@xtccc
2016-12-19T01:58:50.000000Z
字数 11625
阅读 4623
Index

Phoenix
目录
创建Index
创建Index的DDL语法为:
CREATE INDEX {index_name}ON {data_table} ({columns_to_index})INCLUDE ({columns_to_cover})
Global Index v.s. Local Index
Global Index
Global index适合大量读、小量写的场景:性能的开销发生在写数据的阶段。对于global index,数据表的更新操作(DELETE, UPSERT VALUES, UPSERT SELECT)会被截获,接着与该数据表相关的索引表会被更新。
创建Global Index
create index "idx" on "test" ("c");
在默认情况下,对于global index,只有当query中的全部column都被包含在index中,才会使用该索引。
防止Deadlock
对于global index,为了防止维护索引时发生死锁,我们可以让index update的优先级比data update的优先级更高,并让metadata rpc调用比data rpc调用的优先级更高。为了实现这一点,需要在每一个region server的hbase-site.xml中添加以下的配置:
<property><name>hbase.region.server.rpc.scheduler.factory.class</name><value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property><name>hbase.rpc.controllerfactory.class</name><value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property>
Local Index
Local index适合大量写、空间受约束的场景:index data与table data将会处于同一个server上,以防止由写数据发生的网络开销当query没有被完全覆盖时,local index也可以被使用。 与global index不同的是,一个表的所有local indexes都将共享地被存储在一个单独的表中。如果query用到了local index,那么数据所在的每一个region都必须被检查,因为并不能实现明确index data在哪一个region中。综上,对于local index,性能开销在读数据阶段。
Local immutable index由server-side维护。
创建Local Index
create local index "idx" on "test" ("c");
注意:从0.98.6到0.98.8版本的HBase不支持创建local index。
与global index不同的是,即使一个query中的任何column都没有被包含在index内,local index也会使用索引,因为table与index data会处于同一个region server上,这可以保证lookup总是本地的。
配置Local Index
为了data table与local index处于同一个region server上,需要对HBase master上的hbase-site.xml文件添加如下的配置:
<property><name>hbase.master.loadbalancer.class</name><value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value></property><property><name>hbase.coprocessor.master.classes</name><value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value></property>
为了使得当data region merge发生时,local index region merge也能进行,需要向每一个region server的hbase-site.xml文件中添加以下的配置:
<property><name>hbase.coprocessor.regionserver.classes</name><value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value></property>
Salted Index
Index在创建时,也可以将其声明为salted index table,如下:
create index "idx" on "test" ("c") SALT_BUCKETS=10;
如果创建的是local index,则不能指定SALT_BUCKETS。
如果数据表是salted table,则与其对应的index自动是salted。
Immutable Index
对于Immutable table创建的index,是使用时速度更快。但是要求:immutable table中的数据只能追加,不能修改。这种table和index适合timeseries data。
方法:首先,通过IMMUTABLE_ROWS=true来创建一个immutable table,然后为该table创建index。
> create table "test" ("pk" varchar not null primary key, "c" varchar) IMMUTABLE_ROWS=true;> upsert into "test" values('pk-1', 'hi');> select * from "test";+------------------------------------------+------------------------------------------+| pk | c |+------------------------------------------+------------------------------------------+| pk-1 | hi |+------------------------------------------+------------------------------------------+> create index idx on "test" ("c");> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-2', 'hello');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| hello | pk-2 || hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-2', 'abc');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| abc | pk-2 || hello | pk-2 || hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-1', 'abc');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| abc | pk-1 || abc | pk-2 || hello | pk-2 || hi | pk-1 |+------------------------------------------+------------------------------------------+
可以看到,对于immutable table,如果它的某条数据发生了修改,那么相应index并不会修改原来的索引记录,而是会再增加一条索引记录。当主表的数据更新后,该数据原来的索引记录依然存在,但是实际上是失效的。
对于immutable table,它里面的数据是可以修改的,但是它的index不会相应修改,而是会追加新的索引项。
对于global immutable index,index完全由client-side维护,
对于local immutable index,index完全由server-side维护。
Mutable Index
在创建时不指定 IMMUTABLE_ROWS=true,创建的就是mutable table,对应的index也是mutable index。
> create table "test" ("pk" varchar not null primary key, "c" varchar);> upsert into "test" values('pk-1', 'hi');> select * from "test";+------------------------------------------+------------------------------------------+| pk | c |+------------------------------------------+------------------------------------------+| pk-1 | hi |+------------------------------------------+------------------------------------------+> create index idx on "test" ("c");> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-2', 'hello');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| hello | pk-2 || hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-2', 'abc');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| abc | pk-2 || hi | pk-1 |+------------------------------------------+------------------------------------------+> upsert into "test" values('pk-1', 'abc');> select * from idx ;+------------------------------------------+------------------------------------------+| 0:c | :pk |+------------------------------------------+------------------------------------------+| abc | pk-1 || abc | pk-2 |+------------------------------------------+------------------------------------------+
可见,对于mutable table,如果某条数据被修改了,则index中对应的索引项也会相应修改。
对于某个表,如果它的索引表是immutable index,但是我们想
Index表数据的组成与结构
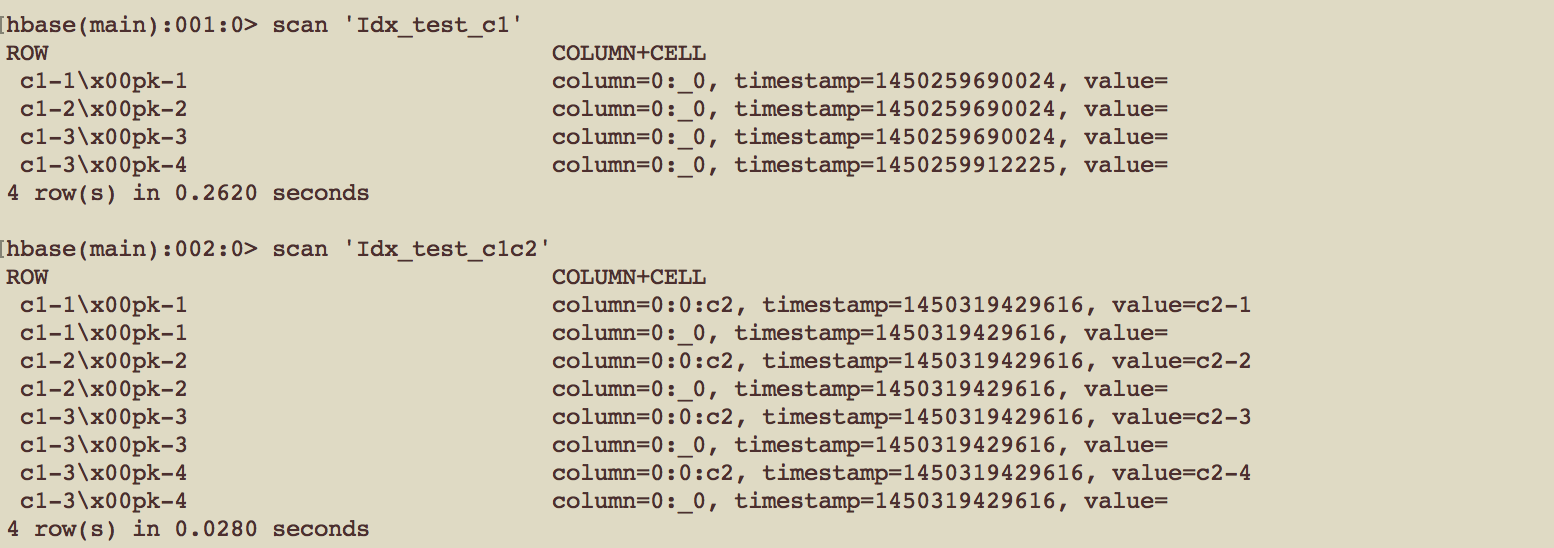
Index在HBase中实际上也是一个table,它把原始数据表的rowkey与column value揉和到了一起,成为了index table的rowkey。
Row keys are concatenated with index column values delimited by a zero byte character and end with data table primary key. If you define covered columns, you will see cells with their values as well in the index table.
例 : 首先创建数据表及其索引,并在数据表中写入一些数据
CREATE TABLE "test" ("pk" VARCHAR NOT NULL PRIMARY KEY,"c1" VARCHAR, "c2" VARCHAR);CREATE INDEX "Idx_test_c1" ON "test" ("c1");CREATE INDEX "Idx_test_c1c2" ON "test" ("c1") INCLUDE ("c2");UPSERT INTO "test" ("pk-1", "c1-1", "c2-1");UPSERT INTO "test" ("pk-2", "c1-2", "c2-2");UPSERT INTO "test" ("pk-3", "c1-3", "c2-3");UPSERT INTO "test" ("pk-4", "c1-3", "c2-4");
然后,看一看两个索引表中的实际数据在HBase是什么样的?
Asynchronous Index Population
Apache Phoenix 4.5之后的版本才支持
使用Index
Index for a Single Column
首先创建一个table
create table TEST (ROW varchar not null, C1 varchar, C2 varchar, C3 varchar CONSTRAINT PK primary key (ROW));
然后向其中插入6,000,00条记录。
先看看在没有创建index的前提下,查询一条记录需要多长时间:

通过column value来查询一条记录,如果没有Index,需要4.063秒,漫长的时间。
我们创建了Index之后,再以同样的方式通过column value查询记录:

可以看到,在为表TEST的C1列创建了Index之后,我们在根据C1列来查询主键时,查询时间非常短(0.04秒),说明在查询时我们创建的Index起作用了。
注意:由于只为表TEST的C1列创建了Index,如果在查询时包含了除主键及C1列之外的其他列,那么Index就不会起作用(上图中的第一次查询已经说明了这个问题)。
Index for Multiple Columns
也可以为多个columns建立索引,但是只能有1个列作为主索引列。
下面,为表TEST的C1列建立Index,同时为C2列建立Covered Index:
> create index "idx" on "TEST" ("C1") INCLUDE ("C2");6,000,001 rows affected (53.661 seconds)
然后,尝试几种不同的QUERY:

可见,如果要保证Index有用,必须:
1. 被查询的列只能包含主键、C1和C2;
2. 必须含有C1列,因为C1列是主索引列;
在QUERY时,在索引起作用的情况下,是先通过主索引列C1查询出所有满足关于C1条件的记录,然后根据C2的值在这些数据中进行过滤。如果仅仅根据C2列的值进行查询,是无法使用Index的。
实际上,索引表idx的rowkey中只包含C1列的内容,完全没有关于C2列的内容,C2列的数据被放在了索引表idx的value中,这一点从HBase shell可以看出:

除了上例的INCLUDE之外,还有下面的形式来对多列建立索引:
> create index "idx" on "TEST" ("C2", "C3");6,000,001 rows affected (38.895 seconds)
这里,C2是主索引列,如果QUERY中不包含C2,Index依然无法起作用:

但是,索引表idx中的内容就与INCLUDE形式不同了:

Index Hint
当QUERY中包含了未被索引的column时,可以通过hint来让该QUERY使用Index:
> create index "idx" on "TEST" ("C1");> select "ROW", "C2" from "TEST" where "C1"='c1-88';+------------------------------------------+------------------------------------------+| ROW | C2 |+------------------------------------------+------------------------------------------+| row-88 | c2-88 |+------------------------------------------+------------------------------------------+1 row selected (3.978 seconds)> select /*+ INDEX("TEST" "idx") */ "ROW", "C2" from "TEST" where "C1"='c1-88';+------------------------------------------+------------------------------------------+| ROW | C2 |+------------------------------------------+------------------------------------------+| row-88 | c2-88 |+------------------------------------------+------------------------------------------+1 row selected (0.11 seconds)
可见,在select与columns之间加入/*+ INDEX(table_name index_name) */,可以让QUERY强制使用index。这种用法要求:满足"C1"='c1-88'
真正的多列索引
如果我希望既可以单独按照C1列查询,也可以单独按照C2列查询,那怎么办?
方法是对同一个table,针对不同的column,分别创建各自的Index。例如,我们为TEST表的C1列建立索引idx_C1,在为C2列建立索引idx_C2。
但是,在查询时,QUERY中的column不能包含没有被索引的列,除非用hint来强制QUERY使用索引。
> create index "idx_C1" on "TEST" ("C1");6,000,001 rows affected (42.06 seconds)> create index "idx_C2" on "TEST" ("C2");6,000,001 rows affected (36.526 seconds)> select "C1" from "TEST" where "C1"='c1-77';+------------------------------------------+| C1 |+------------------------------------------+| c1-77 |+------------------------------------------+1 row selected (0.453 seconds)> select "C2" from "TEST" where "C2"='c2-77';+------------------------------------------+| C2 |+------------------------------------------+| c2-77 |+------------------------------------------+1 row selected (0.045 seconds)> select "C1", "C2" from "TEST" where "C1"='c1-77';+------------------------------------------+------------------------------------------+| C1 | C2 |+------------------------------------------+------------------------------------------+| c1-77 | c2-77 |+------------------------------------------+------------------------------------------+1 row selected (4.035 seconds)> select "C1", "C2" from "TEST" where "C2"='c2-77';+------------------------------------------+------------------------------------------+| C1 | C2 |+------------------------------------------+------------------------------------------+| c1-77 | c2-77 |+------------------------------------------+------------------------------------------+1 row selected (5.015 seconds)> select /*+ INDEX("TEST" "idx_C2") */ "C1", "C2" from "TEST" where "C2"='c2-77';+------------------------------------------+------------------------------------------+| C1 | C2 |+------------------------------------------+------------------------------------------+| c1-77 | c2-77 |+------------------------------------------+------------------------------------------+1 row selected (0.16 seconds)
Drop Index
drop index "idx" on "TEST";
如果数据表中被索引的列被删除了,那么对应的索引表也会被自动地删除。如果数据表中被覆盖的(covered)列被删除了,那么对应的索引表也会被自动删除。
Expression Index
create index "idx" on "TEST" (UPPER("v1"));select "v1" from "TEST" where UPPER("v1")='HELLO';
Data Guarantees & Failure Management
- full transaction是无法提供的,因此index table与data table会存在不同步的情况,但是不同步的时间非常短
- data row与它的index要么全部写入,要么全部没有写入,不存在partial update的情况
- 数据先写入index table,然后才写入data table
