@Team
2019-02-14T12:13:24.000000Z
字数 11105
阅读 4603
深入理解one-stage目标检测算法(上篇)
叶虎
本文翻译自One-shot object detection,原作者保留版权,略有删减。
作为计算机视觉领域的一项重要任务,目标检测是要找到一张图片里的感兴趣物体:
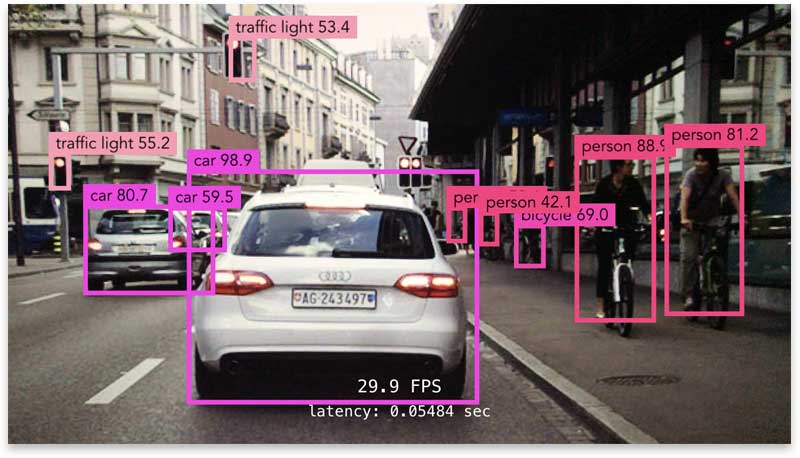
这比图像分类任务更高级,因为分类只需要告诉图像中主要物体是什么,然而目标检测要找到多个物体,不仅要分类,而且要定位出它们在图像中的位置。目标检测模型不仅要预测出各个物体的边界框(bounding boxes),还要给出每个物体的分类概率。通常情况下目标检测要预测许多边界框。每个边界框还需要一个置信度(confidence score),代表其包含物体的可能性大小。在后处理中,通过设定置信度阈值来过滤那些置信度较低的边界框。目标检测相比分类任务更复杂,其面临的一个主要问题在于一张图片中可能存在许多位置不定的物体,而且模型会输出很多预测结果,要计算损失函数就需要匹配真实框(ground-truth bounding box)与预测框。
这里我们主要关注one-stage目标检测算法(也称one-shot object detectors),其特点是一步到位,速度相对较快。另外一类目标检测算法是two-stage的,如Faster R-CNN算法先生成候选框(region proposals,可能包含物体的区域),然后再对每个候选框进行分类(也会修正位置)。这类算法相对就慢,因为它需要多次运行检测和分类流程。而one-stage检测方法,仅仅需要送入网络一次就可以预测出所有的边界框,因而速度较快,非常适合移动端。最典型的one-stage检测算法包括YOLO,SSD,SqueezeDet以及DetectNet。
尽管这些方法都已经公布paper和源码,但是大部分paper对技术细节并没有完全给出来。因而,这篇博文将详细讲述one-shot检测算法(以YOLO和SSD作为典例)的原理,以及它是如何训练和预测的。
为什么目标检测问题更难
图像分类是生成单个输出,即类别概率分布。但是这只能给出图像整体内容的摘要,当图像有多个感兴趣的物体时,它就不行了。在下面的图像中,分类器可能会识别出图像即包含猫,也包含狗,这是它最擅长的。
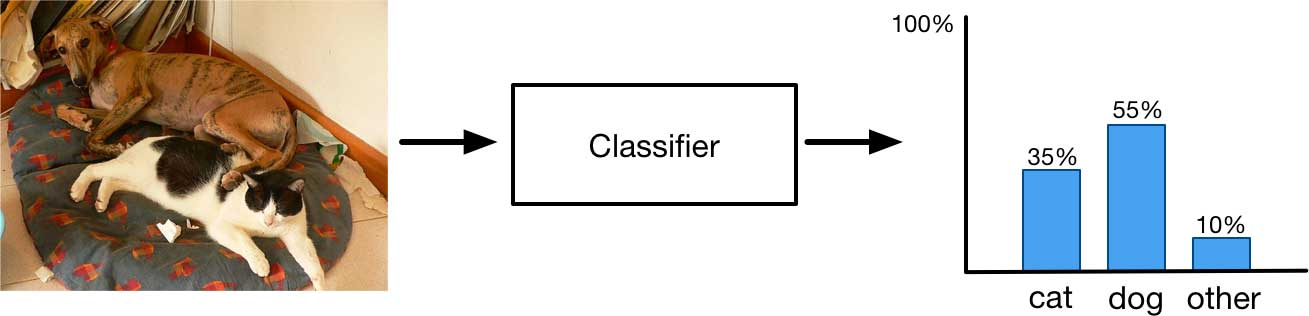
而目标检测模型将通过预测每个物体的边界框来给出各个物体的位置:

因为可以专注于对边界框内的物体进行分类并忽略外部背景,因此模型能够为各个物体提供更加准确的预测。如果数据集带有边界框标注,则可以非常轻松地在模型添加一个定位预测:只需预测额外4个数字,分别用于边界框的每个角落。
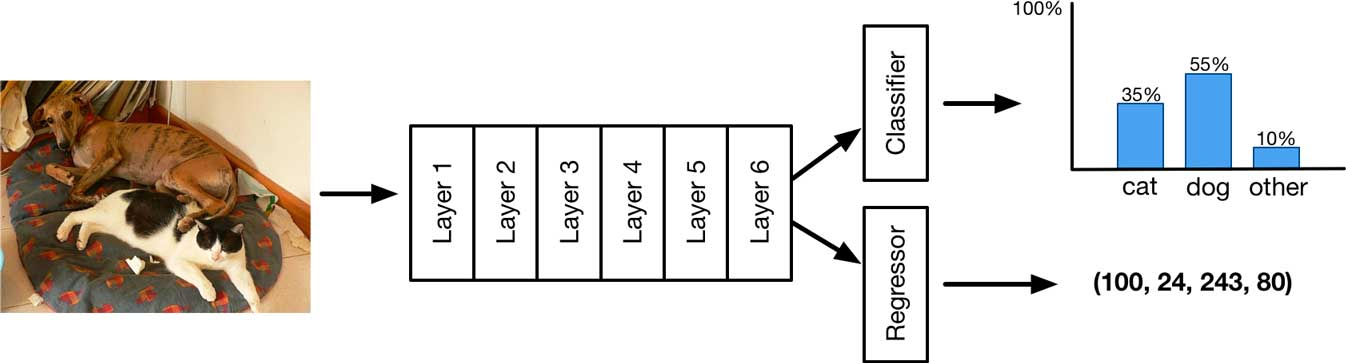
现在该模型有两部分输出:类别概率分布和边界框回归。模型的损失函数只是将边界框的回归损失与分类的交叉熵损失相加,通常使用均方误差(MSE):
outputs = model.forward_pass(image)class_pred = outputs[0]bbox_pred = outputs[1]class_loss = cross_entropy_loss(class_pred, class_true)bbox_loss = mse_loss(bbox_pred, bbox_true)loss = class_loss + bbox_lossoptimize(loss)
然后采用SGD方法对模型优化训练,这是一个预测实例:

模型已正确对图像中物体(狗)分类,并给出它在图像中的位置。红色框是真实框,而青色框是预测框,虽然有偏差,但非常接近。为了评估预测框与真实框的匹配程度,我们可以计算两个边界框之间的IOU(intersection-over-union,也称为Jaccard index)。IOU在0到1之间,越大越好。理想情况下,预测框和真框的IOU为100%,但实际上任何超过50%的预测通常都被认为是正确的。对于上面的示例,IOU为74.9%,因而预测框比较精确。
使用回归方法预测单个边界框可以获得较好的结果。然而,当图像中存在多个感兴趣的物体时,就会出现问题:

由于模型只能预测一个边界框,因而它必须要选择一个物体,这会最终落在中间位置。实际上这很容易理解:图像里有两个物体,但是模型只能给出一个边界框,因而选择了折中,预测框位于两者中间,也许大小也是介于两个物体大小之间。
注意:也许你可能认为模型应该给出一个包含两个物体的边界框,但是这不太会发生,因为训练不是这样的,真实框都是各个物体分开标注的,而不是一组物体进行标注。
你也许认为,上述问题很好解决,对于模型的回归部分增加更多的边界框预测不就好了。毕竟,如果模型可以预测N个边界框,那么就应该可以正确定位N个物体。听起来不错,但是并没有效。就算模型有多个检测器(这里一个边界框回归称为一个检测器),我们得到的边界框依然会落在图像中间:

为什么会这样?问题是模型不知道应该将哪个边界框分配给哪个物体,为了安全起见,它将它们放在中间的某个位置。该模型无法决定:“我可以在左边的马周围放置边界框1,并在右边的马周围放置框2。”相反,每检测器仍然试图预测所有物体,而不是一个检测器预测一个物体。尽管该模型具有N个检测器,但它们无法协同工作。具有多个边界框检测器的模型的效果与仅预测一个边界框的模型完全相同。
我们需要的是使边界框检测器更专一化的一些方法,以便每个检测器将尝试仅预测单个物体,并且不同的探测器将找到不同的物体。在不专一的模型中,每个检测器应该能够处理图像中任何可能位置的各类物体。这太简单了,模型学会的是预测位于图像中心的方框,因为这样整个训练集实际上会最小化损失函数。从SGD的角度来看,这样做平均得到了相当不错的结果,但在实践中它却不是真正有用的结果,所以我们需要更加有效地训练模型。
通过将每个边界框检测器分配到图像中的特定位置,one-stage目标检测算法(例如YOLO,SSD和DetectNet)都是这样来解决这个问题。因为,检测器学会专注于某些位置的物体。为了获得更好的效果,我们还可以让检测器专注于物体的形状和大小。
使用网格
使用固定网格上的检测器是one-stage目标检测算法的主要思想,也是它们与基于候选框的目标检测方法(如R-CNN)的区别所在(实际上Faster R-CNN中RPN网络也采用网格检测)。
让我们考虑这类模型最简单的架构。它首先有一个充当特征提取器的基础网络。像大多数特征提取器一样,它通常在ImageNet上训练。对于YOLO,特征提取器以416×416图像作为输入。SSD通常使用300×300大小的图像。它们比用于分类的图像(如224×224)更大,因为我们不希望丢失细节。

作为特征提取器的基础网络可以是任何CNN网络,如Inception,ResNet以及YOLO中DarkNet,对于移动端可以采用轻量级的网路,如SqueezeNet以及MobileNet等。在特征提取器的后面是几个额外的卷积层。这是模型的目标检测部分,这些都经过训练后学习如何预测这些边界框以及框内物体的分类概率。
有许多用于训练目标检测算法的通用数据集。这里,我们将使用Pascal VOC数据集,该数据集有20个类。因此神经网络的第一部分在ImageNet上进行训练,而检测部分是在VOC数据集上训练。
YOLO或SSD的实际架构要比这个简单的示例网络稍微复杂一点,比如有残差结构,但我们稍后会介绍。目前,上述模型已经可用于构建快速且相当精确的目标检测模型。
最后一层的输出是一个特征图(上图中的绿色图)。对于我们的示例模型,这是一个包含125个通道的13×13大小的特征图。
注意:此处的13x13是因为输入图片大小为416x416,而此处使用的特定基础网络具有五个池化层(或具有stride=2的卷积层),这样按比例缩小32倍:416/32 = 13。如果你想要一个更精细的网格,例如19×19,那么输入图像应该是19×32 =608像素宽和高(或者你可以使用一个较小步幅的网络)。
我们将此特征图解释为13x13个单元格的网格。该数字是奇数,因此中心有一个单元格。网格中的每个单元格都有5个独立的物体检测器,每个检测器都预测一个边界框。
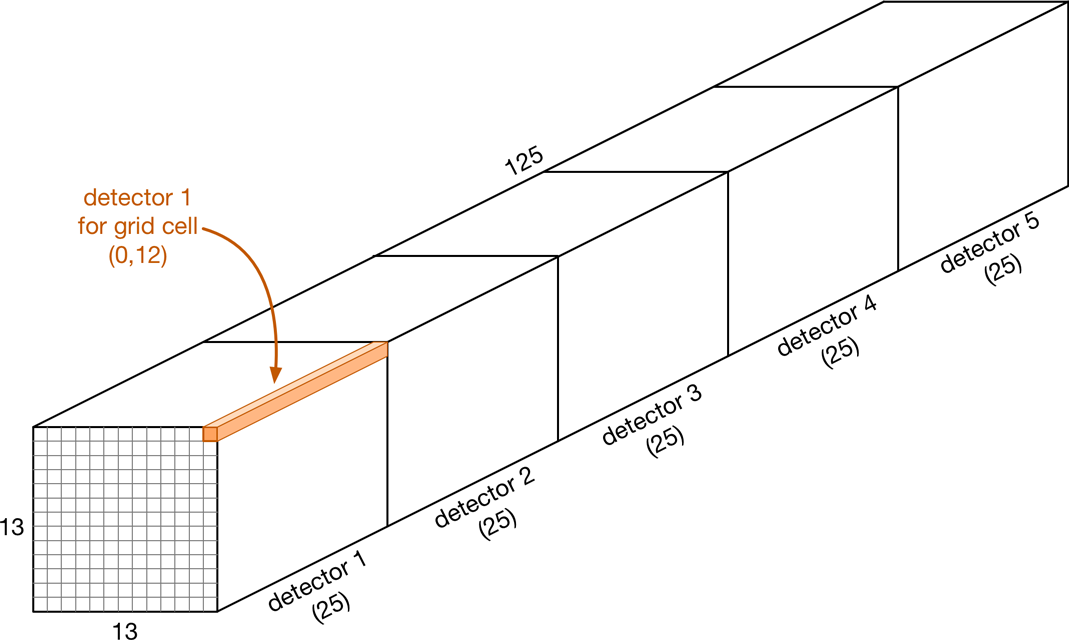
这里的关键是检测器的位置是固定的:它只能检测位于该单元附近的物体(实际上,物体的中心必须位于网格单元内)。这可以避免上一部分所说的问题,当时的检测器有太多的自由度。使用此网格,图像左侧的检测器将永远不会预测位于右侧的物体。
每个物体检测器产生25个值:
- 表征类别概率的20个值
- 4个边界框坐标(中心x,中心y,宽度w,高度h)
- 1个值表示置信度
由于每个单元有5个检测器,5×25 = 125,这就是我们有125个输出通道的原因。
与常规分类器一样,类别概率可以采用softmax获得。我们可以通过查看最高概率值确定类别。 (虽然通常情况下将其视为多标签分类,但是这里20个类是独立的,我们使用sigmoid而不是softmax)
置信度介于0和1(或100%)之间,用于表征模型认为此预测边界框包含真实物体的可能性。请注意,这个分数只说明了这是否是一个物体,但没有说明这是什么类型的物体,后面需要分类概率才能确定。
该模型总是预测固定数量的边界框:13×13个单元乘以5个检测器给出845个预测。显然,绝大多数这些预测都不会有用,毕竟大多数图像最多只包含少量物体,而不是超过800。置信度告诉我们哪些预测框可以忽略。通常情况下,我们最终会得到模型认为很好的十几个预测。其中一些将重叠,这是因为相邻的单元可能都对同一个物体进行预测,有时单个单元会进行多次预测(尽管在训练中这是被抑制的)。

具有许多大部分重叠的预测框在目标检测中比较常见。标准后处理方法是应用非最大抑制(NMS)来去除重叠框。简而言之,NMS保留拥有最高的置信度的预测框,并删除任何与之重叠超过一定阈值的预测框(例如60%)。通常我们只保留10个左右的最佳预测并丢弃其他预测。理想情况下,我们希望图像中的每个物体只有一个边界框。
好吧,上面描述了使用网格进行物体检测的基本思路。但为什么它有效呢?
约束让模型更容易学习
前面已经提到将每个边界框检测器分配到图像中的固定位置是one-stage目标检测算法的技巧。我们使用13×13网格作为空间约束,使模型更容易学习如何预测对象。使用这种(架构)约束是神经网络特别有用的技巧。事实上,卷积本身也是一个约束:卷积层实际上只是一个全连接(FC)层的更受限制的版本。(这就是为什么你可以使用FC层实现卷积,反之亦然,它们基本上是相同的)
如果我们只使用普通的FC层,那么神经网络模型要学习图像要困难得多。对卷积层施加的约束:它一次只看几个像素,并且连接共享相同的权重。我们使用这些约束来消除自由度并引导模型学习我们想要学习的内容。
同样,网格结构强制让模型学习专门针对特定位置的物体检测器。左上角单元格中的检测器仅预测位于左上角单元格附近的物体,而不会预测距离较远的物体(对模型进行训练,使得给定网格单元中的检测器仅负责检测其中心落入该网格单元内的物体)。
前面所说的模型没有这样的约束,因此它的回归层永远不会限制在特定位置。
先验框(Anchors,锚)
网格是一种有用的约束,它限制了检测器可以在图像中找到物体的位置。我们还可以添加另一个约束来帮助模型做出更好的预测,就是物体形状的约束。
我们的示例模型具有13×13个网格单元,每个单元具有5个检测器,因此总共有845个检测器。但为什么每个网格单元有5个检测器而不是一个?好吧,就像检测器很难学会如何预测可以位于任何地方的物体一样,检测器也很难学会预测任何形状或大小的物体。
我们使用网格来专门限制检测器仅查看某个特定空间位置。相应地,为每个网格单元设置几个不同的检测器,我们可以使这些物体检测器中的每一个都专注于某种物体形状。
我们在5种特定形状上训练检测器:
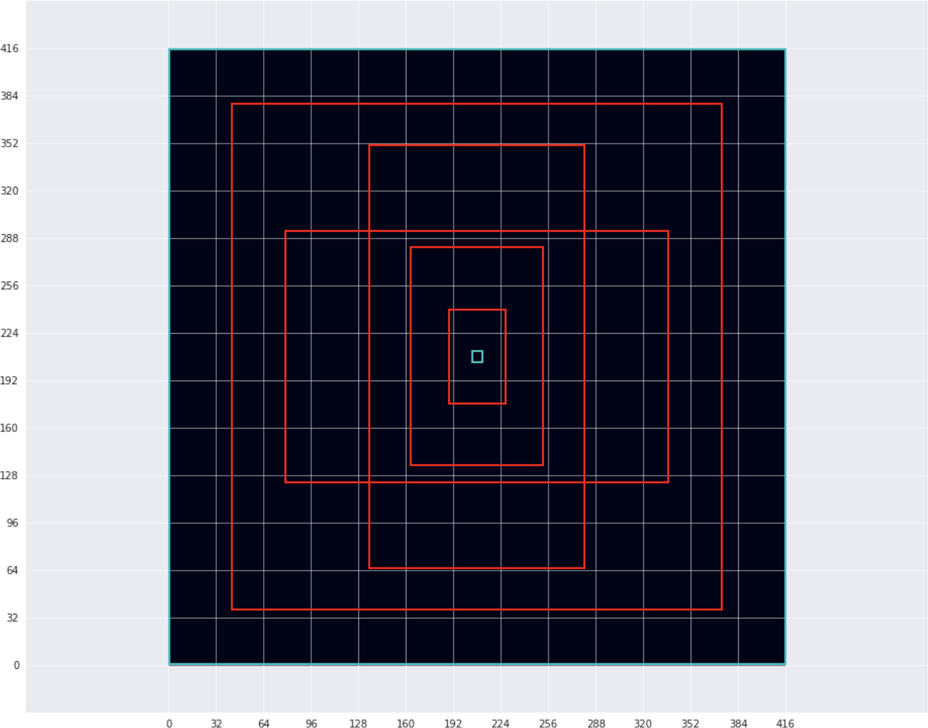
红色框是训练集中五个最典型的物体形状。青色框分别是训练集中最小和最大的物体。请注意,这些边界框显示在输入为416×416中。 (该图还以浅灰色显示网格,因此可以看到这五个形状网格单元相关。每个网格单元在输入图像中覆盖32×32像素)
这五种形状称为先验框或者锚。先验框只是一个宽度和高度列表:
anchors = [1.19, 1.99, # width, height for anchor 12.79, 4.60, # width, height for anchor 24.54, 8.93, # etc.8.06, 5.29,10.33, 10.65]
先验框描述数据集中5个最常见(平均)的物体形状。这里的“形状”指的是它们的宽度和高度,因为在目标检测种总是使用基本的矩形。有5个先验框并非偶然。网格单元中的每个检测器都有一个先验框。就像网格对检测器施加位置约束一样,先验框迫使检测器专门处理特定的物体形状。
单元中的第一个检测器负责检测与第一个先验框相似的物体,第二个检测器负责与第二个先验框相似的物体,依此类推。因为我们每个单元有5个检测器,所以我们也有5个先验框。因此,检测器1将拾取小物体,检测器2拾取稍大的物体,检测器3拾取长而扁平的物体,检测器4拾取高而薄的物体,而检测器5拾取大物体。
注意:上面代码片段中先验框的宽度和高度用网格的13×13坐标系表示,因此第一个先验框略宽于1个网格单元格,高度接近2个网格单元格。最后一个先验框覆盖了几乎整个网格,超过10×10个单元格。这就是YOLO设置先验框的方式。然而,SSD具有几个不同尺寸的不同网格,因此使用先验框的标准化坐标(在0和1之间),它们与网格的大小无关。任何一种方法都可以。
重要的是要了解这些先验框是事先选择的。它们是恒定的,在训练期间不会改变。
由于先验框只是一个宽度和高度集合,而且它们是事先选择的,所以YOLO纸也称它们为“dimension priors”(Darknet,官方的YOLO源代码,称它们为“biases”,也是比较合理 - 检测器偏向于预测某个形状的物体,但是这个术语令人困惑)。
YOLO通过在所有训练图像的所有边界框上进行k-means聚类来选择先验框(k=5,因此它找到五个最常见的物体形状)。因此,YOLO的先验框适合当前训练(和测试)的数据集。k-means算法中数据点是数据集中所有真实边界框的宽度和高度值。如果我们在Pascal VOC数据集的框中运行k-means,将得到5个簇:
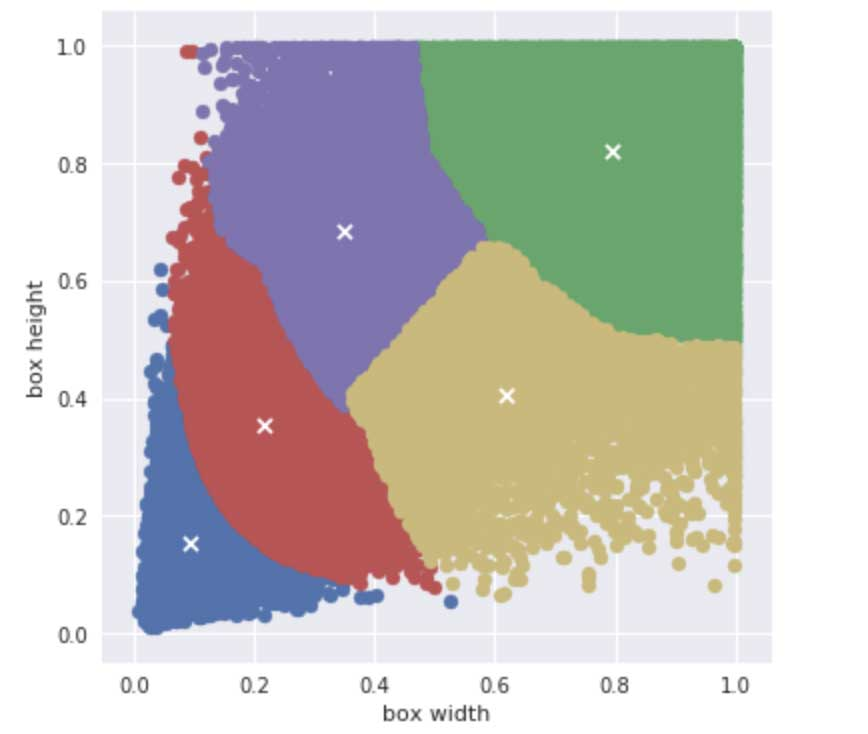
这些簇表示此数据集中存在的不同物体形状的五个“平均值”。你可以看到k-means在蓝色簇中将非常小的物体组合在一起,在红色簇中将较大的物体组合在一起,将非常大的物体分组为绿色。它决定将中间物体分成两组:一组边界框(黄色)宽大于高,另一组高于宽(紫色)。
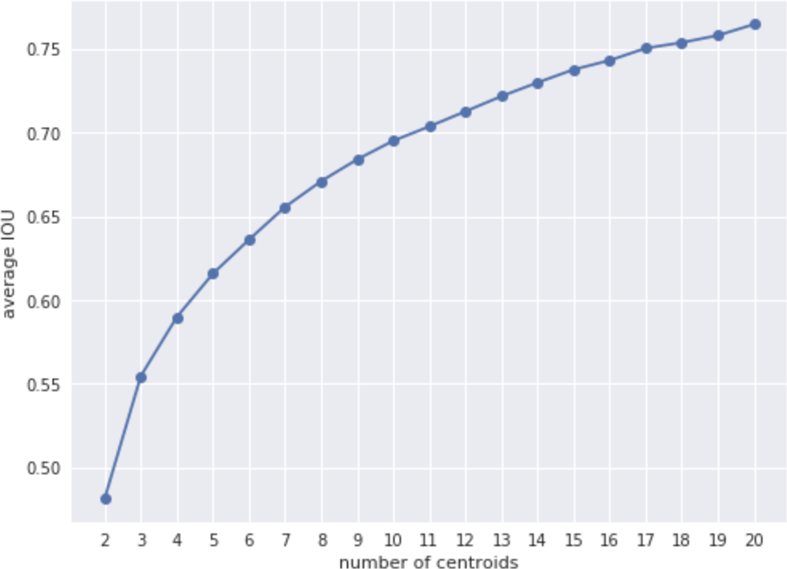
但5个簇是最佳选择吗?我们可以设定不同的k进行k-means,并计算真实框与它们最接近的先验框之间的平均IOU。当然,使用更多的质心(更大的k值)会产生更高的平均IOU,但这也意味着我们需要在每个网格单元中使用更多的检测器,这会使模型运行得更慢。对于YOLO v2,他们选择5个聚类中心,这是在准确度和模型复杂性之间的折衷。
SSD不使用k-means来确定先验框。相反,它使用数学公式来计算先验框尺寸,因此SSD的先验框与数据集无关(SSD称它们为“default boxes”)。SSD和YOLO的先验框设置,到底哪种方式比较好,并没有定论。另一个小差异是:YOLO的先验框只是宽度和高度,但SSD的先验框也有x,y位置。其实,YOLO也包含位置,只是默认先验框位置始终位于网格单元格的中心(对于SSD,先验框也是在网格中心)。
由于先验框,检测器仅预测相比边界框的偏移值,这使得训练更容易,因为预测值全为零时等价于输出先验框,平均上更接近真实物体。如果没有先验框,每个检测器都必须从头开始学习不同的边界框形状,这相当困难。
注意:本文所说的YOLO是指YOLOv2或v3,这与YOLOv1是非常不同的。YOLOv1具有较小的网格(7×7,每个单元仅有2个检测器),使用全连接层而不是卷积层来预测网格,并且不使用先验框。那个版本的YOLO现在已经过时了。相比之下,v2和v3之间的差异要小得多。而YOLOv3在很多方面与SSD非常相似。
模型到底预测了什么
让我们更加细致地看一下模型的输出是什么,由于模型仅仅是一个卷积神经网络,所以前向过程是这样的:
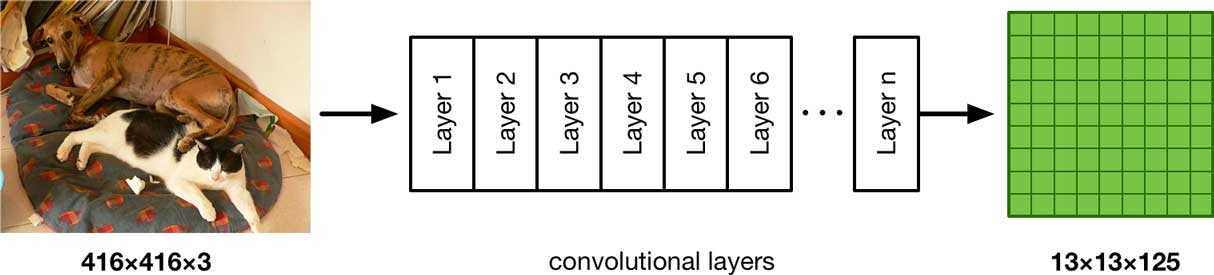
你输入一个416x416的RGB图像,经过卷积层之后是一个13x13x125的特征图。由于是回归预测,最后的层没有激活函数。最后的输出包含21,125个数,我们要将它们转化为边界框。
我们采用4个数来表示一个边界框的坐标。通常有两种方式:或者用xmin, ymin, xmax, ymax表示边界框左上和右下点坐标,或者使用center x, center y, width, height。两个方式都可以(两者可以互相转换),但是这里采用后者,因为知道框中心更加容易将边界框与网格单元进行匹配。
模型预测的不是边界框在图像中的绝对坐标,而是4个偏移值(delta or offset):
delta_x, delta_y:边界框中心点在网格单元内部的坐标;delta_w, delta_h: 边界框的宽和高相对先验框的缩放值。
每个检测器预测的边界框都是相对一个先验框,这个先验框已经很好地匹配了物体的实际大小(这也是为什么要使用先验框),但是它不完全准确。因而,我们需要预测一个缩放因子来知道预测的框是比先验框大还是小,同样地,也要知道预测框的中心相对于网格中心的偏移量。
要得到边界框在图像中的真实宽与高,需要这样计算:
box_w[i, j, b] = anchor_w[b] * exp(delta_w[i, j, b]) * 32box_h[i, j, b] = anchor_h[b] * exp(delta_h[i, j, b]) * 32
这里的i和j是网格(0-12)的行与列,而b是检测器(0-4)的索引。预测框比原始图片宽或者高都是正常的,但是宽和高不应该会是负值,因此这里取预测值的指数。如果delta_w<0,那么exp(delta_w)介于0~1,此时预测框比先验框小。若delta_w>0,那么exp(delta_w)大于1,此时预测框比先验框大。特别地,delta_w=0,那么exp(delta_w)为1,此时预测框与先验框一样大小。顺便说一下,这里之所以要乘以32是因为先验框坐标是13x13网格上的,网格上各个像素点等价于原始416x416图像上的32个像素点。
注意:在损失函数中,我们使用上述公式的逆运算:不是将预测的偏移值通过exp转换到实际坐标,而是将真实框通过log运算转换为偏移值。后面会详细介绍。
利用下面公式可以得到预测框中心的像素坐标:
box_x[i, j, b] = (i + sigmoid(delta_x[i, j, b])) * 32box_y[i, j, b] = (j + sigmoid(delta_y[i, j, b])) * 32
YOLO模型的一个重要特点是仅当某个物体的中心点落在一个检测器的网格单元中心时,这个检测器才负责预测它。这样避免冲突,即相邻的单元格不会用来预测同一个物体。这样,delta_x和delta_y必须限制在0~1之间,代表预测框在网格单元的相对位置,这里用sigmod函数限制值的范围。然后我们加上单元格的坐标i和j(0~12之间),乘以每个单元格所包含的像素数(32)。这样box_x和box_y就表示预测框中心在原始416×416图像中的坐标。
然后,SSD却有点不同:
box_x[i, j, b] = (anchor_x[b] + delta_x[i, j, b]*anchor_w[b]) * image_wbox_y[i, j, b] = (anchor_y[b] + delta_y[i, j, b]*anchor_h[b]) * image_h
这里预测的delta值实际上是先验框宽或高的倍数,所以没有sigmoid函数。这也意味着在SSD中物体的中心可落在单元格的外面。需要注意的是SSD预测的坐标是相对于先验框中心而不是单元格中心。实际上一般情况下两个中心是重合的,但是SSD和YOLO采用的坐标系不一样。SSD的先验框坐标是归一化到[0,1],这样它们独立于网格大小(SSD之所以这样是采用了不同大小的网格)。
可以看出,即使YOLO和SSD大致原理是相同的,但是具体的实现细节是有差异的。
除了坐标之外,模型每个边界框预测了一个置信度,一般采用sigmoid函数得到0~1的概率值:
confidence[i, j, b] = sigmoid(predicted_confidence[i, j, b])
实际上我们的模型预测了845个边界框,但是一张图片中的物体一般是很少的。在训练过程中,由于我们仅让一个检测器预测一个真实框,因此只有很少的预测框的置信度较高,那些不应该找到物体的检测器应该得到较小的置信度。
最后,我们预测分类概率,对于Pasval VOC数据每个边界框有20个值,采用softmax得到概率分布:
classes[i, j, b] = softmax(predicted_classes[i, j, b])
除了采用softmax,还可以采用sigmoid,这将变成一个多标签分类器,每个预测框实际上可以同时有多个类别,SSD和YOLOv3是这样。
但是SSD没有预测置信度,它给分类器增加了一个特殊的类:背景。如果分类结果是背景,那么意味着检测器没有找到物体,这实际上等价于YOLO给出一个较低的置信度。
由于很多预测是不需要的,所以对于置信度较低的预测我们将舍弃。在YOLO中,结合置信度和最大类别概率来过滤预测值(条件概率):
confidence_in_class[i, j, b] = classes[i, j, b].max() * confidence[i, j, b]
置信度低表示模型很不确定预测框是否含有物体,而低分类概率表示模型不确定哪种物体在预测框内,只有两者都高时,我们才采纳这个预测值。
由于大部分的框不含物体,我们可以忽略那些置信度低于某个阈值(比如0.3)的预测框,然后对余下的框执行NMS(non-maximum suppression),去除重叠框,这样处理后一般得到1~10个预测框。
这是卷积预测
卷积神经网络天然适合这样的网格检测器,13×13的网格是卷积层得到的. 卷积实际上是在整个输入图像上以较小的窗口(卷积核)进行滑动,卷积核在每个位置是共享的。我们的样例模型最后的卷积层包含125个卷积核。
为什么是125?因为有5个检测器,每个检测器有25个卷积核。这25个卷积核中的每一个都预测边界框的属性值:坐标x和y,宽度,高度,置信度,20类概率。
注意:一般来说,如果数据集有k类,而模型有b个检测器,那么网格需要有b×(4+1+k)个输出通道。
这125个卷积核在13×13特征图中的每个位置上滑动,并在每个位置上进行预测。然后,我们将这125个数字解释为5个预测边界框。最初,在每个网格位置预测到的125个数字将是完全随机和无意义的,但是随着训练,损失函数将引导模型学习做出更有意义的预测。
尽管每个网格单元中有5个检测器,但对于845个检测器来说,这个模型实际上只学习了总共5个检测器,而不是每个网格单元都学习5个唯一的检测器。这是因为卷积层的权重在每个位置都相同,因此在网格单元之间共享。但模型为每个先验框学习一个检测器,它们在图像上滑动,以获得845个预测值,网格上每个位置有5个。因此,尽管我们总共只有5个独特的检测器,但由于卷积的缘故,这些检测器与它们在图像中的位置无关,因此无论它们位于何处,都可以检测到物体。每个位置的输入像素与检测器所学习到的权重,决定了该位置的最终边界框预测。
这也解释了为什么模型总是预测边界框相对于网格单元中心的位置。由于该模型具有卷积性质,无法预测绝对坐标,而卷积核在图像上滑动,因此它们的预测总是相对于在特征图中的当前位置。
YOLO vs SSD
上面关于one-stage的目标检测模型的原理的描述几乎适用于所有的检测器。但是在解释输出的方式上可能存在细微的差异(例如,分类概率采用sigmoid而不是softmax),但一般是相同的。
然而,不同版本的YOLO和SSD之间存在一些结构上的差异。以下是YOLOv2&v3和SSD模型的架构示意图:
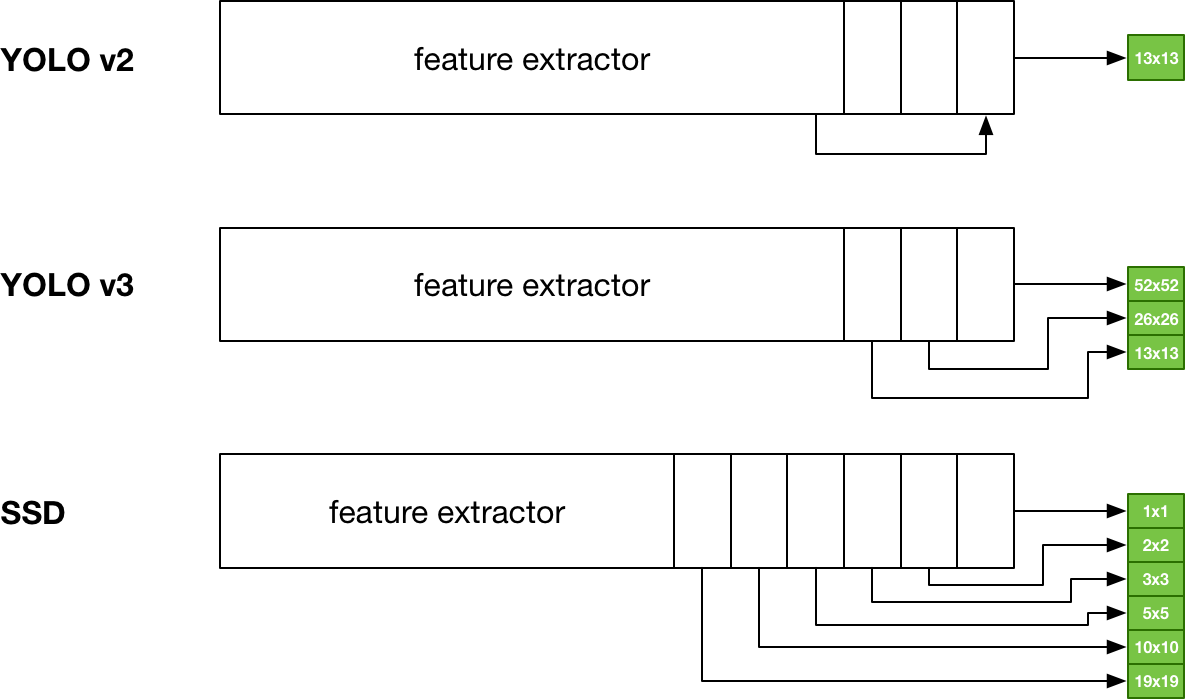
可以看到,YOLOv3和SSD非常相似,尽管它们是通过不同的方法得到网格(YOLO使用升序采样,SSD使用降序采样)。而YOLOv2(我们的示例模型)只有一个13×13的输出网格,而SSD有几个不同大小的网格。Mobilenet+SSD版本有6个网格,大小分别为19×19、10×10、5×5、3×3、2×2和1×1。因此,SSD网格的范围从非常细到非常粗。这样做是为了在更广泛的物体尺度上获得更精确的预测。比较精细的19×19网格,其网格单元非常靠近,负责预测最小的物体。而最后一层生成的1×1网格负责预测基本上占据整个图像的较大物体,其他层的网格适应比较宽范围的物体。YOLOv3更像SSD,因为它使用3个不同大小的网格预测边界框。
和YOLO一样,每个SSD网格单元都会进行多个预测。每个网格单元的检测数量各不相同:在更大、更细粒度的网格上,SSD每个网格单元有3或4个检测器,在较小的网格上,每个网格单元有6个检测器。而YOLOv3的每个网格单元均使用3个检测器。
坐标预测是相对于先验框的,在SSD文件中被称为“default boxes”,但有一个区别是,SSD的预测中心坐标可以超出其网格单元。先验框位于单元的中心,但SSD不会对预测的X,Y偏移应用sigmoid。所以理论上,模型右下角的一个检测器可以预测一个中心在图像左上角的边界框(但这在实践中可能不会发生)。
与YOLO不同的是,SSD没有置信度。每个预测只包含4个边界框坐标和类概率。YOLO使用置信度来表示这个预测包含实际物体的可能性。SSD通过一个特殊的“背景”类来解决这个问题:如果类预测是背景类,那么它意味着没有为这个检测器找到物体。这实际上和YOLO中置信度较低等同。
SSD在先验框上与YOLO稍有不同。因为YOLO必须从单个网格进行所有预测,所以它使用的先验框的范围从小(大约单个网格单元的大小)到大(大约整个图像的大小)。SSD更为保守。19×19网格上的先验框比10×10网格上的要小,比5×5网格上的更小,以此类推。与YOLO不同的是,SSD不使用先验框来使检测器专注于物体大小,而是使用不同的网格来实现这一点。SSD的先验框主要用于使检测器处理物体形状(长宽比)的变化,而不是它们的大小。如前所述,SSD的先验框是使用公式计算的,而YOLO的先验框是通过对训练数据运行k-means聚类来找到的。
因为SSD使用3到6个先验框,它有6个网格而不是1个,所以实际上它总共使用了32个独特的检测器(这与具体网络结构有关)。因为SSD有更多的网格和检测器,它将输出更多的预测。YOLO进行了845次预测,而MobileNet-SSD则包含1917次预测。而SSD512甚至输出24564个预测!其优点是可以更容易找到图像中的所有物体。缺点是,你最终不得不做更多的后处理来找出你想要保留的预测。
由于这些差异,将真实框与检测器的匹配方式在SSD和YOLO之间稍有不同,损失函数也略有不同。后面讲解训练过程时会讨论这个问题。
现在关于这些模型如何做出预测已经讲解的非常清楚了。现在让我们来看看训练目标检测模型所需的数据类型。
