@xtccc
2016-01-14T02:42:44.000000Z
字数 3261
阅读 6774
YARN 使用

YARN
适用版本:Hadoop 2.6.0-cdh5.5.1
目录:
YARN Administrative Tools
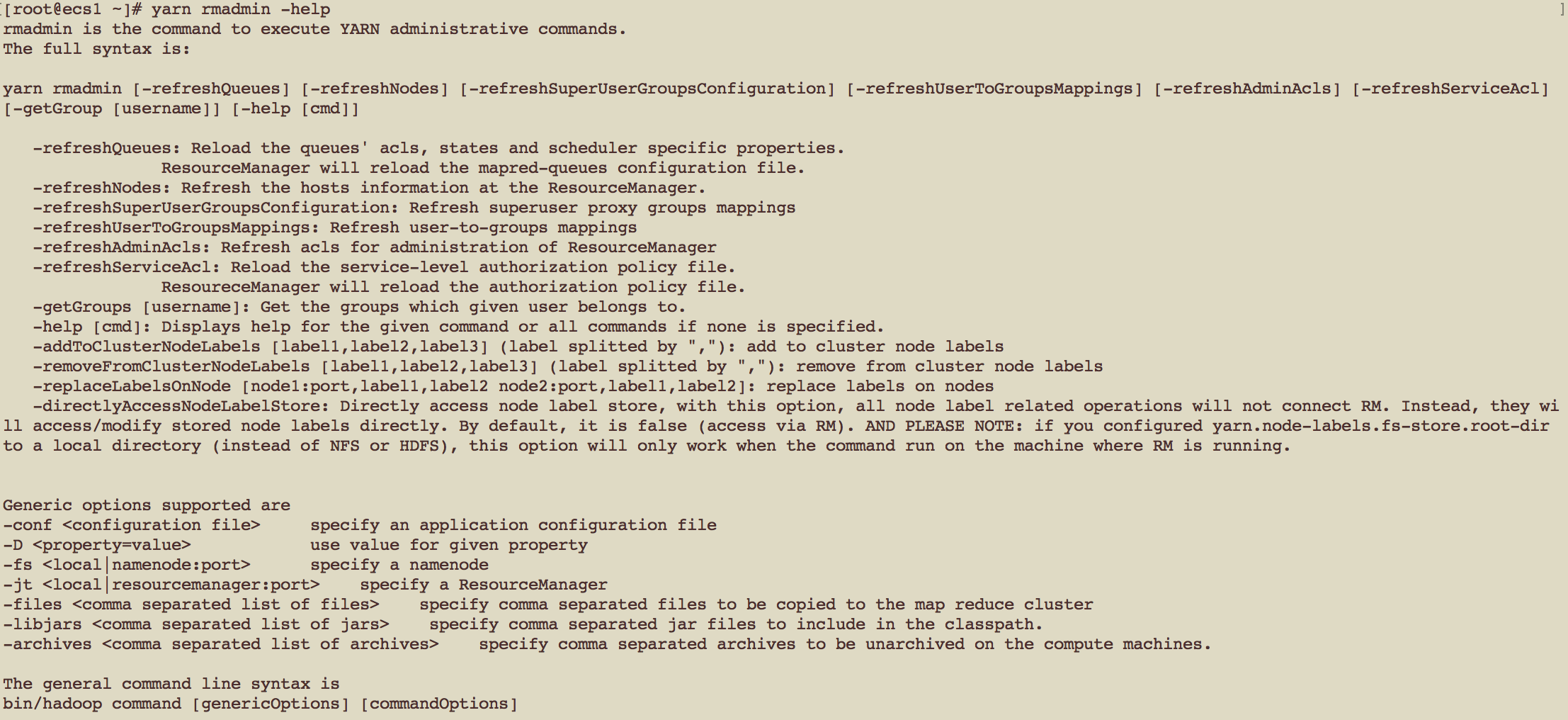
查看YARN命令工具的帮助
yarn rmadmin -help
Managing YARN Jobs
YARN jobs可以用 “yarn application” 命令进行管理。
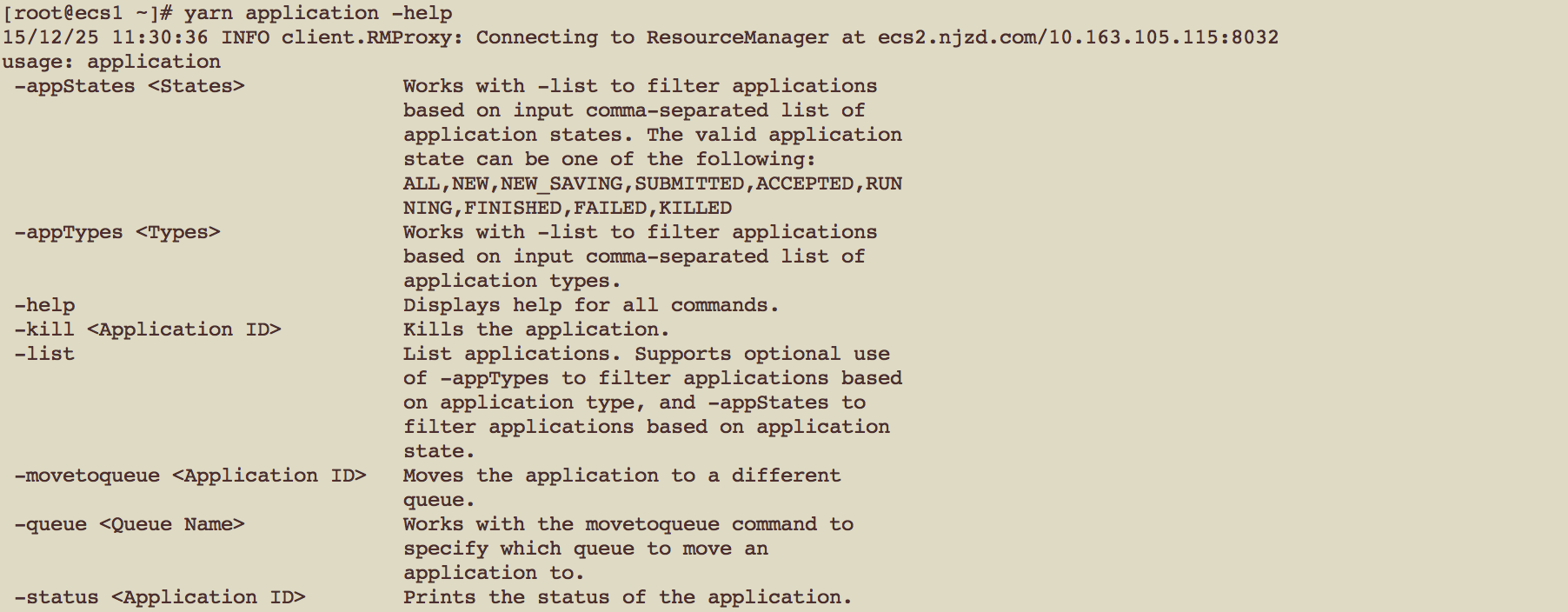
List YARN App
yarn application -list
Kill YARN App
yarn application -kill {yarn-app-id}
配置YARN参数
Container Memory
在 yarn-site.xml 文件中,可以通过以下参数为container配置memory
yarn.nodemanager.resource.memory-mb(默认8GB)
NM所在节点可以分配给container的最大物理内存yarn.scheduler.minimum-allocation-mb (默认1GB)
可以为container申请的最小物理内存,如果申请的container内存小于这个值,则按照这个值给container分配物理内存。如果使用Capacity scheduler或者FIFO scheduler,那么会按照该值的最小整数倍为container分配内存yarn.scheduler.maximum-allocation-mb (默认64GB)
允许为container分配的最大物理内存
Container Cores
在 yarn-site.xml 文件中,可以通过参数配置为container配置virutal CPU cores
yarn.scheduler.minimum-allocation-vcores(默认1)
container可以请求的virtual CPU cores的最小值,如果使用Capacity scheduler或者FIFO scheduler,那么会按照该值的最小整数倍为container分配virtual CPU coresyarn.scheduler.maximum-allocation-vcores(默认32)
container可以请求的virtual CPU cores的最大值yarn.nodemanager.resource.cpu-vcores(默认8)
NM所在节点能够分配给container的virtual CPU cores的最大值
MapReduce Properties
使用YARN之后,MapReduce作为YARN中的一个app运行,可以在mapred-site.xml中对map container和reduce container相关的参数进行配置(这几个配置在CDH 5.5.1中似乎不再使用了/无效)
mapred.child.java.opts
为mapper的child JVM配置heap size 默认值为“-server -Xmx640m -Djava.net.preferIPv4Stack=true”- mapreduce.map.memory.mb
- mapreduce.reduce.memory.mb
- mapreduce.reduce.java.opts
日志
日志聚合
在YARN中,属于同一个app的所有containers的日志将被聚合(aggregated)起来,并写入指定文件系统(HDFS)的某个日志文件中。当一个YARN app运行完成后,我们将得到一个application-level日志目录,同时对于每个节点,也会得到一个日志文件(含有在该节点上运行的、属于该app的全部containers的日志)。
开启Log Aggregation的配置项为
yarn.log-aggregation-log开启之后,YARN App日志的HDFS根目录为
yarn.nodemanager.remote-app-log-dir每个用户都有自己单独的目录,且下一层目录名可以如下配置
yarn.nodemanager.remote-app-log-dir-suffix综上所属,开启日志聚合后,一个Yarn app的日志所在的HDFS目录为
{yarn.log-aggregation-log}/{user}/{yarn.nodemanager.remote-app-log-dir-suffix}当YARN App的日志在HDFS中生成后,可以设置为每隔一定时间自动删除,时长参数为
yarn.log-aggregation.reatin-seconds
例:运行一个MapReduce Job,它的id为“application_1451022530184_0001”,则我们可以用命令 同时我们也可以在HDFS中看到日志的目录结构:

查看聚合日志
用户可以通过YARN命令行工具、web UI来访问这些日志,也可以在文件系统中直接访问这些日志文件。

例如,可以通过命令
yarn logs -applicationId application_1451022530184_0001
直接输出该YARN App产生的日志(很长,包含了全部containers的日志)。
也可以只输出某个container产生的日志。
查看NM节点上的本地日志
YARN App运行时,每个NM节点上都会产生本地日志,这些日志在被聚合到HDFS后,经过一段时间后会被NM的DeletionService删除,这个时间间隔由以下参数决定
yarn.nodemanager.delete.debug-delay-sec
该参数的默认值为0,如果将该值设置地大一些(例如600,即10分钟),则我们可以查看NM上container产生的本地日志的目录,这个目录的配置参数为
yarn.nodemanager.local-dirs
配置Log4j
可以为ApplicationMaster或者exector提供我们自定义的Log4j配置,有以下2种方式
在使用“spark-submit”提交Spark job时,通过参数“--files”上传一个自定义的log4j.properties文件
使用这种方式,executors与ApplicationMaster会共享同一个log4j配置文件,这会导致问题 —— 如果executor与ApplicationMaster运行在同一个节点上,则它们会试图向同一个文件中写入日志。将参数“-Dlog4j.configuration={location_of_cong_file}”添加到“spark.driver.extraJavaOptions”(针对driver),或者添加到“spark.executor.extraJavaOptions”(针对executor)
使用这种方式时,“{location_of_cong_file}”中应该指定“file:”协议,并且该文件应该在每个节点的本地文件系统中存在。
通过在log4j.properties文件中使用“spark.yarn.app.container.log.dir”参数,我们还可以令log4j将日志写入到YARN,这样YARN可以聚合并正确地显示HDFS中的log。
例如,针对普通的Spark job,设置“log4j.appender.file_appender.File=${spark.yarn.app.container.log.dir}/spark.log”;针对streaming app,配置“RollingFileAppender”并将日志文件的路径设置到YARN的日志目录,可以避免日志文件耗尽磁盘空间,并且也可以通过YARN log utlity来显示这些日志内容。
