1 含有物体的置信度loss
2.2 不含有物体的置信度loss
3、类别预测:
3.1 多分类loss。
另外,还有两个条件:
1、这个cell是否负责预测物体。
2、这个cell的哪个bbox负责预测物体。
其中,这里存在疑问:
1、那么,这个cell的bbox负责预测物体,是否意味着这个cell负责预测物体。
目前针对上述疑问,我在这篇文章中找到了解释:
https://zhuanlan.zhihu.com/p/32525231
https://zhuanlan.zhihu.com/p/37850811
并在以下代码中找到了对应实现(194~214行):
https://github.com/lesliejackson/YOLOv1_tensorflow/blob/master/yolo_v1.py
所以,针对上图中的绿字部分,我认为:
(之前上面的解释还差一点)
那么除了和之外,我们别忘了还有一个
代表的是:
1、cell不负责预测物体对应的若干个bbox。
2、cell负责预测物体,但是由于只有一个bbox负责找,那么其他的bbox也在这里面。
所以会对应比较多的bbox。
但其实这里还有一个问题,怎么理解?
那么我们理解了,和,就能够发现,在中情况下,对应的bbox数量不同,的数量是最多的。
回顾上面那副loss的图,那么除了对应的bbox以外【橙色部分】,其他三者对应的bbox对应的数量应该都相同的。
所以部分用了来降低数量带来影响;而坐标回归比较重要,所以用 来增大它的影响。
那么我们回头来看实现:
1)predict_res的前7*7*20位,reshape成【batch_size,7,7,20】表示每个cell类别的预测值。predict_classes
2)predict_res的7*7*20~7*7*22表示每个cell中,两个bbox的置信度,reshape成【batch_size,7,7,2】 predict_scales
3) predict_res的7*7*22到7*7*30,表示每个cell中,两个bbox的坐标信息,reshape成【batch_size,7,7,2,4】 predict_boxes
那么在考虑后面的操作前,我们先来看一看,predict_boxes的每一位【x,y,w,h】究竟表示什么:
1、首先,这四个都是一个0~1值。
2、w和h比较好理解,是bbox相对于原图448的尺寸的比例。
3、x,y比较难理解:
3.1 原图假如说是448*448,我将其划分成7*7的小格。
3.2 对于左上角是(0,5)的这个格子,这个格子是一个1*1的格子。
3.3 x表示在这个格子内,相对于左上角,x的位置。(所以x的取值是在0~1之间,表示被限制在这个格子内)
而label中的box的坐标又代表什么呢?【x,y,w,h】:
1、x,y代表这个gt中心相对图像左上角的坐标,是正常坐标。
2、w,h就是正常宽高。
然后,很关键的一点,在用作计算之前,这个box有被统一除以了image_size = 448
因此有:
1、x,y代表这个gt中心相对图像左上角的坐标的比例,是一个0~1的值。
2、w,h表示gt的w,h和图像尺寸的比例,是一个0~1值。
那么如何让两者变得能够比较呢?
办法1:将predict_boxes变成和label一样的格式:
1、转换predict_boxes:假[x,y,w,h],落在(0,5)这个小格内
x_p:表示转换前
x_p_b:表示转换后
cell_size = 7
(x_p+5)/cell_size = x_p_b
2、那么x_b_p就是和label_box一致了。
办法2:将label_box转换成和predict一样的格式:
1、转换boxes:假[x,y,w,h],落在(0,5)这个小格内
x_b表示转换前
x_b_p表示转换后
x_b*cell_size-5 = x_b_p
2、那么x_b_p就是和predict_box一样的格式了。
好了,现在能够看一下,loss各部分该如何实现了。
1) class_loss
这里
net最后一层是一个线性activation…好歹用一个sigmoid啊…
class是一个one-hot值,predict_classes是一个……随机值…TMD…搞毛啊…这样怎么算啊…
能收敛有鬼了…
class_delta = response * (predict_classes - classes)class_loss = tf.reduce_mean( #平方差损失函数tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]),name='class_loss') * self.class_scale # self.class_scale为损失函数前面的系数
2)坐标loss
中心坐标(x,y)的loss:由于中心值都被回归在0~1之间了,所以就直接回归完事。
长宽(w,h)的loss:由于w和h虽然是在0~1之间,但是bbox的w和he 与 gt的w和h还是在绝对值上会差挺多(比如gt_w=200,bbox_w=192;gt_w=20,bbox_w=15;应该后者更重要,但是绝对值下的话,前者会占很大比例),为了用降低绝对值的差,对w和h去根号之后再算MSE。(只能缓和)
'''这里先把predict_boxex和boxes_traind都按照上面所说的处理好了,故直接计算差的平方即可。''''''框坐标的损失,只计算有目标的cell中iou最大的那个框的损失,即用这个iou最大的框来负责预测这个框,其它不管,乘以0object_mask其维度为:[batch_size, 7, 7, 2], 扩展维度之后变成[batch_size, 7, 7, 2, 1]'''coord_mask = tf.expand_dims(object_mask, 4)# predict_boxes维度为: [batch_size, 7, 7, 2, 4],这些框的坐标都是偏移值boxes_delta = coord_mask * (predict_boxes - boxes_tran)coord_loss = tf.reduce_mean( #平方差损失函数tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]),name='coord_loss') * self.coord_scale
3) obj置信度
对于一个cell的两个bbox,我们看它和gt的IOU,那么大的那个我们就认为其中有obj,就被指认用来预测obj;IOU小的则被认为没有。
那么,对于被指认为有obj的bbox,我们希望它的置信度约靠近1越好(这个有待商榷)。
对于被指认为没有obj的bbox,我们希望它的置信度约靠近0越好。
同样,这个也是只有在这个cell是负责预测物体的情况下来说的。
'''原实现中,是没有乘以response的,我觉得不妥,故加上了。''''''对于每个cell对应的两个预测框,有的预测框有物体,有的没有,对两种情况分开处理1、下面是有物体的情况,对于预测值表示有物体的置信度,2、iou表示label的置信度3、…我去…这也可以…66666'''# 有目标的时候,置信度损失函数# 用iou_predict_truth替代真实的置信度,真的妙,佩服的5体投递object_delta = response*object_mask * (predict_scales - iou_predict_truth)object_loss = tf.reduce_mean( #平方差损失函数tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]),name='object_loss') * self.object_scale'''1、没有物体的时候,就直接算预测置信度就好了…2、我们希望这个IoU是越小越好…这个 noobject_mask*predict_scales,其实可以看做是,noobject_mask*(label_confidence-predict_scales)^2中,label_confidence=0的结果。对于不被用来预测物体位置的预测框,我们就希望它尽可能不要和gt重合…爱去哪去哪…我觉得这个没必要啊…'''# 没有目标的时候,置信度的损失函数noobject_delta = response*noobject_mask * predict_scalesnoobject_loss = tf.reduce_mean( #平方差损失函数tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]),name='noobject_loss') * self.noobject_scale
4、测试
测试部分会用到NMS,以及根据class_prob和confidence_prob进行过滤。
详见我之前的笔记。
5、小看法
从代码中能看出一点yolo的弊端,是在数据准备的时候:
之前说了,需要判断每个gt是由哪个cell负责预测。当存在两个gt,都被判断需要第i个cell来负责:gt_1:A,gt_2:B,问题出现了。
当第二个gt_2,来讲cell_i设置为负责的cell时,发现cell_i已经对另一个gt负责了,此时…会抛弃掉gt_2……
爱情都是占有啊…这么说来cell_i还是个好男人………………
