@Team
2018-04-03T15:37:30.000000Z
字数 3716
阅读 2675
干货|(DL~2)卷积神经网络
石文华
文章来自:https://leonardoaraujosantos.gitbooks.io
作者:Leonardo Araujo dos Santos
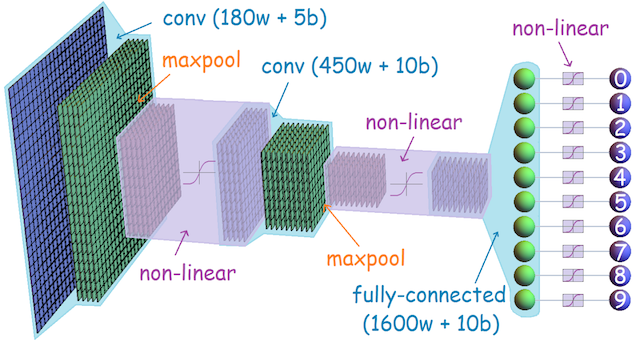
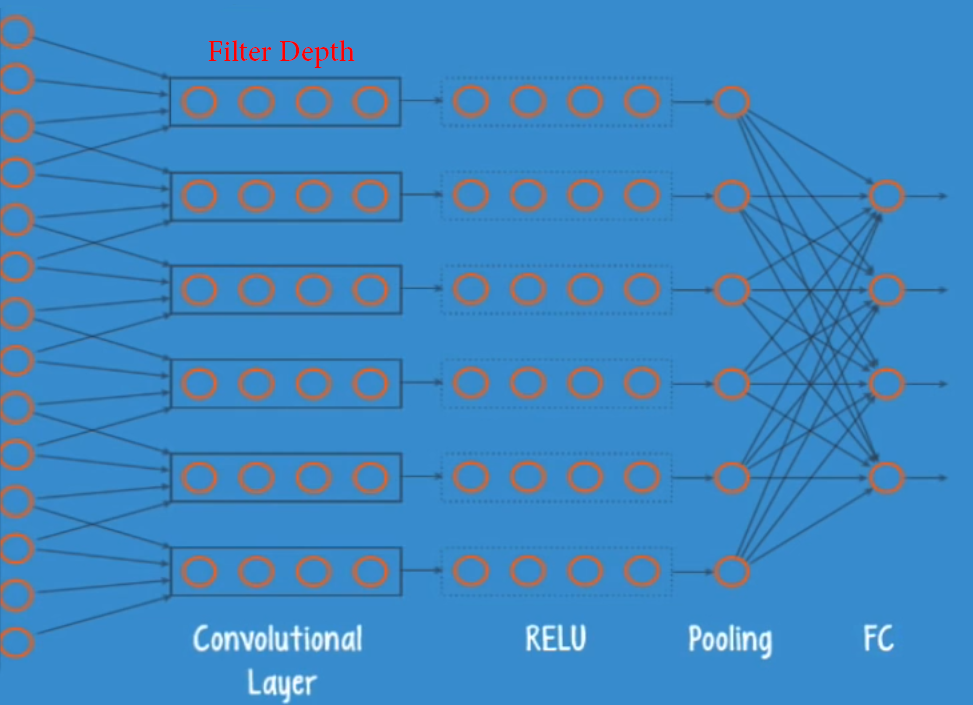
介绍
卷积神经网络由很多层组成,利用过滤器(卷积核)从输入中获取有用的信息,这些卷积核的参数通过“学习”自动的进行调整,使其为没有进行过手工特征提取的任务提取最有用的信息。卷积神经网络更适合图像任务,而全连接神经网络并不很适合图像分类问题。
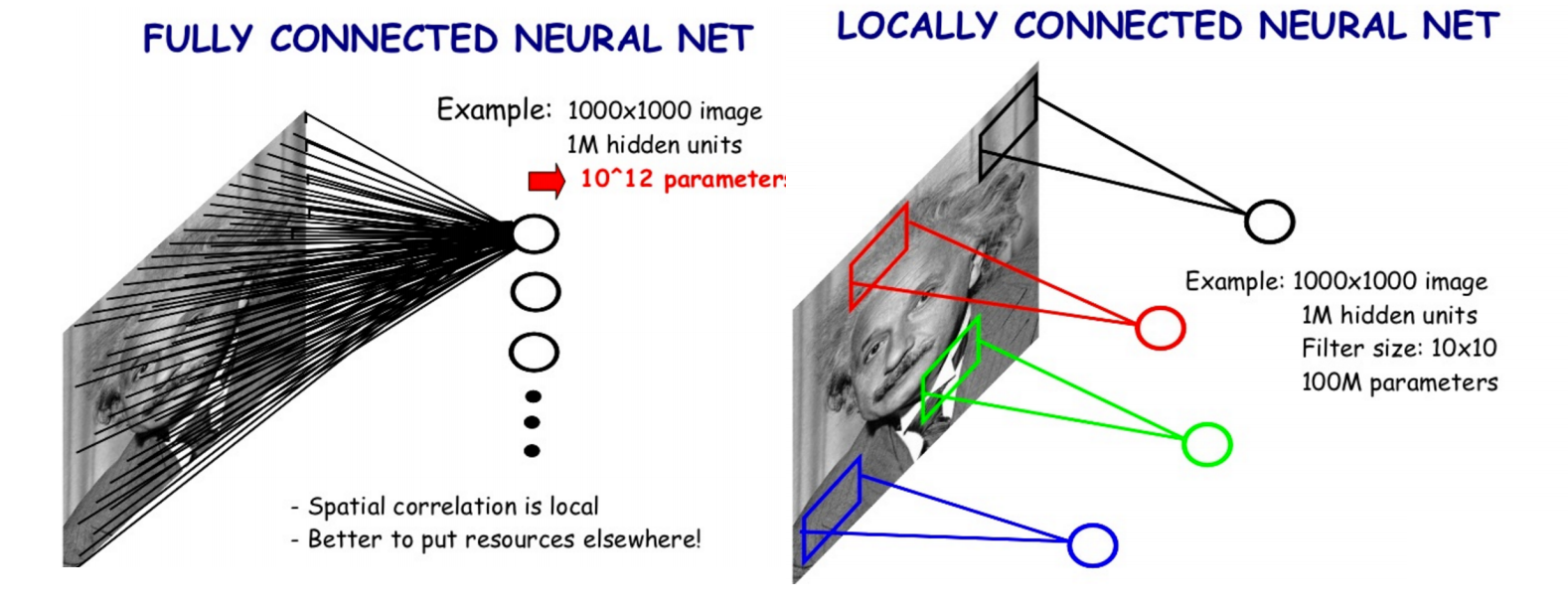
与全连接神经网络的对比
在全连接网络中,我们需要将图像转化为一个一维的向量[1,(width.height.channels)],然后将数据送入一个全连接的隐藏层,如下图的1000*1000图片,输入到100万个节点的隐藏层,这样一个隐藏层就会产生10¹²个参数,而如果使用10*10的卷积核做卷积,这个卷积层才1亿个参数。
常见的构建模式
通常[CONV-> ReLU-> Pool-> CONV-> ReLU-> Pool-> FC-> Softmax_loss(在训练期间)]这样的模式相当普遍。

卷积层
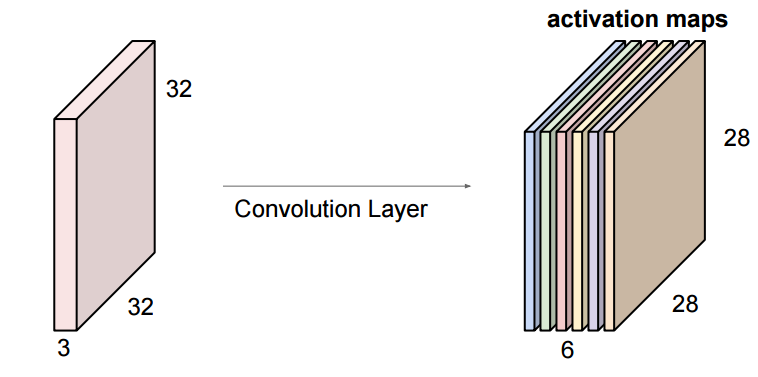
卷积神经网络中最重要的操作是对输入做卷积,如果我们将该一个32x32x3图像与5x5x3进行卷积(卷积核深度必须与输入的深度相同),步长为1,则输出的特征图的维度是28x28x1。

过滤器的作用相当于对图片进行特征提取,并且一个过滤器在一个输入上只会产生一个特征图。

如果我们希望我们的卷积层寻找6个不同的特征图。在这种情况下,我们需要6个5x5x3过滤器。每一个过滤器都会对输入图片进行特征提取。
卷积本身是一种线性操作,如果我们不想受到线性分类问题的困扰,那么我们需要在卷积做完之后添加一个非线性层(通常是Relu)。
使用卷积作为模式匹配的另外一个原因是图像上搜索的目标跟位置是不相关的。在卷积神经网络中,模型将在训练期间对目标所在的确切位置学习它的特征。
超参数
卷积层的超参数有:
卷积核的大小(K):小的更好(如果是在第一层,需要消耗大量的内存)
步长(S):卷积核窗口将滑动多少个像素(通常为1,在pooling层通常为2)
零填充(pad):在图片边缘填充0,使得输出跟输入的大小一致(F = 1,PAD = 0; F = 3,PAD = 1; F = 5,PAD = 2; F = 7,PAD = 3)
过滤器数量(F):也就是希望输出多少个特征图。
输出的特征图的大小
通常情况下,卷积之后的输出是小于输入的,但是我们可以使用0填充使得输出跟输入大小一致。不使用全零填充情况下计算输出特征图的大小,我们可以使用下列公式:
Out(length)=[in(length)-filter(length)+1]/stride(length)
Out(width)=[in(width)-filter(width)+1]/stride(width)
卷积操作
接下来的几个例子,我们通过改变一些超参数来看看卷积操作的效果。
padding为0,步长为1.
输入为4*4的矩阵,卷积核为3*3,padding为0,步长为1,如下图:
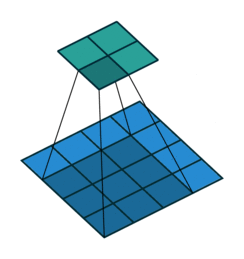
padding为1,步长为1.
输入为5*5的矩阵,卷积核为3*3,padding为1,步长为1,在某些库中,会有参数“same”使得输出矩阵的维度跟输入是一样的。
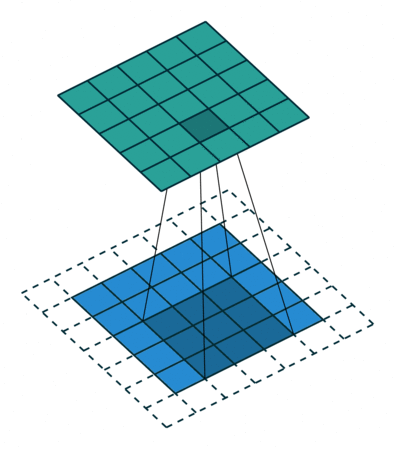
参数的数量(权重)
我们用一个简单的例子举例说明如何计算一个卷积层的参数的数量,输入图片为32*32*3,也就是32*32大小的RGB彩色图,卷积核大小为(5*5),步长为1,padding为2,卷积核数量为10(也就是深度为10),参数的数量为:
(5*5*3+1)*10=760,也就是说参数的数量只与卷积核的大小,输入图片的深度以及卷积核的数量有关,其中+1是偏置项,你也可以省略+1,因为偏置项可以设为0。
特征图占的内存
如何计算卷积图层输出所需的内存量呢?假设我们的输入为32x32x3,3表示RGB三个通道。卷积层的配置为:Kernel(F):5x5,Stride:1,Pad:2,numFilters:10,因为我们使用了填充,所以输出将是32x32x10,最终得到特征图所占的内存大小为:32*32*10=10240字节。内存量基本上只是输出量张量的乘积。
1*1卷积核
这种类型的卷积通常适用于深度,合并它们的时候,并不影响空间信息。
代替大卷积
这里我们解释一下级联几个小卷积的效果,如下图所示,两次3*3的卷积效果相当于一次5*5卷积之后的效果,也就是说级联可以使感受野变大。
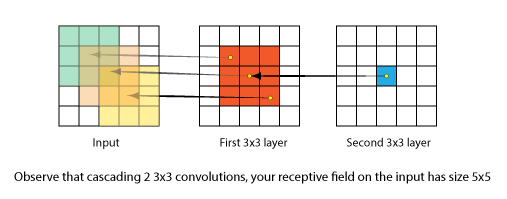
现在更多的是趋向于使用小的卷积核,例如7*7的卷积核你可以使用三个3*3深度相同的卷积核来替换,但是不要在第一层替换,因为深度不匹配,所以无法在第一层替换(除非你第一层只有3个卷积核)
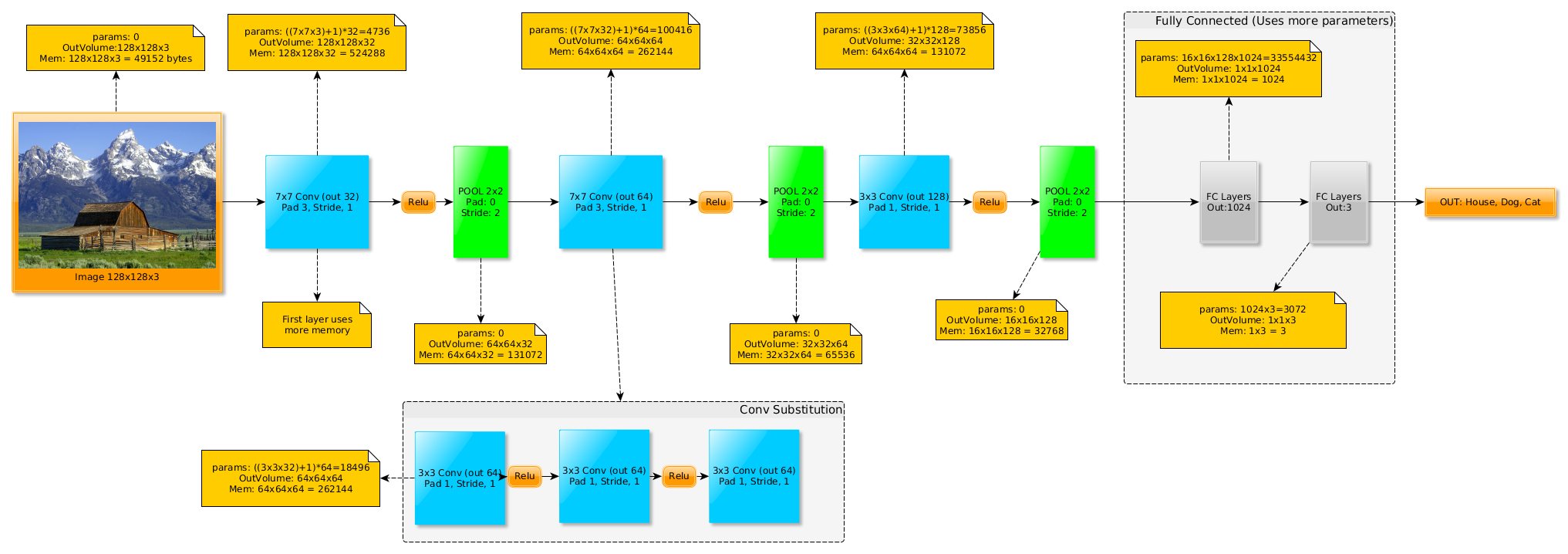
在上图中,我们用3个3x3的卷积核代替一个7x7的卷积核,每个卷积核中间我们有Relu层进行非线性化。此外,越到后面我们拥有更少的权重以及乘加操作,因此计算速度会更快。
计算替换的7*7卷积
输入矩阵为W*H*C的矩阵上使用C个7*7的卷积核,我们可以计算出参数的数量为:7*7*C*C,如果我们使用3个3*3的过滤器代替7*7的话参数的数量为:3*3*3*C*C,可以看出我们将会有更少的参数,由于卷积层之间还要进行非线性的relu操作,所以我们的非线性程度更大。更少的参数和更大程度的非线性操作将使得模型会更优。
在第一层进行替换
如前所述,我们一般不会在第一层用小的卷积代替大的卷积,因为第一层使用小卷积的话得到的特征图所占的内存是远比大卷积得到的特征图的内存要大很多的,有兴趣的话可以计算一下输入图片为256*256*3,卷积神经网络的第一层为3x3与64个滤波器,步幅1和深度7x7和步幅2相同的深度的情况进行比较。
瓶颈层来替换3*3
用一种称为瓶颈的机制来简化3x3卷积。与正常3×3卷积的效果是相同的,但它具有更少的参数和更多的非线性,观察下图用瓶颈层替换3*3的卷积,效果是一样的,但是参数更少,非线性更显著。
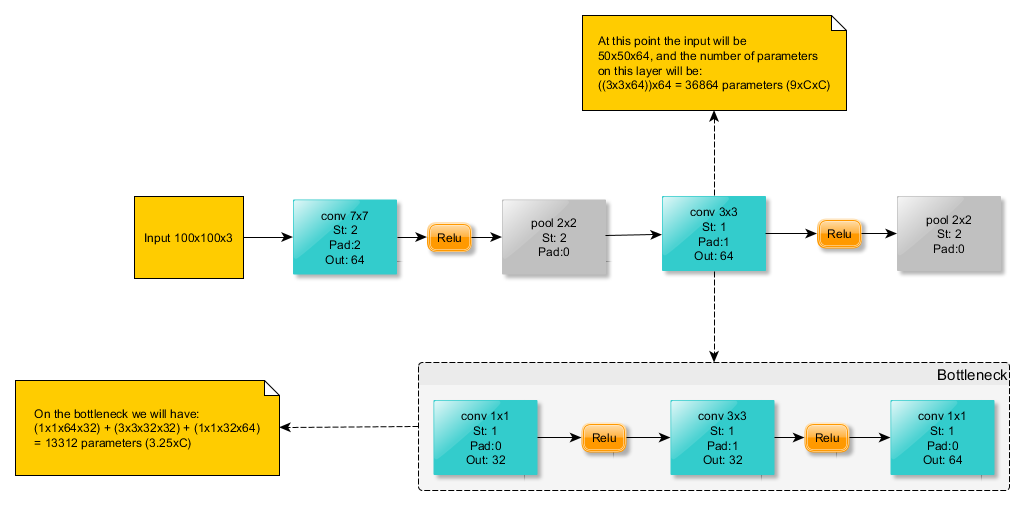
瓶颈层上使用的参数量计算如下:

计算出了是3.25*C*C,明显比9*C*C更少。
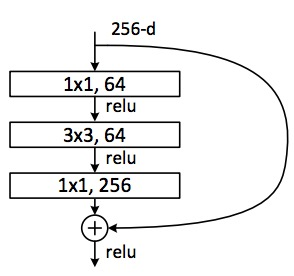
微软的残差网络也是用了这种瓶颈层,如下图所示残差网络。
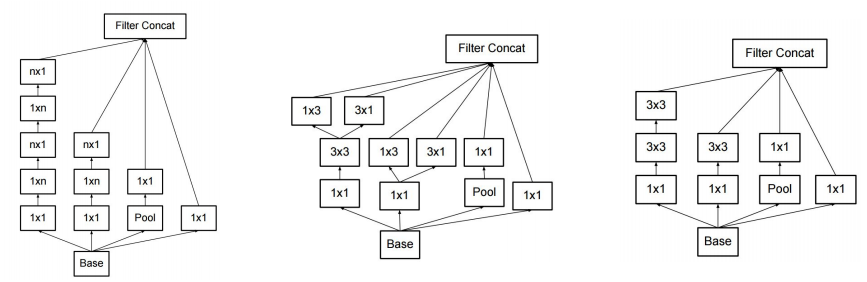
另外一种替换3*3使得参数更少的结构是先使用1*3*C再使用3*1*C,googlenet的 inception层上使用了这种方式。

FC -> Conv
可以将全连接层转换为卷积层,反之亦然,但我们对FC-> Conv转换更感兴趣。这是为了提高性能。
例如,设想输出K = 4096和输入7x7x512的FC层,转换将为:
CONV:卷积核:7x7,pad:0,步幅:1,卷积核数量:4096。
使用2d卷积公式size :
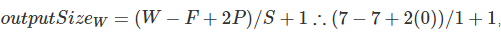
结果是1x1x4096。
通过将FC层转换为卷积的好处:
性能:由于权重共享,计算速度更快
你可以使用比你训练的图像更大的图像,但不会改变任何内容
你将能够在同一图像上检测到2个对象(如果使用更大的图像),则最终输出将大于单行矢量的输出。

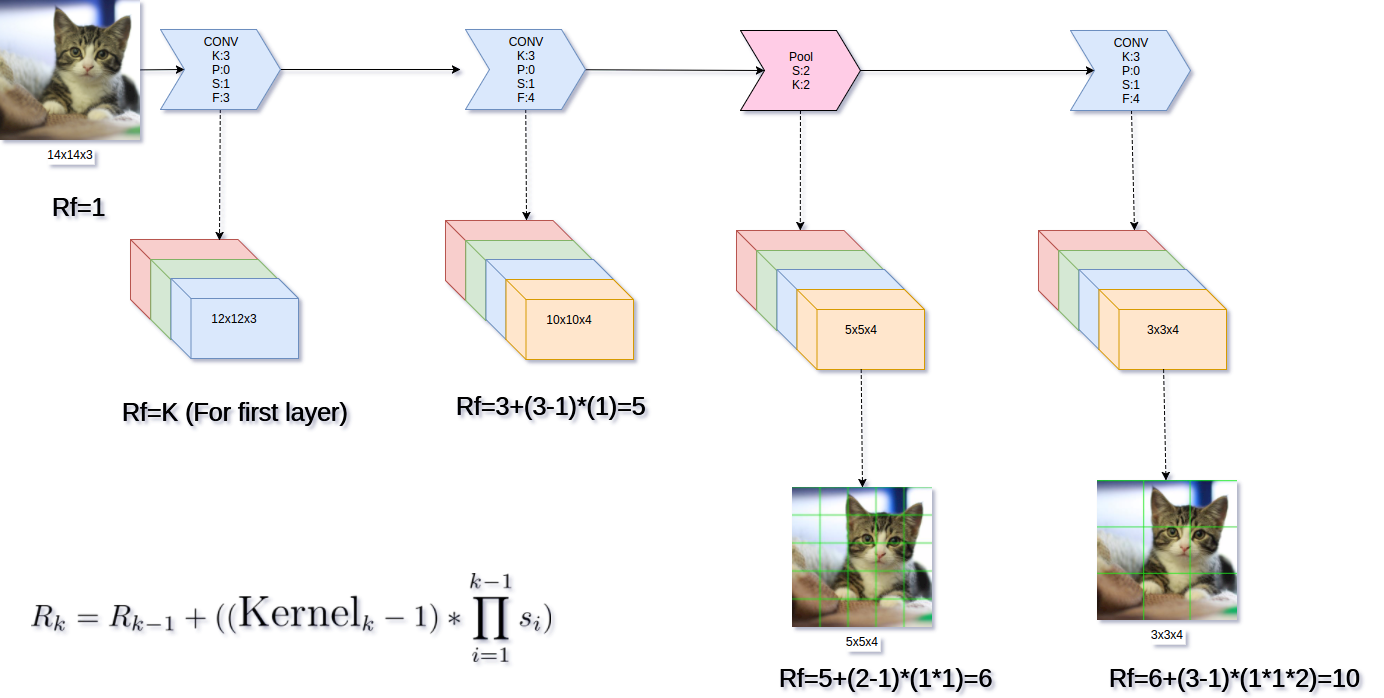
计算感受野
感受野是一个特定的卷积窗口,表示“看到”它输入的张量。
有时候,确切地知道每个单元格从输入图像上“看到”多少,这对于物体检测系统是特别重要的,因为我们需要以某种方式将某些激活图尺寸匹配回原始图像的尺寸(Label图片)。

Rk:当前层k的接受野
Kernel:当前图层k的内核大小
s:步长
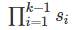 指每一层都输出直到第k-1层(所有以前的层,而不是当前层)
指每一层都输出直到第k-1层(所有以前的层,而不是当前层)
需要注意的一点是:
对于第一层,接受野是内核大小。
这些计算与图层类型(CONV,POOL)无关,例如,步长为2的CONV将与步长为2的POOL具有相同的感受野。
例:
输入为14x14x3的图像:
CONV:S:1,P:0,K:3
CONV:S:1,P:0,K:3
MaxPool:S:2,P:0,K2
CONV:S:1,P:0,K:3
参考文献:
http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf
http://cs231n.github.io/convolutional-networks/
https://www.youtube.com/watch?v=LxfUGhug-iQ
https://www.youtube.com/watch?v=FmpDIaiMIeA
https://www.youtube.com/watch?v=jajksuQW4mc
https://www.facebook.com/yann.lecun/posts/10152820758292143
http://neuralnetworksanddeeplearning.com/chap6.html
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
http://shawnleezx.github.io/blog/2017/02/11/calculating-receptive-field-of-cnn/
https://guillaumebrg.wordpress.com/2016/02/13/adopting-the-vgg-net-approach-more-layers-smaller-filters/
