@w460461339
2018-08-27T03:11:26.000000Z
字数 3595
阅读 9392
轻量化模型:SqueezeNet,MobileNet,ShuffleNet以及Xception
MachineLearning
0、预备知识
首先需要对卷积过程有充分的了解。
参考:
https://blog.csdn.net/sscc_learning/article/details/79814146
https://blog.csdn.net/zhongkeli/article/details/51854619
简单而言,对于输入是 m*m*c的图像,卷积核大小是k*k,其输出是n*n*d,也表示卷积核的数量是d。其总参数是多少,总的乘法计算量是是多少?
总参数: c*k*k*d*q
总乘法计算量:c*k*k*n*n*d
简单来说是这样:
1、对于输出的feature-map上某一个channel的点,它经过如下两步得到:
1.1 一号核大小为k*k,在输入图像的每个channel上都有对应有一个卷积核。
1.2 每个channel的卷积完毕后,通过加法将每个channel上的内容加起来,就得到了最后的一个点。
1.3 这样输出feature-map上每个点的计算量为 c*k*k
2、那么输出的feauter-map上有n*n*d个点,所以总共的乘法计算量是c*k*k*n*n*d
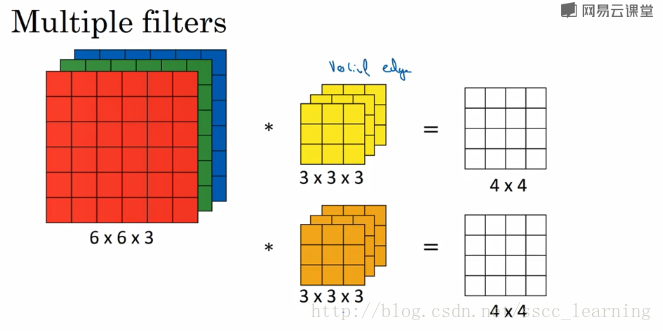
1、Squeeze-Net
参考:
https://blog.csdn.net/shenxiaolu1984/article/details/51444525#fn:1
- 1)squeeze-net的精髓就是下面这个结构:
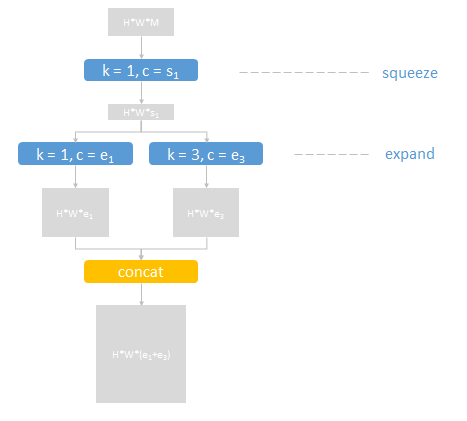
在AlexNet中,通过两个3*3来替换掉了5*5。在squeeze-net中,这里主要是通过1*1和3*3相结合的方式来替换掉原来的3*3.
2)在整体网络设计方面,也用FCN替换掉了FC,节约了大量的参数。
倒数第二层是卷积层,得到一个m*m*1000的featurea-map,之后过一下average-pool,得到一个1*1*1000的向量,就是这个图在1000个类别方面的得分。

3)当然,它还用了一些deep-compression的方法,比如裁剪,量化和编码。
裁剪:设置阈值,对小于阈值的参数直接写0,然后用非零参数再次训练。
量化:对参数做聚类,然后每个类别的参数的梯度值相加,作用在聚类中心上。
编码:Huffman编码进一步压缩存储。
总结:
1、提出了一种新的结构,来对原先的网络进行修改。
2、使用FCN替代FC,减小参数数量。
3、使用deep-compression方法来进一步缩小模型。
问题:
1、对于5*5和两个3*3的计算量,我们可以比较一下。
2、我们假设输入图像大小是5*5*1,最终都需要将其变成1*1*1.
3、那么对于5*5的核(暂时用1个),我们的总参数是25,总的乘法计算数为1*5*5*1=25
4、而对于3*3的核(用1个),我们总参数是2*3*3=18.总的乘法计算数:
4.1 5*5*1->3*3*1: 乘法计算数目为 1*3*3*3*3*1=81次。
4.2 3*3*1->1*1*1: 乘法计算数目为 1*3*3*1*1*1=9次
4.3 总共是90次(超多)
| 核大小 | 参数数目 | 计算量 |
|---|---|---|
| 5*5的核 | 25 | 25 |
| 3*3的核 | 18 | 90 |
但是…计算机读内存的速度比计算乘法的速度慢多了,所以我们宁愿多算几次,也不要多读一点内存数据。
2、Mobile-Net
Mobile-Net是后面两种net的爸爸啊…
参考:
https://blog.csdn.net/c20081052/article/details/80703896
https://blog.csdn.net/qq_25552539/article/details/79221129
还记得我们在预备知识里面说到了,CNN的详细计算过程:
1、核在输入feature-map上的每个channel做卷积。
2、卷积完成后,结果累加得到最终的值。
而Mobile-Net基于这两个过程提出了一种新的卷积思路(depthwise-separable-convolution):
1、对于输入m*m*c的feature-map,我们给c个卷积核。
2、每个卷积核分别在一个channel上做卷积,得到了n*n*c(做padding的话就是m*m*c)的feature-map。
3、之后在n*n*c的feature-map上,做1*1的传统卷积,得到了最终的卷积成果。
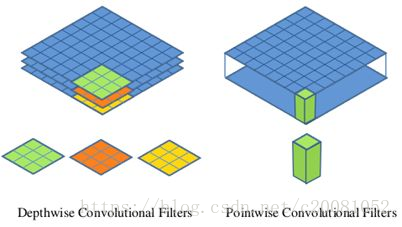
可以简单算一下,乘法计算量,对于输入是DF*DF*M,输出是DF*DF*N,核大小是DK*DK。
传统卷积:
M*DK*DK*DF*DF*N
MobileNet结构:
M*DF*DF*DK*DK+M*DF*DF*N
两者相比的结果:
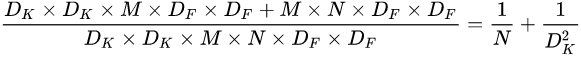
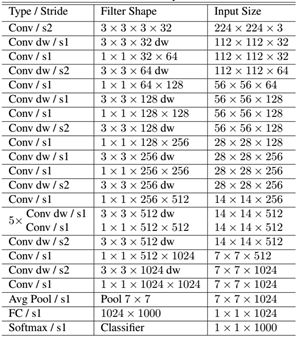
嗯,这个就是这样啦。它的完整网络结果如下,其中dw表示的就是depthwise-separable-convolution:
3、ShuffleNet
这个不知道为什么我看笑了…(应该是觉得这样都行啊…)
参考:
https://blog.csdn.net/u011511601/article/details/79633070
ShuffleNet是在ResNet上进行修改。
核心图:
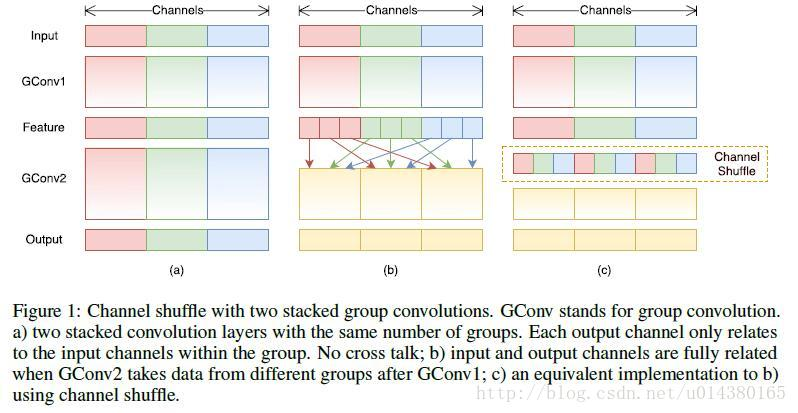
- 1)基本思想:之前每个卷积核都要把所有的输入channel跑一遍太累了,现在我们分一下组。
详解:
1、假设有输入的feature-map是5*5*9的图。我们按照channel将其分为3组。
2、同样我们有12个卷积核,同样将其分为3组,每组负责对某一组channel进行卷积。
3、另外,如果一直这样分开,容易产生边缘效应。所以,对于每个channel内部,在卷积完了后,我们在分成若干个sub-group。
4、然后下一层的group就由上一层每个group中各取一个subgroup组成得到。
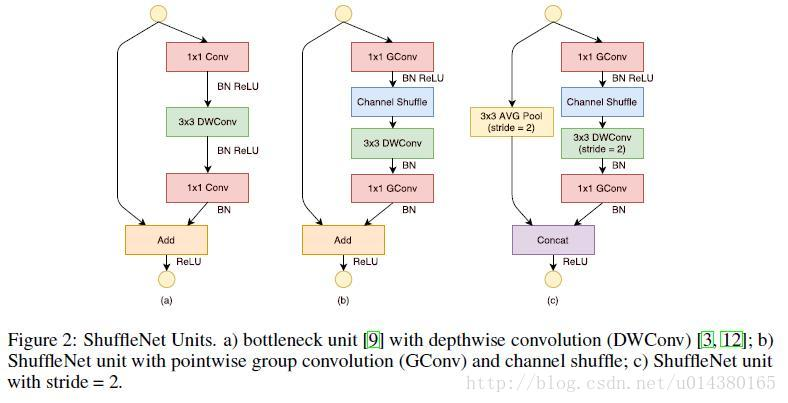
- 2)对ResNet的改进,见下图。
详解:
1、a图是直接用DepthWise-Separable替换掉了其中的传统3*3卷积。
2、b图把最开始的1*1卷积替换成了group-convolution+grou-shuffle结构。
3、c图就是把shortcut上直接传入改成了用3*3的AVG池化,strids=2,且最后不是加二十concat。
总结:
1、ShuffleNet的核心就是用pointwise group convolution,channel shuffle和depthwise separable convolution代替ResNet block的相应层构成了ShuffleNet uint,达到了减少计算量和提高准确率的目的。
2、channel shuffle解决了多个group convolution叠加出现的边界效应,
3、pointwise group convolution和depthwise separable convolution主要减少了计算量。
4、Xception
参考:
https://blog.csdn.net/u014380165/article/details/75142710
- 1)首先,我们简单梳理一下google inception的发展过程。
下图是最基本的inception,思路是我不知道那种提取特征的方式最好,索性都做一遍,然后concat一起,让网络去学习。
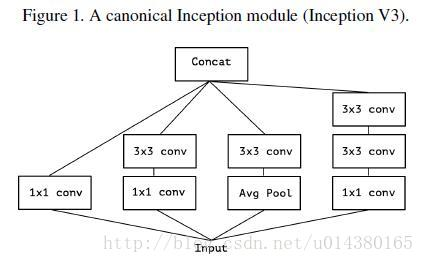
基于Figure1中的内容,提出的简化版的Inception。
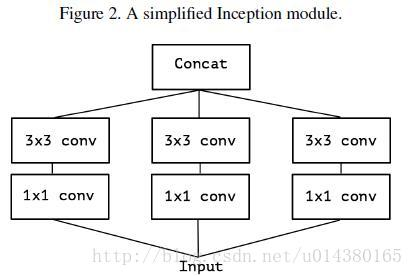
简单利用一下group的思路,就有的Figure3中的版本。首先是对全图做1*1的传统卷积,然后将channel分成3份,每一份过一遍传统的3*3传统卷积。最后再把结果concat一起。
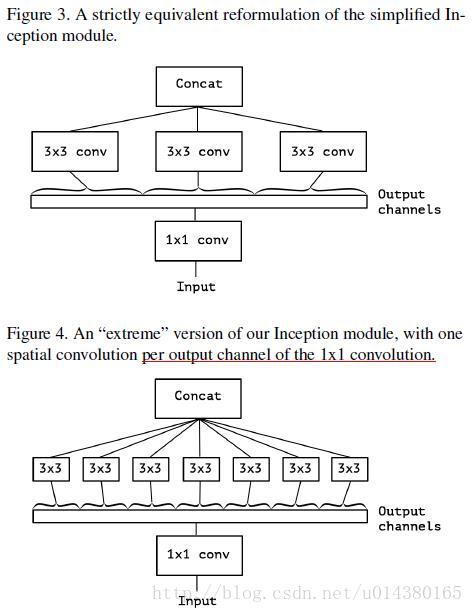
然后,我们每一个channel配一个卷积核,就有了下图。
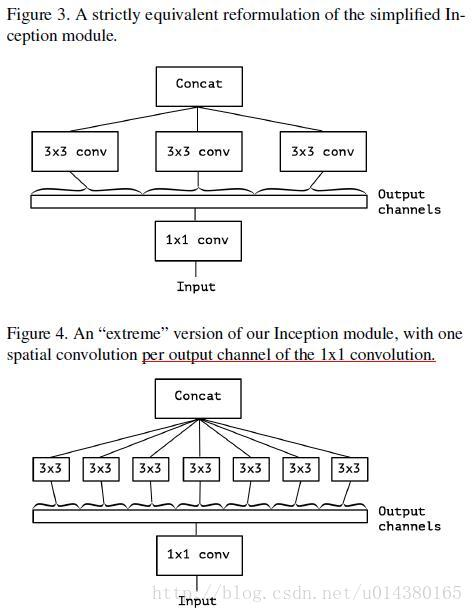
- 2)那么对于Xception而言,它发现figure4的结构和depthwise-separable-convolution的做法很像,只不过一个先1*1传统卷积,再逐个channel做卷积;一个先逐个channel做卷积,然后在做1*1传统卷积。所以google就干脆用了depthwise-separable-convolution的结构。
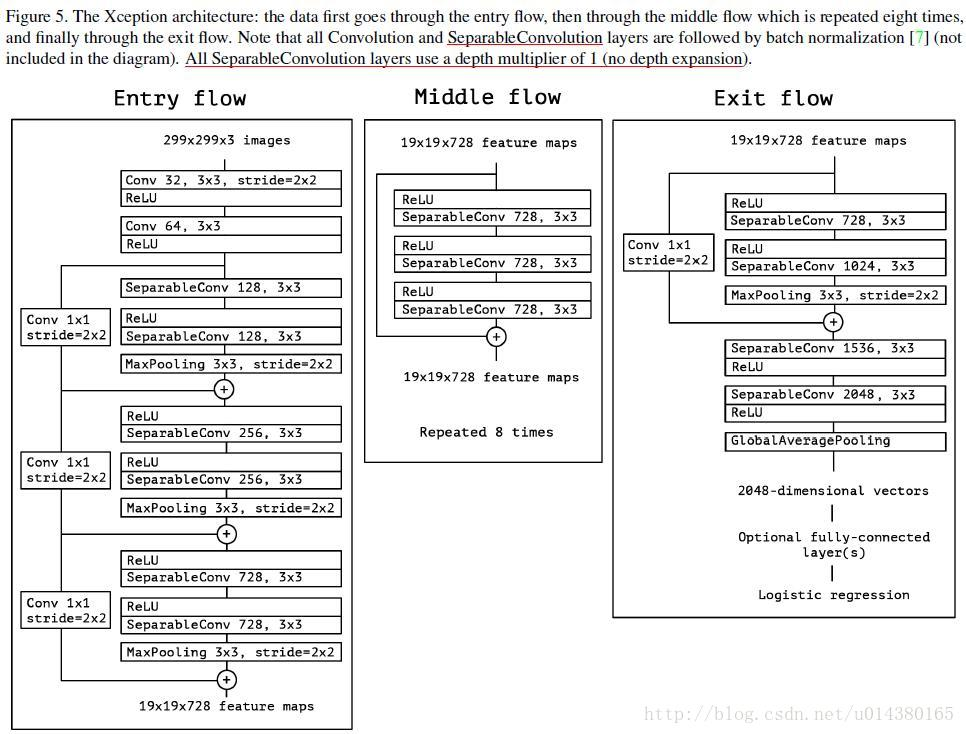
另外,我们发现小块之间的连接采用的是ResNet的残差连接,而不是原来的concat。
总结:
1、Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了depthwise separable convolution,在基本不增加网络复杂度的前提下提高了模型的效果。
2、有些人会好奇为什么引入depthwise separable convolution没有大大降低网络的复杂度,因为depthwise separable convolution在mobileNet中主要就是为了降低网络的复杂度而设计的。
3、原因是Inception的作者加宽了网络,使得参数数量和Inception v3差不多,然后在这前提下比较性能。因此Xception目的不在于模型压缩,而是提高性能。
