@w460461339
2018-10-12T09:04:40.000000Z
字数 2317
阅读 3531
通用OCR-文本检测:PixelLink,MaskTextSpotter,TextSnake
MachineLearning
药品识别-ctpn+crnn
身份证识别-heg+yolo+crnn
发票识别-sift+crnn
通用OCR-各种定位+crnn
风格迁移-GAN网络
人脸匹配-FaceNet
1、PixelLink
1.0 参考
https://zhuanlan.zhihu.com/p/38171172
1.1 原理
和EAST有点像,和其他一点都不像。
具体而言,就是不直接回归文本框,而是用实例分割的方式,找到像素级文字区域,然后通过这些区域得到文本框。
其实还是SSD+U-NET的想法。
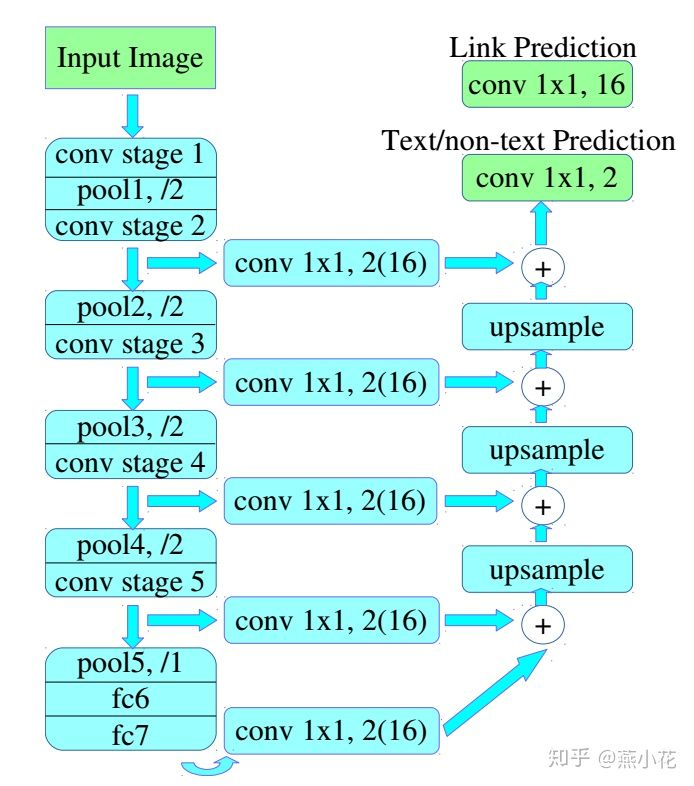
1)输入图片用vgg提取特征,然后提取每一层的feature-map。
2)自顶向下的融合这些feature-map。
3)像素级别的输出每个像素点:
1、是文字还是非文字区域的概率。
2、和周围8个连通域是属于同一个文字区域的概率。
4)会有数据增广。
2、MaskTextSpotter
2.1 参考
https://zhuanlan.zhihu.com/p/44491270
2.2 原理
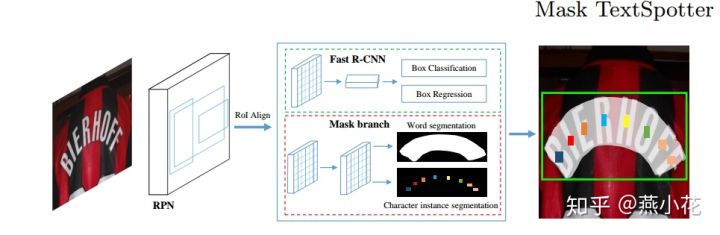
整个网络结构沿用了Mask RCNN,包括四个组件:
1).特征提取主干网络,采用的是ResNet+FPN;
2).候选区域生成RPN;
3).Fast RCNN回归边框;
4).mask分支,用于文本实例分割和字符分割;
相比原生的Mask-RCNN,MaskTextSpotter的创新点在于修改了mask分支的输出,使其包含全局文本实例分割和字符分割。
1)训练阶段,RPN网络提取的候选区域,送入FAST-RCNN(不是FASTER啊),生成文本提取框。同时,也将RPN的输出送入MASK网络(具体就是FCN的操作吧),做文本的实例分割和字符分割。
2)测试阶段,RPN网络提取的候选区域,送入FAST-RCNN,生成文本提取框。然后,将文本提取框的区域送入MASK网络,做文本的实例分割和字符分割。
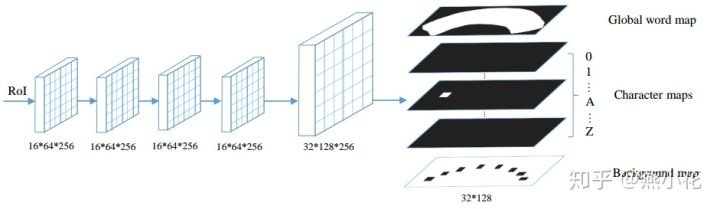
3)MASK分支的channel数量为1+36+1,第一个1表示的是整个文字实例区域,36表示的0~9加a-z这几个字符的mask,最后一个1表示的是背景区域。
别人总结:
1、本文提出了端到端训练的Text-Spotting方法(MaskTextSpotter),该方法可以用于检测和识别任意形状的文本,包括水平文本、垂直文本、曲线文本.
2、MaskTextSpotter中文本检测模块采用的基于文本的实例分割(还有一些文本检测方法也是采用实例分割,如PixelLink、PSENet等),识别模块采用的是基于字符的识别方法.
3、在字符识别时,因为本文只提供了数字和英文字符的识别,并未实现中文的识别.但是在真实场景中,中文识别普遍存在,如果按照论文的方法,如果要想识别中文,需要修改mask分支的输出,如果没记错的话,常用的中文字就有5000个,那mask分支的最终输出为5038张特征图;而且在标注数据的时候,还需要生成对每个中文进行bbox标注,工程量还是挺大的.(这是个人想法,如果理解错误了,望提醒)
4、这篇文章主题的思路其实就是一个mask rcnn,增加了mask分支的输出
3、TextSnake
参考:
https://blog.csdn.net/qq_14845119/article/details/81671717 【更详细】
https://zhuanlan.zhihu.com/p/40864789
3.1 基本想法
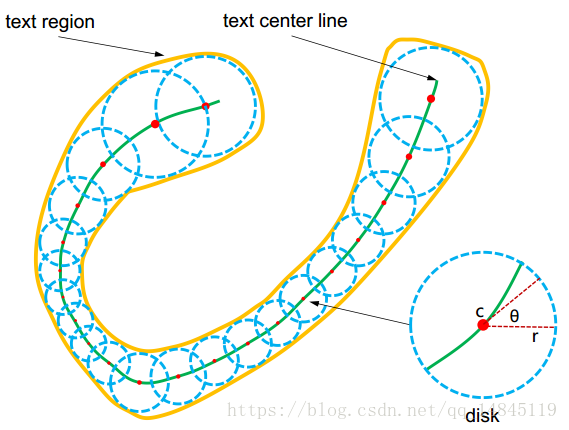
通过用一系列的圆形区域以及骨架线来描述各式各样的文本区域。
3.2 网络结构
1)base-net:利用FCN+FPN思想,使用VGG16,将多层特征自顶向下融合,得到feature-map为原图的1/2.
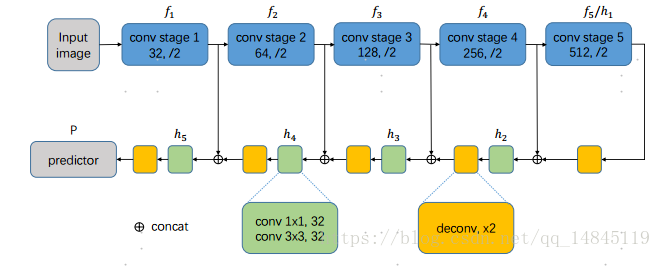
2)输出7层特征图。2层TR(Text Region),2层TCL(Text Center Line。),1层r层(半径),1层cosθ,一层sinθ。
3)得到最终的feature-map之后,对TR和TCL做交集操作,表示TCL必须在TR区域内获得。得到的TCL也是一个,需要根据这样的区域来获得骨架线。
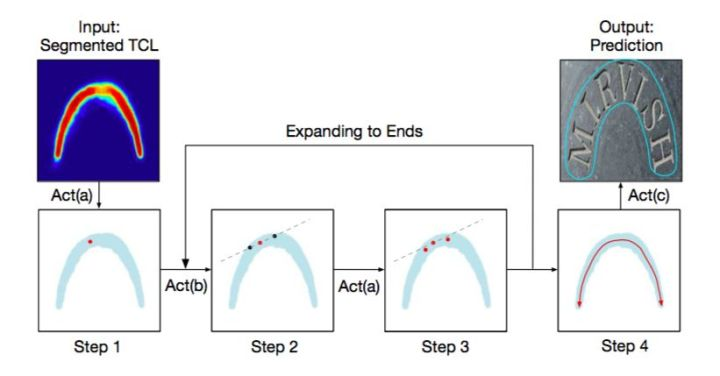
4)具体而言,分三步:
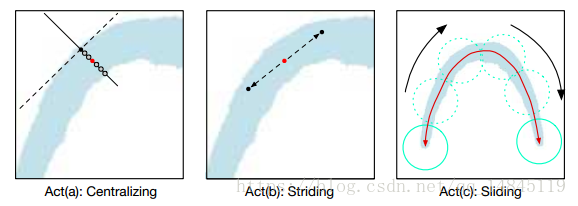
1、随机在TCL区域内选择一点,作为初始点。然后执行下图的centralizing操作,找到它对应的中点。(大概就是根据切线和垂线,然后在垂线上,找到中点就好。
2、根据中点,以及这个点对应的cosθ和sinθ,按照以下公式在该点前后找到新的点。
( (1/2)r × cosθ; (1/2)r × sinθ) and (- (1/2)r × cosθ; - (1/2)r × sinθ)
3、以找到的两个点作为起始点,按照各自的方向找到新的点。
4、当某个点出了TCL区域时,不断缩小r,直到点落在边界上,结束寻找。
3.3 打标是个大工程
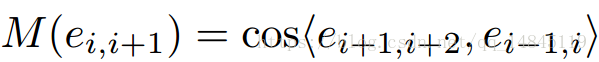
- 1)首先,label需要已知凸多边形的点的坐标。然后每2个相邻的点可以计算一个余弦距离M。
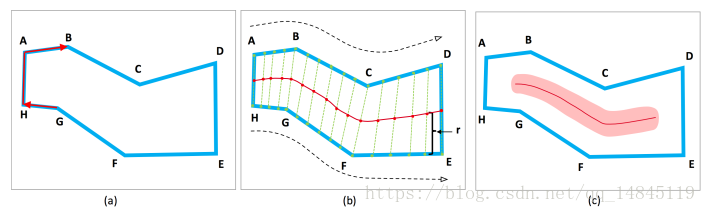
2)将M中的数值两两相乘,乘积最接近-1的,说明是头尾两端。【图a中AB*HG接近-1,是头尾两端】然后取头尾两端的中点作为字体骨架的两端。被该头尾分开的上下两端各取等量的散点,并将上下的散点连接起来,取连接线的中心点作为骨架点,将所有的中点连接起来,生成字体区域的骨架线。
3)后续再对骨架线的左右两端各缩小1/2rend的距离,rend表示TCL 在头尾两个端点处的半径。最后膨胀TCL区域1/5r,得到一个相对较宽的TCL区域。因为单独的一个点对于噪声是比较敏感的。
3.4 loss没有想象中的那么复杂。
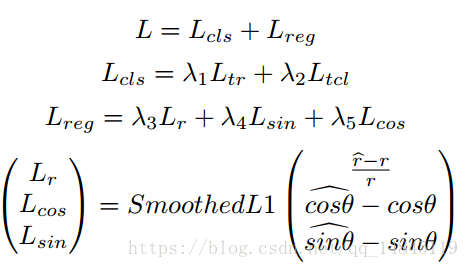
两种loss:
1、TR和TCL区域的分类loss。
2、半径,cosθ,sinθ的回归loss。
