@xtccc
2016-01-10T00:46:28.000000Z
字数 17831
阅读 9975
Consumer API

Kafka
参考:
目录
1. 关于 High Level Consumer
使用High Level Consumer API,我们可以将精力集中在取到数据上,而不用关心取回数据的offset。High Level Consumer在从某个给定partition中取回一条消息时,会将该消息的offet存储在ZooKeeper中,对该offset的存储是基于该consumer的Consumer Group Name。
当一个consumer以某个Consumer Group Name启动时(并指定一个topic),Kafka会将该consumer线程加入到可以消费该topic的线程队列中,并且会触发“re-balance”。在“re-balance”的过程中,Kafka会对partitions与threads的对应关系进行调整,也许会将一个partition对应到一个新的thread。
2. 设计High Level Consumer
在创建一个High Level Consumer时,它应该是一个多线程的模型,且多线程模型须围绕目标Topic的partitions数量来规划。对于给定的Topic而言:
- 如果 # threads > # partitions,则一些threads将永远都收不到任何消息
- 如果 # threads < # partitions,则一些threads会从多个partitions那里收到消息
- 如果某个thread对应了多个partitions,则它收到消息的顺序是无法保证的:同一个partition内的消息是有序的,但是不同partitions之间的消息是无序的
- 增加processes/threads会引起re-balance,这将导致partition与thread对应关系的改变
3. High Level Consumer API 使用实例
/*** Created by tao on 6/24/15.* 这是一个简单的High Level Consumer Client*/public class ConsumerA implements Runnable {public String title;public KafkaStream<byte[], byte[]> stream;public ConsumerA(String title, KafkaStream<byte[], byte[]> stream) {this.title = title;this.stream = stream;}@Overridepublic void run() {System.out.println("开始运行 " + title);ConsumerIterator<byte[], byte[]> it = stream.iterator();/*** 不停地从stream读取新到来的消息,在等待新的消息时,hasNext()会阻塞* 如果调用 `ConsumerConnector#shutdown`,那么`hasNext`会返回false* */while (it.hasNext()) {MessageAndMetadata<byte[], byte[]> data = it.next();String topic = data.topic();int partition = data.partition();long offset = data.offset();int key = bytes2Int(data.key()); /** key和value都是bytes */String msg = new String(data.message()); /** 需要转换 */System.out.println(String.format("Consumer: [%s], Topic: [%s], PartitionId: [%d],Offset: [%d], Key: [%d], msg: [%s]" ,title, topic, partition, offset, key, msg));}System.err.println(String.format("Consumer: [%s] exiting ...", title));}/** 从bytes 转换到int */public int bytes2Int(byte[] bytes) {if (null == bytes || 4 != bytes.length)throw new IllegalArgumentException("invalid byte array");return java.nio.ByteBuffer.wrap(bytes).getInt();}}
// main方法Properties props = new Properties();props.put("group.id", "gid-1");props.put("zookeeper.connect", "ecs2:2181,ecs3:2181,ecs4:2181/kafka");props.put("auto.offset.reset", "largest");props.put("auto.commit.interval.ms", "1000");props.put("partition.assignment.strategy", "roundrobin");ConsumerConfig config = new ConsumerConfig(props);String topic = "topic-C";/** 创建 `kafka.javaapi.consumer.ConsumerConnector` */ConsumerConnector consumerConn =kafka.consumer.Consumer.createJavaConsumerConnector(config);/** 设置 map of (topic -> #streams ) */Map<String, Integer> topicCountMap = new HashMap<>();topicCountMap.put(topic, 3);/** 创建 map of (topic -> list of streams) */Map<String, List<KafkaStream<byte[], byte[]>>> topicStreamsMap =consumerConn.createMessageStreams(topicCountMap);/** 取出 `topic-B` 对应的 streams */List<KafkaStream<byte[], byte[]>> streams = topicStreamsMap.get(topic);/** 创建一个容量为3的线程池 */ExecutorService executor = Executors.newFixedThreadPool(3);/** 创建3个consumer threads */for (int i = 0; i < streams.size(); i++)executor.execute(new ConsumerA("消费者" + (i + 1), streams.get(i)));/** 给3个consumer threads 60秒的时间读取消息,然后令它们停止读取消息* 要先断开ConsumerConnector,然后再销毁consumer client threads** 如果不调用`consumerConn.shutdown()`,那么这3个消费者线程永远不会结束,* 因为只要ConsumerConnector还在的话,consumer会一直等待新消息,不会自己退出* 如果ConsumerConnector关闭了,那么consumer中的`hasNext`就会返回false* */Thread.sleep(60*1000);consumerConn.shutdown();/** 给3个consumer threads 5秒的时间,让它们将最后读取的消息的offset保存进ZK* */Thread.sleep(5*1000);executor.shutdown();
如果启动一个Producer,让它向“topic-C”发送16条消息,每条消息的key是整数,value是key的字符串形式,那么上面的Consumer代码的运行结果为:
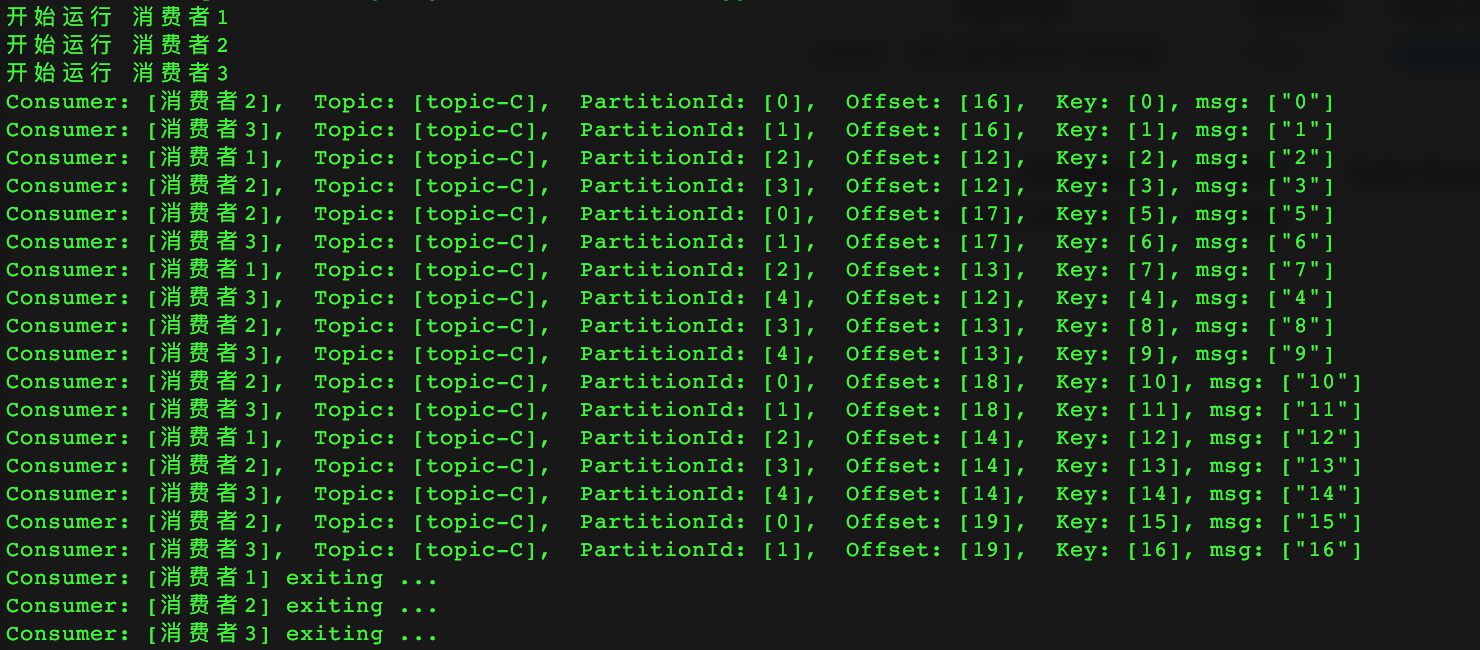
在Consumer收到的消息中,key和value都是byte array,因此需要对这些字节重新解码。
我们也可以在创建message streams时为key和value提供decoder,这样让consumer直接得到解码后的数据。
/** 在这里可以为key和value直接提供各自的 decoder,* 这样consumer thread 收到的解码后的数据* */Map<String, List<KafkaStream<Integer, String>>> topicStreamsMap =consumerConn.createMessageStreams(topicCountMap, new IntDecoder(), new StringDecoder());// 下面是两个解码器public static class IntDecoder implements Decoder<Integer> {@Overridepublic Integer fromBytes(byte[] bytes) {if (null == bytes || bytes.length != 4)throw new IllegalArgumentException("Invalid bytes");return java.nio.ByteBuffer.wrap(bytes).getInt();}}public static class StringDecoder implements Decoder<String> {@Overridepublic String fromBytes(byte[] bytes) {if (null == bytes )throw new IllegalArgumentException("Null bytes");return new String(bytes);}}
3.1 High Level Consumer配置
group.id
这是被创建Consumer实例的 group id,所有该配置相同的consumers都属于同一个consumer groupzookeeper.connect
这是Kafka集群所使用的ZooKeeper的服务URL。如果Kafka集群有“zookeeper.chroot”配置,那么本配置也要加上。本配置形如 node1:port,...,nodeN:port/{zookeeper.chroot}auto.offset.reset
如果ZK中不存在关于该Topic的初始offset,或者初始offset不在有效范围内,则被参数决定怎样重置offset。本配置的值可以为“smallest”或者“largest”auto.commit.interval.ms
Consumer将被消费的消息的offset写入ZK中保存,但不是每消费一条消息就保存一次,而是每间隔一段时间才向ZK中写一次。本配置就是这个时间间隔。partition.assignment.strategy
partitions与consumer threads对应的策略,默认值为“range”,也可以选择“roundrobin”
还有其他的很多配置,请见 Consumer Configs。
3.2 获取给定Topic的KafkaStream
每个KafkaStream代表一个消息流,里面的消息来自一个或者多个partitions(但是1个partition的消息只会流向1个KafkaStream),每1个KafkaStream应该由1个线程处理。
对于每一个KafkaStream,它将一直等待接收新的消息,每收到一条消息,it.hasNext()将会返回true。
3.3 正确地结束Consumer
Kafka并不是每读取一条消息就将该消息的offset写入到ZK中,而是每隔一段时间(由“auto.commit.interval.ms”控制)才将最后读取的消息的offset写入到ZK中。因此,如果简单地让Consumer直接退出,那么已被读取的消息的offset可能不会被更新到ZK中,这会造成下一次启动Consumer时读取到已被读过的消息。
造成Consumer读取到已被读过的消息,还有两种可能的原因:
- 丢失了一个broker
- 某个partition的leader发生变化
因此,需要一种优雅的方法结束Consumer。
我们采用的方法是:首先调用ConsumerConnector.shutdown(),这样,所有的KafkaStreams都不能继续消费数据;然后等待几秒钟,待Kafka将这些streams消费的最后一条消息的offset写入到ZK中之后,再调用ExecutorService.shutdown()命令线程池销毁所有已经运行完毕的线程。
3.4 处理Consumer Thread中的异常
当Consumer thread中发生异常时,我们需要捕获该异常并进行处理。怎样捕获该异常取决与Consumer Thread是怎样被提交的。
4. 相关异常
4.1 ConsumerRebalanceFailedException
在启动一个Consumer时,报错:
kafka.common.ConsumerRebalanceFailedException: gid-1_ecs1.njzd.com-1452137308525-b23962d3 can't rebalance after 4 retries
这个原因往往是因为:在启动Consumer(不妨成为c1)时,Kafka试图进行“re-balance”,实际上已经有另外一个Consumer(不妨称其为c2)在运行了,,而且c1与c2有相同的consumer group name。
触发“re-balance”的一个原因为:···
这时可以查看ZK中的数据:

只要将c2关掉,即可正常运行c1.
关掉c2之后,可以看到ZK中的数据如下:

5. 关于Simple Consumer API
使用High Level Consumer API,我们可以不关心offset等细节,直接从topic中读取数据。但在有些场景中,我们要更精确地控制读取数据的细节:
- 对同一条消息读取多次
- 只读取部分partitions中的消息
- 确保对每条消息处理1次且仅1次
使用Simple Consumer API要比High Level Consumer API更加复杂,这表现在:
- 用户需要自己保存offset
- 用户必须知道给定(topic, partition)的leader是哪一个broker
- 用户需要自己处理leader broker的切换
6. 使用Simple Consumer API
使用Simple Consumer API的步骤如下:
- 向一个active broker发起查询,找出哪一个broker是目标(topic, partition)的leader和replica brokers
- 确定从哪个offset开始读取消息
- 取回数据
- 检测leader的变动,并做出相应的调整
6.1 为(topic, partition)找到leader broker与replica brokers
public class SimpleConsumerUtil {/*** 为给定的(topic, partition)找到它的leader broker* seedBrokers并不一定要是全部的brokers,只要包含一个live broker,* 通过这个live broker去查询Leader broker的元数据即可* */public PartitionMetadatafindLeader(List<String> seedBrokers, int port, String topic, int partition) {PartitionMetadata retMeta = null;/** 循环地查询 */loop:for (String broker : seedBrokers) { /** 按照每一个 broker 循环*/SimpleConsumer consumer = null;try {/** 连接到不同的broker时,需要对该broker创建新的`SimpleConsumer`实例 */consumer = new SimpleConsumer(broker, port, 100*1000, 64*1024,"leaderLookupClient");List<String> topics = Collections.singletonList(topic);TopicMetadataRequest req = new TopicMetadataRequest(topics);/** Fetch metadata for a sequence of topics, which* returns metadata for each topic in the request */TopicMetadataResponse resp = consumer.send(req);/** 在某个broker上按照每一个topic循环,并检查一个topic中的每一个partition */for (TopicMetadata topicMeta : resp.topicsMetadata()) {for (PartitionMetadata parMeta : topicMeta.partitionsMetadata()) {if (parMeta.partitionId() == partition) {retMeta = parMeta; /** 根据 partition id 进行匹配,找到了就退出 */break loop;}}}} catch (Exception ex) {System.err.println("Error: 在向Broker “" + broker +"” 询问 (Topic=“" + topic + "”, Partition=“" + partition+ "”) 的Leader Broker 时发生异常,原因为: \n" + ex.toString());} finally {if (null != consumer)consumer.close(); /** 关闭连接到该broker的`SimpleConsumer`*/}} // end => for (String broker : seedBrokers)return retMeta;}}
下面我们测试这个方法是否能够找出(Topic = “topic-C”, Partition=0)的partition metadata。
/*** 测试`SimpleConsumerUtil#findLeader`方法的使用* 找到(Topic=“topic-C”, Partition=0)当前的leader partition* */public static void TestFindLeader() {SimpleConsumerUtil consumer = new SimpleConsumerUtil();List<String> seedBrokers = new ArrayList<>();seedBrokers.add("ecs1.njzd.com");seedBrokers.add("ecs3.njzd.com");PartitionMetadata parMeta = consumer.findLeader(seedBrokers, 9092, "topic-C", 0);System.out.println("Partition metadata for (Topic=“topic-C”, Partition=“0”) is : \n"+ parMeta + "\n");}
运行结果为:

我们可以查询(Topic=“topic-C”, Partition=“0”)的真实metadata是什么样的,看看上面的代码查询出来的结果对不对。

6.2 确定从哪个offset开始读取消息
使用Simple Consuer API,读取消息时要根据(Topic, Partition, Offset)这个坐标来获取消息,因此,我们需要确定给定(Topic, Partition)的offset,才能进行消息的读取。
在查询时,只能向目标(topic, partition)的leader partition(leader broker)进行查询,不能向replica partitions(follower brokers)进行查询。
public class SimpleConsumerUtil {/*** 确定从(topic, partition)的什么地方开始读取消息,即确定offset* Kafka提供了2个常量:* `kafka.api.OffsetRequest.EarliestTime()`找到log data的开始时间* `kafka.api.OffsetRequest.LatestTime()`是最新的时间** 最旧的offset并不一定是0,因为随着时间的推移,部分数据将被从log中移除*** 这里传入的参数`consumer`的host必须是(topic, partition)的leader,* 否则会报错,错误代码为6** 各种失败代码的含义可以查询这里:kafka.common.ErrorMapping* */public longgetLastOffset(String leaderHost, int port, String clientId,String topic, int partition, long time) {/** 用leader host 创建一个SimpleConsumer */SimpleConsumer consumer =new SimpleConsumer(leaderHost, port, 100*1000, 64*1024, clientId);TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition);Map<TopicAndPartition, PartitionOffsetRequestInfo> reqInfo = new HashMap<>();reqInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(time, 1));OffsetRequest req =new OffsetRequest(reqInfo, kafka.api.OffsetRequest.CurrentVersion(), clientId);OffsetResponse resp = consumer.getOffsetsBefore(req);consumer.close();/** 处理失败 */if (resp.hasError()) {short errorCode = resp.errorCode(topic, partition);System.err.println("为 (Topic=“" + topic + "”, Partition=“" + partition +"”, Time=“" + time + "”) 查询 offset 失败,失败代码为:" + errorCode +", 失败原因为: " + ErrorMapping.exceptionFor(errorCode));return -1;}/** 为什么这里返回的是数组?数组中会有几个数据?* 经过实际的测试,里面只有1个数据 */long[] offsets = resp.offsets(topic, partition);return offsets[0];}}
下面测试:查询(Topic=“topic-C”, Partition=“1”)的最老offset、最新offset和当前offset:
/**** 测试`ConsumerB#getLastOffset`方法的使用* 找出(Topic=“topic-C”, Partition=1)的最老、最新、当前的offset* */public static void TestGetLastOffset() {List<String> brokers = new ArrayList<>();brokers.add("ecs1");brokers.add("ecs4");int port = 9092;String topic = "topic-C";int partition = 1;/*** 首先查询出(Topic=“topic-C”, Partition=“1”)的leader broker's hostname* */SimpleConsumerUtil util = new SimpleConsumerUtil();PartitionMetadata parMeta = util.findLeader(brokers, port, topic, partition);String leaderHost = parMeta.leader().host();/** 最老的offset(依然在log中的msg)*/long earliestOffset = util.getLastOffset(leaderHost, port, "Client - 查询offset",topic, partition, OffsetRequest.EarliestTime());/** 最新的offset */long latestOffset = util.getLastOffset(leaderHost, port, "Client - 查询offset",topic, partition, OffsetRequest.LatestTime());/** 当前的offset */long currentOffset = util.getLastOffset(leaderHost, port, "Client - 查询offset",topic, partition, System.currentTimeMillis());System.out.println("(Topic=“" + topic + "”, Partition=“" + partition +"”) 的leader host是" + leaderHost);System.out.println("(Topic=“" + topic + "”, Partition=“" + partition +"”) 中的offsets: " +"\n\tEarliest Offset: " + earliestOffset +"\n\tLatest Offset: " + latestOffset +"\n\tCurrent Offset: " + currentOffset);}
运行的结果为:

6.3 寻找新的leader broker
如果某个(topic, partition)的leader broker崩溃了,那么ZooKeeper会检测到这种情况的发生,并重新为它分配一个new leader。
我们在使用Simple Consumer API时,需要能够处理这种问题的发生,并查询出新的leader broker。
public class SimpleConsumerUtil {/*** 当原来的leader崩溃后,找出新的leader* */public BrokerfindNewLeader(String oldLeader, List<String> replicaBrokers, int port,String topic, int partition) {/*** 最多尝试5次,如果还找不到则查询new leader失败* */for (int loop = 0; loop < 5; loop++) {boolean willSleep = false;PartitionMetadata parMeta = findLeader(replicaBrokers, port, topic, partition);if (null == parMeta || null == parMeta.leader())willSleep = true;/*** 如果leader broker 崩溃,ZooKeeper会探测到这个情况的发生,并重新分配一个new leader broker* 这个过程需要很短的时间* 如果在第一次循环中,发现 new leader broker 等于 old leader broker,* 则睡眠1秒钟给ZK进行调整,并重新尝试查询new leader* **/else if (oldLeader.equalsIgnoreCase(parMeta.leader().host()) && 0 == loop) {willSleep = true;} else {return parMeta.leader();}/*** 睡眠1秒钟,给Kafka和ZooKeeper进行调整(failover)等* */if (willSleep)try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}// 查询失败return null;}}
测试这个方法的使用:
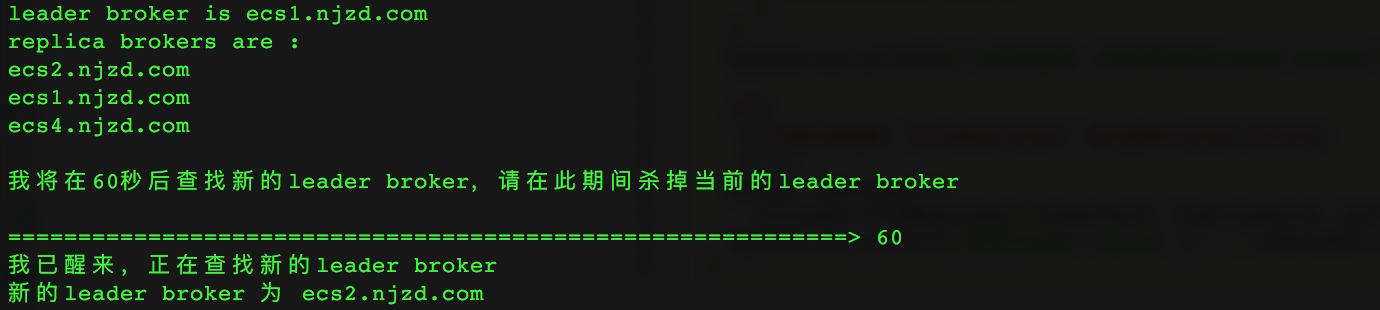
/*** 测试`ConsumerB#findNewLeader`方法的使用** 测试方法:先找出一个leader broker,然后将该broker关掉,* 再使用`ConsumerB#findNewLeader`方法找出新的leader,* 检查能否正确地找出新leader** */public static void TestFindNewLeader() {/*** 首先找到(Topic=“topic-C”, Partition=2)的leader broker与replica brokers* */SimpleConsumerUtil consumer = new SimpleConsumerUtil();List<String> seedBrokers = new ArrayList<>();seedBrokers.add("ecs1.njzd.com");seedBrokers.add("ecs3.njzd.com");int port = 9092;String topic = "topic-C";int partition = 2;PartitionMetadata parMeta = consumer.findLeader(seedBrokers, port, topic, partition);String leaderHost = parMeta.leader().host();List<Broker> replicas = parMeta.replicas();List<String> replicaHosts = new ArrayList<String>();for (Broker broker : replicas)replicaHosts.add(broker.host());// 打印出当前的leader brokerSystem.out.println("leader broker is " + leaderHost +"\nreplica brokers are : ");for (Broker replica : replicas)System.out.println(replica.host() + " ");// 开始120秒倒计时,请杀掉当前的leader brokerSystem.out.println("\n将在60秒后查找新的leader broker,在此期间请杀掉当前leader broker\n");for (int i = 1; i <= 60; i++) {System.out.print("\r");for (int j = 1; j <= i; j++)System.out.print("=");System.out.print("> " + i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}System.out.println("\n我已醒来,正在查找新的leader broker");/*** 下面开始调用 `findNewLeader` 找出新的leader broker* */Broker newLeader =consumer.findNewLeader(leaderHost, replicaHosts, port, topic, partition);System.out.println("新的leader broker 为 " + newLeader.host());}
运行结果:
6.4 读取数据
6.4.1 读取方法
读取数据时,要指定(topic, partition, offset, size)这4个参数。
public class SimpleConsumerUtil {/*** 从Kafka中读取消息* 这个函数中,我们假定读取的消息的key是Int, value是String* 每收到一条消息,会将它的内容在控制台上显示出来* */public voidreadData(List<String> seedBrokers, int port, String clientId,String topic, int partition, long reqOffset, int fetchSize) {System.out.println("[Info]: 开始读取数据\n");/** 首先查询(topic, partition)的leader broker */PartitionMetadata parMeta = findLeader(seedBrokers, port, topic, partition);String leaderHost = parMeta.leader().host();List<Broker> replicaBrokers = parMeta.replicas();/** 为这个leader partition 创建一个SimpleConsumer */SimpleConsumer consumer =new SimpleConsumer(leaderHost, port, 100*1000, 64*1024, clientId);/*** 处理错误响应,最多重试5次* **/FetchResponse resp;int numErrors = 0;while (true) {/** 创建FetchRequest,并利用SimpleConsumer获取FetchResponse */resp = consumer.fetch(new FetchRequestBuilder().clientId(clientId).addFetch(topic, partition, reqOffset, fetchSize).build());if (resp.hasError()) {numErrors++;short errorCode = resp.errorCode(topic, partition);String errorMsg = ErrorMapping.exceptionFor(errorCode).toString();System.err.println("[Error]: 请求获取消息时出现错误: " +"\n\t目标lead broker为 " + consumer.host() +", 错误代码为 " + errorCode +", 错误原因为 " + errorMsg);if (5 == numErrors) {System.err.println("错误次数达到5,不再重试,退出!");consumer.close();return;}/** 这种错误不需要重新寻找leader partition */if (errorCode == ErrorMapping.OffsetOutOfRangeCode()) {reqOffset = getLastOffset(leaderHost, port, clientId,topic, partition, kafka.api.OffsetRequest.LatestTime());System.err.println("[Error]: request offset 超出合法范围,自动调整为" + reqOffset);continue; // 用新的offset重试}/** 用新的leader broker来创建SimpleConsumer */else {List<String> replicaHosts = new ArrayList<String>();for (Broker broker : replicaBrokers)replicaHosts.add(broker.host());leaderHost = findNewLeader(leaderHost, replicaHosts,port, topic, partition).host();/*** 用新的leader来创建一个SimpleConsumer* */consumer.close();consumer =new SimpleConsumer(leaderHost, port, 100*1000, 64*1024, clientId);}} else {break; /** 没有发生错误则直接跳出循环 */}} // End => while (true)consumer.close();/*** 开始真正地读取消息*/long numRead = 0;for (MessageAndOffset data : resp.messageSet(topic, partition)) {/** 要确保:实际读出的offset 不小于 要求读取的offset。* 因为如果Kafka对消息进行压缩,那么fetch request将会返回whole compressed block,* 即使我们要求的offset不是该 whole compressed block的起始offset。* 这可能会造成读取到之前已经读取过的消息。* */long currentOffset = data.offset();if (currentOffset < reqOffset) {System.err.println("[Error]: Current offset = " + currentOffset +", Requested offset = " + reqOffset + ", Skip. ");continue;}/** `nextOffset` 向最后被读取的消息发起询问:“下一个offset的值是什么?” */long nextOffset = data.nextOffset();/** Message结构中包含: bytes, key, codec, payloadOffset, payloadSize */Message msg = data.message();ByteBuffer keyBuf = msg.key();byte[] key = new byte[keyBuf.limit()];keyBuf.get(key);ByteBuffer payload = msg.payload();byte[] value = new byte[payload.limit()];payload.get(value);System.out.printf("消息$%-2d , offset=%-2d , nextOffset=%-2d" +" , key=%-2d , value=%s \n",numRead+1, currentOffset, nextOffset, bytes2Int(key), bytes2Str(value));numRead++;}System.out.println("[INFO]: 读取完毕,共读取了 " + numRead + " 条消息");}}
6.4.2 测试读取方法
调用上面的方法进行测试:
/*** 测试方法 : readData** */public static void TestReadData(String topic, int partition,long reqOffset, int fetchSize) {List<String> brokers = new ArrayList<>();brokers.add("ecs1");brokers.add("ecs4");int port = 9092;SimpleConsumerUtil util = new SimpleConsumerUtil();util.readData(brokers, port, "ClientReadData",topic, partition, reqOffset, fetchSize);}
在测试前,我们创建了“topic-D”,它有3个partition。 随后,我们向“topic-D”写入了17条消息,每条消息的key是int,value是String,每条消息的key,value,partitionId如下(可以看出,key所在的partition = key%numPartitions):
partition 0中消息的key为
{0, 3, 6, 9, 12, 15} 共6条消息partition 1中消息的key为
{1, 4, 7, 10, 13, 16} 共6条消息partition 2中消息的key为
{2, 5, 8, 11, 14} 共5条消息
下面从几个方面来对“topic-D”测试读取过程。
6.4.2.1 测试:读取各个partition中的全部消息
指定reqOffset=0, fetchSize=10000,变幻partition:
- partition=0

- partition=1

- partition=2

总结:
- 对一个consumer而言,它要处理一个topic中每个partition的offset
- 在一个partition中,1条消息占用的offset是1,不论消息的字节数有多少,每读取一条消息,offset就应该往后加1,即offset指的是一条消息在partitin中的偏移量,与这条消息的大小无关
6.4.2.2 测试:读取时指定各种fetchSize
指定 partition=0, reqOffset=0, 变幻fetchSize
fetchSize=36

fetchSize=37

fetchSize=73

fetchSize=74

这说明在我们的这个例子中,一条消息的((0, "msg-0")或者(3, "msg-3"))所占的大小为37个字节。
如果要读取key为{0, 3, 6, 9}的这4条消息,fetchSize应该为37 * 4 = 148。下面验证:
fetchSize=147

fetchSize=148

如果要再读取下一条消息(12, "msg-12"),则fetchSize应该为 148 + 37 + 1 = 186,因为key为12的消息,它的value比前面几条消息的value多了一个字节。下面验证。
fetchSize=185

fetchSize=186

