@w460461339
2019-02-20T10:14:45.000000Z
字数 2319
阅读 1725
Tensorflow Day3.1:Weight-Decay&GoogleNet&feature-map可视化
Tensorflow
1、什么是Weight Decay
简单理解,Weight_Decay,其实就是加了一个L2正则项。
加入L2正则化的Cost——function:
梯度项:
梯度更新:
那么相当于对更新的参数进行了缩放,所以是weight_decay.
注意和momentum的区分
momentum是在梯度项上做了手脚,对梯度项加上了之前的梯度值,使得其能够保留之前的信息。
这个和对被更新的weight进行缩放是不同的。
2、googlenet inception迭代特点
参考:
https://my.oschina.net/u/876354/blog/1637819
2.1 googleNet-inception-V1
首先,为什么会有v1?
1)提升网络能力的方法有两种:
1、加深网络层数。
2、加宽每一层的网络。(就是每一层参数更多一些)然而:
1、太深会有梯度消失问题。
2、太宽则导致参数过多。2)因此,Google利用Inception这一种结构来解决参数的问题。
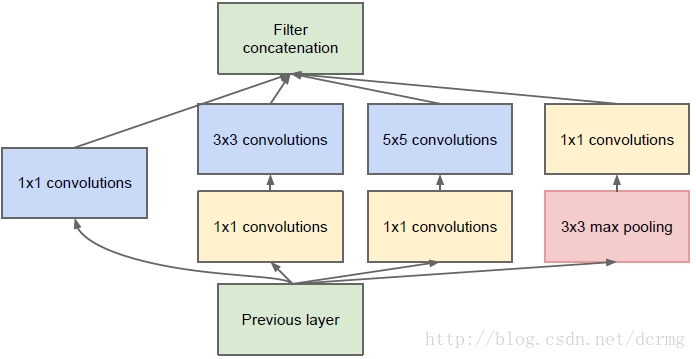
3)在这一个结构中,不同的分支采用了不同大小的卷积核,表示对原图的不同感受野的特征提取,可以理解为多尺度的特征融合。
4)前面的1*1卷积,是为了对输入feature-map进行降维,减少后面3*3以及5*5所需要的卷积核参数。
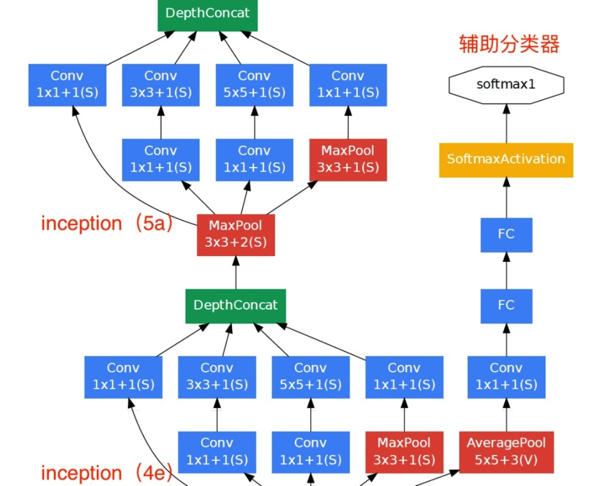
5)GoogleNet中会看到下图的结构,有一个辅助分类器,
其作用如下:
1、GoogleNet网络较深,担心梯度消失。
2、因此,在这里计算了这一步输出的分类结果,作为额外的梯度值,在乘以某一个系数(比如0.3)之后,再加入到最终的loss中去。
3、这样好处有三:
3.1 增大了梯度信号。
3.2 对这一步之前的weight而言,相当于加入了正则项,防止过拟合。
3.3 训练时候相当于用了多尺度,做了模型融合。
4、这个只是在训练过程中使用,预测时候不适用。
- 6)效果:GoogleNet更深,但是参数却是VGG或者AlexNet的1/12,乃至更少。
2.2 Inception-V2&V3
- 1)卷积分解。
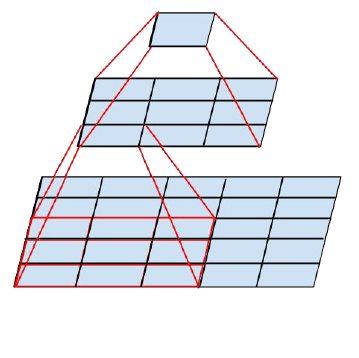
1、5*5分解成两个3*3.
2、将3*3分解成1*3后面接一个3*1.
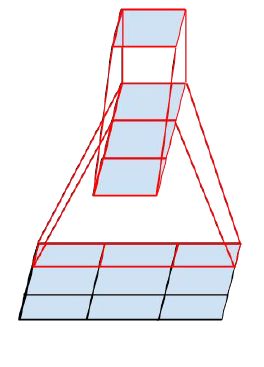
但是,第二种卷及分解在浅层效果不好。实验表明,当feature-map的尺寸在12~20(这里不知道是指边长还是面积)时,效果才比较好。
- 2)降低特征图大小。
1、在inception中并行执行池化和步长为2的卷积,进行feature-map的减小。
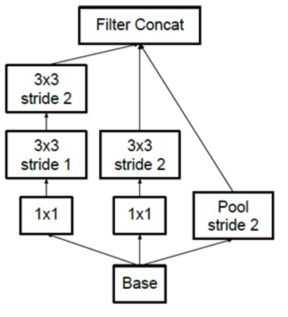
2.3 Inception-V4
加入了ResNet的思想。
3、feature-map可视化总结
这个其实没有什么好说的,其实操作很简单:
1、找到想要可视化的层,和执行训练一样,用sess.run执行它。
2、得到的结果一般是一个[batch_size,height,width,channel]的tensor。
3、我一般都是随意选一个batch,然后将每个channel的图像分开保存,相当于得到了channel个[height,width]的图像。
4、注意得到的图像中每个像素值是一个小数,一般是0~1之间。所以我会乘以一个255,并整数化,就能得到中间层的值了。
'''train'''feature_map_dir='./feature_maps/'init=tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)for i in range(20000):batch_x,batch_y=mnist.train.next_batch(50)if i%100==0:# h_pool1就是我们想看的feature_mapresult,feature_map1=sess.run([accuracy,h_pool1],feed_dict={x_input:batch_x,y_input:batch_y,keep_prob:1.0})# 打印尺寸print(int(i/100),result,feature_map1.shape)# 对于每个channel,将对应的feature-map*255,并整数化后保存即可。for j in range(32):cv2.imwrite('./feature_maps/img_'+str(j)+'.jpg',feature_map1[24,:,:,j]*255)sess.run([trainer],feed_dict={x_input:batch_x,y_input:batch_y,keep_prob:0.5})
