@xtccc
2016-01-03T03:44:51.000000Z
字数 3775
阅读 4563
Serialization

Spark
Spark的序列化
Spark数据以records的形式进行流动,record以两种形式存在:序列化的字节数组与反序列化的Java对象。一般来说,Spark存放在内存中的records是deserialized Java objects,在磁盘中存储及在网络中传输的records是serialized bytes。
目前,将in-memory shuffle data以序列化的形式来存储的工作正在进行中,参见SPAKR-2926。
在写Spark的应用时,尝尝会碰到序列化的问题。例如,在Driver端的程序中创建了一个对象,而在各个Executor中会用到这个对象 —— 由于Driver端代码与Executor端的代码运行在不同的JVM中,甚至在不同的节点上,因此必然要有相应的序列化机制来支撑数据实例在不同的JVM或者节点之间的传输。
什么时候需要调用序列化?
结论
先把结论给出:
- RDD自身是serializable,不论里面的数据类型是不是serializable,这一点可以参考RDD的定义
- closure必须是serializable
- 从execturor传递到driver的数据可以是unserializable
- 如果一个Java class
implements Serializable,则这个类是serializable
以类UnserializableBean为例,下面分别给出说明。
RDD自身是serializable
测试代码:
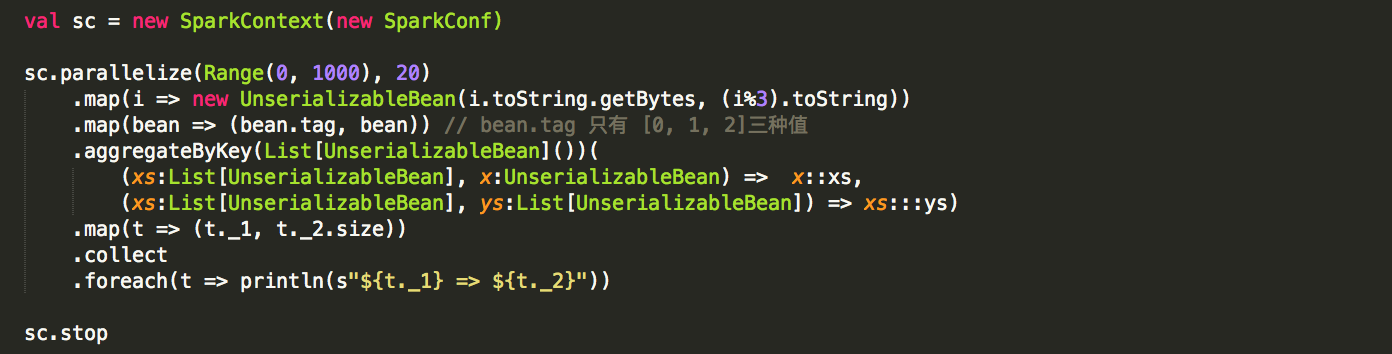
运行结果

所以,可以证实本结论。
Clousure必须是Serializable

这里的bytes是在driver中创建的变量,且它被用在了closure中,是captured variable。
一个closure中的全部captured variables都是serializable,这个closure才是serializable。
运行这些代码会报错,因为ImmutableBytesWritable自身是unserializable。
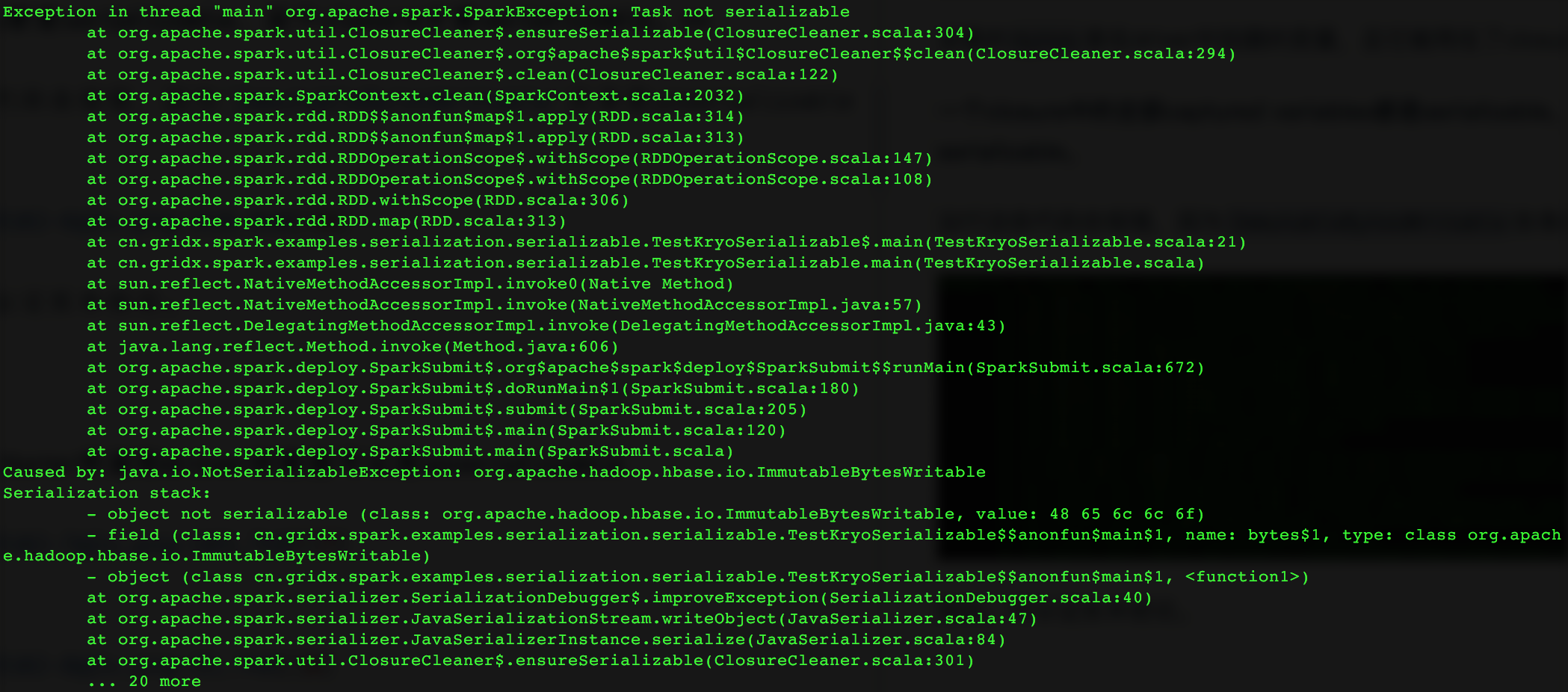
因此,可以证实本结论。
值得注意的是:目前对闭包的序列化只支持Java Serializer。
从execturor传递到driver的数据是serializable
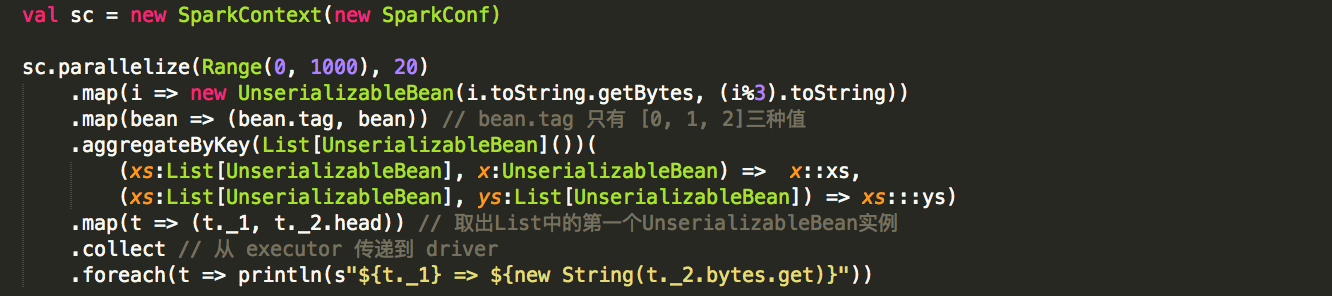
运行结果

这里,虽然UnserializableBean是不可序列化的类,但是当将该类型的数据从executor传递到driver时,并没有出现异常。因此,可以证实本结论。
什么样的数据类型能够被Spark序列化
首先给出结论:不论是使用Java的序列化框架,还是使用Kryo的序列化框架,自定义的class都必须 implements java.io.Serializable 才能被序列化。
Learning Spark 中对序列化有如下描述:
Whether using Kryo or Java's serializer, you may encounter a NotSerializableException if your code refers to a class that does not extend Java's Serializable interface.
例如,下面是一个自定义的类 CustomBean:
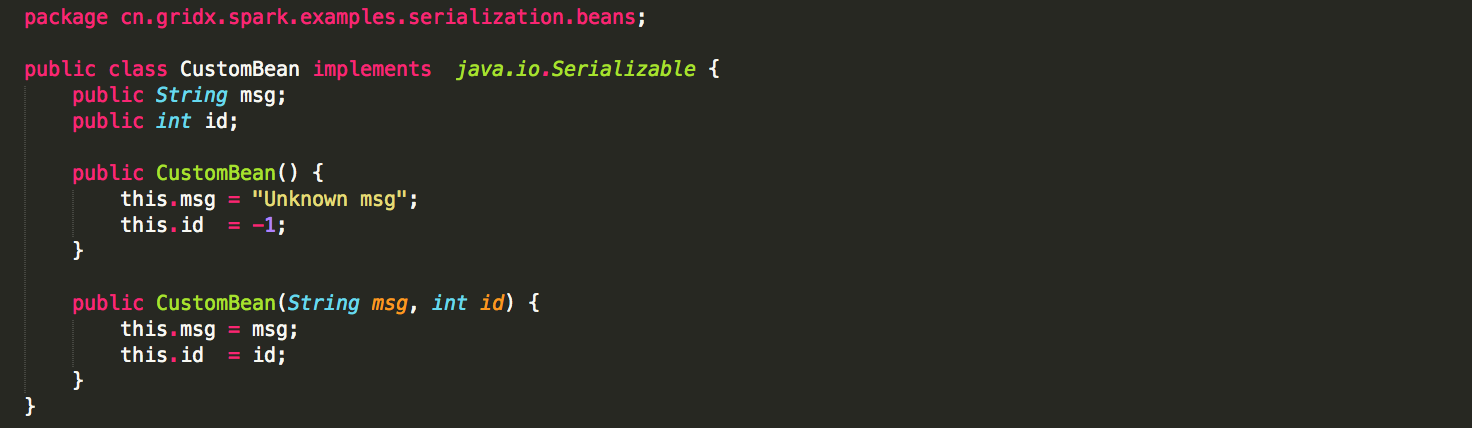
它可以被如下使用:
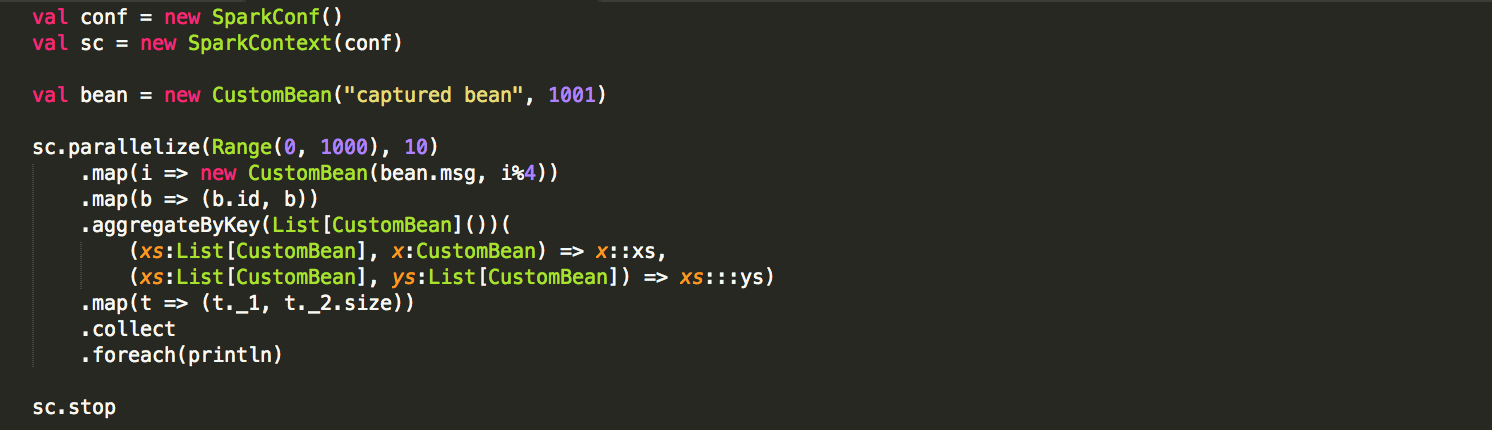
如果我们使用了第三方的类,但是这个类没有实现 java.io.Serializable 接口,而且我们也无法修改这个第三方类的实现,怎么办?
Learning Spark 由如下描述:
If you cannot modify the class in question you will need to use some advanced workarounds, such as creating a subclass of the type in question that implements Java's Serializable interface or customizing the serialization behavior using Kryo.
如果需求是从driver向executor传递一个class instance,则可以通过broadcast来实现,即使该class没有implements Serializable,或者包含无法被序列化的成员:
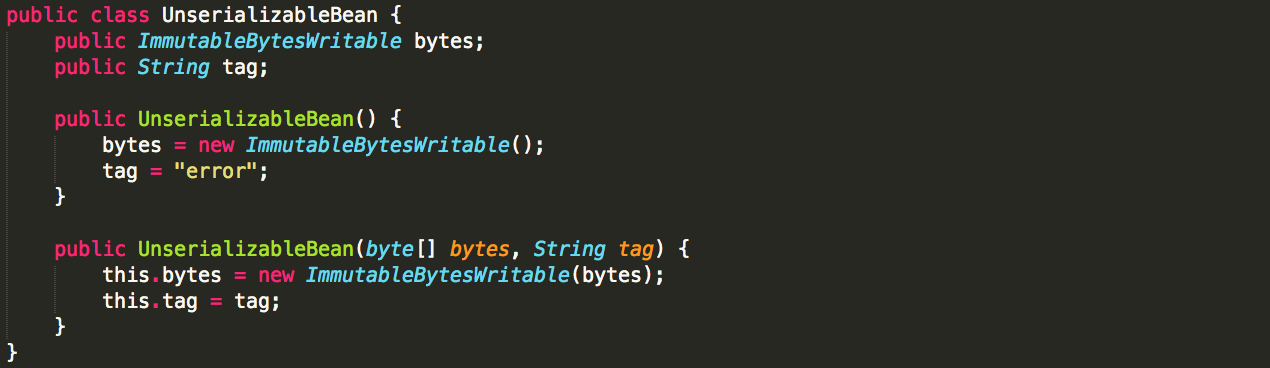
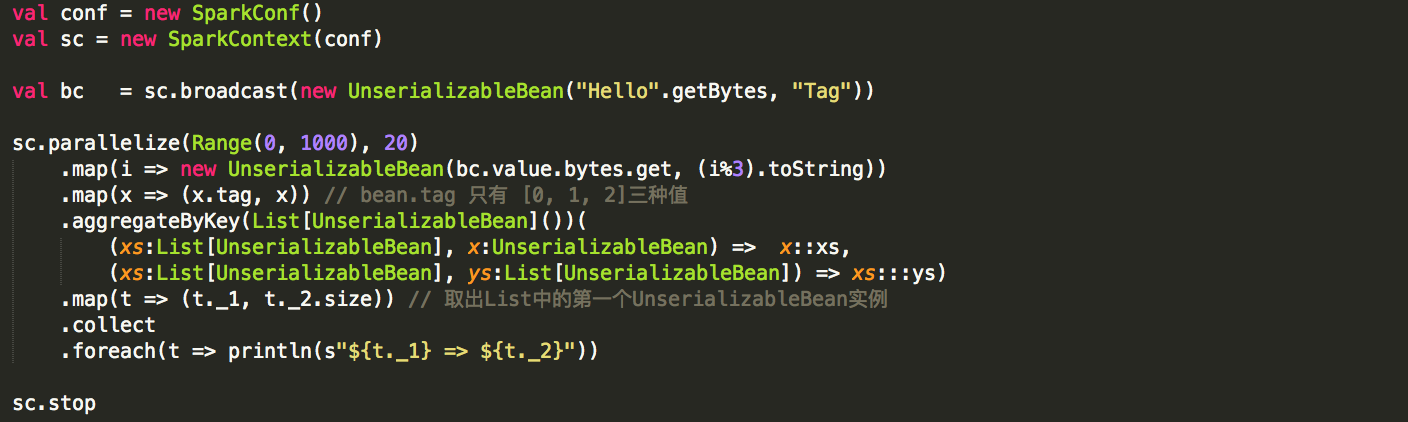
Kryo
根据 Tuning Spark,Spark默认使用Java的序列化框架。『只要一个class实现了java.io.Serializable接口,那么Spark就能使用Java的ObjectOutputStream来序列化该类』。
实际上,Spark还支持另一种序列化框架 —— Kryo 。 Kryo是一个高效的序列化框架(可以比Java的序列化快10倍以上)。但是Kryo并不能支持所有的Serilizable class,因此需要在使用Kryo前对目标类进行注册(register)。
使用Kryo作为Spark的序列化框架的方法如下:

其中:
SparkConf#set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")要求将Kryo作为Spark的序列化框架
SparkConf#registerKryoClasses是为Kryo注册需要被序列化的classes
有一些其他的参数可以设置:
spark.kryoserializer.buffer.max
Kryo serialization buffer允许的最大值,必须大于要序列化的最大对象,默认值为“64m”。如果遇到异常“buffer.limit.exceeded”,则要增大该值。
spark.kryoserializer.buffer
Kryo serialization buffer的初始大小,在worker上的每一个core都会有一个buffer,默认值为“64k”。如果需要的话,Kryo serialization buffer将会增大,最大值为“spark.kryoserializer.buffer.max”。
- spark.kryo.referenceTracking
spark.kryo.registrationRequired :
如果设置为“true”,那么当试图序列化一个未注册的class时,Kryo会抛出异常;如果设置为“false”,Kryo则会将未注册的class的类名与每一个类实例一起写入序列化的结果,这会大大增加序列化的负担。 当该参数被设置为“true”时,会要求将所有需要被Kryo序列化的类都必须被注册。如果我们仅仅注册自己定义的class,则运行时会爆出异常,显示以下class还未注册,例如: `scala.collection.immutable.Nil`,`scala.collection.immutable.Range`,`scala.collection.immutable.$colon$colon`,`scala.Tuple2`···。 实际上,这是一个[bug](https://github.com/apache/spark/pull/8465),因为这些Scala的基础类不应该由用户进行注册,这在Spark 1.6中将被修复。 目前的建议是,不要将该参数设置为“true”。
- spark.kryo.classToRegister
闭包相关的序列化
什么是闭包
闭包的序列化
看一个例子:
class MyCoolApp {val repos: RDD[Repository] = ···val team: RDD[String, List[String]] = ···def projects() = {val filtered = repos.filter { repo =>team.exists(user => repo.contri.contains(user))}filyered.collect}}
运行上面的例子会报错:java.io.NotSerializableException
原因是:第6行~第8行代码构成的closure无法被序列化。
那么,一个闭包怎样才能被序列化呢?
A closure is serializable if all captured variables are serialzable.
这个闭包中的captured variables是哪些呢?
乍一看,变量 team 是唯一的captured variable,实际上,this (team所在的MyCoolApp实例)才是captured variable。但是,类MyCoolApp不能被序列化,因为它没有实现接口 Serializable
令closure可以序列化
怎样解决上面的问题呢?
可以用local variable来代替class field:
class MyCoolApp {val repos: RDD[Repository] = ···val team: RDD[String, List[String]] = ···val localTeam = teamdef projects() = {val filtered = repos.filter { repo =>localTeam.exists(user => repo.contri.contains(user))}filyered.collect}}
值得注意的是:目前对闭包的序列化只支持Java Serializer。
