@xtccc
2016-01-14T02:43:35.000000Z
字数 7251
阅读 6077
YARN Architecture

YARN
YARN - Yet Another Resource Negotiator
目录:
Core Concepts
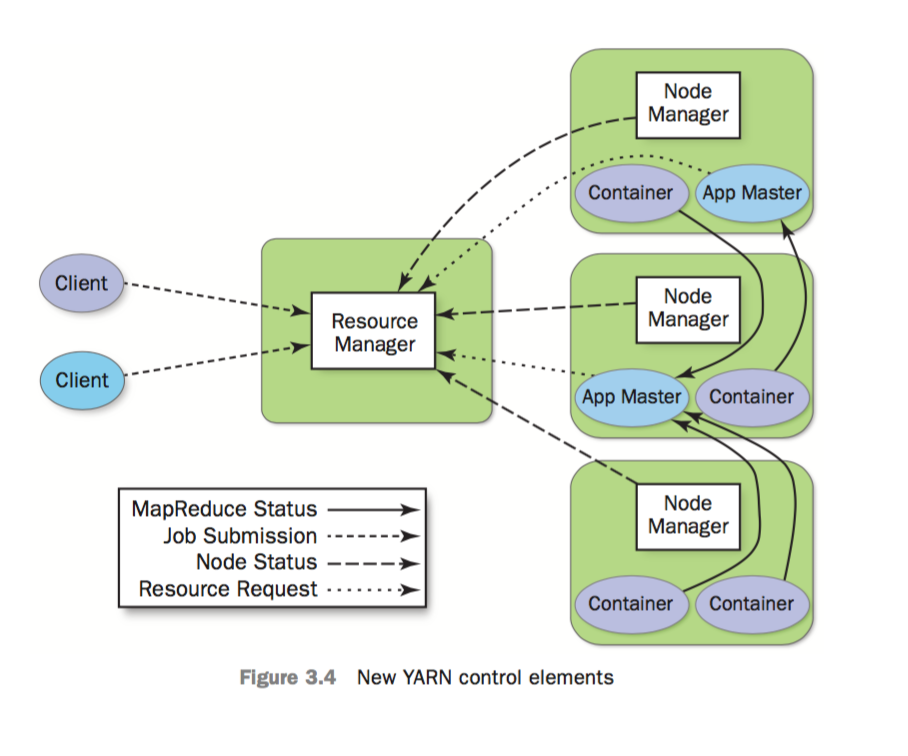
- RM - Resource Manager (包含 Scheduler 和 ApplicationMaster)
- NM - Node Manager (每个节点有1个)
- AM - Application Master (每个app都有单独的AM)
YARN的基础思想:
将原本属于JobTracker的两个任务,即 resource management 与 job scheduling/monitoring,分别交给两个进程负责: Resource Manager 和 Application Master
RM与NM共同构成了一个在分布式环境下实现管理app的OS。
Resource Manager
RM决定资源在各apps之间如何分配,由1个pluggable scheduler与1个ApplicationManager组成。
其中,scheduler是一个纯粹的资源调度器,只负责的全局资源的调配,不会做以下事情:监控/跟踪App的状态,重启失败的task,等等。而ApplicationMaster则管理集群中的用户作业。
RM在进行资源调度时,基于app的资源请求,并使用了resource container(包含了memory, CPU, network, disk等资源维度)。
RM也可以要求收回某些running apps正在使用的资源,特别是当集群资源紧张时。ResourceRequest可以是 strict 或者 negotiable,这使得AM能够灵活地决定怎样处理RM回收资源的要求 —— 选择一些对计算不太重要的container让RM回收,或者是保存任务状态,或者将计算迁移至其他containers。如果AM不同意协商(不同意让出资源),RM可以命令NM强制终止一些containers,并回收资源。
Node Manager
每一个node上都会有1个NM,它的最主要任务是管理由RM指派给它的app containers。正是通过各个节点上的NM,RM才能获得全局的资源视角。
具体而言,NM的职责包括:
- keeping up-to-date with RM
- overseeing app container's life-cycle management
- monitoring resource usage (CPU, memory) of individual containers
- tracking node health
- log management
Application Master
每一个App都会有自己的AM。AM会与RM协商请求获取资源,并与NM协同工作来执行和监控task。AM从RM那里获取resource container,跟踪其状态并监控其进度。从系统角度来看,AM本身是作为一个普通的container运行的。
在AM启动后(作为一个container),它会周期性地向RM发送心跳以表明其存在,并更新它的资源要求。在收到由RM分配的containers后,AM会根据资源的多寡来调整其任务的执行计划。
Resource Model
App通过AM要求获取资源时,可以提出以下的要求:
- Resource name (包括hostname, rackname, network topology)
- Amount of memory
- CPUs (number/type of cores)
- Eventually resources (disk/network I/O, GPUs, etc.)
ResourceRequest & Container
Container是与集群中某一个节点绑定的逻辑概念,代表了该节点上的资源(memory, CPU),它被NM监控,被RM调度。集群中的每一个节点都被认为是由若干个container构成的。
YARN container由 container launch context (CLC) 描述,它包含:
- a map of environment variables
- dependencies stored in remotely accessible storage
- security tokens
- payloads for NM services
- commands necessary to create the process
在验证了container lease的真实性后,NM将为container配置环境。
RM中的Scheduler通过分配一个container来响应AM提出的资源请求,而该container能满足AM在ResourceRequest中提出的具体要求。
ResourceRequest 的形式如下:
- resource-name : 希望从哪里获取资源,可以是hostname,rackname或者*(没有任何偏好)。
- priority : app内部的优先级,它对同一个app内的多个ResourceRequests进行排序。
- resource-requirement : 请求获取的资源(目前只支持 amount of memory 和 CPU time)。
- num-of-containers :
总而言之,container是RM分配的资源(在RM成功地响应了某个特定的ResourceRequest之后),它实际上是授权一个app在指定的host上使用特定的资源(memory, CPU)。
AM在得到container之后,须将其交给特定节点上的NM,然后在该节点上真正地分配资源以启动task。对于MapReduce,在container中运行的代码可以是map task或者reduce task。
Container Specification
container本身只表示授权一个app在指定的host上使用特定的资源,AM必须向NM提供更多的信息来启动(launch)该container。YARN允许APP 启动任何进程,并不仅限于Java app。
Container Launch Specification API 与平台无关,它包含以下内容:
- 在contain内启动进程的命令行
- 环境变量
- 启动container之前所需的本地资源,包括 jars, shared-objects, data files等
- security-related tokens
Scheduling Component
YARN中的调度器组件是可插拔的(pluggable scheduler),用户可以根据自己的需求选择 a) FIFO Scheduler ; 2) Capacity Scheduler ; 3) Fair Scheduler 。
通过Resource Manager的Web UI可以看到当前使用的调度器类型,如下:
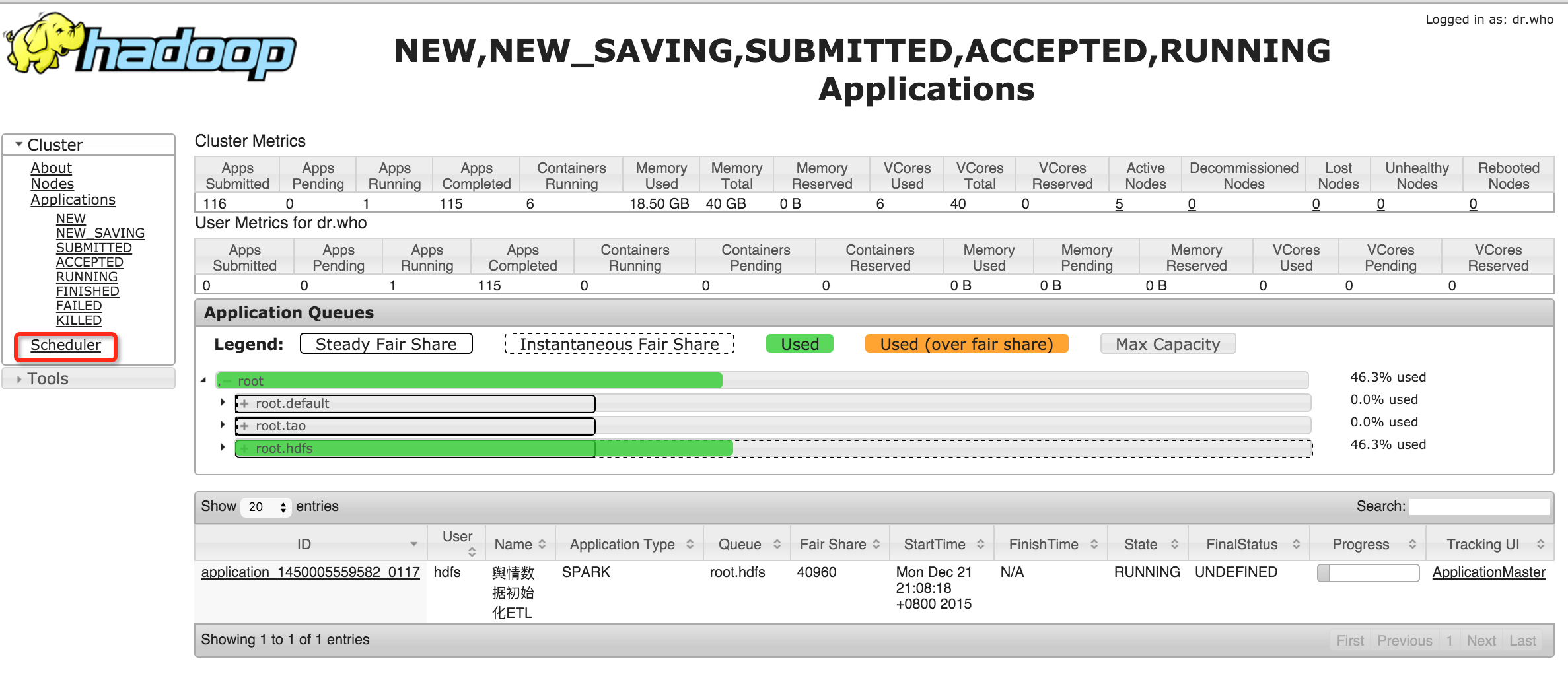
Capacity Scheduler
Capacity scheduler允许多个group共享一个集群。
在使用Capacity scheduler之前,管理员需要创建若干个queue,并为每一个queue配置它能使用的系统资源的占比,这为每一个queue保证了其可用资源的下限值(即使该queue中没有任何app请求资源,也要为该queue保证满足其下限值的资源)。在为每一个queue配置资源时,管理员可以设置soft limits 及 optional hard limits。每个queue都有自己的ACL,从而能限制哪些用户可以向该queue提交app,并且用户也不能查看或修改自己不该访问的apps。
在运行时,管理员可以增加queue,但是不能删除queue。并且,在运行时,管理员可以停止某个queue,来保证 a) 已有的apps能一直运行到结束 ; b) 任何新的app无法被提交到该queue 。
在同一个queue中的数个apps之间使用hierarchical FIFO队列进行调度。
Fair Scheduler
Fair scheduling尽可能地使得每一个app获得均等的资源。除了提供公平共享,Fair scheduler还允许设置能保证queues享有资源的某些下限值。
在Fair scheduler mode中,每一个app都处于某个queue中,containers被分配给拥有最少资源的queue。在一个queue的内部,该container被分配给了拥有最少资源的app。
在默认情况下,所有用户共享一个被称为“default”的queue。如果一个app在container resource request中指定queue,则该request会被提交至该queue。
为了防止某个用户提交过多的apps而占用过多的系统资源,Fair scheduler可以限制每个user/每个queue能运行的apps的数量。这样,queue中的某些user app可以在queue中等待,直到之前提交的apps运行完毕。
Fair scheduler支持的一些feature:
- weights on queues
- minumum shares
- maximum shares
- FIFO policy within queues
为了防止多个小内存的apps饿死一个大内存的app,YARN引入了 reserved container 。如果一个app被分配了一个container,但是由于当前内存不足,它不能立刻使用该container,那么该app可以要求保留(reserver)该container( 在该container被释放之前,其他app不能使用 )。该container将一直等待,直到本地的其他containers被释放。在此之后,该container可以使用被释放的资源来完成app。一个node最多只允许有一个reserved container。
Fair scheduler支持 hierarchical queues ,即queues可以嵌套在其他queues中。一个queue会将分配给它的资源,通过fair scheduling的方式再分配给它的subqueues。
User App Submission
Outline
User app通过一个网络协议被提交给RM,并且在此过程中会经历安全证书检查等步骤。一旦该app通过检查被接受了,它就会被转交给RM的scheduler并且允许运行。当scheduler发现资源可以满足app的要求时,app的状态将从accepted转移至running。
以上过程包括:
- 内部记账(internal bookkeeping)
- 为AM分配一个container(记为“container 0”),并将该AM放置在某个node中
- 除了“container 0”之外,AM此时并没有获得其他的资源,它必须继续地申请所需的containers
AM实际上是一个master user job,它负责管理user app生命周期相关的全部事情,包括:
- 动态地增加/减少资源消耗(containers)
- 管理执行流(例如,对于MR job,要根据maps的输出来运行reducers)
- 处理计算过程中出现的的fault和skew
- 开展一些本地的优化措施
AM可以运行用任意语言编写的app,因为它与RM和NM之间的通讯会使用统一的网络协议(Google Protocol Buffers)进行编码。
上面提到,在考虑资源可用性与调度策略的情况下,RM会试图满足每一个app提出的resource request。当一个资源被调度给了某个AM后,RM会为该资源生成一个租约(lease),随后的AM heartbeat会获取到该lease。当AM向NM递呈container lease时,一个基于令牌的安全机制会保证该container lease的真实性。
一般来说,running container会通过一个app-specific protocol与AM进行通讯,向其报告状态与健康信息,并接受framework-specific commands。因此可以说,YARN为container的监控及其生命周期的管理提供了一种基础设施,而app-specific semantics则是完全独立地由相应的framework来管理。
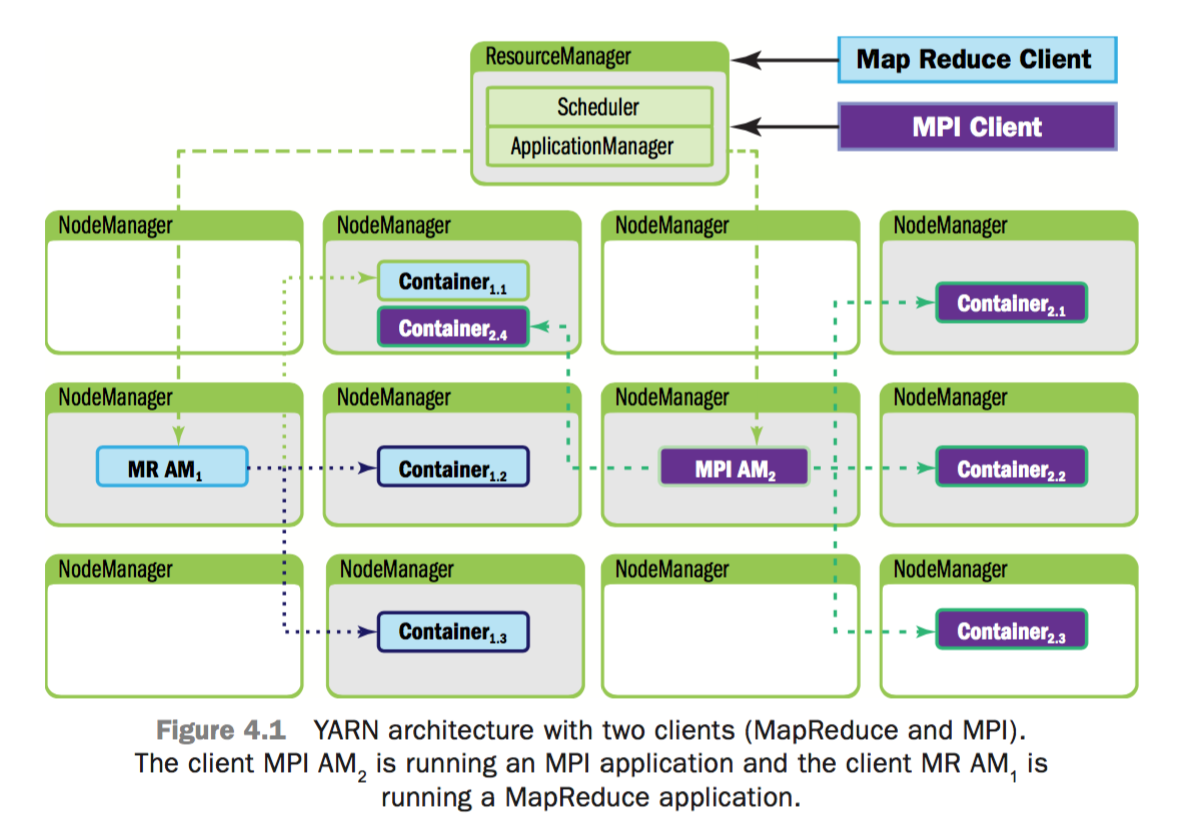
下面将会正式地描述一个user app提交的过程:1)client向YARN提交申请,YARN会为client分配一个AM及其所需的resource contaniner;
Client Resource Request
从下图可以看出,1个YARN app是从client resource request开始的,而该过程是由client与ApplicationManager通讯发起的。
- Step 1: client首先通知RM自己希望提交app
- Step 2: 随后RM会响应一个ApplicationID及关于当前系统资源容量的信息(供client发起资源请求时作为参考)

ApplicationMaster Container Allocation
- Step 3: client回应“Applicatin Submission Context” 及 “Container Launch Context (CLC)”。app submission context 包含Application ID, user, queue, 以及启动AM所需的其他信息;CLC中包含了resource requirements, job files, security tokens,以及在一个node上启动AM所需的其他信息
- Step 4: 当RM收到app submission context后,将会试图为AM调度分配一个可用的container(该container被称为“container 0”,它就是AM,并且它后续将继续请求更多的containers)。如果没有可用的conainer,该请求将会等待。如果有可用的container,RM会选择并联系一个node,然后在该node上启动AM。并且,用于监控app状态的AM RPC port与tracking URL将被建立起来
- Step 5: RM向AM回送关于集群中maximum and minimum capabilities的信息。此时,AM必须决定怎样来使用这些可用资源。从这里可以看出,YARN允许app适应当前的集群环境
- Step 6: 基于RM在step 5中回送的关于当前集群可用资源的信息,AM将请求若干containers
- Step 7: 随后,RM将根据调度策略对此请求进行回应,并将containers分配给AM
当作业开始运行后,AM将向RM发送心跳/进度信息。在这些心跳信息中,AM可以请求更多的containers,也可以释放containers。当作业运行完毕后,AM向RM发送Finish消息后退出。
AM-Container Manager Communication
到此时,对于已被分配的NMs,RM将对它们的控制转交给AM。AM将独立地与这些被分配的NMs联系,并向它们提供CLC(Container Launch Context,including environment variables, dependencies located in remotely accessible storage, security tokens and commands needed to start the actual process)。当container启动后,所有的数据文件、可执行文件及依赖都将被复制到该节点的本地存储中。运行目标app的containers之间可以共享依赖。
当全部的containers都启动后,AM会检查它们的状态。这时,RM就不再参与app的运行过程,从而可以参与对其他资源的调度和监控了。
RM可以要求NM kill containers,在以下情况中会发生kill events:1) AM通知RM自己的使命完成了 ; 2) RM需要将某些nodes回收提供给其他apps ; 3) container在某些方面超过了自己的极限 。
当container被kill之后,NM会清理它的本地工作目录;当作业运行完毕后,AM会通知RM该作业已经运行完毕,然后RM将通知NM进行日志聚合、清理container相关的文件,RM还会指令NM kill任何还未退出的container(包括AM)。
Managing App Dependencies
在YARN中,app是通过运行containers来完成工作的,而这些containers则会映射到本地OS的进程。Container在运行时会依赖于一些文件,例如,如果希望将一个Java程序作为一个container运行,我们就必须将一系列相关的class files和jar files作为其依赖。为了防止这些app每次运行时都要远程地访问这些文件,YARN允许app本地化(localize)这些文件。
在启动container时,AM可以指明:这个container需要用到哪些文件,以及哪些文件应该被本地化 。一旦指明了这些文件,YARN将接管起本地化过程,并且向用户隐藏该过程背后的复杂细节(securely coping, managing and later deleting these files)。
