@Team
2020-12-13T06:06:47.000000Z
字数 963
阅读 2243
CondInst:性能和速度均超越Mask RCNN的实例分割模型
我是小将
对于实例分割来说,主流的做法还是基于先检测后分割的流程,比如最流行的Mask RCNN模型就是构建在Faster RCNN基础上。目前基于one-stage的物体检测模型已经在速度和性能上超越two-stage模型,同样地,大家也希望能找到one-stage的实例分割模型来替换Mask RCNN。目前这方面的工作主要集中在三个方向:
- Mask encoding:对2D mask编码为1D representation,比如PolarMask基于轮廓构建了polar representation,而MEInst则将mask压缩成一个1D vector,这样预测mask就类似于box regress那样直接加在one-stage检测模型上;
- 分离检测和分割:将检测和分割分离成两个部分这样可以并行化,如YOLACT在检测模型基础上额外预测了一系列prototype masks,然后检测部分每个instance会预测mask coeffs来组合masks来产生instance mask,BlendMask是对这一工作的进一步改进;
- 不依赖检测的实例分割:不依赖检测框架直接进行实例分割,TensorMask和SOLO属于此种类型,前者速度太慢,后者速度和效果都非常好;
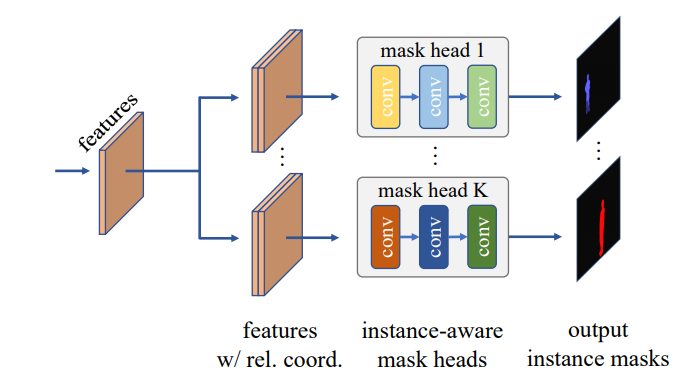
对于mask encoding方法,虽然实现起来比较容易,但是往往会造成2D mask的细节损失,所以性能上会差一点;分离检测和分割,对于分割部分可以像语义分割那样预测global mask,分辨率上会更高(要知道Mask RCNN的mask分辨率只有28x28),但是这种方法需要一种好的方式来产生instance mask;不依赖检测而直接进行实例分割这可能是未来的趋势。这里介绍的CondInst,其实属于第二种,但是它与YOLACT不同,其核心点是检测部分为每个instance预测不同的mask head,然后基于global mask features来产生instance mask,思路非常简单,而且实现起来也极其容易(已经开源在AdelaiDet),更重要的是速度和效果上均超越Mask RCNN。