@w460461339
2018-08-15T08:59:32.000000Z
字数 2061
阅读 1960
目标语义分割:FCN,SegNet/DeconvNet,DeepLab
MachineLearning
0、备注
下面主要分析FCN和DeepLab这两个。SegNet和DeconvNet简单分析。
参考:
https://blog.csdn.net/yuanlunxi/article/details/79430493
1、FCN(全卷积网络)
1.1 FCN
FCN参考:
https://blog.csdn.net/u010548772/article/details/78582250
http://www.cnblogs.com/gujianhan/p/6030639.html
卷积网络的拓扑结构:
https://blog.csdn.net/zhongkeli/article/details/51854619
卷积网络中卷积核的理解:
https://blog.csdn.net/sscc_learning/article/details/79814146
关于卷积核,这里简单说一下:
1、输入是5*5*3的图片。
2、两个3*3的卷积核A和B。
3、那么,对于卷积核A,它在输入图片的每个channel上,都会有一个用相同的参数进行卷积,然后将每个channel的结果来加,得到这个卷积核的输出:3*3*1.
4、卷积核B同理,所以总共的输出是3*3*2。
1)通过卷积网络的拓扑结构,我们其实可以发现,卷积神经网络其实就是普通神经网络使用了局部连接和参数共享,因此,卷积层和全连接层是可以相互转换的。
2)考虑AlexNet或者VGG之流,它们的操作是在CNN+Flatten+全连接+softmax。在Flatten的时候,会丢失大量的空间信息,(当然它们也不需要,因为是全图的分类问题)。
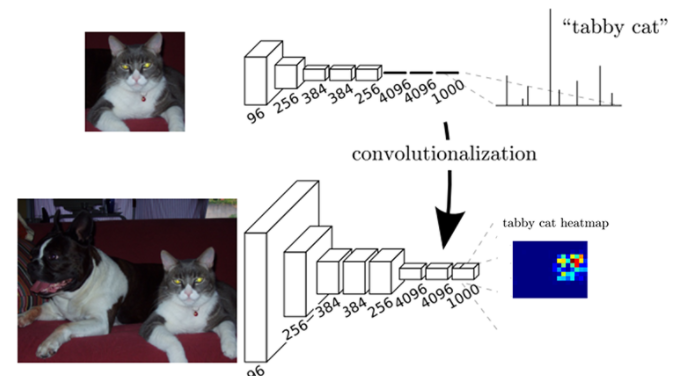
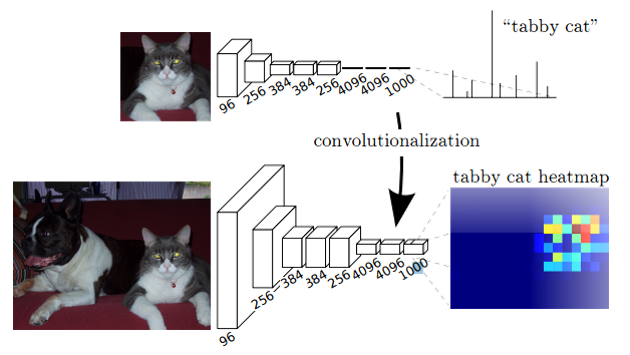
3)在FCN中,将最后几层全连接层换成对应的卷积层,不出意外会得到一个1*1*1000的feature-map。这个和全连接的最终输出的长为1000的向量相同。
4)但是!但是!,如果我们把最终的输出变成2*2*1000的feature-map。由于用了卷积层代替全连接,最终输出上的每个像素点都可以和原图的一个感受视野对应。而最终输出左上角对应的1*1*1000的向量,就对应原图中左上角窗口中的分类。
5)通过这种方式,可以实现对空间信息的保留,从而实现结果和滑动窗口的对应。
1.2 上采样
参考:
https://www.jiqizhixin.com/articles/deeplab-v3
别忘了我们的目的是对图像进行语义分割。
因此需要有一种办法将图像恢复到原大小。
1)一种简单的想法就是之前的卷积层都用stride=1,padding=same的方式进行卷积,这样输入输出尺寸不变,从而就不需要“恢复”,但这样的计算太大,内存吃不消…
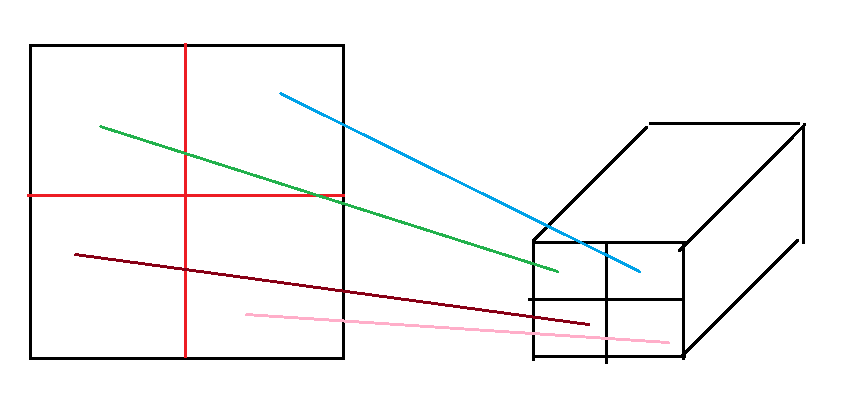
2)这里就需要上采样了。简单来说,我们将5*5变成3*3,需要用3*3的kernel以及strides=1,我们用相同的kernel以及strides,对一个3*3的图像做padding,然后将这些kernel以及strides应用起来,就可以得到我们的5*5的图了。 具体见下面连接。
https://github.com/vdumoulin/conv_arithmetic
- 3)这样,我们对于一个输入,利用传统CNN提取图像特征,然后使用上采样将数据恢复相同大小。
1.3 CRF-条件随机场
CRF就是用作对每个像素进行分类。
具体我也看不太懂,下面给一下学习链接。
参考:
https://blog.csdn.net/qq_28743951/article/details/60465524
https://blog.csdn.net/redfivehit/article/details/76609898
https://download.csdn.net/download/nut__/10233790
1.4 总结
总体来说,这是一种encoder-decoder架构。
利用传统的CNN提取特征(encoder),然后通过上采样恢复原大小(decoder),之后结果用CRF进行分类。
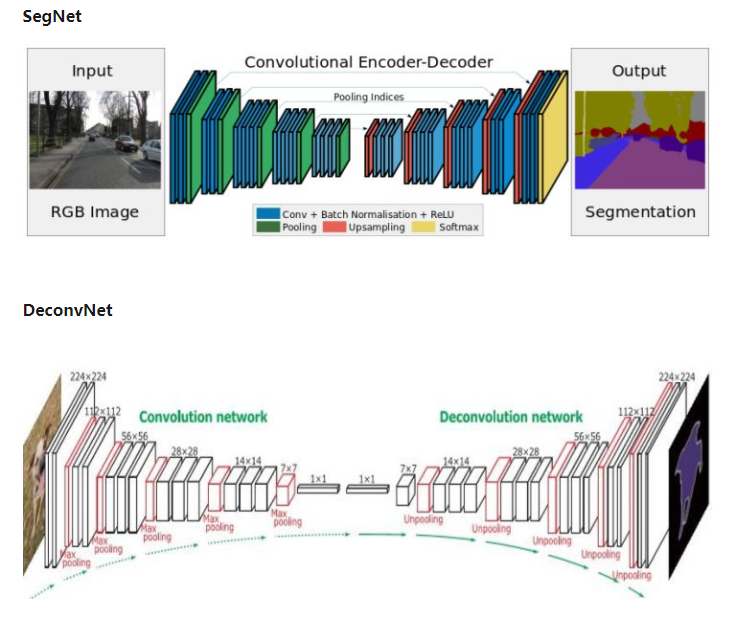
2、SegNet/DeconvNet
结构其实和FCN差不多,下面就上一下结构图就好了。
3.DeepLab
之前说过,语义分割的一大问题就是最后的输出是需要和原图等大小的。
而传统CNN(卷积+池化)的操作使得feature map的尺寸不断缩小,是为了:
1、降低计算量。
2、让高层的filter获得更广的感受视野。
3、获取多尺度下的特征。
SegNet以及之前的FCN,采用的是类似encoder和decoder的结构,先采用传统的CNN获取信息,然后用上采样+线性插值的方式将图恢复到原图大小。
1)而DeepLab则采用另一套做法,它对卷积核进行了修改,采用带洞卷积。
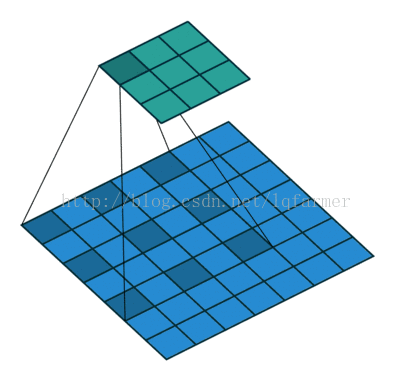
2)基于带洞卷积,它把这个和SPP-net结合,形成了带洞金字塔结构,最终deeplab v3的结构如图:
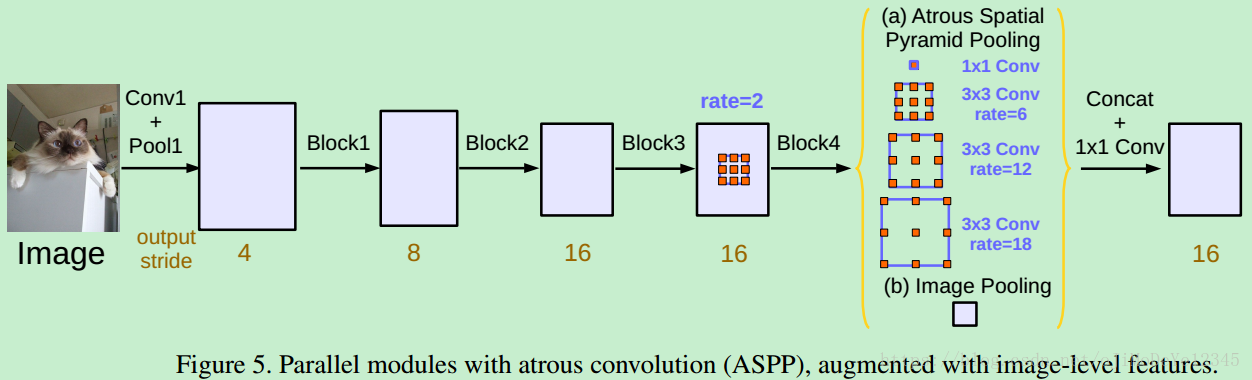
3)最后用DenseCRF,全连接CRF进行像素级别的分类,完成整体的图像语义分割。
