@xtccc
2015-12-29T02:49:03.000000Z
字数 2188
阅读 3070
HA

HDFS
什么是HA
在Hadoop 2.0之前,Namenode是HDFS的一个单点故障(SPOF),如果Namenode退出或者崩溃,则HDFS系统就无法对外提供服务。
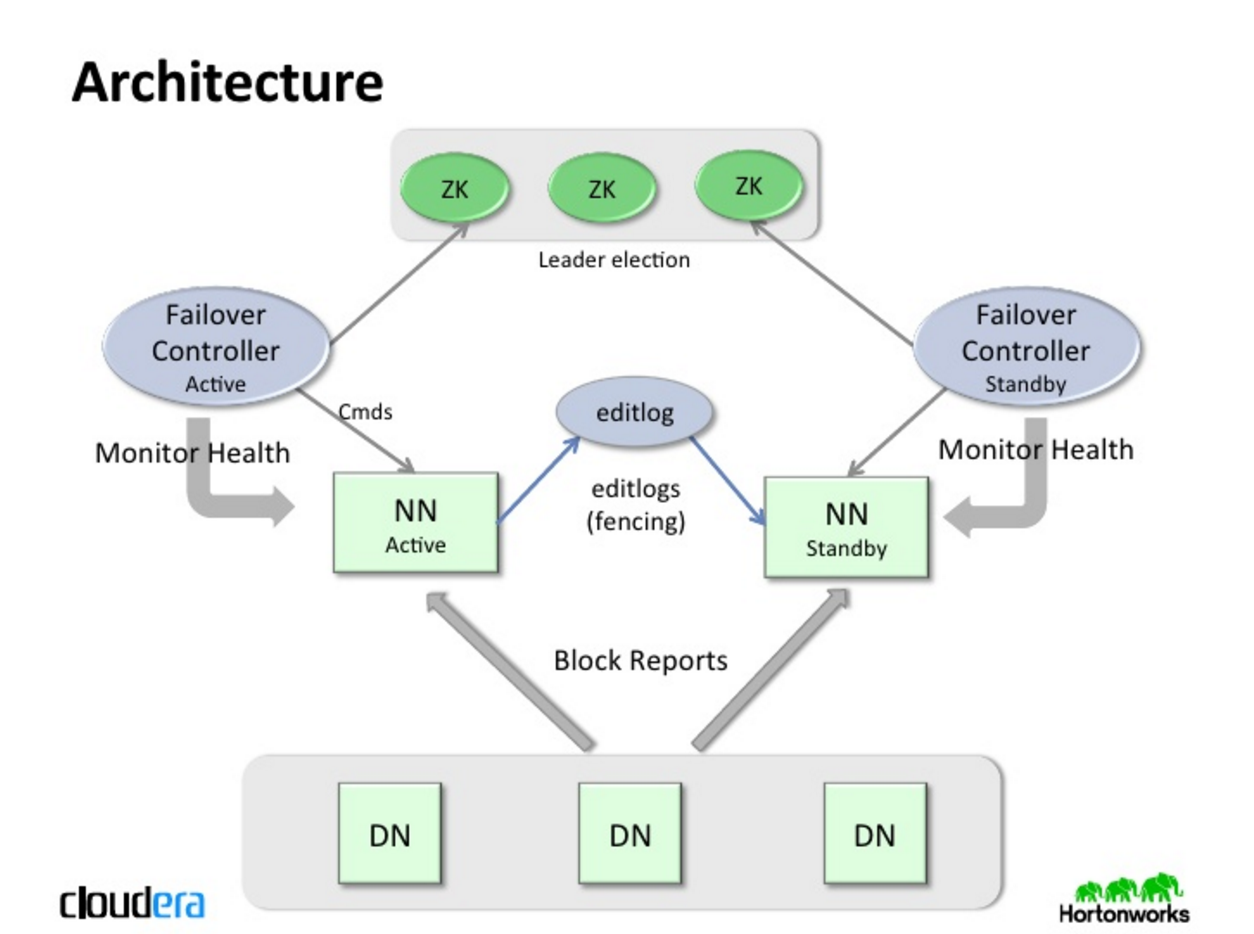
HDFS High Availability(HA) 则解决了这个问题,它在同一个HDFS cluster中运行两个Namenode(分别在两个节点上)。在任何时间,其中一个Namenode处于 Active 状态(称为Active Namenode),另一个Namenode处于 Standby 状态(称为Standby Namenode)。Active Namenode负责对外部全部clients提供HDFS服务,Standby Namenode则只保存Active Namenode的状态,便于实现快速的故障恢复。
Standby Namenode为了使自己的状态数据能够与Active Namenode保持同步,目前的HA实现中要求这个两个节点能够访问共享存储系统(例如NFS,或者Quorum-Based Storage URI)中的某个目录,但是这个限制在今后的版本中可能被放宽。
当Active Namenode对HDFS中的数据进行改动后,Active Namenode会将修改记录写入到共享目录的一个edit log file中,Standby Namenode会始终监视这个共享目录,并同步状态的变动。
在实现快速故障恢复时,Standby Namenode必须知道HDFS中blocks的位置信息。因此,在配置HDFS HA时,Datanodes会知道这两个Namenodes的位置信息,并将block location information与心跳发送给它们俩。
部署HA
HDFS HA cluster中所有的节点都可以拥有相同的配置,而不需要基于节点的类型去分别部署不同的配置文件。
类似于HDFS Federation,HDFS HA cluster使用 nameservice ID 来标识一个HDFS实例,尽管它可能包含多个HA Namenodes。实际上, HDFS HA 引入了一个新的概念 —— NameNode ID,集群中的每一个Namenode都有自己的NameNode ID。
为了实现所有的Namenodes共用一套相同的配置文件,相关的配置项参数会将 namespace ID 和 NameNode ID 作为后缀。
client怎样连接HDFS?
在HDFS HA cluster中,有2个Namenodes,因此client在访问时HDFS服务时,不需要指定Namenode的地址,而是指定一个 Nameservice(由core-site.xml中的参数 fs.defaultFS决定),客户端根据这个Nameservice可以自己判定去访问哪一个Namenode。
例如,如果core-site.xml中的内容如下:
<property><name>fs.defaultFS</name><value>hdfs://nameservice1</value></property>
那么,可以用下面的URL来访问HDFS的某个目录/文件
hdfs dfs -ls hdfs://nameservice1/user/tao/jars
SecondaryNamenode V.S. StandbyNamenode
在HDFS HA cluster中,Standby Namenode也会对namespace state进行checkpoing,因此不需要在集群中运行Secondary Namenode、CheckpoingNode或者BackupNode(如果这么做会引发错误)
。
SecondaryNamenode的作用是不同的:
The NameNode stores modifications to the file system as a log appended to a native file system file, edits. When a NameNode starts up, it reads HDFS state from an image file, fsimage, and then applies edits from the edits log file. It then writes new HDFS state to the fsimage and starts normal operation with an empty edits file. Since NameNode merges fsimage and edits files only during start up, the edits log file could get very large over time on a busy cluster. Another side effect of a larger edits file is that next restart of NameNode takes longer.
The secondary NameNode merges the fsimage and the edits log files periodically and keeps edits log size within a limit. It is usually run on a different machine than the primary NameNode since its memory requirements are on the same order as the primary NameNode.
