@w460461339
2018-08-27T09:47:40.000000Z
字数 4186
阅读 3919
详解LeNet,AlexNet,VGG,GoogleNet,ResNet,DenseNet
MachineLearning
LeNet~ResNet实现和参考:
实现:https://blog.csdn.net/wang1127248268/article/details/77258055
简单介绍:https://blog.csdn.net/xbinworld/article/details/45619685
1、LeNet
参考:
https://blog.csdn.net/qqadssp/article/details/70431236
卷积的开山鼻祖吧,3*3卷积,用了池化,activation-function用的是tanh。
1.1 模型
模型输入:32*32
模型层级:
(除了最后一个Dense的激活用activation以外,其他都用tanh)
模型输入为32X32的灰度图像,
第一层为6个5X5卷积核,不扩展边界;
第二层为2X2的最大值池化层,步进为2X2;
第三层为16个5X5卷积核,不扩展边界;
第四层为2X2的最大值池化层,步进为2X2;
第五层为展平层,并全连接120个节点;
第六层为全连接层,84个节点;
第七层为全连接softmax层,输出结果。
2、Alexnet
参考:
https://blog.csdn.net/hong__fang/article/details/52080280
模型特点:
1. 相比于lenet更深了.
2. 加入了relu作为激活层
3. 使用了dropout,防止过拟合.
4. 使用maxpooling,而不是averagepooling
5. CNN在GPU上并行操作,加速训练
模型结构:
输入图像size : 227 * 227 * 3
第一层卷积 : 55*55*96 (相当于有96张55*55的图)
并且,我们将这96张图,分成两部分,存在两个GPU上。(每部分都是55*55*48)
池化: 27*27*96
第二层卷积: 在每个GPU上,使用自己的48张图,生成 27*27*128的图。(所以总共是27*27*256)
池化: 13*13×256
第三层卷积: 在GPU1上,使用全部256份数据,生成上半部分的192的数据(13*13*192)。(总共是13*13*384)
第四层卷积: 每个GPU各自将输入的13*13*192映射到13*13*192
第五层卷积: 每个GPU 13*13*192-》13*13*128
第六层池化: 每个GPU:6*6*128
第六层全连接: 全部6*6*256进行全连接-》4096 (relu+drop)
第七层全连接:4096->4096 (relu+drop)
第八层全连接:4096->1000
多GPU训练,通过精确控制feature map的传播来控制GPU间数据通信,仅有部分层需要利用全部的feature map。
3、VGG
参考:
https://blog.csdn.net/qq_31531635/article/details/71170861
特点:
VGG是把网络分为5组(模仿AlexNet的五层),然而它使用了3*3的滤波器,并把它们组合起来作为一个卷积序列进行处理。特征:
1.网络更深DCNN,channel数目更大。
2.采用多个3*3的卷积,模仿出更大的感受野的效果。这些思想也被用在了后续的网络架构中,如 Inception 与 ResNet。
3、相比于5*5,7*7的kernel,3*3可以用多个堆叠的方式,以更小的参数数量达到相同的感受视野。
模型:

4、GoogleNet
参考:
https://blog.csdn.net/qq_25491201/article/details/78367696
https://www.zhihu.com/question/56024942
https://zhuanlan.zhihu.com/p/22817228
加入了inception块:
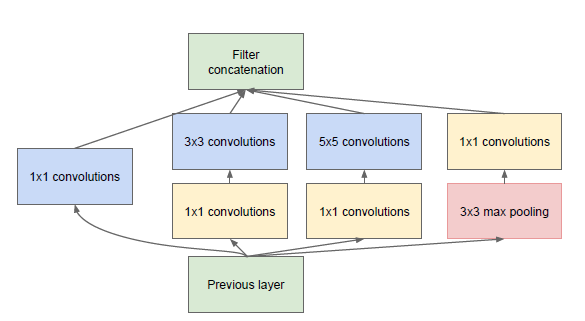
inception理解:
1. inception分两部分看,一部分是米黄色的1*1卷积,一部分是浅蓝色的1*1~5*5的卷积和红色的池化.
Part1:浅蓝色卷积+红色池化
怎么理解这里?
其实可以这么理解. 我们不知道模型需要通过怎样大小的卷积核来提取特征,因此就把4个选择给他,让他自己来选.
Part2:1*1 卷积
网上都说1*1卷积是用来降维的,是的,它是用来降depth的维度的.
比如输入是5*5*3的图像,经过它,可以实现5*5*2的图像.
可以理解为它对把不同depth的图像进行线性组合,线性组合的个数就是最终输出的depth个数.
2、concatenation指的是channel叠厚。
3、最大池化是因为,maxpooling的效果也不错,所以就加上。
5、ResNet
参考:
https://blog.csdn.net/buyi_shizi/article/details/53336192
https://zhuanlan.zhihu.com/p/31852747
https://www.zhihu.com/question/64494691
https://blog.csdn.net/wspba/article/details/56019373#commentsedit
https://www.zhihu.com/question/52375139
如何用conv3*3来实现identity-mapping(He【作者】在PPT里提到的):
1、padding with 1
2、kernelsize=3,自定义核,中间1,其他都是0;strides=1
前面几个模型都是10+层的小打小闹,这个网络一下就到了150+,最深还可以达到1000多。
其他一些理解:https://www.zhihu.com/question/64494691
目标问题:
1、对VGG19,通过添加由conv3*3实现的identity mapping层来加深模型。
2、理论上,更深的模型表现能力应该更好。
3、但是,实验结果是,更深的模型表现能力更差了。————退化问题
4、因此提出了新的解决方案。
退化问题:
1、这里关于退化问题多说两句。
2、发现退化问题:在plain network上加了identity mapping层后,发现更深的网络效果不好。
3、然后觉得gradient vanish问题已经被batchnormalization解决了。
4、觉得plain network难以学习到identity mapping,所以效果才这么差= -。
5、额,所以从这个角度看,退化问题并不是一个推导出来的问题,而是一个由实验得出来的问题。
6、而,gradient vanish,是从数学上证明了,会有这个问题= - 。
误差传递: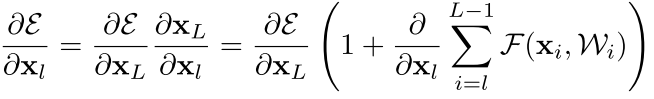
1、这个传递保证了$∂E/∂xl$ 这一项不会衰减,而后面的又是累加,
2、这两项都保证了误差在向后传播时,不会衰减。
ResNet的核心结构(最优结构):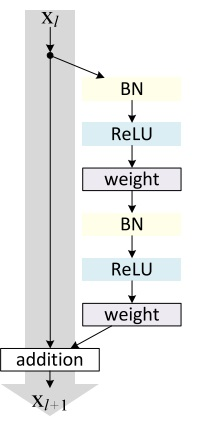
输入输出维度变化怎么办:
1、首先明确一点,有conv,BN,ReLU的叫residual unit;另外一边叫shortcut。
2、维度变化是指,网络生成过程中,我们会增加feature的数量,于此同时,feature map的size会减半。
3、那么这个时候 residual unit的输入输出的size就不一致了,这个时候有这么3种方案:
对shortcut处理:
1、shortcut全部都用线性变换 Wl×Xl,来处理维度不一致。
2、在residual unit输入输出维度一致的地方,直接用identity map;尺寸有变的地方,用线性变换。
对residual unit处理:
1、对featurea map利用zero padding来填充,shortcut直接就是identity map
4、我们这个模型里面,采用的是residual unit一致的地方采用identity map;尺寸有变的地方采用线性变换
6、DenseNet
参考:
https://blog.csdn.net/u014380165/article/details/75142664
https://blog.csdn.net/qq_31531635/article/details/71170861
模型结构:
input->
Conv->DenseBlock ->
Conv->POOL->DenseBlock->
Conv->Pool-> DenseBlock ->
Pooling ->全连接
核心,DenseBlock:
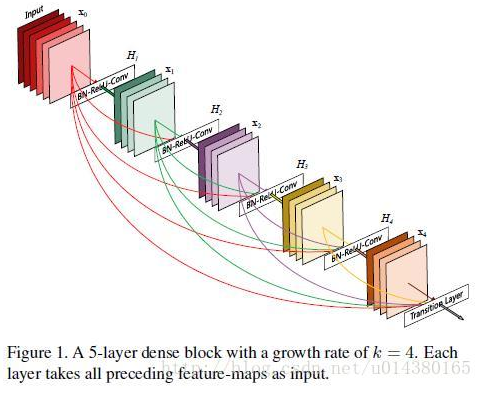
DenseBlock解释:
1、图中每一组彩色正方形表示一个卷积,可以看到图中一共有5组卷积。
2、每一个卷积,他的输出,都会和后面每一个(包括自己)的卷积结合(concatenation),然后传递到下一层。
3、比如1的输出,传递到1-2之间,传递到2-3之间并与2结合,传递到3-4之间并与2,3结合...
ResNet和Dense:
1、对于ResNet而言,从loss上可以看到它使得梯度或者信息能够高效的传递。
2、DenseNet而言,从图像上,在一个denseblock内,我们可以认为,每一层conv提取出的特征,都用到下面每一层中。
3、所以,从DenseNet而言,它的浅层feature都可以被很后面的层看到。
4、从一个DenseBlock内看,无论多深,后面的层都可以直接看到前面任何一层,降低了传输loss的传输成本。
5、就这一点而言,DenseBlock做的比ResNet直接。毕竟ResNet要通过一个一个的Identity Mapping来实现,这里就直接跳了= -
6、另外,ResNet处理前面层信息的方式是 add(理解为融合),而DenseNet是concatenation(理解为直接使用)
减少计算量和处理overfitting:
1、在DenseBlock中的每个conv(3*3)前面都加了1*1的卷积(称为bottleneck layer),来减少channel的数量。
2、在DenseBlock和DenseBlock之间的conv(3*3)前,也加入1*1卷积,称为Translation layer
