@w460461339
2018-08-20T08:49:21.000000Z
字数 2578
阅读 2489
图像语义分割:Mask RCNN
MachineLearning
0、参考
什么是FPN:
https://blog.csdn.net/u014380165/article/details/72890275
复习一下FASTER-RCNN中的RPN:
https://www.cnblogs.com/CodingML-1122/p/9043128.html
什么是MASK-RCNN:
https://blog.csdn.net/WZZ18191171661/article/details/79453780
1、基本原理
- 1) 提取ROI。
- 2) 根据ROI,利用SPP生成定长的vector,然后对接两个FC,分别得到classifier和bounding-box的结果。
- 3) 根据ROI,利用Upsampling,对ROI进行一定的放大。然后在放大后的ROI中,生成不同的类别的mask,将该mask对应回去,就是原图上的轮廓。
2、详细过程
2.1 ResNet+FPN
参考:
https://zhuanlan.zhihu.com/p/37998710
1)ResNet不多说,它的强大大家都知道。
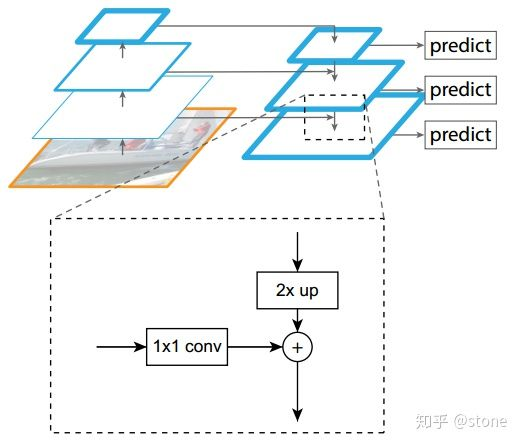
2)FPN其实是一种架构,它有三个关键词:自下而上,自上而下,横向连接。
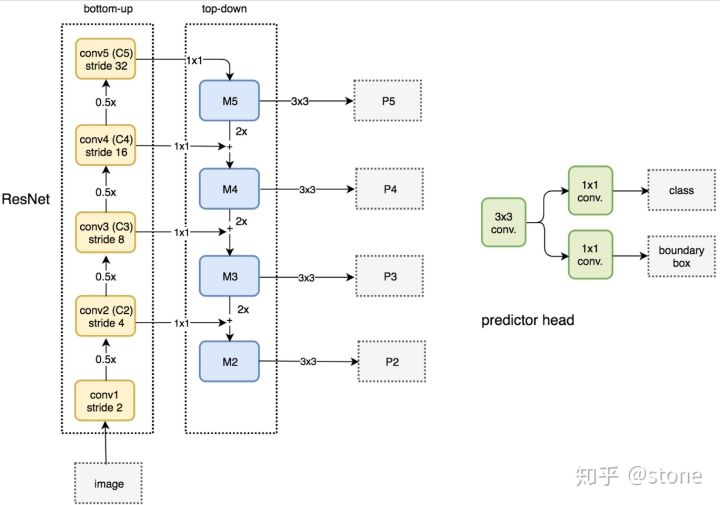
自下而上:
指的是利用现有网络对图像进行特征的提取。
图像在conv1,conv2,conv3,conv4和conv5之后都会缩小50%。
自上而下:
利用差值/反卷积技术(这两个不一样,论文中貌似使用差值),将conv5输出的feature-map逐步放大。
横向连接:
将conv4和M5的输出结合。conv3和M4的输出结合。。。
具体结合方式为:
1、对conv4的输出做1*1的卷积,主要是为了降低通道数。
2、之后对两部分内容直接采用相加操作。
3、加完后对整体用3*3卷积(没提要不要padding),为了降低混叠效应。
- 3)在过了FPN架构之后,会得到P5到P2,4种feature-map。那么我们该从哪个feature-map上来获得所需要的ROI呢?我们会根据公式:
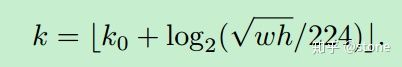
来计算对应的所需要切割的feature-map。
其中,224表示输入图像的原始大小,k0是表示原图的ROI该从哪里切,224的话对应是4。w和h表示ROI在原图中的大小。
假设ROI的scale小于224(比如说是112 * 112), k = k_0-1 = 4-1 = 3 ,就意味着要从更高分辨率的 P_3 中产生。另外,k 值会做取整处理,防止结果不是整数。
2.2 ROIAlign
参考:
https://blog.csdn.net/WZZ18191171661/article/details/79453780
量化操作:
* 1)量化操作1:对于800*800的图,5次pooling之后(缩小32倍),其大小为25*25.但是对于原图上大小为665*665的ROI而言,它的缩小之后就是665/32*665/32=20.78*20.78,不是整数。为了将其对应到像素点,需要取整,将其化为20*20.
- 2)量化操作2:当我们得到20*20的feature-map上的ROI之后,需要通过SPP之类的操作将其变为7*7的feature-vector。这个时候20/7=2/86又除不尽了,只能够再一次进行一下取整操作。
注意,这两步取整操作在物体的分类,甚至是目标物体的检测任务上都不会带来很大的困扰。
但是,像图像语义分割这类需要像素级对准的问题而言,就会歪的不行…
因此,就有了ROIAlign。
ROIAlign:
参考:
https://zhuanlan.zhihu.com/p/37998710
ROIAlign的基本想法是双线性差值。
我认为的做法是这样的:
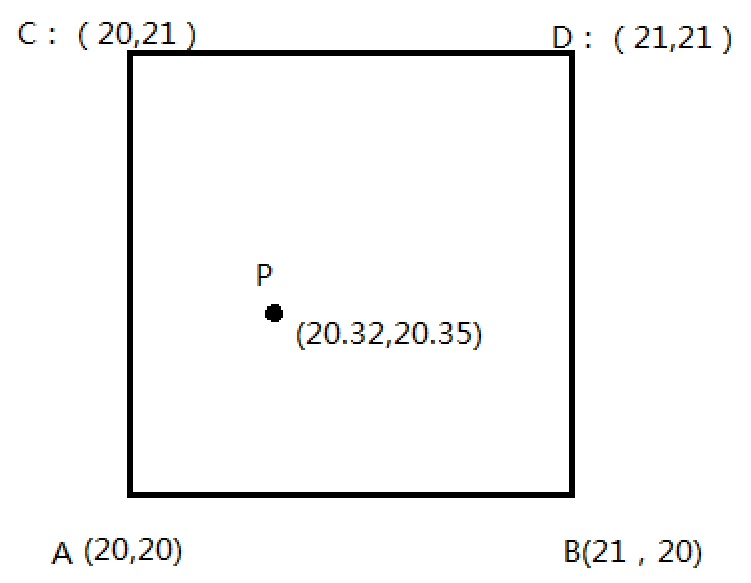
我们发现ROI的点没有落在feature-map的整数点位上。那么点P的像素值,可以通过
的方式得到,
而不需要将P点取整。
这样,ROI上的每一点都可以比较精确的表示,之后对应回原图上也不会有太大的偏差。
2.3 MASK分支
接下来到了MASK分支。
对于MASK而言,网上的博客没具体说,是采用和DEEPLAB一样的逐个像素点分类还是怎样得到MASK的…
我感觉应该没有用概率图模型,就是利用简单的网络来训练了。比如网络输入的是14*14*14的内容,那么输出的还是14*14*14,只不过对每个位置上已经有了一个简单的分类。
但是,假设我们的问题分15类(14+1)。那么,对于每个ROI,我们会输出m*m*14个mask。然后,我们会根据classifier分支的结果,取对应的mask,将其映射回原图上。
另外,mask分支我们采用的是FCN来代替了FC。
个人理解:
FCN能够更好的利用空间信息,从而对图像有更好的感受力。FC的话就丢失了空间信息,太粗暴…
3、总结
看了MASK-RCNN和Deeplab,发现两者的确是走两个不同的路子。
MASK-RCNN走的还是Faster-RCNN的路子,想着如何更高效的利用现有的信息:
1、RCNN -》 FAST-RCNN。重复提取ROI信息太麻烦,我先提取全图信息,你再慢慢选取ROI。
2、FAST-RCNN -> FASTER-RCNN。不需要另外来选proposal-region,feature-map上找一找都有的!
3、FASTER-RCNN -》 MASK-RCNN。既然feature-map上提取的ROI那么有用,不如看看能不能从它里面找到更细致的轮廓信息。
但是,我觉得mask-rcnn离像素级别的分类还是差了一点,因为它更多的通过mask来描述一个对应关系。
DeepLab就不是了。
1、FCN ->SegNet/DeconvNet:类似encoder-decoder的架构,从原图获得低分辨率的feature-map,然后再从低分辨率的feature-map恢复到原图大小。最后使用概率图模型逐个像素进行分类。
2、DeepLab系列:不通过降采样的方式来扩大感受视野从而获取抽象特征(像FCN它们做的),而是通过比例不同的带洞卷积来获得更高级的特征。之后同样对原图使用概率图模型,逐个像素分类。
没具体研究过,猜测:
因此,我觉得从精度上而言,应该会是deeplab为代表的像素级图像语义分割高一些,但是从计算速度上,我可能更看好mask-rcnn。
