@xtccc
2016-03-18T07:08:12.000000Z
字数 4556
阅读 3628
Shuffle

Spark
Partitions
一个RDD会存在于一个或多个Partition(s)中,Partition有如下性质:
- 单个Partition中的数据不会跨节点,一定是存在于同一个节点中
- 集群中的一个节点可以有一个或多个partitions
- 一个RDD的partition是可以配置的,包括partitions的数量以及partition类型
Spark提供了Partitioner的抽象类:“org.apache.spark.Partitioner”,并且提供了两种Partitioner object:“HashPartitioner” 和 “RangePartitioner”。
Partitioner实例包含两部分:
- numPartitions - 给出目标partitions的数量
- getPartition(key) - 计算key对应的partition索引(从0开始)
为一个RDD设置Partitioner
val partitionedRdd = rdd.partitionBy()partitionedRdd.persist
注意:必须调用partitionedRdd.persist,否则之后每次使用partitionedRdd时都会重新对原RDD进行partition,这样会引发多次shuffle。
丢失Partitioner
有些transformation,例如map, 会导致结果RDD丢失原有的partitioner,因为map之后原来RDD中的key可能会发生改变。
下面的transformations可以保留原有的partitioner:
cogroup foldByKey
groupWith combineByKey
join partitionBy
leftOuterJoin sort
rightOuterJoin mapValues (if parent has a partitioner)
groupByKey flatMapValues (if parent has a partitioner)
reduceByKey filter (if parent has a partitioner)
什么是Shuffle
Shuffle是一个很昂贵的操作:被shuffle的数据都要先被写入磁盘,然后再通过网络传输。
因此,尽量避免和减少shuffle,参考 SchemaRDD 以及 Spark's Catalyst Optimizer。
何时发生Shuffle
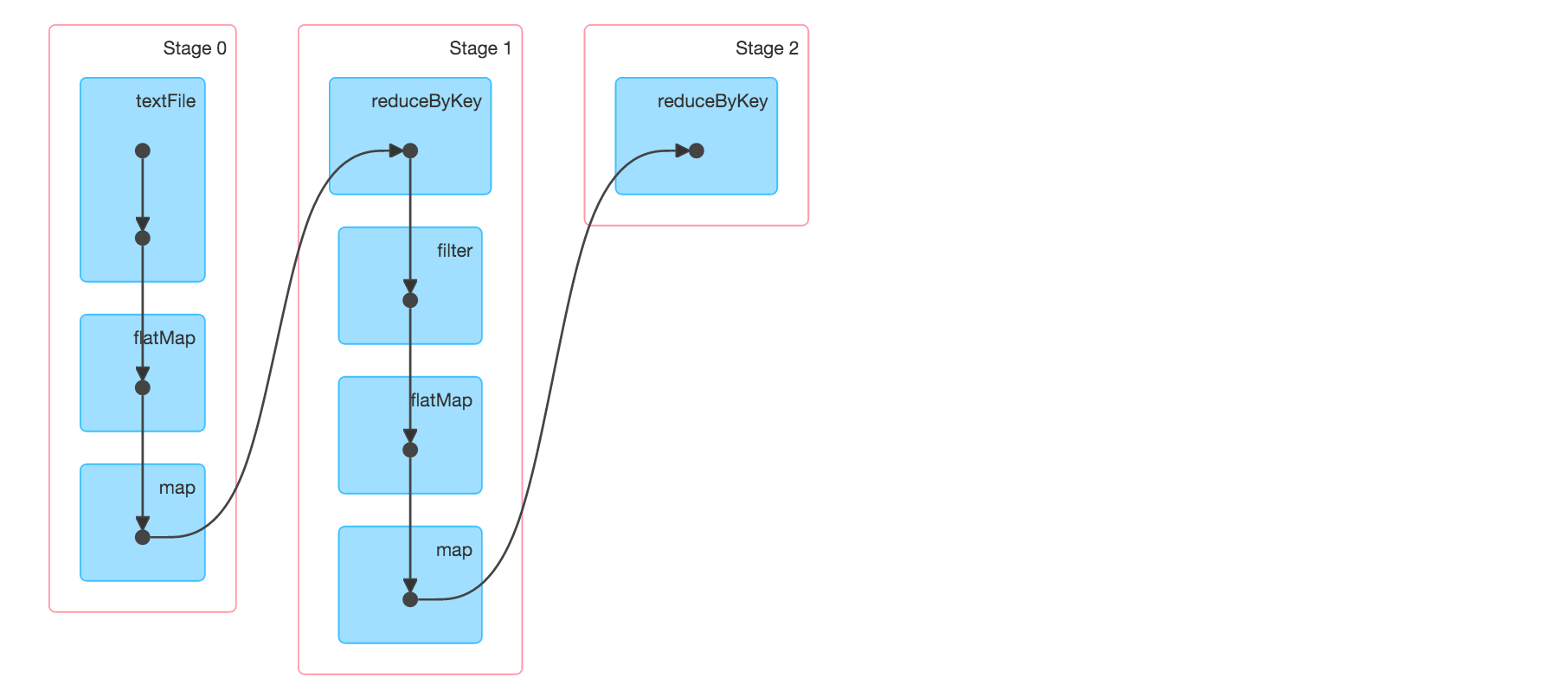
例1:val tokens = sc.textFile("path-to-file.txt").flatMap(_.split(" "))val wordCounts = tokens.map((_, 1)).reduceByKey(_ + _)val filtered = wordCounts.filter(_._2 >= 1000)val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)charCounts.collect
例1中有3个stages,reduceByKey是stage的边界,因为在shuffle阶段会对数据进行repartitioning,如下图所示:
例2:
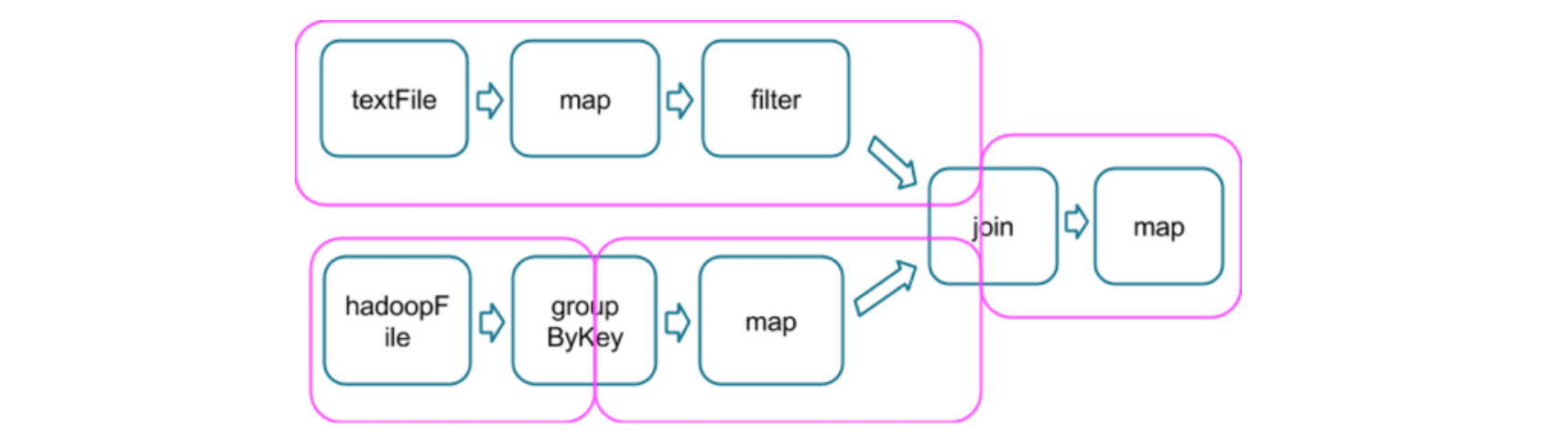
例3中,存在3个stage。
在两个stages的边界处,parent stage中的tasks会将数据写入磁盘,然后child stage中的tasks会通过网络来读取这些数据。因此,stage boundary会带来很可观的磁盘I/O和网络I/O。
parent stage和child stage的partition数量可以不同,而且引发stage boundary的transformation一般也会带有一个numPartitions参数来决定child stage的partition数量。
每一个RDD都可以有一个关联的Partitioner实例(但是非必需),默认的Partitioner是HashPartitioner。
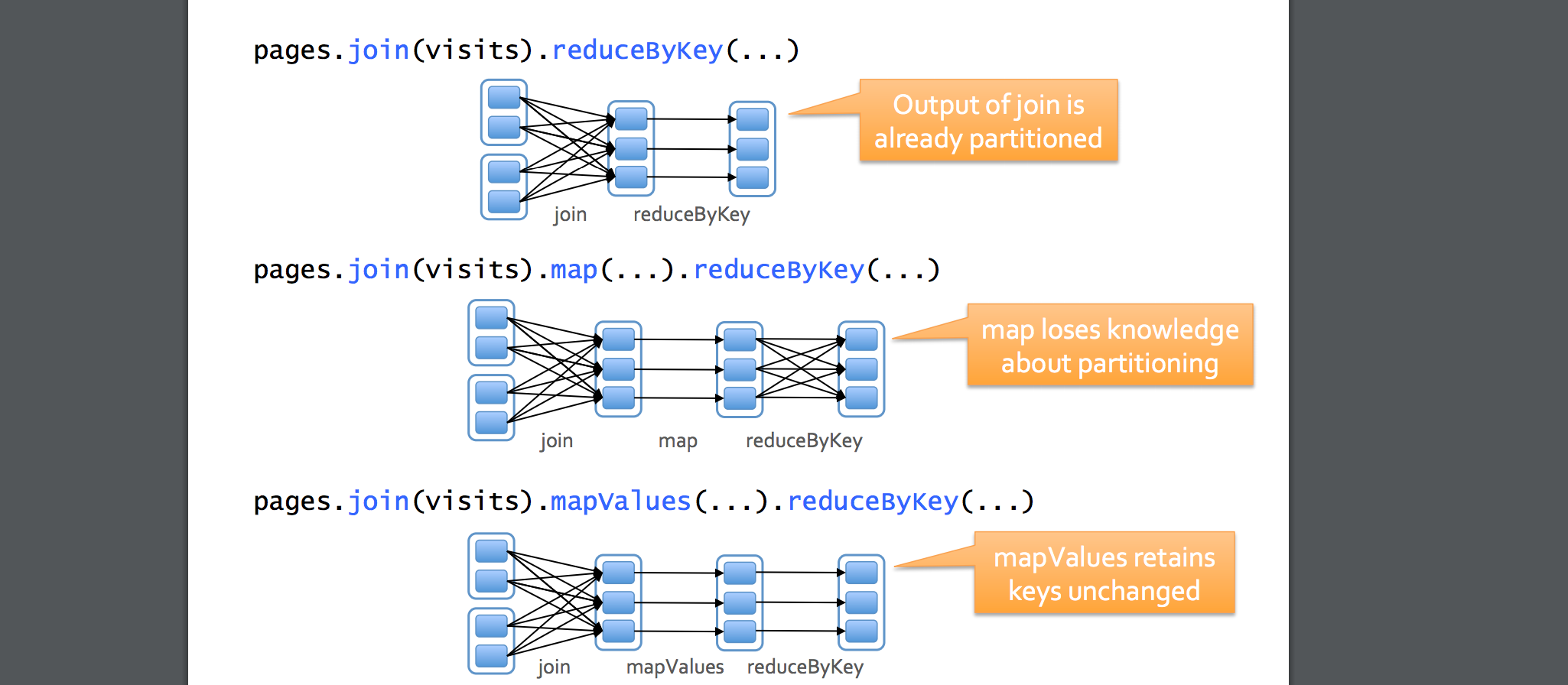
如果对一个RDD进行shuffle操作,shuffle过程将根据它的Partitioner进行
如果shuffle发生于两个RDDs,则shuffle过程会根据其中一个RDD的Partitioner进行(如果这个RDD有自己的Partitioner)。如果两个RDDs都没有设置自己的Partitioner,则shuffle过程会按照默认的HashPartitioner进行
避免和减少Shuffle
Avoid
groupByKeywhen performing an associative reductive operation例如,
rdd.groupByKey.mapValues(_.sum)与rdd.reduceByKey(_ + _)将产生相同的结果,但是后者更好,因为后者可以首先在各个partition中将key相同的tuples的value进行累加,这是一个本地操作。
Avoid
reduceByKeywhen the input and output value types are different
例如,我们想找出每一种key有多少个unique values:rdd.map(t => (t._1, Set[String](t._2))).reduceByKey(_ ++ _)
上面的代码就不如下面的代码(因为map-side aggregation更好):
val zero = Set[String]()rdd.aggregateByKey(zero)((set, v) => set += v,(set1, set2) => set1 ++= set2)
Avoid
flatMap - join - groupBypatternWhen two datasets are already grouped by key and you want to join them and keep them grouped, you can just use cogroup. That avoids all the overhead associated with unpacking and repacking the groups.
何时不会Shuffle
有些transformations,例如 reduceByKey、aggregateByKey、groupBy等,会引发shuffle。
对于某个transformation,如果它的输入RDD来自于前一个transformation,且前面的transformation已经用同样的partitioner对数据进行partitioning了,那么Spark会避免在这个transformation中对数据进行shuffle。
考虑下面的代码片段:
val rdd1 = someRdd.reduceByKey(...)val rdd2 = otherRdd.reduceByKey(...)val rdd3 = rdd1.join(rdd2)
在上面的代码中,由于没有向reduceByKey传递partitioner,因此rdd1和rdd2都将是 hash-partitioned。如果rdd1和rdd2的partitions的数量相同,则后面执行rdd1.join(rdd2)时不会引发新的shuffle,因此rdd1任意一个partition中的keys只会出现在rdd2的某一个partition中(不会对应rdd2的多个partitions)。也就是说,rdd3任意一个partition中的数据只会来源于rdd1的某一个partition和rdd2的某一个partition,因此 rdd1.join(rdd2) 不需要shuffle。
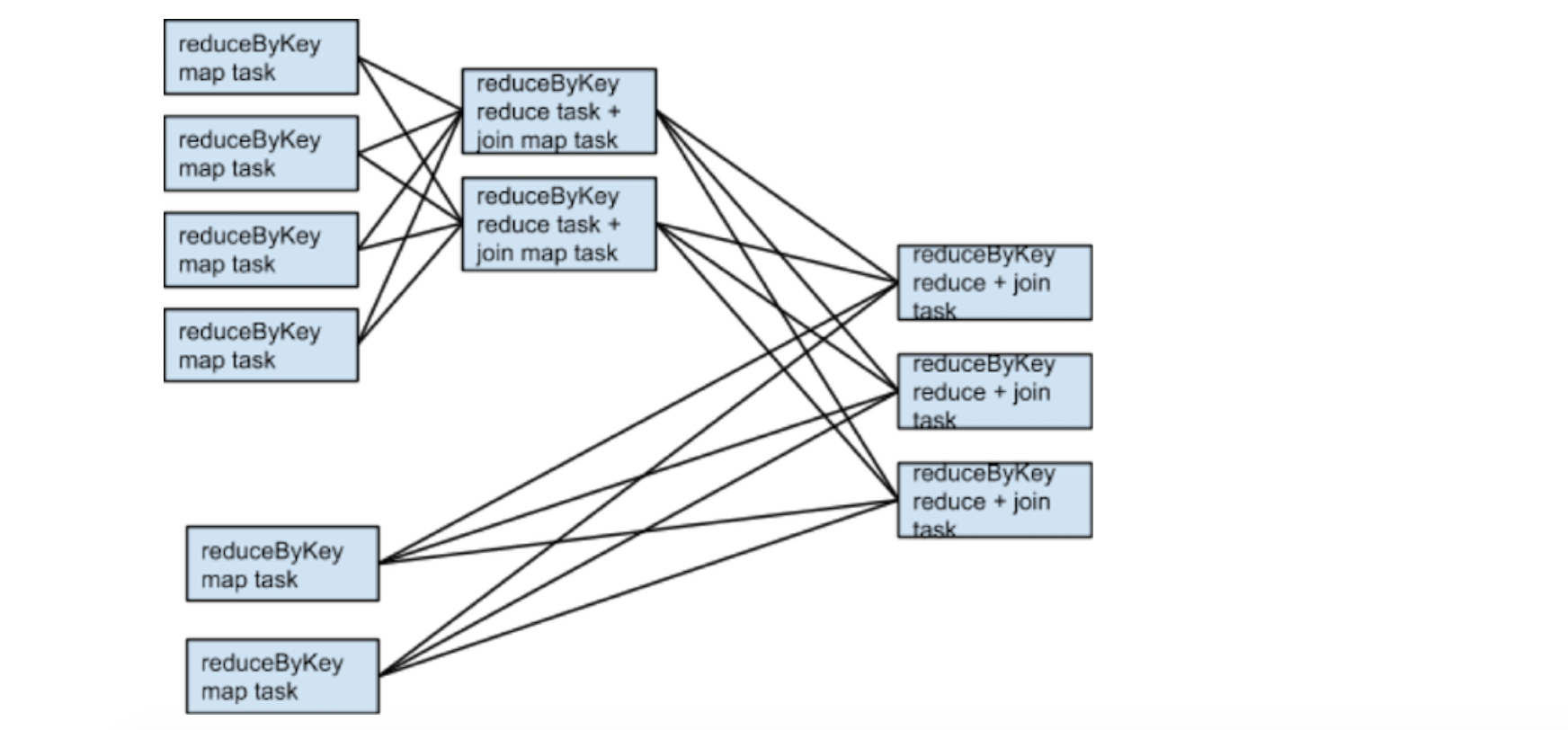
假定someRdd有4个partitions,otherRdd有2个partitions,且它们俩的reduceByKey均使用3个partitions,则运行时的tasks如下图所示:
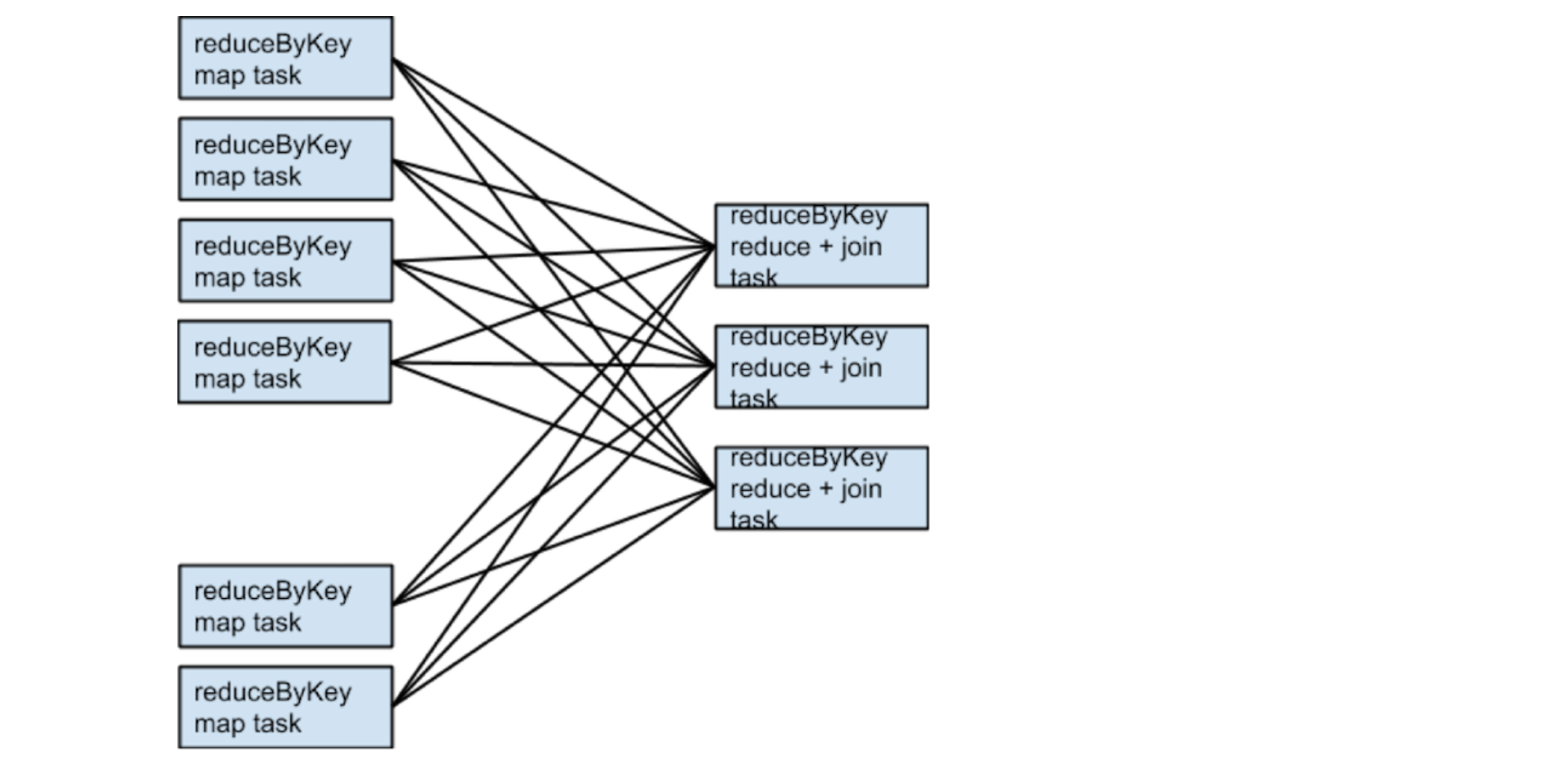
如果rdd1和rdd2在进行reduceByKey时使用不同的partitioners,或者它们都是用相同的partitioners但是partitions的数量不同,会发生什么?
实际上,在这种情况下,rdd1和rdd2进行join时,只有一个RDD(partitions数量少的RDD)需要进行shuffle,且resulting RDD的partitions的数量等于原来两个RDDs中较大的partitions数量。
假定someRdd有4个partitions,otherRdd有2个partitions,那么运行时的tasks图如下:
Parallelism
每一个Spark stage都包含若干个tasks,每一个task内部都会串行地处理数据。在优化Spark app的并行度时,一个stage中的tasks数量是最重要的因素之一。
一个stage中的tasks的数量是由什么决定的呢?
一个Stage中的tasks的数量,等于该stage中最后一个RDD的partitions的数量。
RDD中partitions的数量,一般等于它依赖的RDD的partitions的数量,但是有如下的例外:
coalesce允许创建一个RDD,使得它的partitions数量比parent RDD更少;union创建的RDD的partitions数量是所有parent RDDs的partition数量之和;cartesian创建的RDD的partitions数量是所有parent RDDs的partitions的数量之积。
如果RDD没有parent:
- 由
textFile等创建的RDD,其partitions数量由InputFormat决定,通常每一个HDFS block都会对应一个partition;- 由
parallelize创建的RDD,其partitions数量由用户指定,如果不指定则等于默认配置“spark.default.parallelism”
如果stage中tasks的数量偏少,则会加重每个task中aggregation操作的负担。
join、cogroup和*ByKey这些操作会将数据放入hashmap或者内存中进行group/sort。如果内存无法很容易地满足,会带来一些overhead。
- 首先,GC会较为严重;
- 其次,如果内存真的放不下这些数据,则Spark会将它们spill到磁盘,这将导致I/O和sorting;
对于大型的shuffle而言,以上两点,是导致任务卡顿的最重要原因。
怎样增加partitions?
如果stage是从Hadoop中读取数据:
1. 调用“repartition” 2. 配置“InputFormat”增加splits 3. 将数据写入HDFS时,使用更小的block size
如果stage是从另一个stage那里得到数据:
stage boundary一定是由某个transformation引发的(e.g., reduceByKey),那么可以向这个transformation传入一个参数: rdd2 = rdd1.reduceByKey(f, numPartitions=N) 确定参数N : 将parent RDD的partitions数量乘以1.5,如此往复,直到取得最好的性能为止
