@Team
2019-09-02T17:09:01.000000Z
字数 6372
阅读 4191
送给即将入学的你们—炼丹师修炼手册
陈扬
前段时间我一直在外面比赛,好久没有认认真真的坐在电脑前写一写东西了。这一年以来,随着我个人对深度神经网络的学习逐渐深入,也开始看到有所收获。正好这段时间我们实验室新来了8位研一的小伙伴,我也借此分享一些我个人的学习经验和心得给大家吧。
关于深度学习我一点个人见解

我想,你们在选择了进入组里之前想必是应该或多或少是听过现在仍然很火的人工智能,也许你们一时半会对于深度神经网络这样的名词还觉得很高大上,也许你还在思考着 SVM 和 MLP 到底是什么,或许是一知半解的在网上搜着 NLP、CV 等等等。
其实在我看来,深度神经网络并不是什么很复杂的东西,他在本质上和一个二元函数并没有什么太大的区别,其很多的算法也来自于数值计算,比如随机梯度下降法SGD等等。而事实上,你们将来要做的工作也许会比解一个二元函数复杂很多,但是其本质仍然没有改变,只不过也许在你们未来研究的工作中可能遇到的第一个问题就是—我不知道我的目标到底是什么?
再说一句题外话
我觉得在长篇大论说起 DeepLearning 之前,由于我也不是特别清楚你们大学里学的到底咋样,我再啰嗦一些基础技能,大神这一段就跳过吧……
代码
python语法
对于一名合格的炼丹师来说,拥有良好的代码能力是炼丹成功的第一步。在大学期间,也许你们并没有接触过 python,大部分学校应该是学的 c 艹或者 java,而在炼丹界,我们最常使用的这是 python。

如何学习 python?
基本语法:http://funhacks.net/explore-python/File-Directory/text_file_io.html
python 的基本语法相对来说很简单,我这里推荐看FunHacks 大神写的基础入门教程,我个人觉得相比菜鸟和廖雪峰老师的来说更为实用简单。
学会了基础的语法后,我推荐你们去 letcode 或者牛客上刷几十题,实战收悉代码语法。
Letcode:https://leetcode-cn.com/problemset/all/
安装 python
python 之所以深受炼丹师们的热爱,除了其简洁易懂的语法外,更离不开其强大的扩展性和多如繁星的第三方开源库,但是作为一名初来乍到的新人,这也许对你们来说第一道坎来了—如何配置好 python 环境?

这里我推荐Anaconda:https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
清华大学的源非常快,基本上是一键式配置科学技术框架,注意要按官方要求换tuna的源。
IDE
现在有了基础的语法,有了基础的 python 包,想必是按捺不住想要动手写一下代码了吧?
市面上也有在非常的的 IDE,我这里分享一些我个人用过觉得比较好的 IDE。
MAC 系统:CodeRunner:
CodeRunner:https://coderunnerapp.com/

即开即用,应该是不用写教程就能看得懂吧……
windows&Linux 下:sublime
sublime:https://www.sublimetext.com/
需要安装插件包:https://www.4spaces.org/how-to-install-package-control-on-sublime-text/
好电脑:pycharm
pycharm:https://www.jetbrains.com/pycharm/
应该是最好用的 python IDE了吧,不过也有很大的缺点,那就是对电脑配置要求较高,带的动的电脑基本上就是无脑推荐 pycharm 了。

一定要下载PRO 版,因为你将来远程用服务器跑程序,社区版没有远程功能。
最舒服的 IDE--jupyter
jupyter:https://jupyter.org/

但凡是写 python的,jupyter几乎可以说是从入门到精通都一直伴随着你的 IDE 了,其功能扩展性极高,可读性极强,网上非常多的代码教程都是直接用 jupyter 写的,没有 jupyter,你的世界可以说少了一半光明。
写作
出入科研领域的你们,也许要和你们熟悉的 office 三节课说拜拜了。写作在科研在是非常重要的一环,一篇漂亮的论文除了要有好的 idea,同样离不开精美的排版,最重要的是会议和期刊都有着严格的格式要求。

LATEX将接替你们熟悉的 word,承担起写作工具的大任。
学习网站:https://www.latexstudio.net/
当然了,除了论文的写作,日常学习生活中知识的积累同样非常重要,一般我们在做论文笔记的时候,首选推荐的是Markdown;

Markdown 的语法及其简单,简单到你看一遍就能学会:https://markdown-zh.readthedocs.io/en/latest/
除此之外,你还需要一款好的 Markdown 软件,我当然是推荐Typora:https://www.typora.io/
论文
开始了炼丹生涯模式,那 paper 自然就少不了,特别是像深度学习这种发展非常快的领域,每天生产的论文可谓是多不胜数(当然绝大部分都是学术垃圾)

所以说,初来乍到的你们,开始的时候都会很困惑—我该读什么?
我个人推荐三个途径:
你的导师--摸爬滚打了几十年,姿势不知道比我们高到哪里去了,但是可惜的是老板们的时间一般来说都很有限,不是嫡传弟子,很难说能教你多少。
组里的师哥师姐们--你的师哥师姐们好歹也是比你找来几年,基本上你可能遇到的坑他们都踩过了,而且如果是你们将来能接手他们的工作,对你们来说好处实在不要太多(当然了,也可能接手那种祖传的坑……),不过像我们组里,师哥师姐们简直是人太好了。
我接下来推荐几个和论文有关的网站,逐一介绍怎么用。
Browse state-of-the-art
网站:https://paperswithcode.com/sota
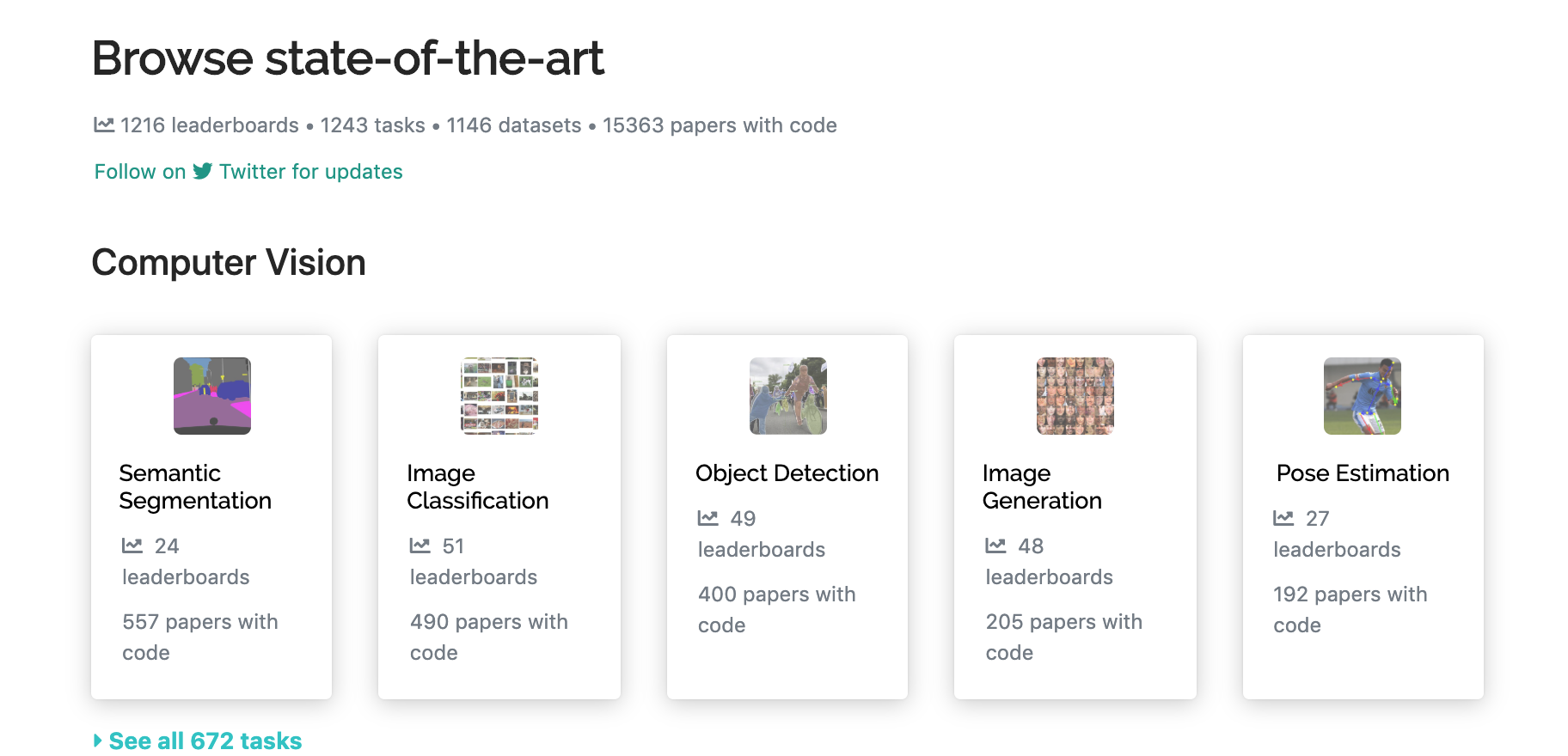
这是 Reddit 的一个用户 rstoj 做的一个网站,将 ArXiv 上的最新机器学习论文与 Github 上的代码(TensorFlow/PyTorch/MXNet/等)对应起来。相比之前推荐的阅读 ArXiv 的网站,这位用户做出了满足更多研究者的最大需求--
寻找论文算法实现的代码!
寻找论文算法实现的代码!
寻找论文算法实现的代码!
这个项目索引了大约 5 万篇论文(最近 5 年发布在 arxiv 上的论文)和 1 万个 Github 库。
你可以按标题关键词查询,或者研究领域关键词,如图像分类、文本分类等搜索,也可以按流行程度、最新论文以及 Github 上 Star 数量最多来排列。这个网站能让你跟上机器学习社区流行的最新动态。
Papers with Code
github:https://github.com/zziz/pwc/blob/master/README.md#----

GitHub 上非常热门的一个开源项目,总结这这几年顶会里优秀的论文并且附带代码实现,高级炼丹师的绝对福利!
Model ZOO
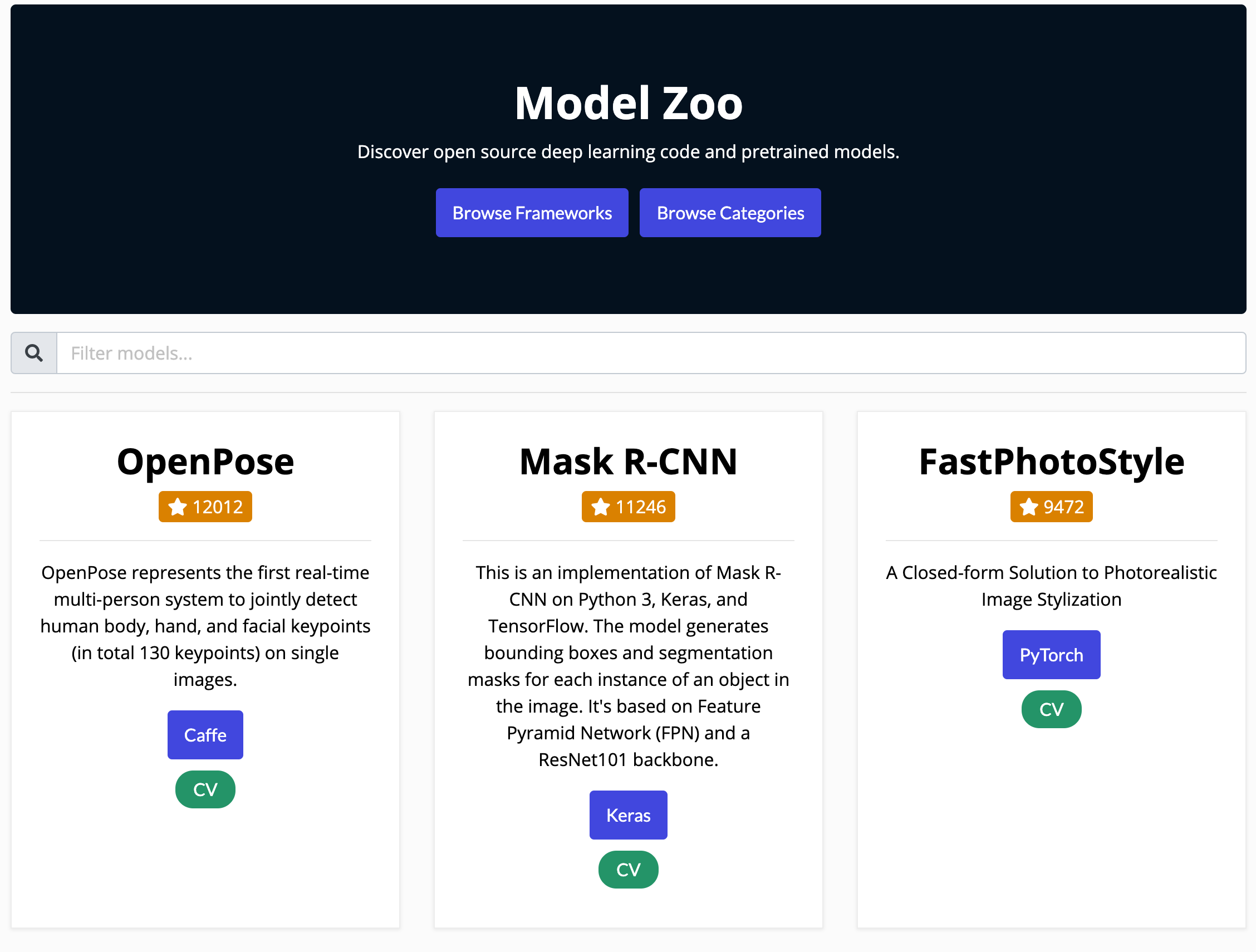
Model Zoo 更加注重深度学习算法的应用价值,里面推荐的项目很多都是偏应用的项目,如果说你研究侧重在应用上,那 Model Zoo 一定是你的首选。
其实我大概也只是抛砖引玉的介绍几个我觉得日常比较实用的。
GitHub
为什么我要单独把 github 从代码里摘出来讲呢?因为 GitHub 实在是太重要了,对一个现代炼丹师来说,你几乎每一天都离不开 GitHub。
开源是一件很伟大的事情,这个问题上升到哲学层面,我不展开讲。
我在这里也并不想对于“送去”再说什么,否则太不“摩登”了。我只想鼓吹我们再吝啬一点,“送去”之外,还得“拿来”,是为“拿来主义”。 —鲁迅《拿来主义》
当然了还有就是借机推广一下自己嘛(皮一下2333),我目前一直在维护我们实验室的 GitHub 账号 OUCML:https://github.com/OUCMachineLearning/OUCML,我个人总结的学习资料基本上都在上面。(小小声:知乎账号:马卡斯·扬)
Git的奇技淫巧
Git常用命令集合,Fork于tips项目
Git是一个 “分布式版本管理工具”,简单的理解版本管理工具:大家在写东西的时候都用过 “回撤” 这个功能,但是回撤只能回撤几步,假如想要找回我三天之前的修改,光用 “回撤” 是找不回来的。而 “版本管理工具” 能记录每次的修改,只要提交到版本仓库,你就可以找到之前任何时刻的状态(文本状态)。
关于如何使用GitHub,看这一篇就够了:https://github.com/521xueweihan/git-tips
深度学习入门
前面乱七八糟聊了这么多,我用哲学三问步入正题。
我是谁
WIKI:
深度学习(英語:deep learning)是机器学习的分支,是一種以人工神經網路為架構,對資料進行表徵學習的算法。[1][2][3][4][5]
深度学习是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别[6])。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。[7]
表征学习的目标是寻求更好的表示方法并建立更好的模型来从大规模未标记数据中学习这些表示方法。表示方法来自神经科学,并松散地建立在類似神经系统中的信息处理和对通信模式的理解上,如神经编码,试图定义拉動神经元的反应之间的关系以及大脑中的神经元的电活动之间的关系。[8]
至今已有數种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和递归神经网络已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并取得了极好的效果。
Emmmm,还是简单点说吧,把数据作为 X,标签作为 Y,我们深度学习就是找到一个 F(·),使得y≈f(x)。

这个 F()很复杂,我得从(宇宙大爆炸开始讲起)机器学习讲起。
我从哪里来
- 1943年
由神经科学家麦卡洛克(W.S.McCilloch) 和数学家皮兹(W.Pitts)在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity)。建立了神经网络和数学模型,称为MCP模型。所谓MCP模型,其实是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,也就诞生了所谓的“模拟大脑”,人工神经网络的大门由此开启。[1]
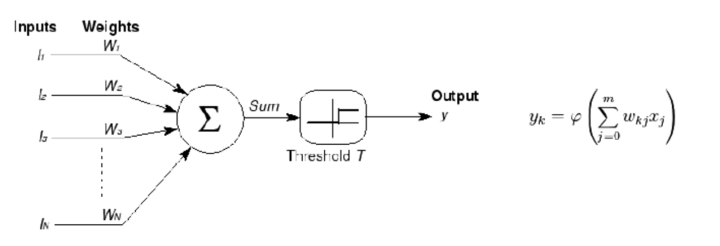
- 1958年
计算机科学家罗森布拉特( Rosenblatt)提出了两层神经元组成的神经网络,称之为“感知器”(Perceptrons)。第一次将MCP用于机器学习(machine learning)分类(classification)。“感知器”算法算法使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
我到哪里去
这个问题说实话,我答不上来。
但是,我可以简要介绍一下目前深度学习比较火的几个领域:
CV
计算机视觉(Computational Vision)是由相机拍摄图像, 通过电脑对图像中的目标进行识别和检测。可以说是机器学习在视觉领域的应用,是人工智能领域的一个重要部分。
emmm,这个门槛低,应用广,这几年都快挤爆了。
NLP
自然語言處理(英語:Natural Language Processing,缩写作 NLP)是人工智慧和語言學領域的分支學科。此領域探討如何處理及運用自然語言;自然語言處理包括多方面和步骤,基本有认知、理解、生成等部分。

NLP 相对来说垄断性质较高,也就是其实大家算法都差不多,谁数据多谁 NB。
医学

没做过,不知道。。。。
强化学习

不得不提巨坑 AutoML
Google 爸爸一直在努力推进 AutoML,说白了就是让算法自动设计神经网络。
推荐 18 年的一篇综述:https://arxiv.org/pdf/1810.13306
图卷积
这两年爆火的,说实话我也不太懂。。。。
他比我懂👉图卷积神经网络(GCN)详解:包括了数学基础(傅里叶,拉普拉斯)
迁移学习

把从数据集 A 上学到的知识迁移到数据集 B 的任务上。
深度学习框架
所谓工欲善其事必先利其器,之前我们提到过 python 有着很多的第三方库,那我接下来将要解释一下常用的深度学习框架:
TensorFlow

Google 支持的 TensorFlow 框架,应该是最出名的没有之一了吧。优点是大部分模型都是 TensorFlow 写的,代码复现快,缺点是版本迭代产生的 bug 多如繁星。
https://www.tensorflow.org/overview
Keras

新手入门神器,相当于在 TensorFlow 的基础上又包了一层皮,API 接口稳定,代码实现简易,缺点是自由度太低了。
pytorch

好用的一匹(我在用),动态计算图谁用谁知道,缺点之一是:老老实实读源代码吧。
PyTorch 1.0重构和统一了Caffe2和PyTorch 0.4框架的代码库,删除了重复的组件并共享上层抽象,得到了一个统一的框架,支持高效的图模式执行、移动部署和广泛的供应商集成等。这让开发人员可以同时拥有PyTorch和Caffe2的优势,同时做到快速验证和优化性能。PyTorch的命令式前端通过其灵活而高效的编程模型实现了更快速的原型设计和实验,又吸取了Caffe2和ONNX的模块化以及面向生产的特点,使得深度学习项目能从研究原型快速无缝衔接到生产部署,在一个框架中统一实验研究和生产能力。
Theano
不想贴图,两个字--有毒
Caffe
据说做网络结构压缩那一块的小伙伴用的比较多,因为可以方便的改底层的实现。
Caffe2
现在叫 pytorch1.0
MXnet

这本书就是李沐大神用 MXnet 写的,听说挺好用的,就是没啥钱做宣传推广,那我帮他推广一下:https://zh.gluon.ai/chapter_introduction/deep-learning-intro.html
今晚其实写这个写了挺久的,现在已经凌晨 1 点多了,其实我真的挺喜欢深度学习这个研究领域的,说实话总感觉还有好多话想说出来,想和大家聊聊动态计算图,自动微分库,网络结构可视化,Lipschitz条件等等等等……
接下来的大三了,也许课程压力挺大的,希望喜欢一件事情就能坚持下来吧(๑•̀ㅂ•́)و✧
要是觉得有用麻烦关注点赞转发三连啦<( ̄︶ ̄)>
参考文献:
[1]https://zhuanlan.zhihu.com/p/29096536
[2]https://zhuanlan.zhihu.com/p/59086302
