@xtccc
2016-01-07T03:06:45.000000Z
字数 2463
阅读 4053
Kafka基础

Kafka
目录
1. 基本特征
快速处理
单个Kafka broker每秒可以服务多达数千个客户端的读写请求(数百MB的数据量),服务数十万条消息(普通硬件)。
可扩展性
可以灵活地、透明地对Kafka集群进行扩展,并且在扩展时可以不中断服务。
可靠性
消息被复制并持久化在磁盘上,以防止丢失数据。
2. Kafka概念
Kafka Cluster
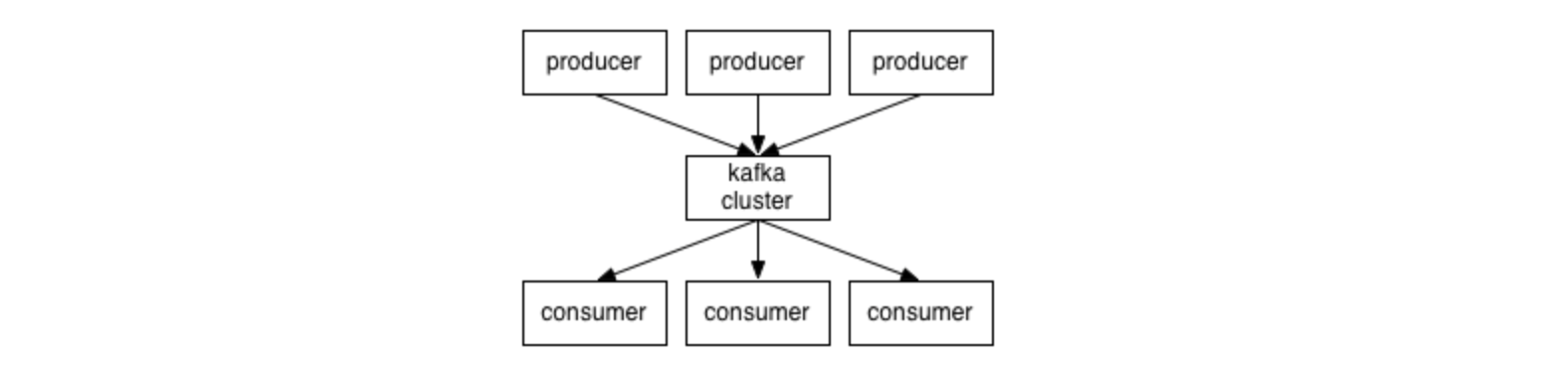
Client与Servers之间的通讯是通过一种语言无关的TCP协议实现的,不仅包括Java,还包括很多其他语言。
Topics and Logs
对于每一个topic,Kafka集群都为之维护了一个如下的partitioned log:
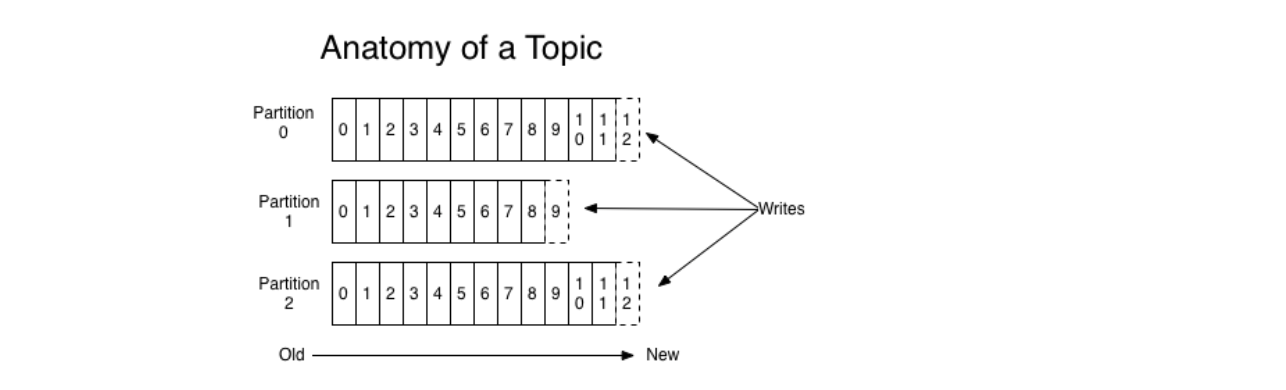
不同的partition可以分布在不同的server上,这样整个log就可以不受某个server容量的限制。但是一个partition是受限于它所在的server的容量的限制的。
一个partition内的消息之间是有序的,且每一条消息都被赋予了一个在该partition内唯一的id,称为 offset 。这里的一个partition也可以被称为一个commit log。
每一条消息都会被Kafka集群保留一段时间,不论这些消息是否已经被消费了。
实际上,consumer持有的唯一元数据是它在log中的位置,称之为 offset ,这个offset完全由consumer控制。正常情况下,随着consumer不断地读取消息,offset会随之向前推进,但是consumer也可以决定将offset重置为某一个,以便于重新处理消息。
Distribution
每一个partition会在数个server上被复制(servers的数量可配置),以此实现容错性。在这几个server中,其中一个server的角色是 leader,其他servers的角色是 follower。leader负责处理该partition的全部读写请求,而followers则会复制leader。如果leader崩溃了,则某一个follower会自动地成为新的leader。
如果一个topic的副本因子为N,则最多可以容忍N-1个server宕机而保证不丢失数据。
一个server上面会有若干个partitions,该server会作为其中某些partitions的leader以及其余partitions的follower。
Producer
Producer将消息发布到它选择的topic中去,它负责决定将哪个消息送到topic的哪个partition中。这可以以round robin方式进行,也可以以其他方式进行(例如按照消息中的key决定将该消息发送到哪一个partition)。
Consumer
存在若干个consumer group,每个consumer都会由一个consumer group name标签。
对于某个topic而言,会有若干个consumer group订阅该topic。当一条消息被发送给该topic后,它会被推送给每个consumer groups的其中一个consumer实例。
当消费行为发生时,一个topic会限制任何一个partition只能被subscribing consumer group中的一个consumer处理,这样就能保证这个consumer是该partition的唯一消费者,也就能保证一个partition中的消息是按照原来生成的顺序被读取的。由于一般partition的数量很多,这也能保证负载被均摊到很多消费者的身上。值得注意的是,consumer group中的消费者数量不能大于该consumer group订阅的topic的partition的数量。
Kafka只保证任何一个partition内的消息是有序的,不保证topic中的消息是有序的。
3. 命令行工具
kafka-topics
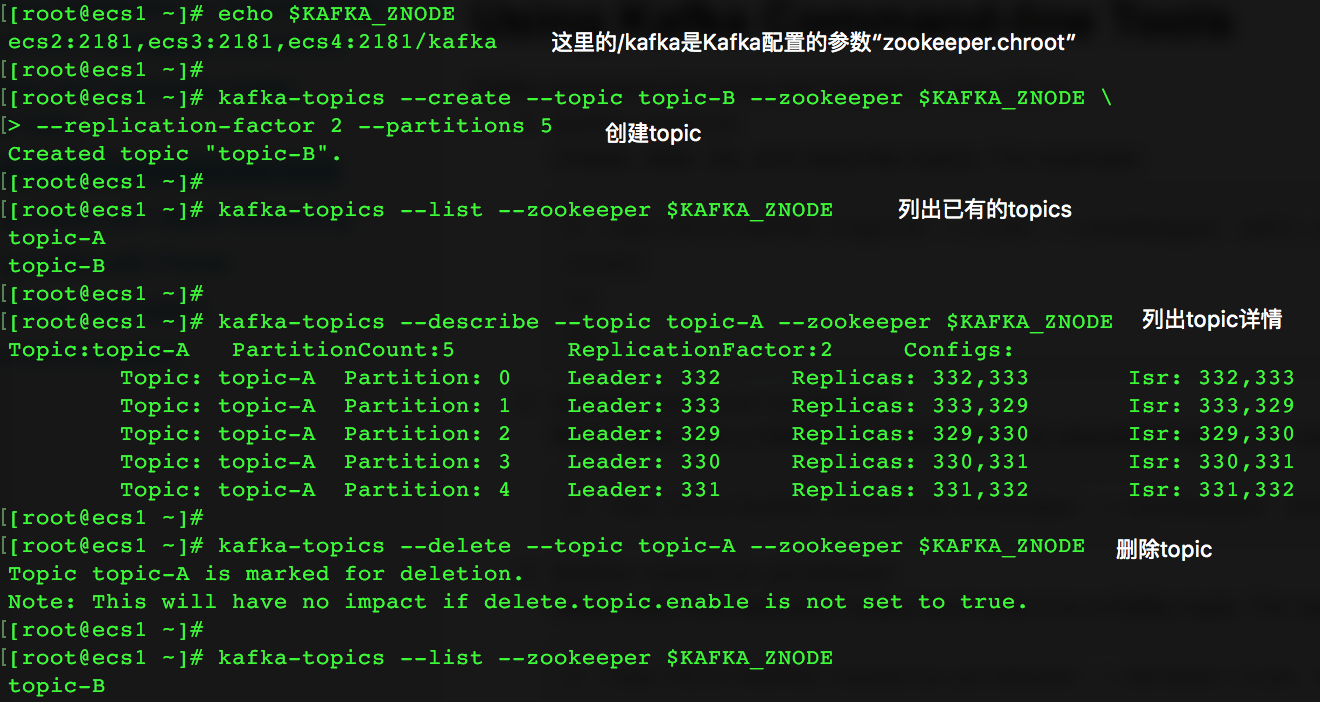
kafka-console-producer

kafka-console-consumer

如果没有参数“--from-beginning”,则不会显示任何消息,因此这个console consumer此时并没有建立与该topic关联的offset。
此时,我们从Kafka root znode中可以看到这个consumer:

4. Kafka 与 ZooKeeper
4.1 ZNODE
Kafka是一个分布式的消息系统,需要用到ZooKeeper的服务。
在配置Kafka时,与ZooKeeper相关的配置项是
zookeeper.chroot
ZK中的znode,将作为本Kafka集群的在ZK中的root znodezookeeper.session.timeout
如果Kafka server在这个时间段内没有向ZK发送心跳,则认为这个server失效了,默认值为6秒。
例如,我们将“zookeeper.chroot”配置为“/kafka”,那么通过ZK的命令行工具,可以看到znode “/kafka”中有如下的内容:
4.2 删除topic
当使用命令行删除某个topic时,实际上并不是立即真正地删除,而是将该topic标记为“删除”,如下

参考 When/how does a topic “marked for deletion” get finally removed?
4.3 Brokers
Kafka是怎样探测当前可用的brokers?
Kafka的配置项 zookeeper.chroot 指定了Kafka集群在ZK中使用的root znode,所有与该Kafka集群相关的ZK数据都会保存在该root znode下。Kafka客户端会根据命令中的 --zookeeper参数来查看当前可用的brokers。例如,如果这个参数为“{zk_quorum}/kafka”,那么可以看到这个目录下有这些数据:

其中的5个znode是5个brokers的broker_id。
