@w460461339
2019-02-20T10:14:24.000000Z
字数 2865
阅读 1362
TensorflowDay4.1:ResNetForward
Tensorflow
1、ResNet Forward
参考:
代码:https://blog.csdn.net/superman_xxx/article/details/65452735
原理:https://blog.csdn.net/lanran2/article/details/79057994
https://blog.csdn.net/u013709270/article/details/78838875
1.1 ResNet基本概念
这里不详细说,大概就是通过残差的思想,解决了神经网络不能过深的问题,使得神经网络从原来的19or32层,一下子跳到了152层,甚至可以更深。
网络的部分看起来差不多长这个样子
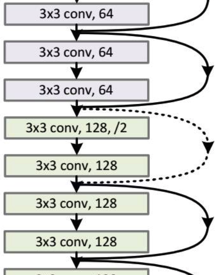
然后,每个残差块长这个样子:
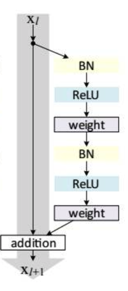
论文说上面的模块是最优的,但实际写起来不是这样的啊:
1、需要区分输入和输出的维度是否相同。如果不同,那么对于shortcut(就是上图灰色区域笔直的那一条,还需要加上一些操作才行。
2、实际写起来,上图右边的区域差不多是:
2.1 显示BN+激活
2.2 1x1xn,3x3xn,1x1xn这样的三个卷积过来,其中3x3的卷积,还可能是stride=2的情况,
2.3 最后将shortcuts和残差路线的结果对应位置相加。(不是concate)
1.2 代码逻辑
注意到,resnet中,有:
1、每个残差单元中包含若干个(3个)卷积操作。
2、将输出维度一致的残差单元放在一起,形成若干个(4个)Block。
3、Block之间的交汇处需要缩小尺寸,因此通过步长为2的卷积实现。
因此,我们定义两层循环:
1、第一层,表示需要有几个Block。这里是4.
2、第二层,表示每个Block里面有几个残差单元。
2.1 下面看到,第一个Block中有3个残差单元,
2.2 其中,其前两个残差块的输出维度是256,中间卷积输出维度是64,步长都是1
2.3 最后一个输出维度不变,但是步长是2,即需要缩小尺寸。
Block('block1',bottleneck,[(256,64,1)]*2 + [(256,64,2)]),Block('block2',bottleneck,[(512,128,1)]*7 + [(512,128,2)]),Block('block3',bottleneck,[(1024,256,1)]*35+[(1024,256,2)]),Block('block4',bottleneck,[(2048,512,1)]*3)
在拿到每个残差块需要的参数(256,64,1)后,我们开始搭建残差块:
@slim.add_arg_scopedef bottleneck(inputs,depth,depth_bottleneck,stride,outputs_collections=None,scope=None):'''Args:inputs: A tensor of size [batch, height, width, channels].depth、depth_bottleneck,stride三个参数是前面blocks类中depth表示这个残差块最终输出channeldepth_bottleneck表示这个残差块中间的卷积核输出channelstride表示卷积步长outputs_collections: 是收集end_points的collectionscope: 是这个unit的名称。'''with tf.variable_scope(scope,'bottleneck_v2',[inputs]) as sc:depth_in = slim.utils.last_dimension(inputs.get_shape(),min_rank=4)'''1、回忆resnet的顺序,第一条路:先normal,再激活,然后再卷积第二条路:shortcuts'''preact = slim.batch_norm(inputs,activation_fn=tf.nn.relu,scope='preact')'''下面是short_cuts部分'''if depth == depth_in:shortcut = subsample(inputs,stride,'shortcut')else:shortcut = slim.conv2d(preact,depth,[1,1],stride=stride,normalizer_fn=None,activation_fn=None,scope='shortcut')'''下面是非short_cuts部分'''residual = slim.conv2d(preact,depth_bottleneck,[1,1],stride=1,scope='conv1')# 就只有这里stride可能是2,所以需要特殊写一个conv方法,来处理residual = conv2_same(residual,depth_bottleneck,3,stride,scope='conv2')residual = slim.conv2d(residual,depth,[1,1],stride=1,normalizer_fn=None,activation_fn=None,scope='conv3')output = shortcut+residual'''这里大致意思是把output这个tensor以别名sc.name的方式加入到名字为outputs_collections中去然后再返回output这个tensor'''return slim.utils.collect_named_outputs(outputs_collections,sc.name,output)
1.3 其他问题
问:tf.variable_scope中的values参数是干什么用的?
答:主要是为了当跨graph时,也能够正确传递参数用的。
https://stackoverflow.com/questions/40164583/tensorflows-tensorflow-variable-scope-values-parameter-meaning
问:@slim.add_arg_scope是做什么的?
答:通过这个修饰自己的函数,这样就可以使用with slim.arg_scope来定义参数了。
https://blog.csdn.net/weixin_35653315/article/details/78160886
问:collections.namedtuple用法?
答:相当于简单的类把。
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431953239820157155d21c494e5786fce303f3018c86000
还有很多参数用法,具体可以看我的代码。
