@w460461339
2019-02-19T02:51:31.000000Z
字数 7687
阅读 2123
目标检测:RCNN,Spp-Net,Fast-RCNN,Faster-RCNN
MachineLearning
0、前言
之前介绍的各种net,主要都在图片分类的问题上,来区分不同图片分别属于什么类型。
现在有一个更加复杂的任务,在一张图片中找出多个实体,并把它们用框框圈出来。
这个任务就是目标检测,接下来介绍几种目标检测的方法。
综合参考:
https://zhuanlan.zhihu.com/p/34325398
https://www.ctolib.com/topics-122565.html
1、RCNN
参考:
https://www.cnblogs.com/soulmate1023/p/5530600.html
RCNN不是rnn+cnn = =,它是Regions with CNN.
后面说的fast-rcnn,faster-rcnn都是基于它的改进,所以要对她有深刻的理解。
从名字可以看出,它其实继承了滑动窗口的思想,对不同的region用cnn来做识别。
1.1 流程
很多都是基本照搬参考的,这里只是为了更好的记录。
目标问题:
20+1的目标检测问题(1表示的是背景)
基本流程:
1)候选区生成:
1、通过selective search生成若干候选区域(2000个proposal region)
2、对不同尺寸的候选区resize,大小统一到(227*227)2)CNN网络训练,用于提取特征:
3、在另一个图像分类问题上(1000类),训练一个CNN网络(AlexNet+softmax)
4、用之前训练好的模型,接着在我们resize后的proposal region上训练,得到模型。3)接SVM进行分类再训练
5、训练完成后,把CNN后面的全连接层(也就是softmax)去掉,然后分别和20个svm接在一起。
6、在用resize的数据训练一遍CNN+SVM,得到每个region属于每一个类别的得分。4)非极大值抑制与微调
7、对这些region做一个非极大值抑制,抑制那些得分太低的窗口。
8、利用之前标注过的物体的精确位置和现在的识别出来的位置,训练一个回归器,微调一下现在的窗口。
整体思路就是,利用CNN作为特征提取的模型,然后用SVM做分类,之后利用非极大值抑制和回归器对窗口大小做微调。
1.1.1 Selective Search
使用Selective Search(选择性搜索)方法从一张图片中生成许多小图,Selective Search是先用过分割手段将图片完全分割成小图(小图生成途径1),再通过一些合并规则,将小图均匀的合并,这是合并的小图相比原图还是小图(小图生成途径2),这样合并若干次,直到合并成整张原图,至此,将所有生成小图的途径过程中的小图全部输出,就产生了region proposals, 原作者很形象的说道:
例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。
不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
这里的a,b,c,d,e,f,g,h,ab,cd,ef,gh,abcd,efgh都是region proposals。这样的小图生成策略就叫做Selective Search。为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。在一个颜色空间中,使用上述四条规则的不同组合进行合并。所有颜色空间与所有规则的全部结果,在去除重复后,都作为候选区域输出。作者提供了Selective Search的源码。
selective search论文:
https://www.koen.me/research/selectivesearch/
1.1.2 图片resize
首先解释下图片为什么要resize,
按道理CNN的输入是不要求尺寸统一的,只不过这样CNN的输出大小也不一样了;而CNN后面跟了一个softmax(全连接),全连接必须要求输入统一,所以CNN跟着没办法只能要输入统一尺寸了。
1)各项异性的resize方法:别的不说直接resize。
2)各项同性的resize方法:
1、先把region的框resize到目标大小(227*227),超出部分用没超出部分的均色填充,然后再截下来。
2、先把region切出来,然后用区域内的均色填充周边,直到满足要求(227*227)。3)另外还有padding。padding的想法就是,我原来region,可能还会需要它边界以外的其他信息,那么就别bb,在把区域外的信息一起拿回来就好。下图白框就是黑框加了padding=8之后的效果。加完padding之后,在从各项异性或者各项同性之间选一下。

最后,貌似是各项异性+padding16效果比较好。
(我觉得这里证明了,很多时候原来的proposal region包含的信息不够,需要在往外面多看一点像素才好,而同性的方法1,又看的太多了,引入了太多的噪声。)
1.1.3 预训练&调优训练——CNN
- 1)预训练
使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号,学习率0.01。
网络结构是基本借鉴Hinton 2012年在Image-Net上的分类网络Alexnet,略作简化。这样避免了直接从随机初始化的参数进行训练,使得网络开始之前参数都是经过训练过的参数,该技巧可以大大提高精度,这种方法叫有监督的训练方式(也称为迁移学习)。此网络提取的特征为4096维,之后送入一个4096->1000的全连接(fc)层进行分类。
相当于拿了一个训练好的网络来作为初始模型。
2)微调
网络结构同样使用上述网络,最后一层换成4096->21的全连接网络,数据集换成这批数据集,即使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。考察一个候选框和当前图像上所有标定框(人工标注的候选框)重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
问题1:为什么可以有这样的预训练-调优训练的操作?
答:因为RBG大神说了,通过他们的实验得出,一般的CNN网络(eg,S1-S5,F6,F7),前5层是用于特征提取的,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。所以这里可以将后面的层修改用于对象检测。 学习率0.001,每一个batch包含32个正样本(属于20类)和96个背景的负样本。
1.1.4 SVM
当CNN训练完成之后,我们把CNN最后的全连接层(softmax)拆了,拿到CNN提取出来的特征向量(4096维),作为输入,去训练20个SVM二分类器。
我们都知道SVM分类器是需要正负样本的,但这里由于负样本远远大于正样本的数量,所以采用hard negative mining的方法,其中,正样本就是原图中真正标定bounding-box的样本,而负样本是通过考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本。
问题2:为什么不要softmax,而选择另外去训练20个SVM?
答:
这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN-softmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding-box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding-box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。
总的来说,就是加上一个SVM分类器,识别精度更高了!
1.1.5 框框去除
1、当从一张图中,我们得到了2000个proposal region。
2、当从CNN中,我们把这2000个proposal region转化成了2000*4096的向量。
3、当从每一个SVM,我们都可以得到一个2000*1的向量,那么20个SVM就会有2000*20的向量
第三句解释一下,我们有一个SVM是用来判断区域内有没有狗的(一共有20个这样的SVM,用来判断各种有没有),输出的是一个0~1内分数,这样2000个区域进来,每个区域用一个4096的向量表示,输出是对每个区域的打分,这样20个SVM,就有20个这样的打分= -。
然后,我们有了一个2000*20的向量。
最后将得到所有region proposals的对于每一类的分数,再使用贪心的非极大值抑制方法对每一个SVM分类器类去除相交的多余的框。
非极大值抑制法:
参考:
https://www.jianshu.com/p/714348edb2a8
https://blog.csdn.net/shuzfan/article/details/52711706
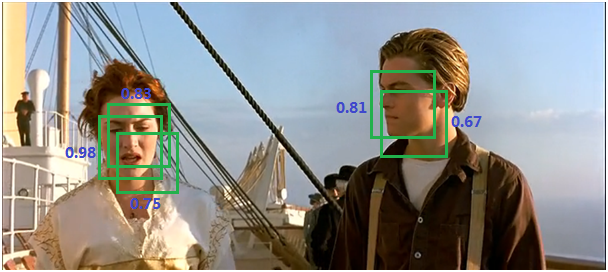
对于上图,有5个框都检测到了人脸,我们按照置信度从小到大排序,A,B,C,D,E。
1)从置信度最大的E,我们找到和它重合度(IoU)大于阀值的其他候选框(比如是D,B),然后删除,得到下图。此时我们发现,Jack脸上的框没有减少,而Rose脸上的框只有1个了,去除了冗余!
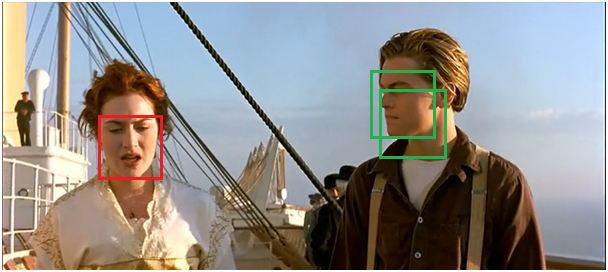
2)此时还有A,C两个框没有处理,那么重复1的过程,拿到C,判断A和它的IoU,然后删,得到最后的图。
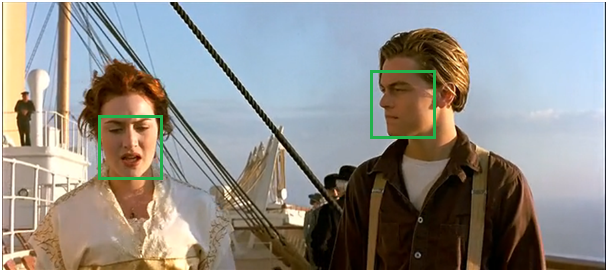
非极大值抑制法的作用,是能够在去除冗余窗口的情况下,不会遗失同类多个实体的信息。
1.1.6 位置精修
回归器
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。(L1嘛)
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
1.2 问题:
1)问题1:速度太慢:
1、每个图片要用提取2000个候选区。
2、每个候选区都要经过CNN来处理。2)问题2:模型太复杂:
1、先是预训练的CNN,然后又是SVM,最后还要精调,神烦。3)问题3:信息丢失:
1、region图片需要resize,怎么着都会丢信息= -。
2、Spp-Net
参考:
https://www.ctolib.com/topics-122565.html
https://blog.csdn.net/v1_vivian/article/details/73275259
https://blog.csdn.net/chaipp0607/article/details/78446708
Spp-Net的全名是Space pyramid pooling-net,空间金字塔池化,可以解决问题:信息丢失问题&每个region都要过CNN。
因为有了Spp-Net之后,就不需要在把图resize之后再输入了,不同尺寸的图丢进去,输出的都是相同维度的特征向量。同时,我们可以直接对原图做CNN,然后把区域映射一下就完了,不需要在每个都做。
2.1 如何解决CNN输出不统一问题
原理图
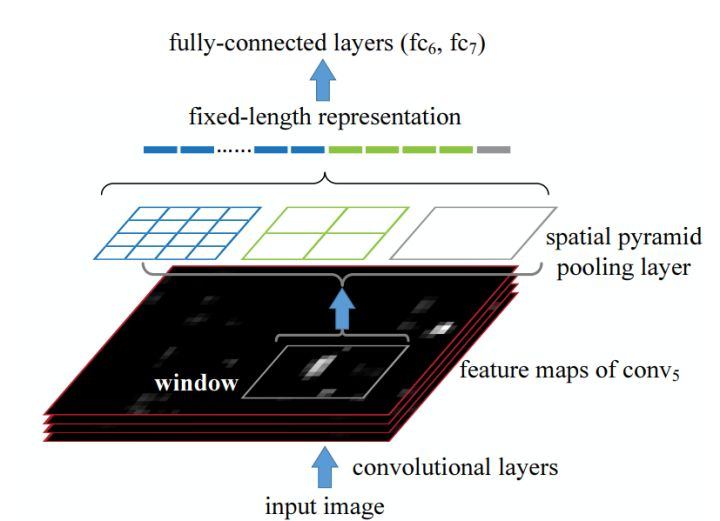

我们假设上面马的图片就是我们提取出来的特征图(feature map)。
然后我们用不同的网格来切割(4*4,2*2,和1*1),然后在每个区域里面采用最大池化,最后得到(16+4+1)个点,拼接起来,得到一个21*1的向量,作为统一的输出。
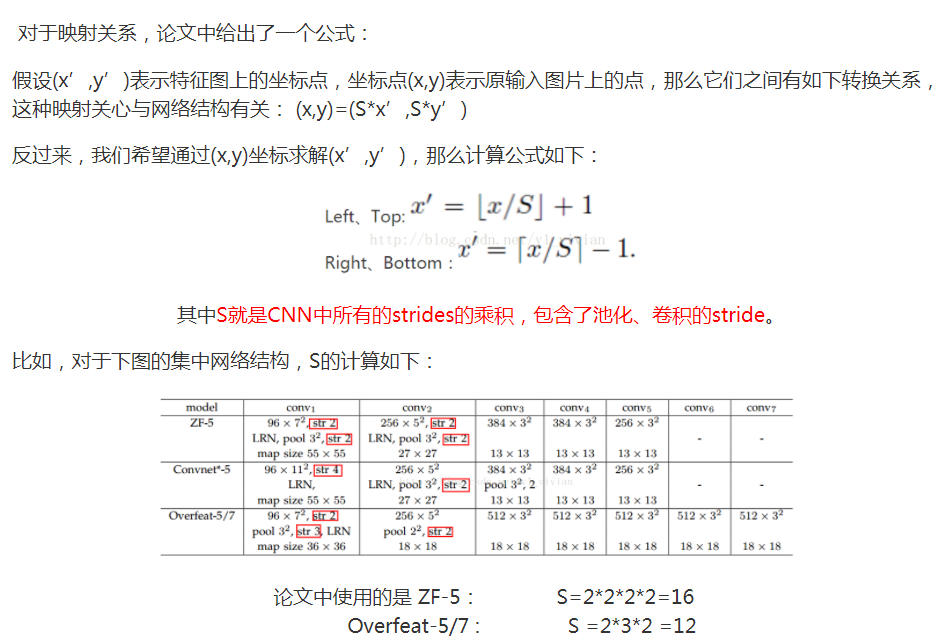
具体怎么实现的,呃,根据卷积之后的尺寸s=(原尺寸-核宽度+2*padding)/strid+1,这里把核宽度和步长都变成动态的:
在我们这里,n可以是4,2,1。

2.2 如何将原图上的region映射到feature map上
首先说一下这里为什么要介绍这个:
SPP是一种方法,可以加在任何地方,然后SPP-NET可以认为是把SPP加载了RCNN上。
RCNN中需要对每个proposal-region进行resize之后在进行特征提取,但是SPP-NET中不用,我得到了全图的feature-map之后,由于相对位置不变,原图上的一块区域,对应的也是feature-map上的一块区域,然后对这块区域街spp,得到固定长度的输出,后接分类器就行了。
类似于计算感受视野的操作,如果feature-map一个点,所对应的感受视野(在原图上的区域)包含了某个点,那么就完成了原图上某一个点到feature map上一个点的映射(一般用中心)。
2.3 Spp-Net整个计算过程
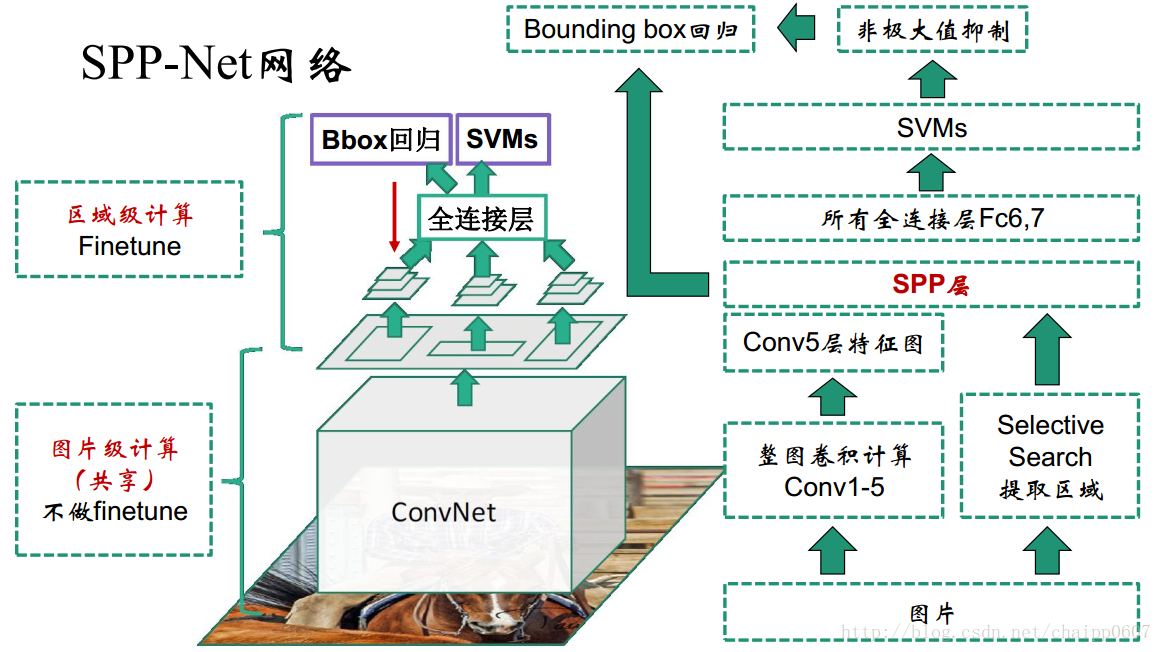
图中可以看到,在feature-map上找到proposal-region后,网络会把对应的区域“挖”出来,然后送到spp中,得到统一尺寸的输出,然后丢到SVM里面计算啥的。
2.4、迁移学习和fine-tune(微调)
https://blog.csdn.net/AUTO1993/article/details/78677812
https://blog.csdn.net/lonely_dark_horse/article/details/53896837
https://www.zhihu.com/question/49534423
https://datascience.stackexchange.com/questions/22302/what-is-the-different-between-fine-tuning-and-transfer-learning
感觉迁移就是拿东西过来,换掉最后的输出,直接用;
fine-tune就是拿东西过来,换点最后输出,然后在自己数据集上训练。
这个还要继续看一看呀。
3、Fast-RCNN
参考:
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
http://closure11.com/rcnn-fast-rcnn-faster-rcnn%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BA%8B/
https://www.cnblogs.com/skyfsm/p/6806246.html
http://www.cnblogs.com/soulmate1023/p/5557161.html
有一篇文章说Fast-RCNN是在之前Spp-Net的基础上捡漏,呃,看了下后,觉得差不多。
首先回顾了Spp-Net解决的问题:
1、Spp层,解决了输入尺寸不统一的问题。
2、region映射方法,解决的重复提取特征的问题。
而Fast-RCNN看到了Spp-Net漏掉的一些问题:
1、真的需要三层Spp嘛?
2、SVM分类器真的靠谱嘛?
3、region框回归调优需要单独分开嘛?
3.1 RoI VS Spp
Spp-Net中,采用的是4*4,2*2,1*1三层的金字塔池化,然后把数据拼接在一起,得到一个长度为21的向量。
之前看过一篇文章,是说这样三层的金字塔是否需要,因为4*4的空间池化中,就已经包含了后面2*2以及1*1的所有信息。
Fast-RCNN中,就没有采用这样的结构,而是用一个7*7/8*8的池化,来把每一个区域都变成一个49/64长度的向量。

3.2 SVM or softmax
之前给了理由说,SVM的准头更高,所以采用SVM来作为最后的分类器。
但是这里就不用了,直接采用softmax来作为分类器,节省空间。
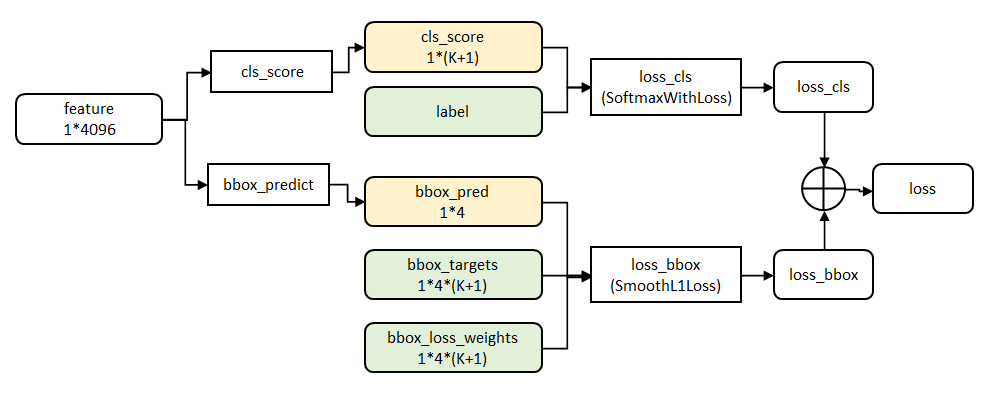
3.3 单独reigon回归 or 整合
RCNN中,使用SVM来对region做分类,然后另外有一个回归器对region框做微调。
现在Fast-RCNN把这个回归一起整合到CNN框架里面,并且把回归器的loss和分类器的loss加起来,作为最终的loss,以此来对网络进行调整。
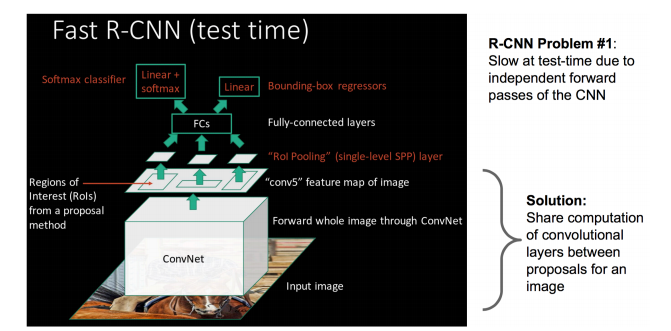
3.4 结构
4、Faster-RCNN
参考:
https://blog.csdn.net/qq_17448289/article/details/52871461
https://zhuanlan.zhihu.com/p/24916624?refer=xiaoleimlnote
https://blog.csdn.net/u013126125/article/details/52859361
这篇讲的比较细:https://blog.csdn.net/zziahgf/article/details/79311275
我们看看FAST-RCNN都干了点啥:
1、Spp层有冗余,我们只要一个RoI
2、Softmax凭什么比svm差,我们不要svm,要softmax。
3、既然用了softmax,那么就把回归器一起放进网络吧。
那么Faster-RCNN其实又在捡Fast-RCNN的漏,它着重解决一件事情:
1、能不能把proposal region的选取也融入到网络中,而不用selective search。
4.1 RPN网络
参考:
https://blog.csdn.net/u011534057/article/details/51247371
呃,能把区域选择融入进CNN的方法就是RPN网络。
- 1)直接把整张图片(600*1000)输入cnn,最后得到40*60feature map,256个。
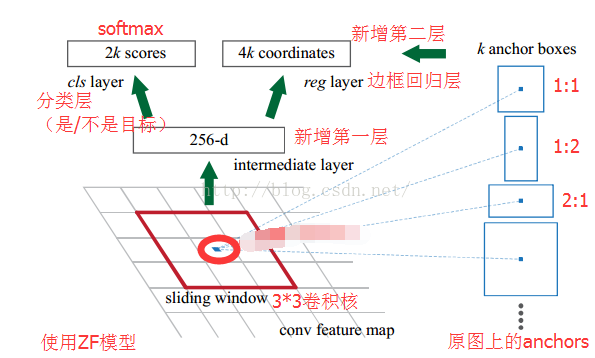
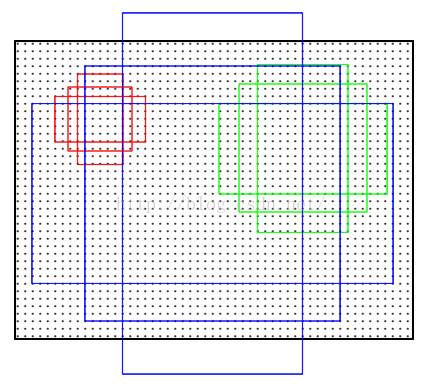
2)如上图所示,对每一个feature-map,采用3*3的窗口,每个窗口的中心点,映射回原图,然后按照三种面积 ,三种长宽比来在原图上生成proposal region。
下图为了演示方便把3种面积的图的中心画的分开了,实际上,对于一个3*3窗口而言,这9个region的中心应该在一块。
然后我们默默的把这些框的大小和中心点记在心里。
- 3)每个滑动窗口不仅有9个区域,还会采用池化,提取其中心点,这样,这9个区域的特征我们就可以用这个256*1的向量来表示了。
1、然后在接上一个1x1x18的卷积核,就可以输出18=2x9个评分(9个anchor,每个anchor有两个评分,代表前景,背景的confidence)。【注意,这里没有分类,没有对类别进行分类!】2、在256维特征后面接1x1x36的卷积核就可以得到36个值(9个anchor,每个anchor是4个值,分别代表中心点坐标,宽,高值的修正)。3、在有了修正之后,我们就可以把它和之前记住的框框位置合在一起,得到最终的框框位置
4)总结一些,RPN网络输出了两个内容:
1、每个框是前景还是背景。
2、每个框的位置修正量。加之定好的anchor,就可以得到框框的最终位置。
4.2 FAST-RCNN网络
之后,需要用FAST-RCNN网络来做分类和最后的精修。
两个网络需要有一个模型融合的操作…
