@xtccc
2016-01-17T13:11:39.000000Z
字数 15574
阅读 6942
Runnning Spark On YARN

Spark
参考链接:
spark-submit提交脚本
通过“spark-submit”命令可以提交一个job,具体的用法如下:
# spark-submitUsage: spark-submit [options] <app jar | python file> [app arguments]Usage: spark-submit --kill [submission ID] --master [spark://...]Usage: spark-submit --status [submission ID] --master [spark://...]Options:--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") oron one of the worker machines inside the cluster ("cluster")(Default: client).--class CLASS_NAME Your application's main class (for Java / Scala apps).--name NAME A name of your application.--jars JARS Comma-separated list of local jars to include on the driverand executor classpaths.--packages Comma-separated list of maven coordinates of jars to includeon the driver and executor classpaths. Will search the localmaven repo, then maven central and any additional remoterepositories given by --repositories. The format for thecoordinates should be groupId:artifactId:version.--exclude-packages Comma-separated list of groupId:artifactId, to exclude whileresolving the dependencies provided in --packages to avoiddependency conflicts.--repositories Comma-separated list of additional remote repositories tosearch for the maven coordinates given with --packages.--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to placeon the PYTHONPATH for Python apps.--files FILES Comma-separated list of files to be placed in the workingdirectory of each executor.--conf PROP=VALUE Arbitrary Spark configuration property.--properties-file FILE Path to a file from which to load extra properties. If notspecified, this will look for conf/spark-defaults.conf.--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).--driver-java-options Extra Java options to pass to the driver.--driver-library-path Extra library path entries to pass to the driver.--driver-class-path Extra class path entries to pass to the driver. Note thatjars added with --jars are automatically included in theclasspath.--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).--proxy-user NAME User to impersonate when submitting the application.--help, -h Show this help message and exit--verbose, -v Print additional debug output--version, Print the version of current SparkSpark standalone with cluster deploy mode only:--driver-cores NUM Cores for driver (Default: 1).Spark standalone or Mesos with cluster deploy mode only:--supervise If given, restarts the driver on failure.--kill SUBMISSION_ID If given, kills the driver specified.--status SUBMISSION_ID If given, requests the status of the driver specified.Spark standalone and Mesos only:--total-executor-cores NUM Total cores for all executors.Spark standalone and YARN only:--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,or all available cores on the worker in standalone mode)YARN-only:--driver-cores NUM Number of cores used by the driver, only in cluster mode(Default: 1).--queue QUEUE_NAME The YARN queue to submit to (Default: "default").--num-executors NUM Number of executors to launch (Default: 2).--archives ARCHIVES Comma separated list of archives to be extracted into theworking directory of each executor.--principal PRINCIPAL Principal to be used to login to KDC, while running onsecure HDFS.--keytab KEYTAB The full path to the file that contains the keytab for theprincipal specified above. This keytab will be copied tothe node running the Application Master via the SecureDistributed Cache, for renewing the login tickets and thedelegation tokens periodically.
Deploy Mode
如果希望让Spark作为一个普通App运行在YARN中,则在提交Spark job时指定 “--master YARN”,此时ResourceManager的URL将被从Hadoop的配置文件中提取出。
当通过client来提交Spark Job时,可以指定两种 deploy mode
yarn-cluster
在这种模式下,Spark driver运行在Application Master的进程内,在提交完job之后client就可以退出了。executors和driver使用由“yarn.nodemanager.local-dirs”定义的本地日志目录,“spark.local.jar”即使被指定了它也会被忽略。yarn-client
Spark driver运行在client的进程内,此时AM只负责向RM请求资源。executors将使用由“yarn.nodemanager.local-dirs”定义的本地日志目录,而driver将使用由“spark.local.dir”定义的本地日志目录,因为driver并不在YARN中运行,只有executors在YARN中运行。 “spark.yarn.am.memory”指定YARN AM使用的内存
添加依赖文件
从“spark-submit”命令的用法可以看出,以下参数与添加依赖文件有关
--jars
Comma-separated list of local jars to include on the driver and executor classpaths.--files
Comma-separated list of files to be placed in the working directory of each executor.--driver-library-path
Extra library path entries to pass to the driver.--driver-class-path
Extra class path entries to pass to the driver. Note that jars added with “--jars” are automatically included in the classpath.--archives
Comma separated list of archives to be extracted into working directory of each executor (applied to YARN-mode only).
使用“--files”和“--archives”时,可以通过“#”来给文件起别名。例如,如果指定“--files localtest.txt#appSees.txt”,那么本地文件“localtest.txt”将被上传至HDFS,而且该文件将有一个别名“appSees.txt”,YARN app在应用该文件时应该使用这个别名。
配置Spark App
Spark有关的参数配置可以参考 Spark Configuration
Spark App配置参数的构成
Spark App中的配置来源于三处:
- 用“bin/submit-spark”提交Spark app时,可以通过选项“--conf”向Spark app中传递任意配置参数
- 除此以外,“bin/submit-spark”还会从文件“spark-defaults.conf”中读取配置
- Spark app中的“SparkConf”实例也可以通过代码接收配置
实际生效的参数值是上述三者的合并值,合并时的优先级为:通过“SparkConf”直接设置的参数 > 通过“--conf”向“bin/submit-spark”传递的参数 > 从文件“spark-defaults.conf”读取的参数
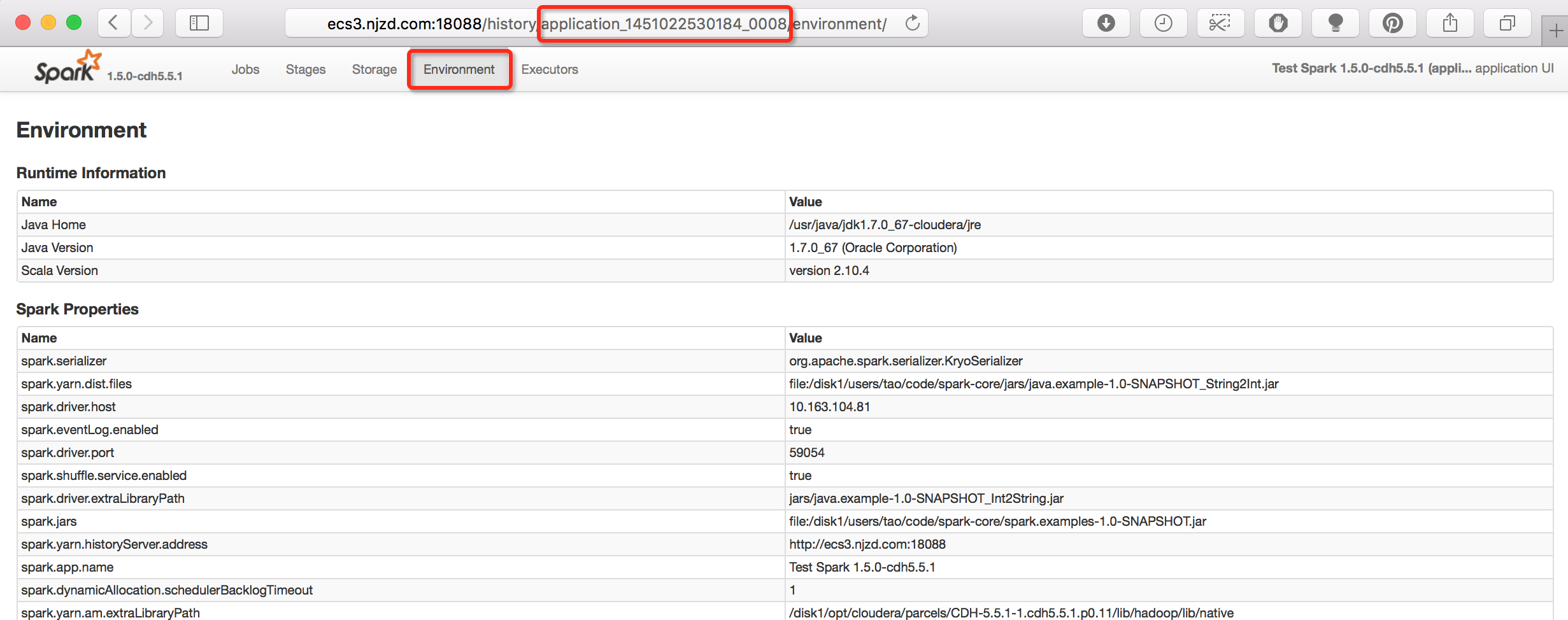
查看某个Spark App的配置参数
在某个App的详情页面,可以看到针对该App的配置参数。这个页面中包含了从“spark-defaults.xml”文件、“SparkConf”实例、“bin/submit-spark”的“--conf”三处指定的配置参数,其他的参数可以认为是取了默认值。
以指定用户的身份运行Spark Job
似乎不行
术语
Application
Spark applications run as independent sets of processes on a cluster, coordinated by the “SparkContext” object in your program (called the “driver program”).
Job
A job is a parallel computation consisting of multiple tasks that get spawned in response to a Spark action (e.g., save, collect), including any tasks that need to run to evaluate that action.
At the top of the execution hierarchy are jobs. Invoking an action inside a Spark app triggers the launch of a Spark job to fulfill that action. To decide what this job looks like, Spark examines the graph of RDDs that action depends on and formulates an execution plan. The plan starts with the farthest-back RDDs (those that depend on no other RDDs or reference already-cached data) and culminates in the final RDD required to produce the action's results.
Executor
An executor is a process for an application on a worker node, that run tasks and keeps data in memory or external storage across them.
An executor is a long running process launched at the start of Spark app and killed after the app is finished.
Every Spark executor in an application has the same fixed number of cores and same fixed heap size.
Task
A task is a unit of work that will be sent to one executor, and each task is a thread which resides in an executor.
The cores property of an executor controls the number of concurrent tasks it can run, e.g., --executor-cores 5 means each executor can run at most 5 tasks at the same time.
Stage
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce).
Every stage has a number of tasks, each of which processes data sequentiqlly. The number of tasks in a stage equals to the number of the partitions in the last RDD in the stage.
The execution plan consists of assembling the job's transformations into stages. A stage corresponds to a collection of tasks that all execute the same code, each on a different subset of the data. Each stage contains a sequence of transformations that can be completed without shuffling the full data.
例1:sc.textfile("path-to-file.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count
例1中只有1个action,这个action依赖于一串transformations。上面这段代码在执行时,只有1个stage,因为例1中3个transformations中的任意一个transformation的输入数据都只会来自单个partition,即这3个transformations都是narrow transformations。
例2:val tokens = sc.textFile("path-to-file.txt").flatMap(_.split(" "))val wordCounts = tokens.map((_, 1)).reduceByKey(_ + _)val filtered = wordCounts.filter(_._2 >= 1000)val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)charCounts.collect
例2中有3个stages,reduceByKey是stage的边界,因为它会对数据进行repartitioning.
例3:
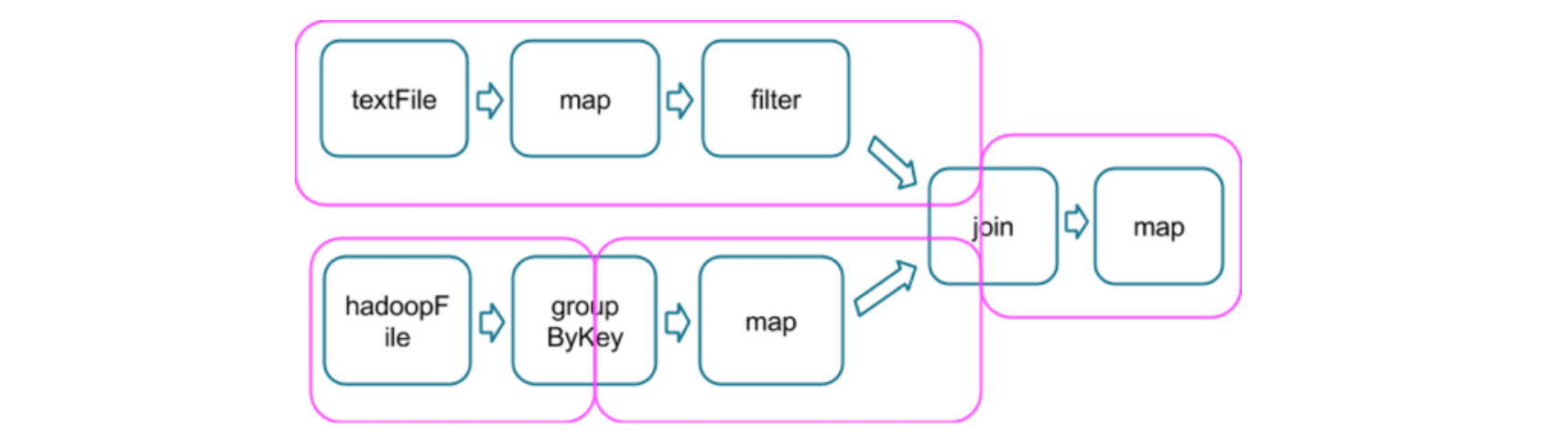
例3中,存在3个stage。
在两个stages的边界处,parent stage中的tasks会将数据写入磁盘,然后child stage中的tasks会通过网络来读取这些数据。因此,stage boundary会带来很可观的磁盘I/O和网络I/O。
parent stage和child stage的partition数量可以不同,而且引发stage boundary的transformation一般也会带有一个numPartitions参数来决定child stage的partition数量。
Shuffle
Shuffle是一个很昂贵的操作:被shuffle的数据都要先被写入磁盘,然后再通过网络传输。
因此,尽量避免和减少shuffle,参考 SchemaRDD 以及 Spark's Catalyst Optimizer。
Action, Transformation
Action
如果函数在对RDD计算完成后,向driver返回一个计算结果,则该函数为action。Transformation
如果函数在对RDD计算完成后,向driver返回一个新的RDD,则该函数为Transformation。
Spark model
Spark app为了运行在集群中,“SparkContext”实例可以连接多种cluster managers(Mesos, Yarn等)。一旦连接建立, Spark将要求在集群的节点中获取executors(这些executors的职责是计算并存储数据);接着,Spark会将app code发送给各个executors;最后,“SparkContext”实例将tasks发送给executors供其运行。
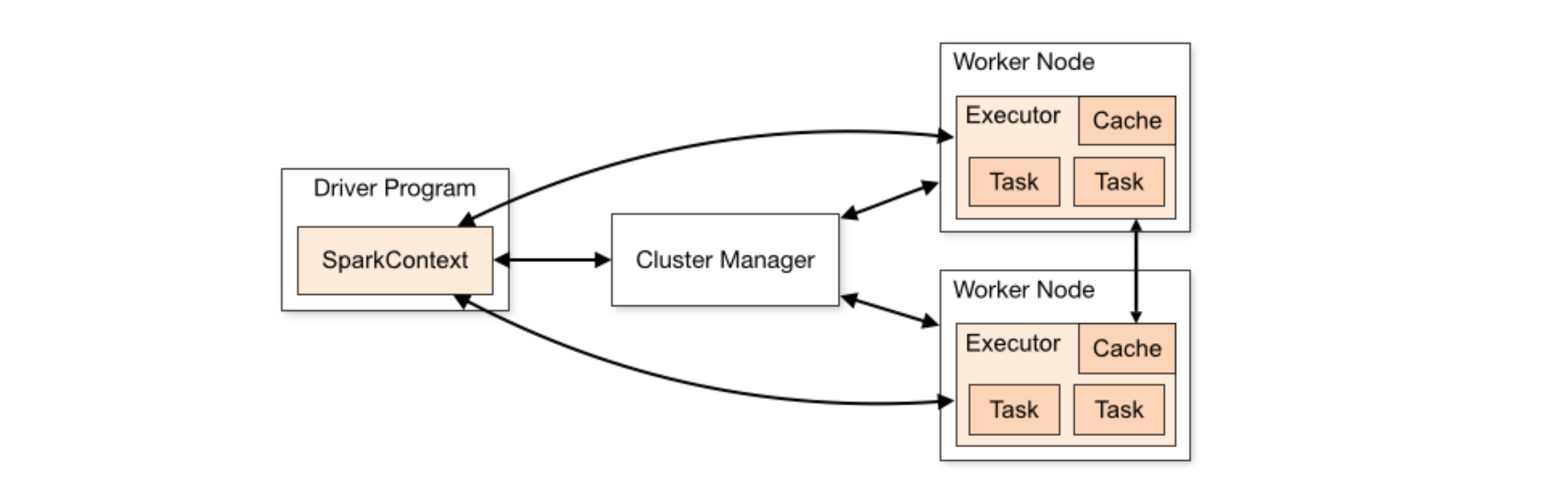
每个Spark app都有自己的executor processes,每个executor都会在一个或多个thread(s)中运行task(s)。这样可以将不同的Spark apps彼此隔离开来:每一个driver只能调度自己的tasks,不同Spark apps的tasks也会运行在不同的JVMs中。但是,这也意味着,除非通过外部存储系统,否则两个Spark apps无法共享数据。
Driver与executors都会在Spark App的整个声明周期期间存在(如果开启了dynamic resource allocation机制,则会有所不同)。
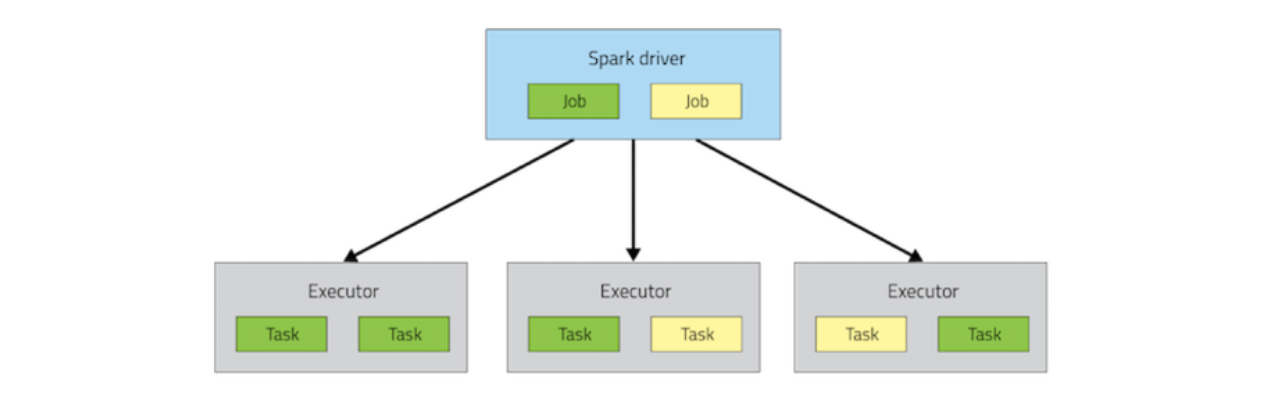
Job Scheduling
在每一个Spark app内部,如果多个不同的threads提交了多个jobs(actions),那么这些jobs可以并发地运行。
Scheduling Across Apps
前面提到,在集群中运行时,每一个Spark app都有自己独立的executor JVMs。如果多个用户向共享这个集群来提交多个Sparl apps时,可以有几种不同的资源分配方式(这由cluster manager决定)。
最简单的方式是对资源的静态划分(static partitioning of resources)。这种方式为每一个app规定了它能使用的资源上限,在一个Spark app的整个运行期间,将相应的资源分配给它。当我们在YARN中提交Spark app时使用的就是这种方式(通过 “--num-executors”、“--executor-memory”、“--executor-cores”参数指定)。
Spark Resource and YARN Container
Spark通过上面的几种参数向YARN请求资源 (Container) 时,YARN是怎样来满足这些请求的呢?
YARN有如下的资源相关参数:
yarn.nodemanager.resource.memory-mb
一个NodeManager能够分配给其上所有containers的最大物理内存yarn.nodemanager.resource.cpu-cores
一个NodeManager能够分配给其上所有containers的最大虚拟CPU核数
当Spark请求5个CPU cores时,实际的请求内容就是向YARN请求5个virtual CPU cores。但是在请求内存时,情况会不同 —— 实际向YARN请求的内存量受到以下因素的影响:
--executor-memory/spark.executor.memory参数控制了 executor heap size,但是JVM也可以使用堆外内存 (off-heap memory),例如 interned string 及 direct byte array。参考参数spark.yarn.executor.memoryOverhead的含义及设置YARN也可能将请求的内存上调一些,这受到参数
yarn.scheduler.minimum-allocation-mb和yarn.scheduler.increment-allocation-mb影响。
下图是当Spark运行在YARN之上时,内存的体系模型图

Dynamic Resource Allocation
从Spark 1.2开始,如果一个Spark app不再需要某些资源,它可以将这些资源退还给集群,等到需要用到的时候再向集群申请所需的资源。在分配给一个app的资源中,如果其中的一部分资源空闲,那么这些空闲资源可以被送还给集群的资源池并被其他的apps申请使用。
对于Spark,资源可以按照executor粒度进行动态分配。也就是说,随着某个Spark App的工作负载的变化,它的executors数量也会相应地进行增减。目前该特性只能在YARN中生效(Spark 1.5)。
要开启此特性,需要进行以下设置。
spark.dynamicAllocation.enabled = true
spark.shuffle.service.enabled = true
注意CDH 5.5.1对“spark.shuffle.service.enables”的一段描述
The External Shuffle Service is not robust to NodeManager restarts and so is not recommended for production use.
开启了此特性后,Spark app就需要用到external shuffle service,它的作用是保存由executors生成的shuffle files,这样executors便可以安全地退出(参考这里)。在YARN中,external shuffle service是由“org.apche.spark.yarn.network.YarnShuffleService”实现的,它将运行在集群的每一个NM中。配置external shuffle service的步骤如下:
1. 找到external shuffle service的实现包
e.g., spark-1.5.0-cdh5.5.1-yarn-shuffle.jar
2. 把这个包放进每个NodeManager的classpath中,classpath在哪里?
3. 在每个节点的yarn-site.xml文件中,添加以下设置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
4. 重启每个Node Manager
此外,还需要设置以下参数 (spark.dynamicAllocation.*形式的参数在CDH中需要在Spark组件中配置,而不是在YARN组件中配置):
spark.dynamicAllocation.minExecutors
spark.dynamicAllocation.maxExecutors
spark.dynamicAllocation.initialExecutors
spark.dynamicAllocation.executorIdleTimeout
spark.dynamicAllocation.cachedExecutorIdelTimeout
spark.dynamicAllocation.schedulerBacklogTimeout
当YARN dynamic resource allocation生效后,参数 “--num-executors”就无效了,参考 Investigation of Dynamic Allocation in Spark 。
Resource Allocation Policy
当某些executor不再需要时,Spark应该释放它们。如果需要用到额外的executors,Spark再发出请求。但是,事先并不能知道,将被释放的executor未来会不会运行task,将请求的新executor会不会空闲。
Request Policy
当存在等待调度的pending tasks(这意味着,当前的executors无法同时满足所有已被提交但是还未运行完成的tasks)时,Spark app会请求更多的executors。
Spark对executors的请求是一轮一轮进行。如果存在pending tasks,且它们的挂起时间超过了“spark.dynamicAllocation.schedulerBacklogTimeout”,则会触发对executor的请求。之后,如果pending task queue持续存在,则每隔“spark.dynamicAllocation.sustainedSchedulerBacklogTimeout”时长,都会触发对executors的请求。在每一轮中,Spark请求的executors数量都会比上一轮呈指数级的增加(e.g., 1, 2, 4, 8)。
Remove Policy
如果一个executor的空闲时长超过了“spark.dynamicAllocation.executorIdleTimeout”,则Spark app会释放该executor。当然,如果存在等待调度的tasks,则executor不应该处于idle的状态。
Graceful Decommission of Executors
在启动资源动态分配之前,executor并不是随着自己任务完成就结束,而是会一直存在,而是直到自己发生错误/异常或者它的SparkContext退出才会结束。在资源动态分配模式下,即使人为地结束executors,Spark app仍然可以运行。但是此时,如果Spark app试图访问这些executors中保存的状态数据,它就不得不重新计算出这些状态数据。因此,Spark需要能够让executor“优雅地”结束(decommission)的机制,即在结束executor前保存它的状态数据。
这个机制对shuffle而言特别重要。在shuffle过程中,executor首先将自己的输出数据写入到本地磁盘文件中,然后,当其他executors试图访问这些数据时,这个executor作为file server为其它executors提供服务。如果开启了资源动态分配机制且出现了straggler(如果某些tasks运行的时间明显比其他tasks长很多,那么这些tasks就称为stragglers),那么在shuffle完成之前,可能某个executor就结束了,这意味着这个executor输出的shuffle files必须被重新计算。
满足该机制要求的解决方案就是使用external shuffle service来保存shuffle files。External shuffle service是一个长时间运行的进程,它运行于每一个节点上,且独立于Spark app及其executors。如果开启了external shuffle service,那么executors就会从external shuffle service去取shuffle files,而不是从其他的executors处去取shuffle files。这意味着,可以在executor的生命周期之外继续提供executor的shuffle state的服务。
Scheduling Within an Application
在一个SparkContext内,如果多个threads提交了多个jobs,那么这些jobs可以并发地运行(这里的“job”指的是一个action及其相关的tasks)。Spark scheduler是完全线程安全的。
在默认情况下,Spark scheduler以FIFO的方式运行jobs。如果队列中的第一个job不需要使用集群中的全部资源,那么后面的job可以立即运行;如果队列中的第一个job很大,则后面的job需要等待(也许需要等待很长时间)。
从Spark 0.8开始,可以通过配置令Spark scheduler以fair sharing的方式运行jobs。在fair sharing模式下,Spark以round robin的方式在jobs之间分配tasks,使得所有的jobs能获得近乎公平的集群资源。这意味着,即使一个长作业正在运行,短作业也可以立即获得集群资源从而获得较好响应时间,而不必等待长作业运行完毕。它适合多用户模式。
如何配置fair sharing scheduler?
val conf = new SparkConf()conf.set("spark.scheduler.mode", "FAIR")val sc = new SparkContext(conf)
Tuning Performance
下面只讨论在YARN中运行Spark app的情况。
Spark app的任务类型
计算密集型
每个task的计算量较大(较复杂的计算)数据密集型
需要从磁盘/HDFS读取或者写入大量的数据网络密集型
大量的数据需要在节点之间/executors之间进行shuffle
不同类型的Spark job所需到的performance bottleneck不同,对应的优化手法也不同。除此以外,影响性能的因素还有:
- GC
- data locality
- resource allocation/competetion
- race condition
资源分配优化
相关参数
total number of executors
“--num-executors”,默认2 如果开启了dynamic resource allocation,则上述参数无效,而下面的参数有效 “spark.dynamicAllocation.minExecutors” “spark.dynamicAllocation.maxExecutors” “spark.dynamicAllocation.initialExecutors”memory per executor
“--executor-memory”,默认1GBcores per executor
“--executor-cores”,默认1memory for dirver
“--driver-memory”,默认为1024M 如果在drvier中调用“collect”或者“take(N)”等,且RDD中的数据较大,则需要将该值设置地大一些
资源分配法则
考虑AppicationMaster所需的资源
AM是一个 non-executor container,它的职责之一是向YARN申请containers,它本身也是会占用资源的。在 “yarn-client”模式下,给AM分配的资源是1GB内存和1个vcore。在“yarn-cluster”模式下,driver本身也是运行在AM中的,所以一般需要通过“--driver-memory”和“--driver-cores”来提升分配给AM的资源。限制Executor的内存
如果太大的话,GC的时间会较长。单个executor的内存一般不超过64GB限制每个HDFS clients的并发线程数量
在写入数据到HDFS时,如果要达到full write throughput,最好将每个executor的tasks数量限制在5个以下,因此每个exectuor的vcores数量不应超过5(在写HDFS时)。谨慎看待many tiny executors
Tiny executors(e.g., 只为executor分配1个vcore和足够的内存,只运行1个task),可能会抵消在一个JVM中运行多个并发tasks所带来的好处。例如,broadcast variable需要为每一个executor都复制一份,因此 many tiny executors 会导致对广播数据的过多复制。
配置实例
假设集群的物理配置如下:
6个节点运行NodeManager
每个节点有16个cores和64GB内存
那么,YARN的配置应该如下:
“yarn.nodemanager.resource.memory-mb” 设置为 63*1024 = 64512MB
“yarn.nodemanager.resource.cpu-vcores” 设置为 15
为什么?由于每个节点都需要资源运行OS和Hadoop daemons,因此没有将100%的资源都分配给YARN containers。
基于上面对YARN NodeManager的配置,可能我们会为Spark做出这样的参数配置:
--num-executors 6 --executor-cores 15 --executor-memory 63G
但这是错误的!
因为上面对Spark的配置会导致:
1. Executor memory overhead将超过63GB,因而NodeManager的63GB内存无法满足executor要求63GB内存的请求
2. ApplicationMaster自身要占用某个节点上的1个core,因而该节点上NodeManager的可用vcores只剩下14个,无法满足executor要求15个vcores的请求。
3. 15 vcores per executor 将导致不理想的HDFS吞吐量
所以,更好的Spark配置如下:
--num-executors 17 --executor-cores 5 --executor-memory 19G
理由是:
1. 上面提到了,一个executor的tasks数量限制在5以下,因此设置“--executor-cores 5”
2. “--num-executors”指的是一个Spark app的executors总数,是各个NodeManager上该Spark App的executors的数量之和。ApplicationMaster本身需要占用资源(假设占用1个vcore),那么集群中AM所在节点的NM可用vcores数量为15-1=14,可以运行的executors数量为14/5=2,其他5个节点的NM可用vcores数量为15,可以运行的executors数量为15/5=3,因此设置“--num-executors 17”
3. 一个NM有63GB内存,最多运行3个executors,因此一个executor最多使用的内存为63GB/3=21GB。另外,由于每个executor都需要用到off-heap memory(参数“spark.yarn.executor.memoryOverhead”),因此需要留出的off-heap memory为21GB*0.1=2.1GB,这样每个executor的内存可以设置为21GB-2.1GB=19GB,因此设置“--executor-memory 19G”
以上是假设静态资源分配的情况,且只有1个Spark App在运行。
如果运行多个Spark apps,或者开启了dynamic resource allocation,则情况又会不同。
GC优化
最好的方法是通过Tachyon的off-heap storage不产生GC。
Types of Garbage Collector
数据格式
Failover
当一个executor/task失败、异常或者遇到错误而退出后,会不会重启一个新的executor/task来重新开始这个失败的计算过程?
这个问题非常重要,特别是当一个task中向数据库等外部存储组件写入数据时。如果某个task失败后会自动尝试重新运行,就意味着同样的数据会被重复地写入数据库(外部存储系统)。
