@w460461339
2018-09-10T01:59:01.000000Z
字数 911
阅读 1385
目标检测:SSD
MachineLearning
0、参考
https://zhuanlan.zhihu.com/p/33544892
差不多也是这一篇就够了。
1、SSD基本原理
回想一下YOLO:
1、将proposal-region整合到一个网络里面,而不是像RCNN系列分两步。
2、YOLO对分类和框位置预测都采用回归预测得到结果。
现在SSD就以下三个方向进行改进:
1、使用VGG的前几层,且在最后没有接全连接,而是用卷积层代替。
2、采用了FPN的设计思路,在不同尺度的feature-map上进行预测,离原图近的feature-map上预测小物体,离原图圆的feature-map上预测大物体。
3、SSD采纳了FASTER-RCNN中的想法,用了不同的先验框。
下面针对这几个特点一一来说。
全卷积参考:
https://blog.csdn.net/lien0906/article/details/78429053
https://blog.csdn.net/lanmengyiyu/article/details/80719373
1)卷积层替代全连接层。简单来说,就是一个图像上有多个物体需要检测/分类时,如果用FC的话,需要多FC,但是用全卷积网络的话,就可以减少参数。
2)FPN。SSD和YOLO网络的比较如下图所示。可以看到SSD从conv5_3就开始预测。通过采用不同大小的feature-map作为预测输入,来得到不同尺度下的预测结果,有利于小物体的检测。
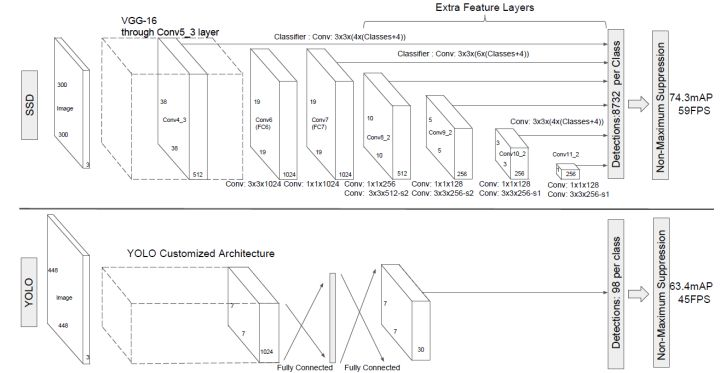
3)先验框。下面两幅图,第一幅是SSD的先验框,第二幅图是YOLO的bounding-box。对于SSD而言,它在feature-map每个像素点上,会首先给定若干个大小比例固定的先验框。之后,网络可以基于这些先验框来得到他的预测框。而在yolo上,它并没有先验框,它每个网格中随机给两个框,然后通过调整这两个框的位置,来做预测。
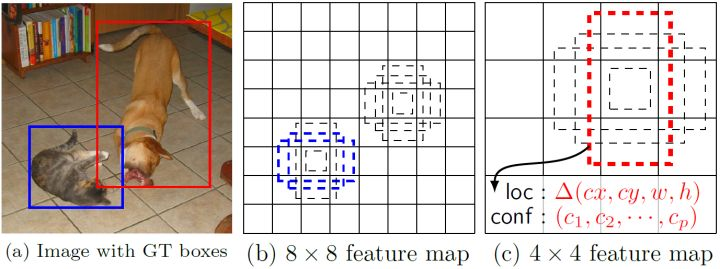

这里引入的先验框,跳开来看我觉得和ResNet的设计思路很相似。Yolo的操作是我不给你任何知识,你就自己随机选择然后调整吧。SSD的操作是,我告诉你这个物体有可能被这样或者那样的框框住,但是我给的不一定很准,你在我的基础之上调整吧。
