@xtccc
2016-03-24T07:04:05.000000Z
字数 11612
阅读 6524
Architecture

Cassandra
参考链接:
目录
1. Cassandra特点
- 分布式的行存储数据库
- 自动的数据分布
- 可定制的数据副本
- 可以线性扩展
Cassandra是一个分布式的数据库,由多个节点构成,数据就分布地存储在这些节点上。集群的节点之间每隔1秒钟进行信息交换。每个节点通过它的sequentially written commit log来捕捉写操作,以此实现数据的持久性。然后,数据被索引并写入到一个称作 memtable 的内存结构(类似于 write-back cache )。一旦 memtable 满了,它的数据就被写入到磁盘上的一个 SSTable 文件。所有的写操作都会在集群中自动地实现partitioned以及replicated。一个被称为 compaction 的进程会周期性地压紧SSTables,以删除陈旧数据及tombstone(数据是否应该被删除的标志)。
Cassandra是一个面向行的(row-oriented)数据库。客户端可以连接到集群中的任意一个节点,并通过CQL来访问数据。当客户端连接到某个节点并发起请求时,该节点就为该客户端的操作充当 coordinator 的角色。基于集群配置的partitioner以及replication strategy,该coordinator将决定应该将请求发送给环中的哪些节点。参考 Client Requests 。
2. 重要概念及组件
Node
存储数据的地方Data Center
Nodes的集合。Data center可以是物理的,也可以是虚拟的。不同的workloads应该使用各自的data centers,数据的冗余复制也是由data center设置的。根据数据的副本因子,数据可以被写入到多个data centers中。Cluster
一个cluster可以包含一个或者多个data centers。Gossip
一种端到端的通讯协议,它可以发现并共享关于集群中其他节点的位置和状态信息。Seeds
Seed是Cassandra中较为特殊的一类nodes,它的作用是在Cassandra启动时帮助寻找集群,或者可以说seeds是Gossip网络中的hubs。借助于seeds的作用,每个节点都可以快速发现其他节点状态的变化。参考 FAQ 以及 stackoverflow。Partitioner
Partitioner决定怎样将数据分布到cluster的各个节点上,以及数据的第一个副本放在哪个node上。在最简单的情况下,partitioner可以是一个hash function,它计算出partition key的token。每一行数据都由一个partition key来唯一地标记,并根据token的值分布在集群中。Murmur3Partitioner 是新建Cassandra Cluster的默认分区策略,它在大部分情况下都是一个很好的选择。用户必须设置partitioner,并为每一个node配置 num_tokens 值 —— 它由系统的硬件性能决定。如果没有使用虚拟节点(vnodes),则可以设置 initial_token 来代替。
Tokens
参考 Cassandra Wiki,How to scan the local token range of a table ,Calculating tokens。
Replication Factor
副本因子指row在集群中的副本数量。对于某个row,它的所有副本都具有相同的地位 —— 不存在master replica或者primary replica。用户需要为每一个data center设置replication factor。Replica Placement Strategy
对于大多数情况下的部署,推荐采用 NetworkTopologyStrategy 。在创建keyspace时,用户必须为它定义replica placement strtegy以及replication factor。
Snitch
Snitch决定了nodes属于哪些data centers以及racks,以此来告诉Cassandra关于网络拓扑的信息,实现Requests在集群中的高效路由。Replication Strategy将基于Snitch提供的信息来决定如何放置数据副本(尽量将多个数据副本放置在不同的机架上)。我们需要在配置文件cassandra.yaml中为每一个节点定义snitch。默认的 SimpleSnitch 不能识别关于data center以及rack的信息,因此它只适合单数据中心的部署。对于生产环境,推荐 GossipingPropertyFileSnitch ,因为它定义了节点的data center和rack,并使用 gossip 将该信息传播到其他节点。
注意: 如果改变了snitch,则我们可能需要执行额外的操作,因为snitch会影响数据副本的位置,详见 Switching snitches。
关于Snitch还有很多的内容和配置,详情请参考 Snitches。
3. 数据分布及复制
Cassandra中的数据是通过Table来进行组织的,并且由一个primary key唯一地标识,同时primary key决定了该数据(row)存储在哪个节点上。影响数据复制的因素包括:
- Virual Nodes - assign data ownership to physical machines
- Partitioner -
- Replication Strategy - 决定了每一行数据(row)的副本数
- Snitch - 定义了拓扑信息,replication strategy根据它来决定数据副本放在哪里。
Cassandra在进行数据复制时,是以partition为单元进行的。
3.1 Consistent Hashing
Consistent hashing allows distributing data across a cluster which minimizes reorganization when nodes are added or removed. Consistent hashing partitions data based on the partition key.
关于partition keys和primary keys,请参考Data Modeling Example
其实,这与rows在HBase中的分布是十分类似的。在HBase中,一个RegionServer负责存储rowkey在某个范围内的rows。在Cassandra中,每一个row都有对应的partition key,Cassandra会为每个partition key计算出一个hash value,Cassandra集群中的一个节点负责存储整个数据集的某个子集,这个子集中的所有rows的hash value会落在某个范围内。
3.2 Virtual Nodes
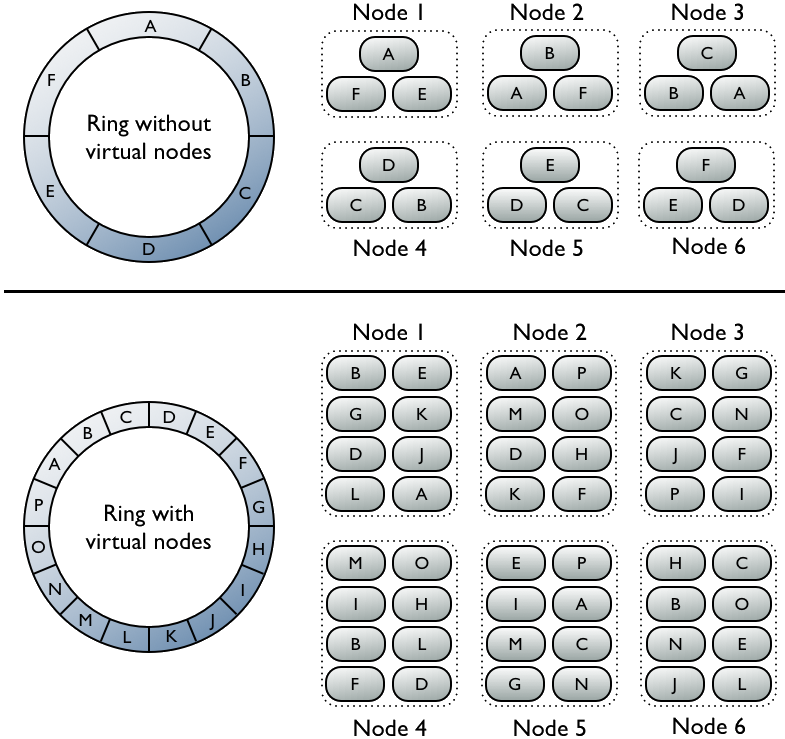
在1.2版本之前,必须为集群中的每一个节点计算出一个令牌,并将计算出的令牌赋给该节点。令牌决定了该节点在环中的位置,以及它要负责存储的数据(根据它的hash value)。从1.2开始之后的版本,一个节点允许有多个令牌 —— 该机制被称为virtual nodes(vnodes)。vnodes机制允许每个节点拥有多个small partition ranges。
Virtual v.s. Single-Token Architecture
The top portion of the graphic shows a cluster without vnodes. In this paradigm, each node is assigned a single token that represents a location in the ring. Each node stores data determined by mapping the partition key to a token value within a range from the previous node to its assigned value. Each node also contains copies of each row from other nodes in the cluster. For example, range E replicates to nodes 5, 6, and 1. Notice that a node owns exactly one contiguous partition range in the ring space.
The bottom portion of the graphic shows a ring with vnodes. Within a cluster, virtual nodes are randomly selected and non-contiguous. The placement of a row is determined by the hash of the partition key within many smaller partition ranges belonging to each node.
3.3 Data Replication
SimpleStrategy
第一个数据副本被放置在由partitioner决定的节点上,其他数据副本则被放置在顺时针方向的下面若干个节点中。该策略只能用于单数据中心。对于多数据中心,必须使用NetworkTopologyStrategy。
NetworkTopologyStrategy
如果要将集群部署在多个数据中心,则要使用这种策略,它指定了每一个数据中心里放置多少个数据副本。对于某个给定的数据中心,该策略会以顺时针的次序找到环中第一个属于其他机架的节点,然后将数据副本放到该节点上。
一个数据中心应该设置多少个副本?
2个或者3个均可。
3.4 Data Consistency
参考 Data consistency 和 Configuring data consistency。
数据一致性是指:Cassandra的一个row的多个数据副本是否是最新的,以及同步程度有多大。Cassandra通过提供 可调节一致性(tunable consistency) 扩展了 最终一致性(eventual consistency) 的概念。
可调节一致性指的是:对于任一个给定的read或者write请求,由客户端决定被请求的数据应该满足怎样的一致性。
即使我们设置了一个较低的consistency level,Cassandra还是会将数据写入到所有的副本中(包括别的data center)。一致性级别的作用是决定有多少个数据副本将向客户端响应“write success”。一般来说,客户端指定的一致性级别会稍低于keyspace的副本因子数。这种做法保证了在写入数据时,即使某些数据副本崩溃了或者无法返回“write success”响应,coordinator也可以报告写成功。
Read Consistency Level 指定了在向客户端返回数据之前,有多少个数据副本必须响应该读请求。这篇CQL文档解释了怎样使用cql tracing来比较consistency levels。
3.5 Partitioners
Cassandra提供了三种partitioners
Murmur3Partitioner : 这是默认的partitioner,它基于MurmurHash hash values,为partition key创建一个64位的hash value(范围在 ~ 之间),以此将数据均匀地分布在集群中。Murmur3Partitioner是比RandomPartitioner更快的哈希方法,但是它只能被用于新建的集群——我们不能改变一个已有集群的partitioner。
RandomPartitioner : 基于MD5 hash values(范围在 ~ 之间),以此来分布数据。
ByteOrderedPartitioner : 按照key bytes的字典序来分布数据,这使得我们可以很简单地对rows进行range scan。
使用Murmur3Partitioner或者RandomPartitioner时,可以通过token function以分页的方式来遍历全部的rows。
相关配置
在cassandra.yaml文件中
- Murmur3Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
- RandomPartitioner : org.apache.cassandra.dht.RandomPartitioner
- ByteOrderedPartitioner: org.apache.cassandra.dht.ByteOrderPartitioner
如果使用vnodes,则不需要计算令牌。否则,必须计算令牌,并赋给cassandra.yaml文件中的initial_token参数。
选用哪种Partitioner?
ByteOrderedPartitioner使得我们可以直接地对rows进行range scan,但是不推荐使用ByteOrderedPartitioner,因为:
- 负载均衡很麻烦,必须基于partition key的分布情况来预估partition ranges。
- 顺序读写会造成 hot spot
- 多表数据不易均衡。如果app有多个表,则不同表的数据分布是不同的。即使partitioner能够适合某个表,它对于其他表的数据很难凑巧也是适合的。
实际上,即使我们不使用ByteOrderedPartitioner,也可以通过table indexes来实现对rows进行range scans。
4. Data Modeling
DataStax Academy 提供了 关于Cassandra Data Modeling的课程,Data model distilled提供了关于CQL的最基本的解释。
Cassandra's data model is a partitioned row store with tunable consistency. Rows are organized into tables; the first component of a table's primary key is the partition key; within a partition, rows are clustered by the remaining columns of the key. Other columns can be indexed separately from the primary key. Because Cassandra is a distributed database, efficiency is gained for reads and writes when data is grouped together on nodes by partition. The fewer partitions that must be queried to get an answer to a question, the faster the response. Tuning the consistency level is another factor in latency, but is not part of the data modeling process.
怎样设计Cassandra中的table?
Notice that the key to designing the table is not the relationship of the table to other tables, as it is in relational database modeling. Data in Cassandra is often arranged as one query per table, and data is repeated amongst many tables, a process known as denormalization (joins are not performant in a distributed system). The relationship of the entities is important, because the order in which data is stored in Cassandra can greatly affect the ease and speed of data retrieval.
4.1 Keys
Partition Key
Case 1: 位于PRIMARY KEY定义中的第一个column作为partition key;
Case 2: 如果是复合主键,则可以是构成主键的多个列(称为composite partition key)。
Compound Primary Key
复合主键由一个partition key和若干个其他columns(称为clustering columns)构成。partition key决定了该row存储在哪个节点上,而clustering columns决定了每个partition内的数据是怎样聚集(clustering)的。Clustering为一个partition内的数据进行排序。
例1: Simple Primary Key
create table t1 (id uuid,name text,age int,PRIMARY KEY (id, name));
id是t1的partition key, name是t1的clustering column。id作为Parition,决定了rows在整个集群中是怎样分布的,而name作为clustering column,决定了一个partition中的数据的存储顺序(升序)。
例2: Composite Partition Key
CREATE TABLE Cats (block_id uuid,breed text,color text,short_hair boolean,PRIMARY KEY ((block_id, breed), color, short_hair));
block_id和breed是Cats的composite partition key,color和short_hair是Cats的clustering columns。对于两个columns,如果它们的block_id相同但breed不同,则这两个columns将被存储在不同的节点上;如果block_id与breed都相同,则它们将被存储在同一个节点上。
4.2 Data Types
Collections
Cassandra支持的集合数据类型:set, list, map
Primitive Types
User-defined Types
参考 Using a user-defined type
5 Database Internals
5.1 Storage Structure
Cassandra使用了类似于LSM-Tree的存储结构,而不是传统关系型数据库使用的B-Tree。 由于在分布式系统中,read-before-write会带来很大的问题,因此Cassandra永远不会re-write或者re-read已有的数据,也不会在原地更新rows。
5.1.1 Write Path
Cassandra实现数据写入时所经过的路径:
Logging data to commit log and memtable
当我们向Cassandra中写入数据时,数据首先被保存到内存中的memtable和磁盘上的commit log;Flushing data from memtable
当memtable中的数据达到阈值后,其中的数据(包括index)会被放入一个队列中等待写入磁盘(flush to SSTable);如果队列已满,那么后续的写请求都会被阻塞,直到flush成功完成。我们可以通过nodetool flush命令来手动触发flush。Storing data in SSTables on disk
每个table都有对应的memtables和SSTables,其中SSTables是不可修改的(当memtabl is flushed之后); 因此,一个partition往往会被存储在多个SSTable files中。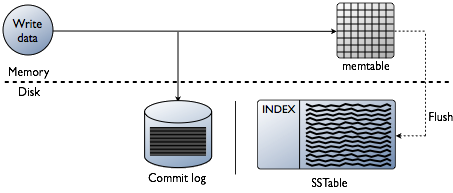
Compaction
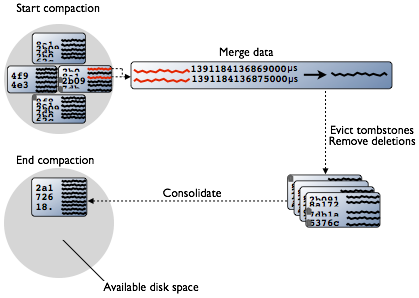
当inserts/updates发生时,Cassandra不会重写/修改rows,而是为欲插入/更新的数据打上新的timestamp版本,然后将其写入到另一个SSTable。在删除数据时也不会原地将数据删除(因为SSTable是immutable),而是使用tombstone将row标记为deleted。Compaction根据partition key将每个SSTable中的数据合并起来(每个SSTable中的数据按照partition key都是有序的),合并时会选择timestamp最新的数据。在删除deleted数据后,compaction会将多个SSTable files合并成一个文件,然后旧的SSTable files将被从磁盘上删掉。
5.1.2 Hinted Handoff Writes
5.2 About Reads
Cassandra必须将 active memtable 和 potentially multiple SSTables 中的数据结合起来,才能满足read request。在处理read request时,Cassndra首先会检查Bloom filter。每一个SSTable都有一个对应的Bloom filter,它的作用是在磁盘上进行真正的检索之前,检查自己数据是否会包含目标partition。后续的动作,请参考 这里 。
6 老内容
Column
1个column是1个key-value形式的键值对,以及它被最后更新时的timestamp。在server端,columns are immutable。Cassandra中的column是通过interface org.apache.cassandra.db.IColumn定义的
1.2.2 Column Family
1个family包含了若干的rows,这些rows有相似但是不完全相同的column sets,这与HBase中的family的概念不同。不同的column families在磁盘上会作为不同的文件进行存储。
Cassandra可以看作是schema-free,因为尽管column families是固定的,但是columns不是固定的 —— 我们可以随时给任意column family添加任意的column。
Column family有2个属性:
name
column family的名字comparator
当我们发起查询时,Cassandra会将columns排序后返回给用户,而comparator value则决定了怎样对columns进行排序 —— 例如根据 long、byte、UTF8或者其他的排序规则。
1.2.3 Super Column
一个super column也是一个key-value形式的键值对,其中key是它的名字(byte array),value是它存储的sub-columns(这些sub-columns以map的形式存在,其中key是column names,values是columns)。
对于普通的column families(这是缺省的),可以将type设置为Standard;对于super column family,可以将type设置为Super。
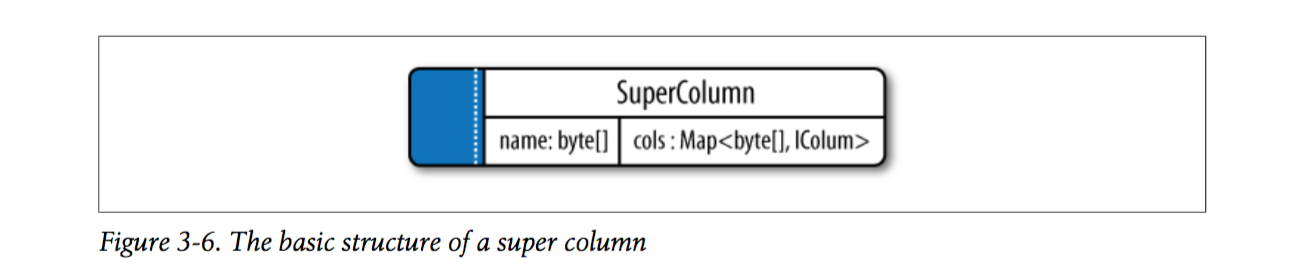
为了使用super column,需要将column family的类型定义为 Super 。
1.2.4 Super Column Family
如果想要创建一组相关的columns,即再增加维度,那么通过super column family来实现。
1.2.5 Timestamp
每个column都可以有一个timestamp,row没有timestamp。timestamp不是能够自动被更新的属性,必须由client提供。
1.2.6 Row Key 与 Primary Key
每一个row都有自己的rowkey,rowkeys之间是按照byte array进行排序的。
table由自己的primary key,它可以是simple key,也可以是 compound key。
Table primary key的第一部分是partition key。
1.3 Cluster
“cluster”是Cassandra中最外层的概念,cluster也称为“ring”,因为Cassandra在将数据分配给cluster中的节点时,是按照ring的方式安排数据的。
1.4 Keyspace
Keyspace是作用是定义数据怎样在各节点上进行复制冗余,它有以下的属性:
- Replication Factor
这是1条row的副本数量,每个节点上放置1个副本。
- Replica Placement Strategy
这决定了1条row的若干个副本数据在ring中怎样放置,即1个节点能够被分配哪些keys的副本。
- SimpleStrategy (rack-unaware strategy)
- OldNetworkTopologyStrategy (rack-aware strategy)
- NetworkTopologyStartegy (datacenter-shared strategy)
- Column Family
A column family is a container for an ordered collection of rows, each of which is itself an ordered collection of columns. Each keyspace has at least one and often many column families
有人建议每一个app都创建自己单独的keyspace,但这并不一定是正确的,根据app的实际需求来创建keyspace即可(1个app可以创建多个keyspace)。
在创建keyspace时,需要指定 strategy class:
如果是普通的需求,或者只是评估Cassandra集群,使用 SimpleStrategy class 即可
如果是生产环境,或者集群中有不同workloads,则使用 NetworkTopologyStrategy class如果是为了评估的目的使用 NetworkTopologyStrategy(例如一个单节点的集群),请指定缺省的data center name。使用工具
bin/nodetool status可以查询缺省的data center name:

如果是在生产环境中使用 NetworkTopologyStrategy,则需要将缺省的snitch(即SimpleSnitch)修改为network-aware snitch:在snitch配置文件中定义一个或者多个data center names,并使用这些data center names来定义keyspace。如果使用了NetworkTopologyStrategy但是没有修改缺省的snotch,则Cassandra无法完成写请求,并会输出如下的错误日志:
Unable to complete request: one or more nodes were unavailable.
当一个keyspace使用了 NetworkTopologyStrategy,则只有满足以下两个条件之一时才能将数据写入到该keyspace内的table中:
条件1. 在snitch配置文件中定义了data center names;或者,
条件2. 使用名为“datacenter1”的single data center
