@Team
2019-04-03T04:59:54.000000Z
字数 8346
阅读 4663
图解高效神经网络结构搜索(ENAS)
刘源
本文翻译自[Illustrated: Efficient Neural Architecture Search]https://towardsdatascience.com/illustrated-efficient-neural-architecture-search-5f7387f9fb6(需要翻墙)
针对于不同的任务,比如图像分类和自然语言理解,设计神经网络结构通常需要大量的结构工程和技能知识。因此,神经网络结构搜索(Neural Architecture Search,NAS)应运而生,其主要任务就是把人工设计神经网络结构的过程自动化。随着深度学习模型的愈发重要,人们对神经网络结构搜索的研究兴趣也越来越大。
目前有许多搜索或者发现神经网络结构的方法。在过去的几年中,有如下不同的搜索方法被提出,其中包括:
强化学习
遗传算法
序列的模型优化(Sequential model-based optimization)
- Progressive Neural Architecture Search 6
贝叶斯优化
基于梯度的优化
在这里,我们主要介绍Efficient Neural Architecture Search via Parameter Sharing (ENAS)这个使用强化学习来构建卷积和循环神经网络的神经网络结构搜索方法。作者提出了一种预定义的神经网络,由使用宏和微搜索的强化学习框架来指导生成新的神经网络。这就是由神经网络去自主构建另一个神经网络。
0. 概叙
ENAS中包含两种神经网络:
控制器——一种预定义的循环神经网络(RNN),一般是长短期记忆(LSTM)循环神经网络
子模型——图像分类任务所需要的卷积神经网络(CNN)
和绝大多数神经网络结构搜索(NAS)算法一样,ENAS包括三个方面:
- 搜索空间——所有可能的不同结构或者能够产生的子模型
- 搜索策略——产生这些结构或者子模型的方法
- 性能评估——测量这些产生的子模型效能的方法。
让我们看看这五种概念是如何构成ENAS的。
控制器通过使用搜索策略产生指令集(或者,更严格地说,做出和挑选决策),来控制或者直接构建子模型的结构。这些决策就像是组成子模型中特定网络层的各种操作类型(如卷积,池化等等)。通过这些决策便能够构建子模型。一个生成出来的子模型就是众多能够在搜索空间中可能产生的模型之一。
接下来,我们将使用随机梯度下降法来训练这个子模型直到收敛,从而最小化预测类别与真是类别之间的期望损失函数(对于图像分类任务来说)。经过指定的迭代次数——我们习惯称为子迭代(child epoch)——之后,训练将完成,然后我们便可以去验证这个训练好的模型。
随后,我们使用REINFORCE——一种基于策略的强化学习算法——去更新控制器的参数,从而最大化期望奖励函数,也就是验证准确率。我们希望这种参数更新能产生更好的决策从而给出更高的验证准确率。
这整个过程(前面三个段落)其实只是一个整体的迭代过程(epoch)——我们称之为控制器迭代(controller epoch)。一般来说我们会重复指定次数的控制器迭代,比方说2000次。
在这些控制器迭代过程中产生的2000个子模型中,我们将选择拥有最高验证准确率的子模型来作为图像分类任务的神经网络。然而在这个子模型用于部署之前,当然要经过至少一轮或者更多的训练。
整个训练过程的算法如下:
CONTROLLER_EPOCHS = 2000CHILD_EPOCHS = 100-------------------------------------------------------------------------Build controller network-------------------------------------------------------------------------for i in CONTROLLER_EPOCHS:1. Generate a child model2. Train this child model for CHILD_EPOCHS3. Obtain val_acc4. Update controller parameters-------------------------------------------------------------------------Get child model with the highest val_accTrain this child model for CHILD_EPOCHS
这整个问题基本上就是具备典型元素的强化学习框架:
- 智能体(Agent)——控制器
- 动作(Action)——用于构建子模型的决策
- 奖赏(Reward)——子模型的验证准确率
强化学习的目标就是从智能体(控制器)选择的动作(构建子模型的决策)中最大化奖赏(验证准确率)。
1. 搜索策略
回顾一下前面部分中,控制器使用指定搜索策略来产生子模型结构的过程。在这一部分,你应该有两个问题需要提出:(1)控制器如何做出决策?(2)什么样的搜索策略?
控制器如何做出决策?
我们首先来看看控制器,一个LSTM神经网络。这个LSTM神经网络通过softmax分类器来挑选决策,然后进入自回归的模式中:上一步的决策会作为输入嵌入到下一步中。
什么样的搜索策略?
ENAS的作者提出了两种策略用于搜索或者生成结构。
- 宏搜索(Macro Search)
- 微搜索(Micro Search)
宏搜索是一种控制器决定整个网络的方法。使用这种方法的文献还有NAS 1,FractalNet 11和SMASH 12。另一方面,微搜索是一种控制器设计模块或者构建组件的方法,这些模块或者组件联合起来构建出最终的网络。实现了这种方法的文献还有Hierarchical NAS 13,Progressive NAS 14和NASNet 2。
在接下来的两小节中,我们将看到ENAS如何实现这两种策略的。
1.1 宏搜索
在宏搜索中,控制器需要对子模型的每一层做出两种决策:
- 决定对前面的网络层该执行什么操作
- 考虑用于跳跃连接的前面的网络层是哪个
在这个宏搜索的样例中,我们将看到控制器如何生成四层的子模型。这个子模型中的每一层将分别使用红、绿、蓝和紫色进行区分。
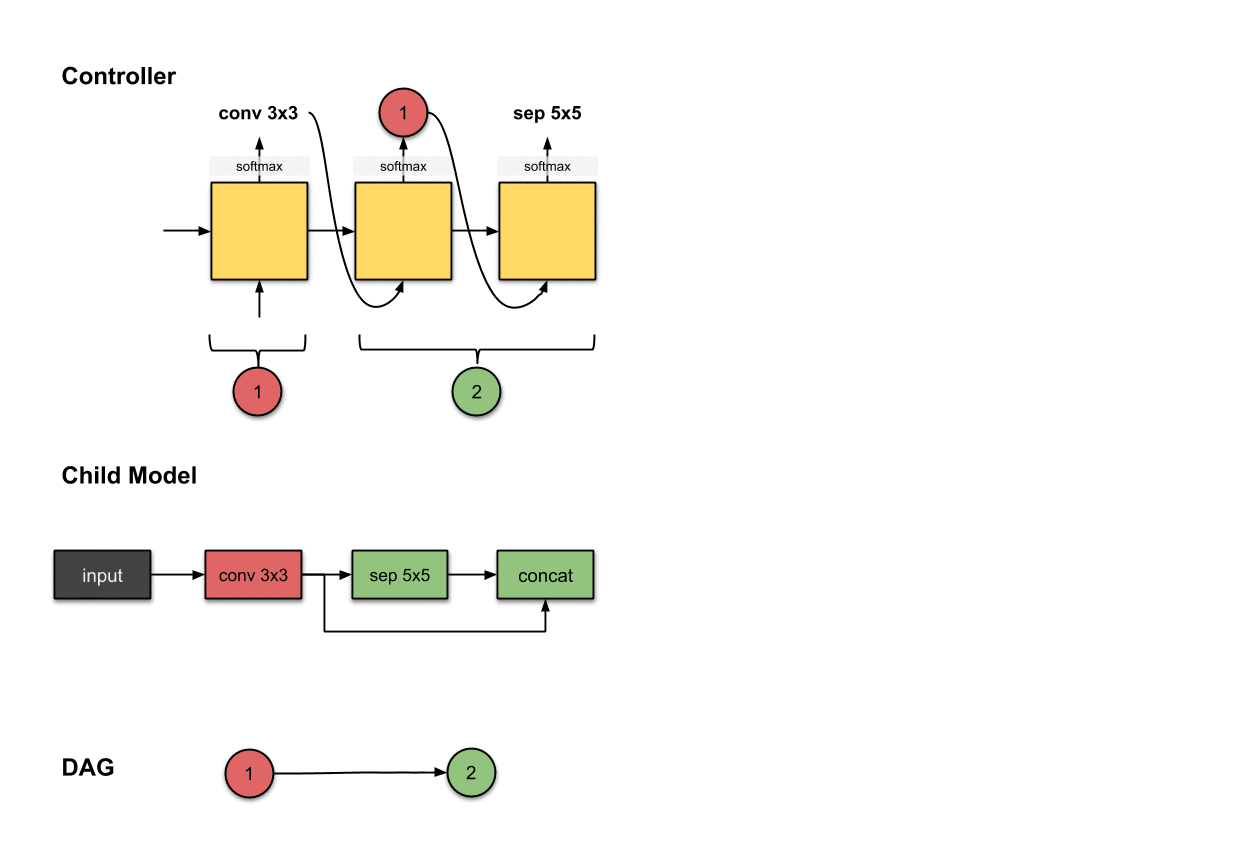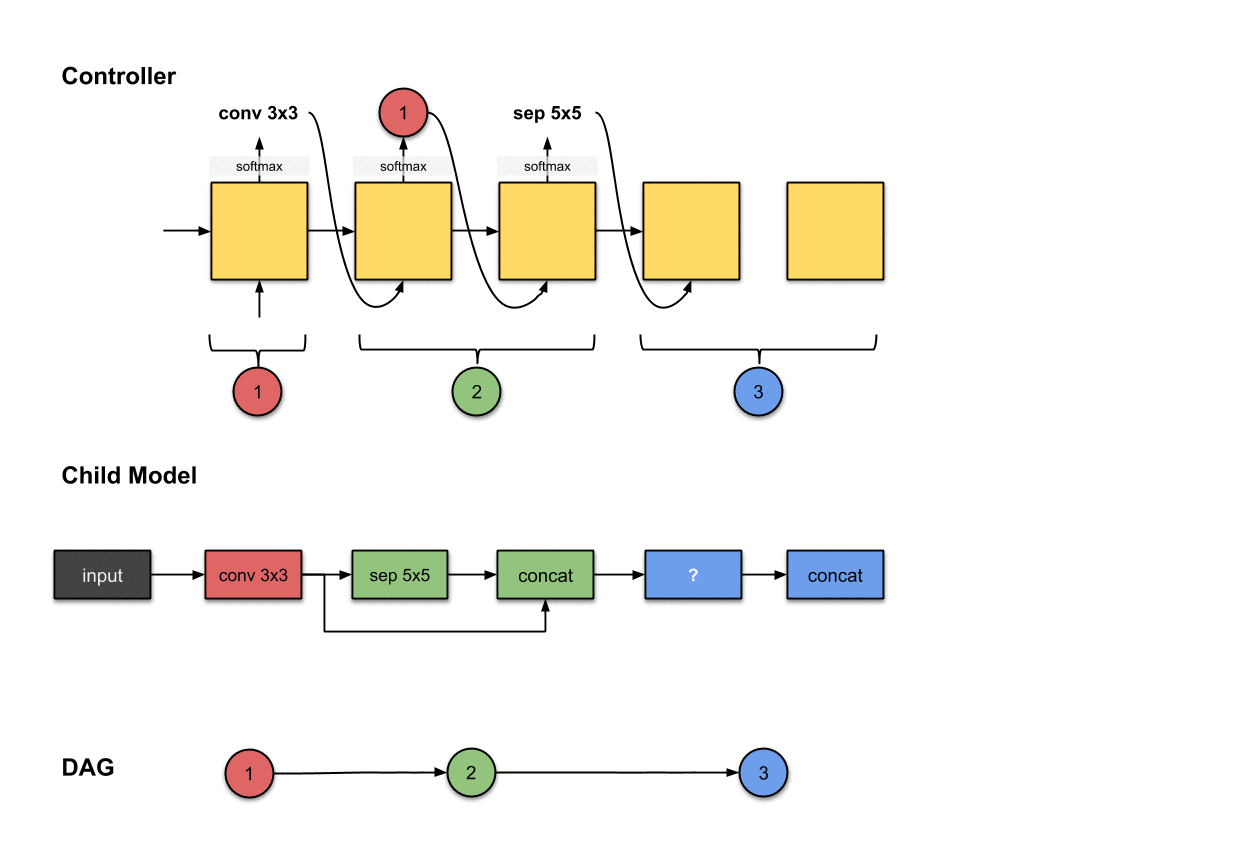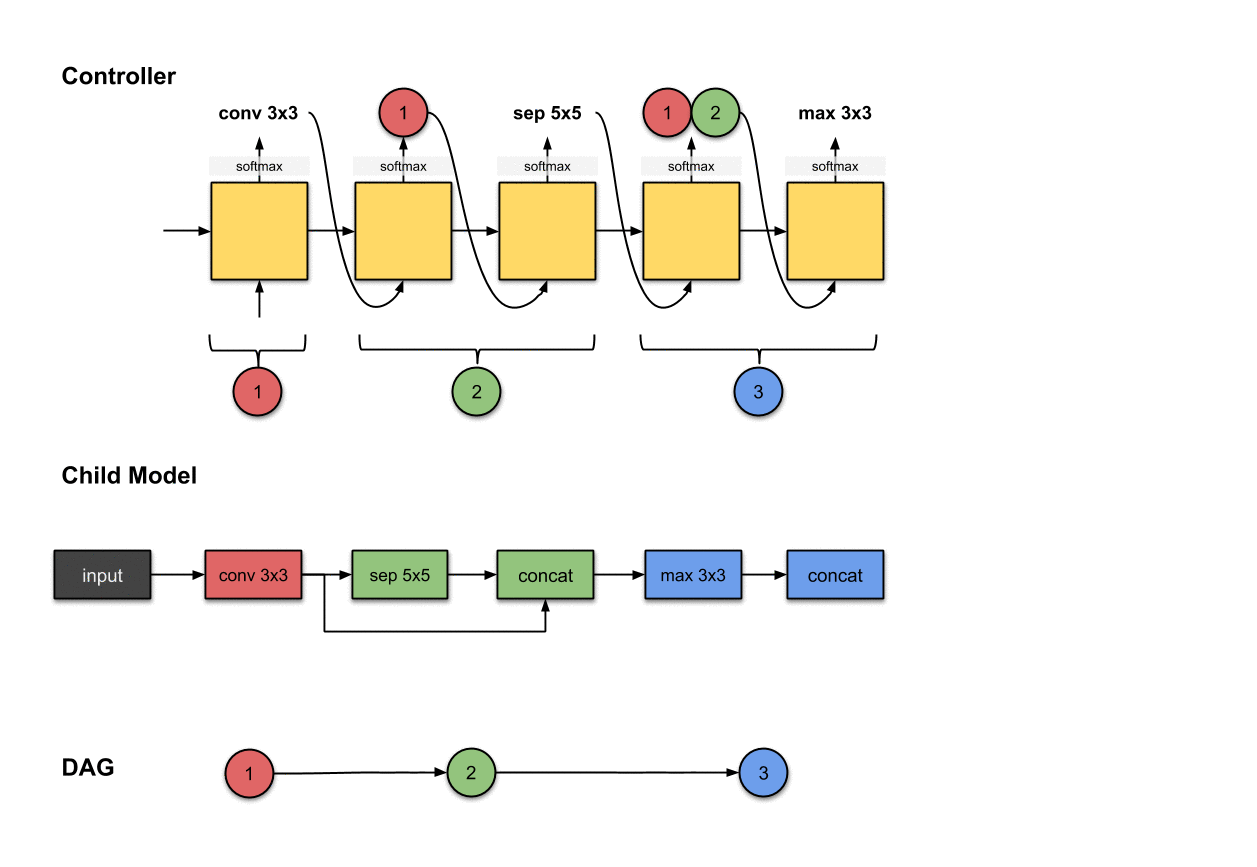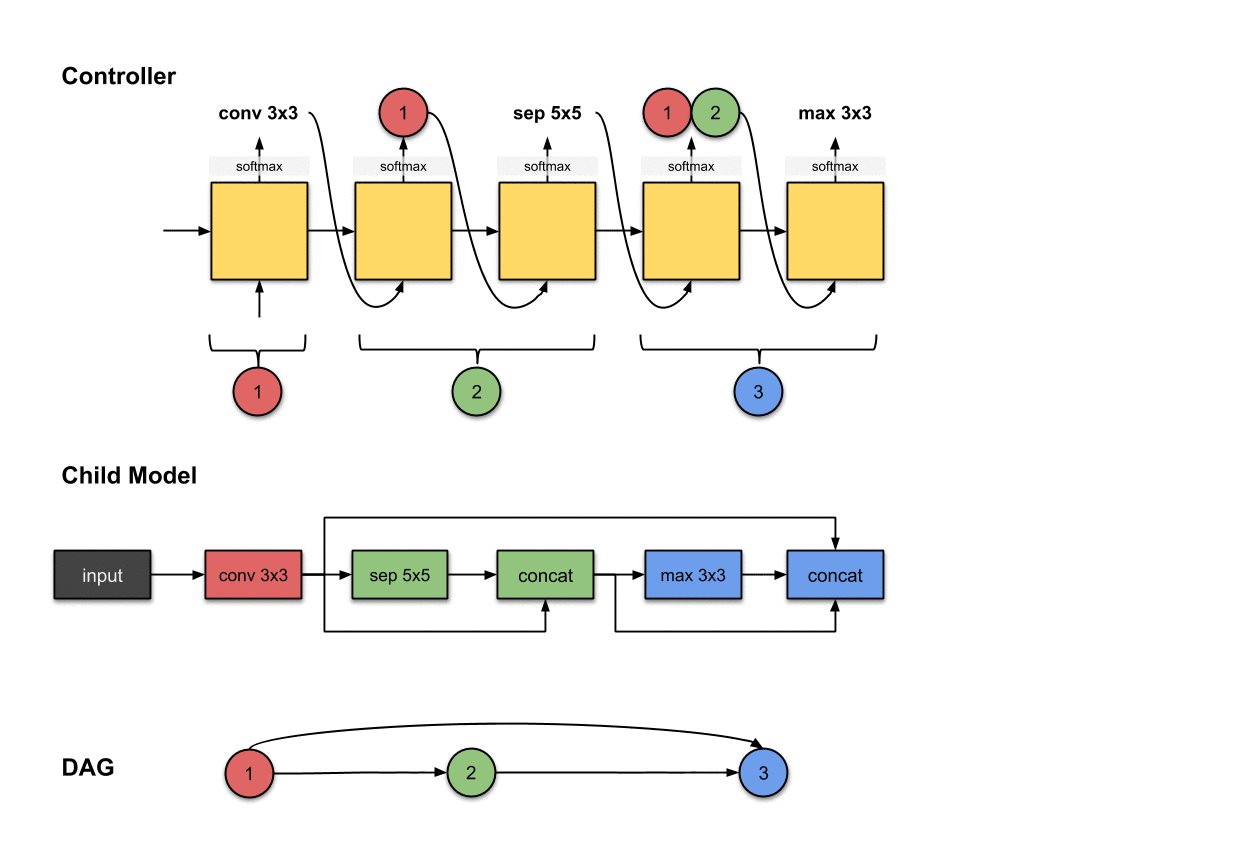
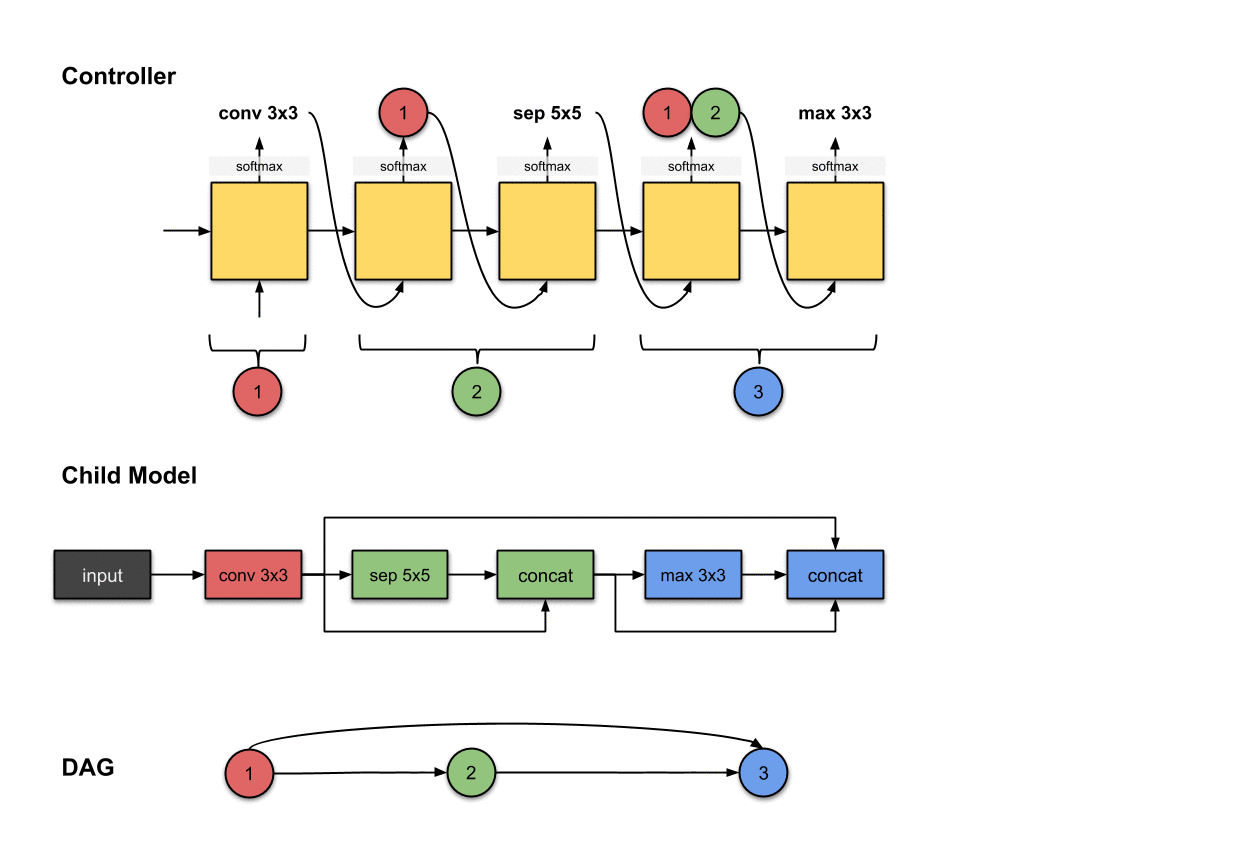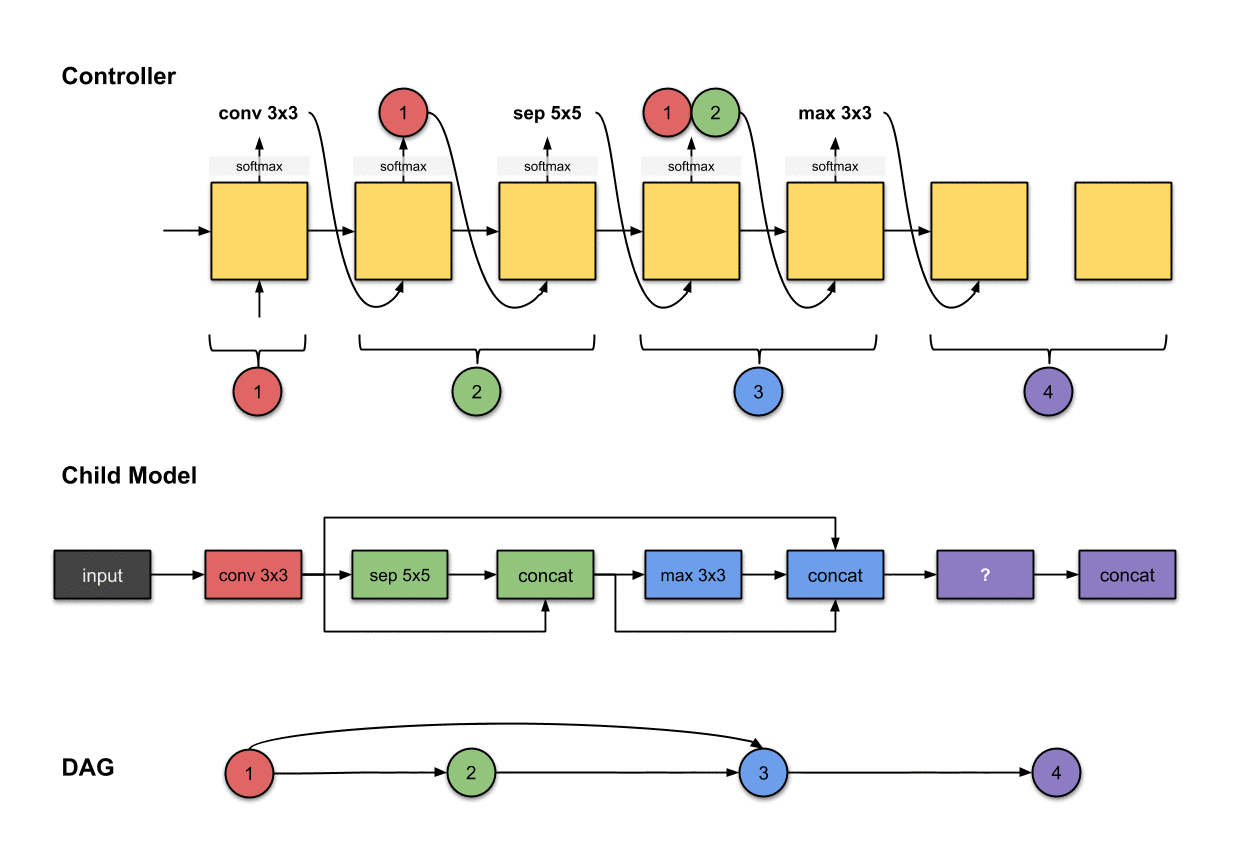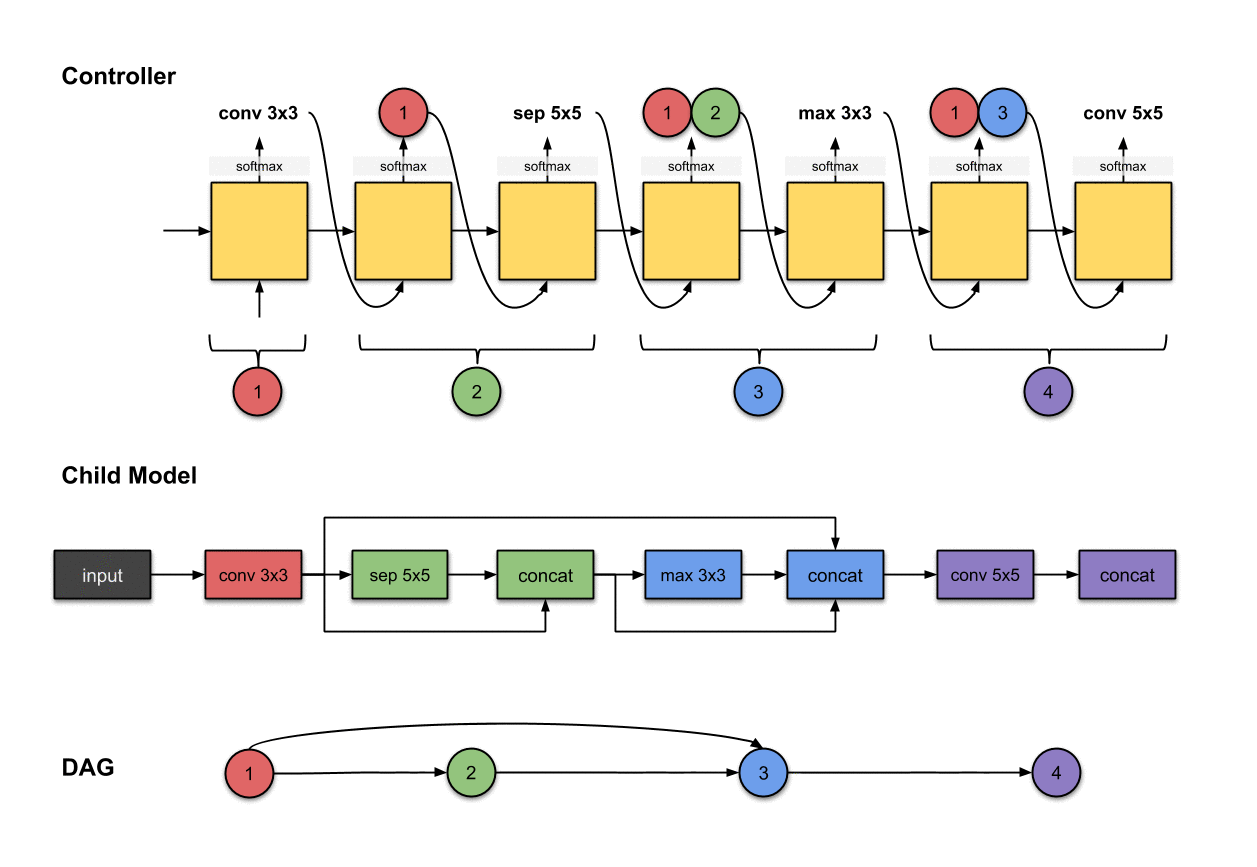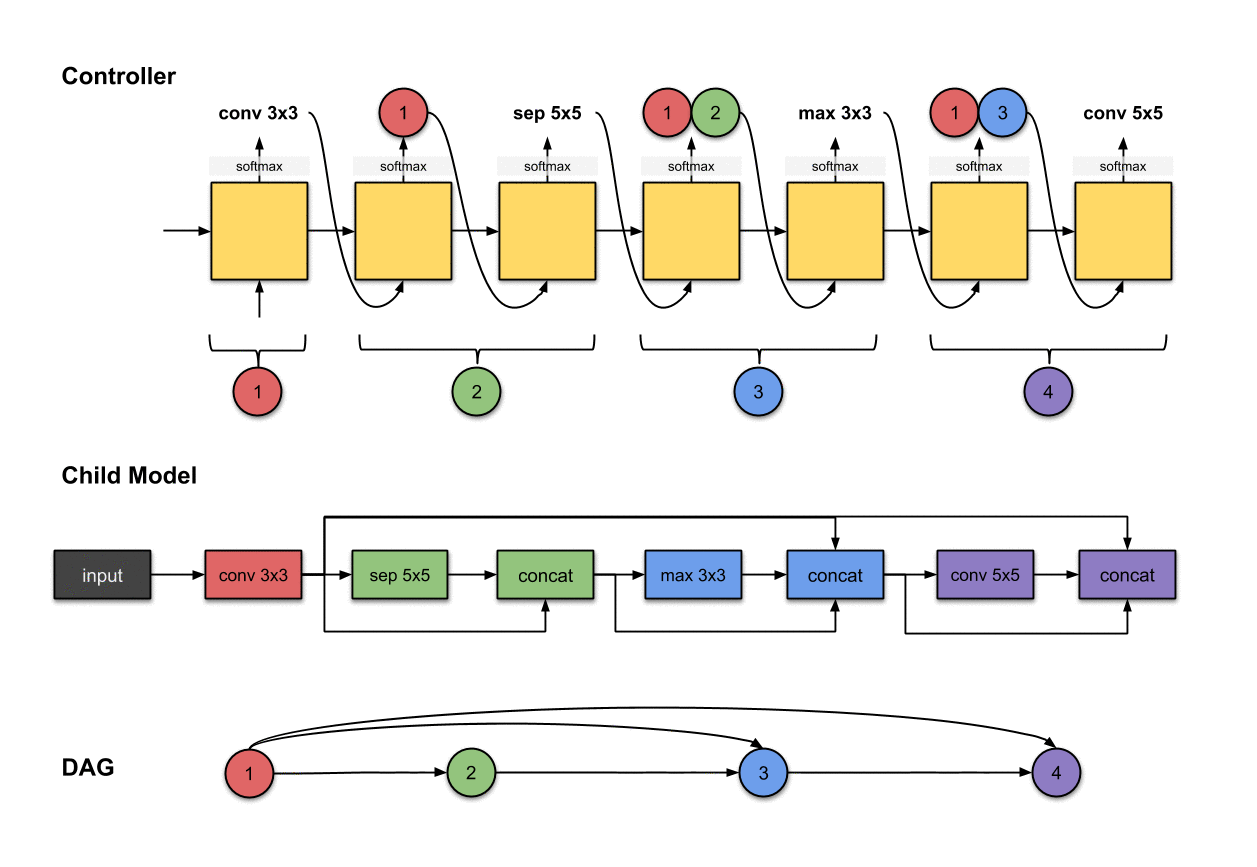
1.1.1 卷积层1(红色)
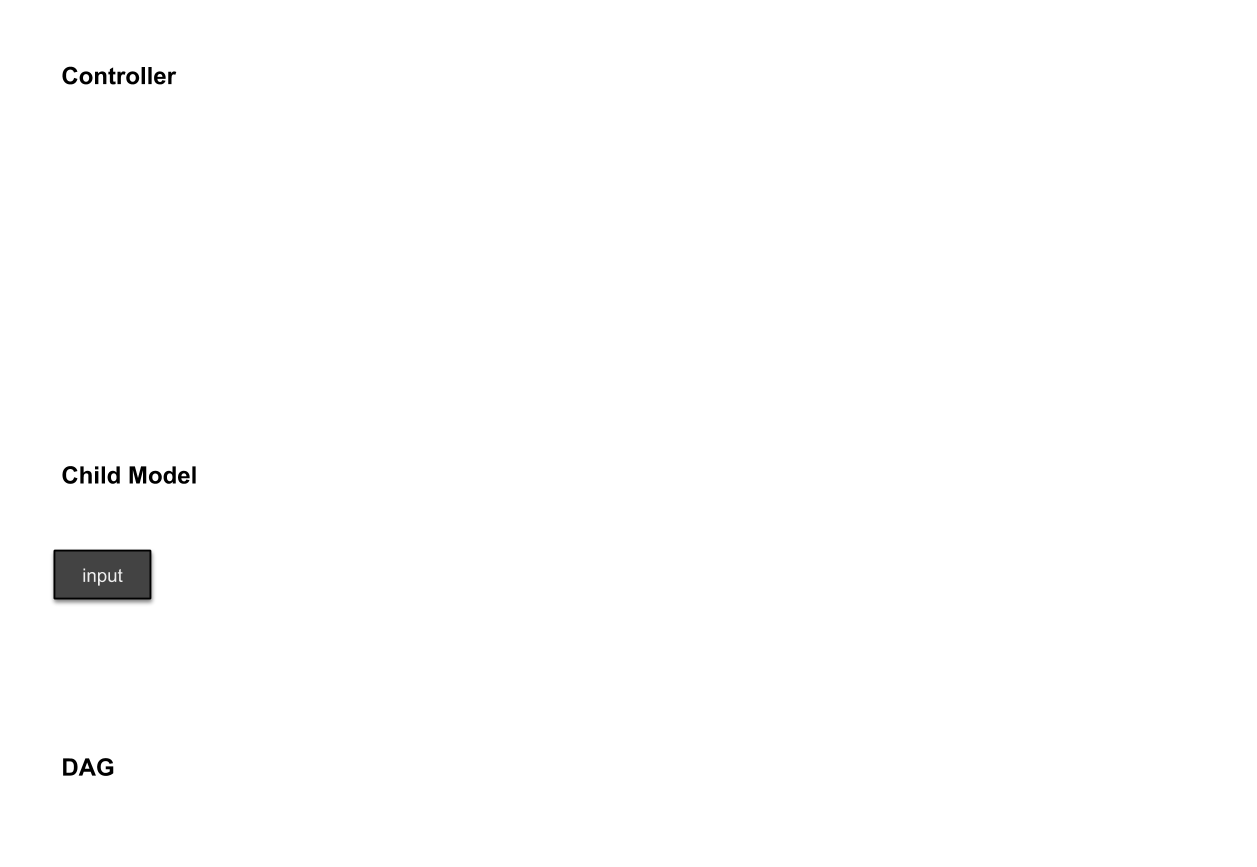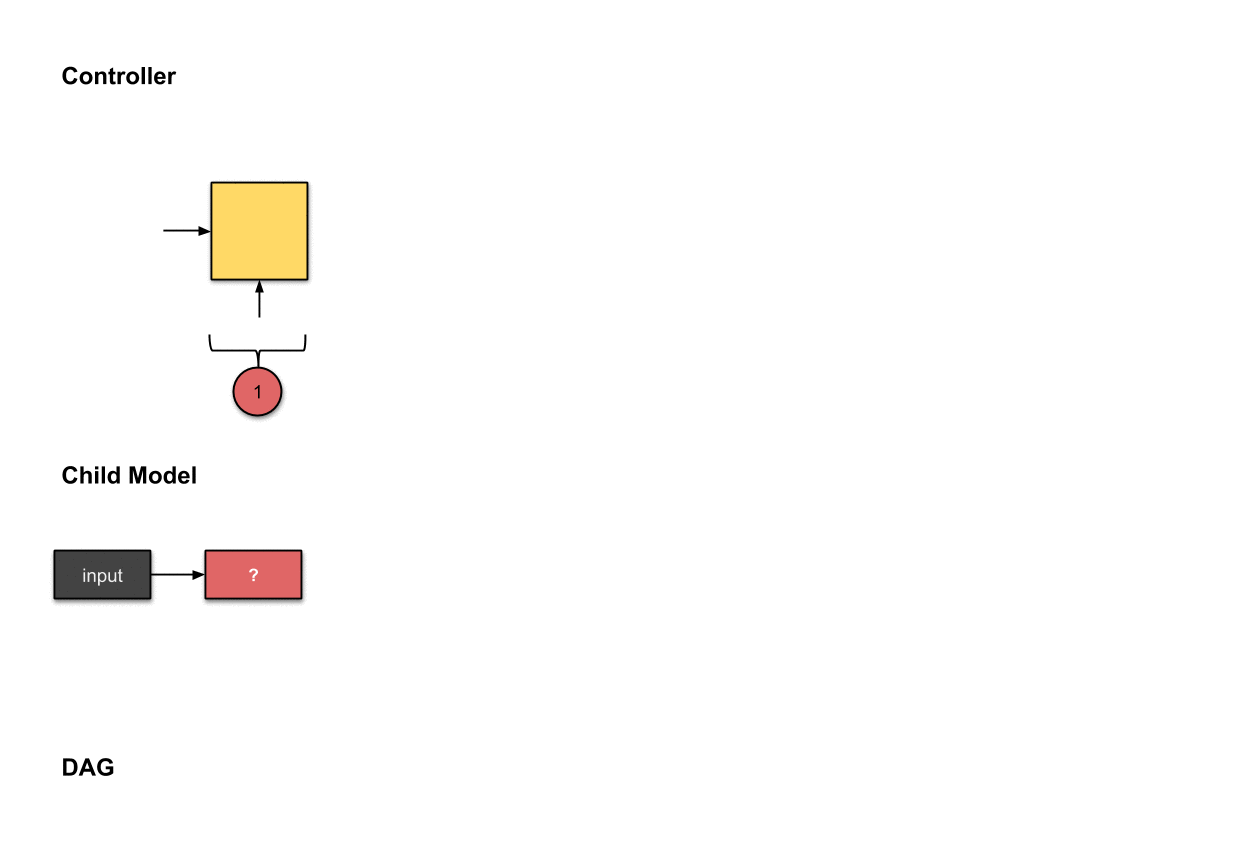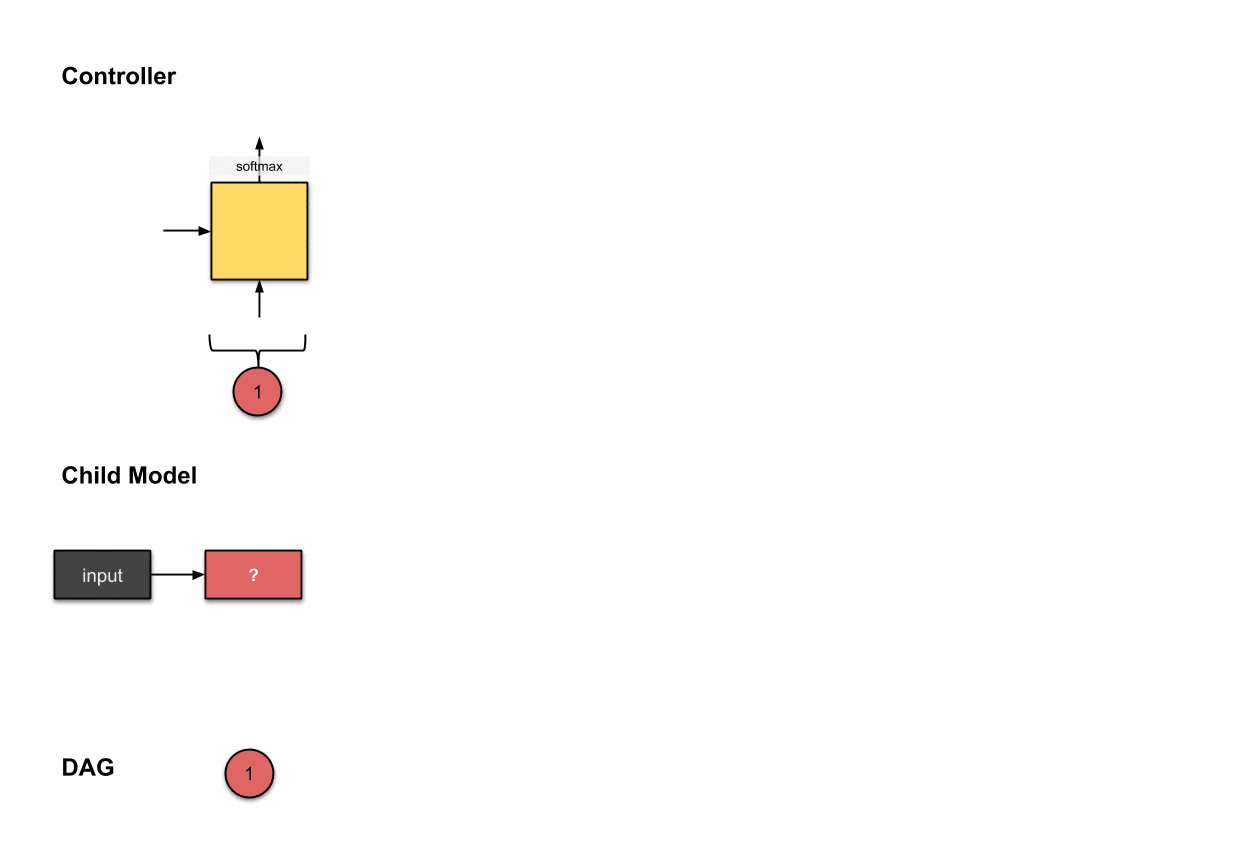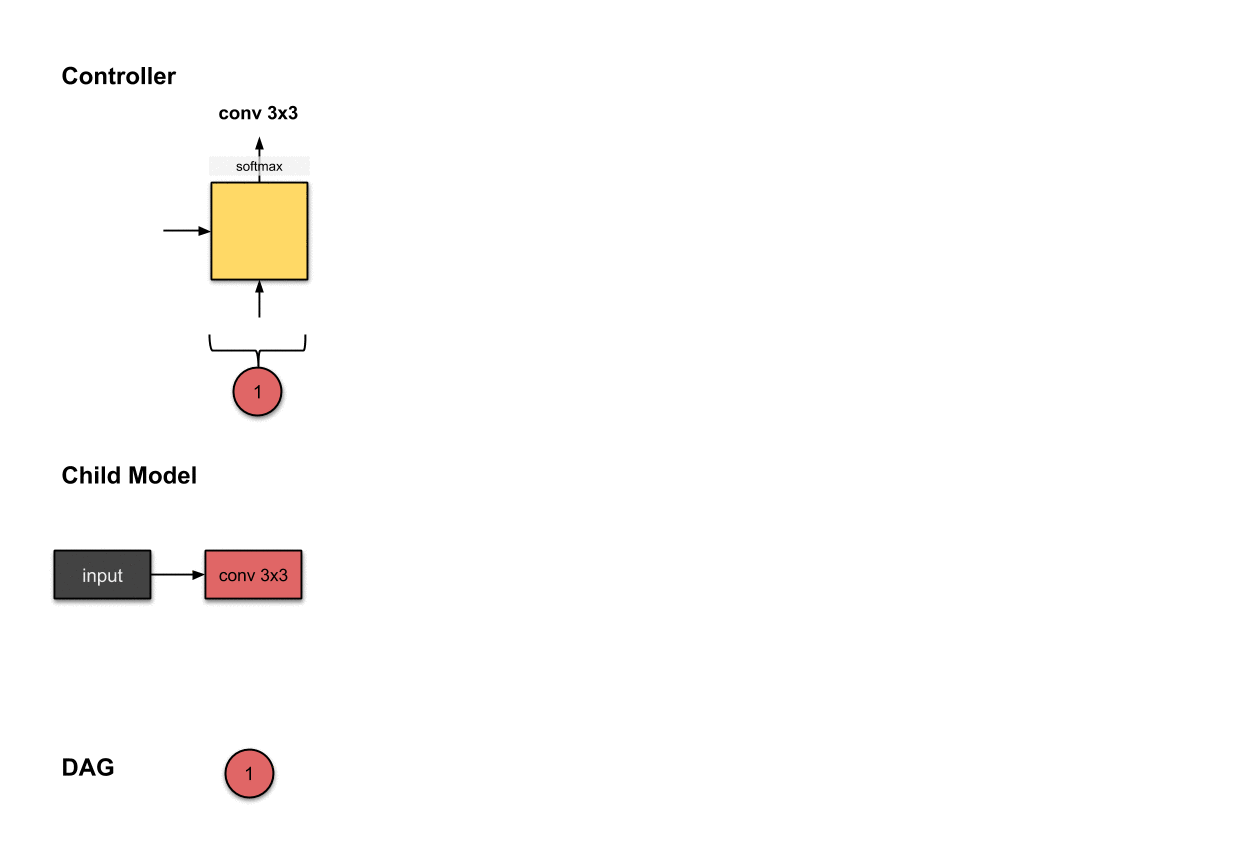
控制器第一步的输出()与在子模型中构建第一层网络(红色)相关。这意味着子模型对输入图像执行了的卷积操作。
我们首先从控制器执行的第一步开始。这一步的输出被softmax函数归一化成一个向量,随后翻译成了一个的操作。对于子模型来说,这意味我们使用一个的滤波器对输入图像执行了卷积操作。目前为止,控制器还只做出了一个决策,而我们前面说过需要做出两个决策。这是因为目前还只是第一层网络,所以我们只需要决定对前面的网络层该执行什么操作,而不需要考虑用于跳跃连接的前面的网络层是哪个。
1.1.2 卷积层2(绿色)
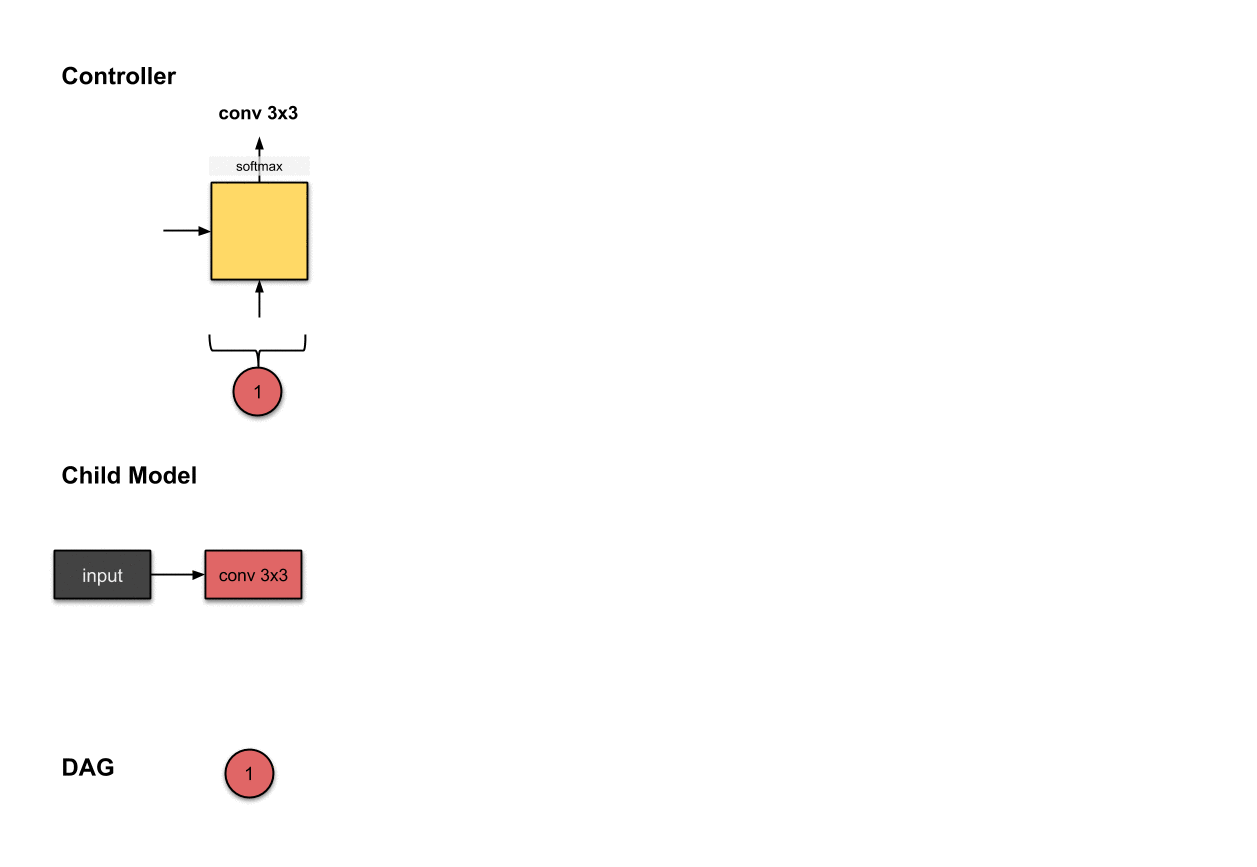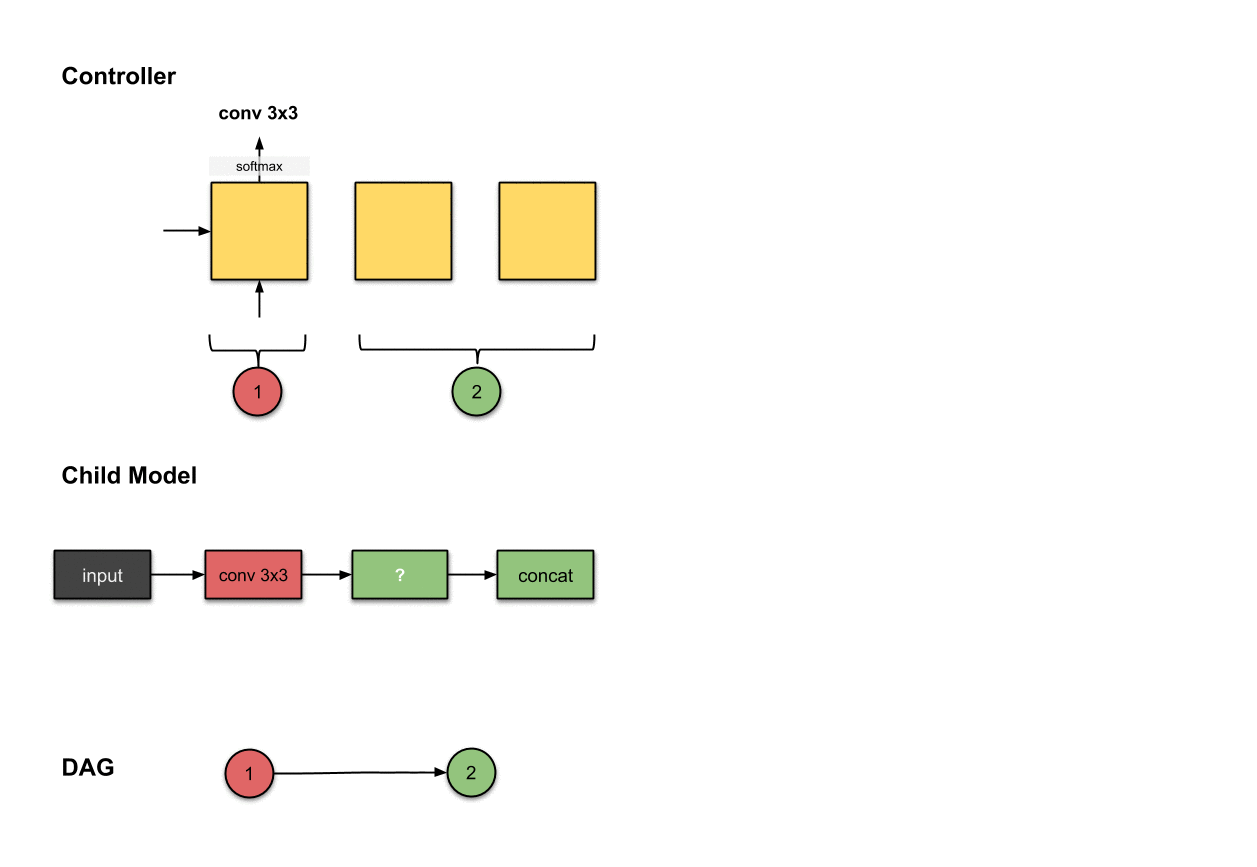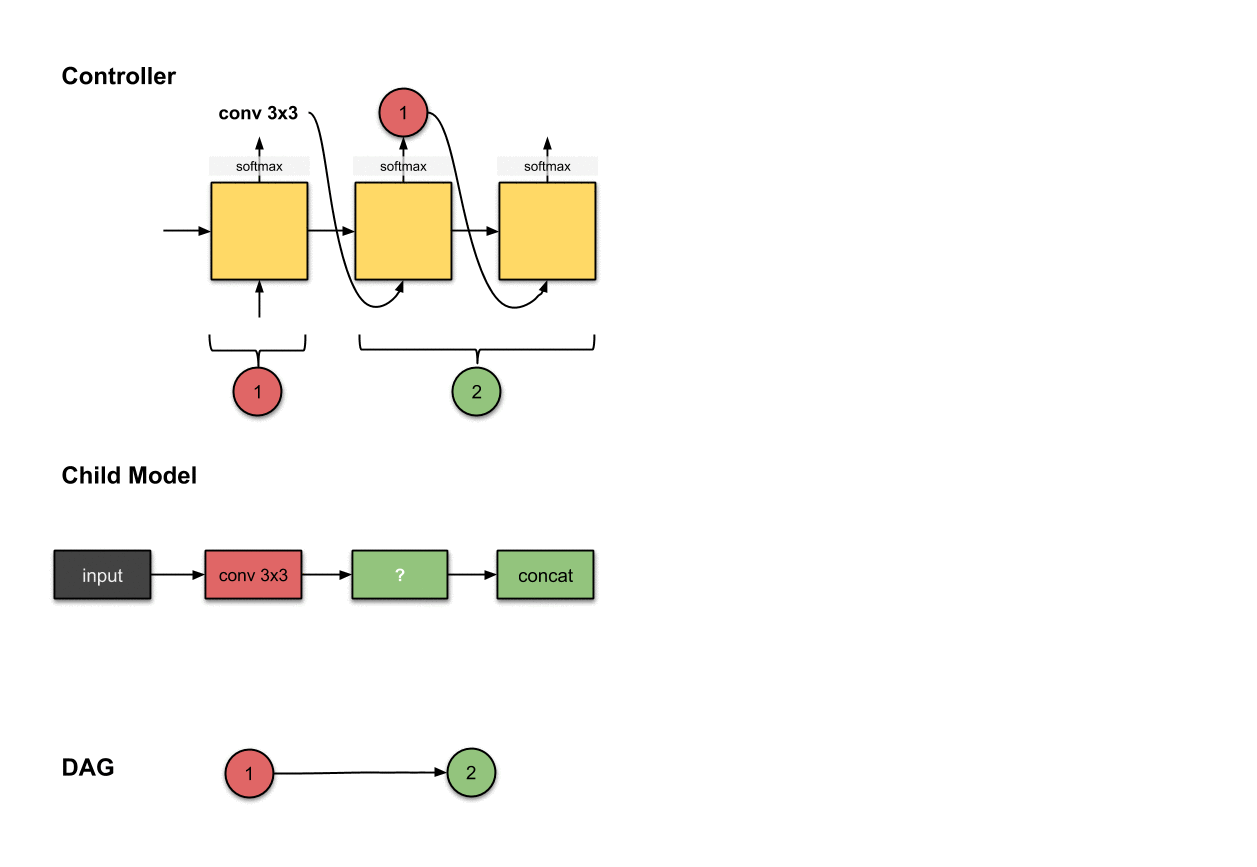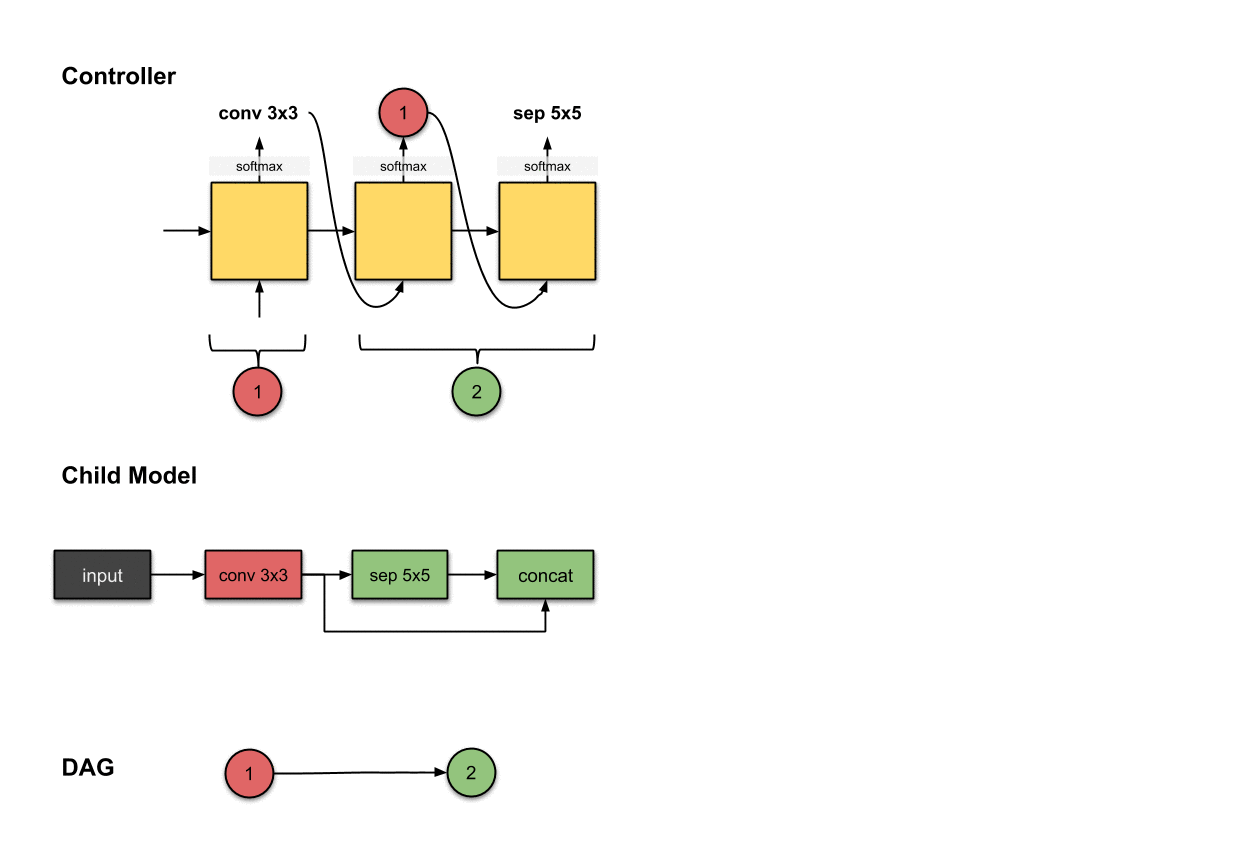
控制器的第二和第三步的输出(和)和在子模型中构建卷积层2(绿色)相关。
为了构建后续的卷积层,这下控制器真的需要做出两个决策:(1)操作和(2)应该连接的层。在这里,我们看到它产生了和。对于子模型来说,这意味着我们对前面网络层的输出执行了一个的操作。然后这个操作的输出将会沿着深度维度与网络层(也就是红色的网络层)拼接(concatenated)到一起。
1.1.3 卷积层3(蓝色)
控制器的第四和第五步的输出(和)和在子模型中构建卷积层3(蓝色)相关。
我们重复先前的步骤来生成第三个卷积层。同样的,我们看到控制器产生了两个输出(1)操作和(2)应该连接的层。在这里分别是和。对于子模型来说,这意味着我们对前面网络层的输出执行了一个的操作。然后这个操作的输出将会沿着深度维度与网络层和拼接(concatenated)到一起。
1.1.4 卷积层4(紫色)
控制器的第六和第七步的输出(和)和在子模型中构建卷积层4(紫色)相关。
我们重复先前的步骤来生成第四个卷积层。同样的,我们看到控制器产生了两个输出,分别是和。对于子模型来说,这意味着我们对前面网络层的输出执行了一个的操作。然后这个操作的输出将会沿着深度维度与网络层和拼接(concatenated)到一起。
这样我们就通过宏搜索生成了一个子模型。接下来是微搜索。
1.2 宏搜索
正如前面所说,微搜索设计模块或者构建组件,这些组件一同组成了最终的结构。ENAS把这些单元称为“卷积单元”(convolutional cells)和“下采样单元”(reduction cells)。简单地来说,一个卷积单元或者下采样单元就是一个操作的组件。两者都比较类似,唯一的区别就是下采样单元是用来进行空间维度的下采样。
1.2.1 为从微搜索中推导的网络构建单元
以下是几种从微搜索中推到的子网络的构建组件的层次,从大到小分别是:
- 组件(block)
- 卷积单元和下采样单元
- 节点(node)
一个子模型包含多个组件。每个组件又包含个卷积单元和个下采样单元。而每个卷积或者下采样单元包括个节点。每个节点由标准卷积操作组成。和是两个可以人为调整的超参数。
下面是一个有3个组件的子模型。每个组件包含个卷积单元和1个下采样单元。每个单元中的操作在这里并没有列出来。
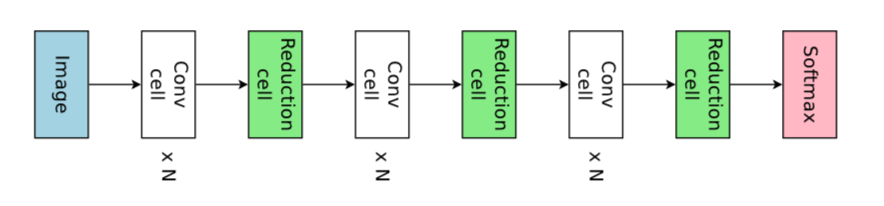
生成的最终网络总览
1.2.2 从微搜索中生成子模型
简单起见,我们首先构建一个只含有单个组件的子模型。每个组件包含个卷积单元和1个下采样单元。每个单元包含个节点。因此,我们生成的子模型应当如下图所示:
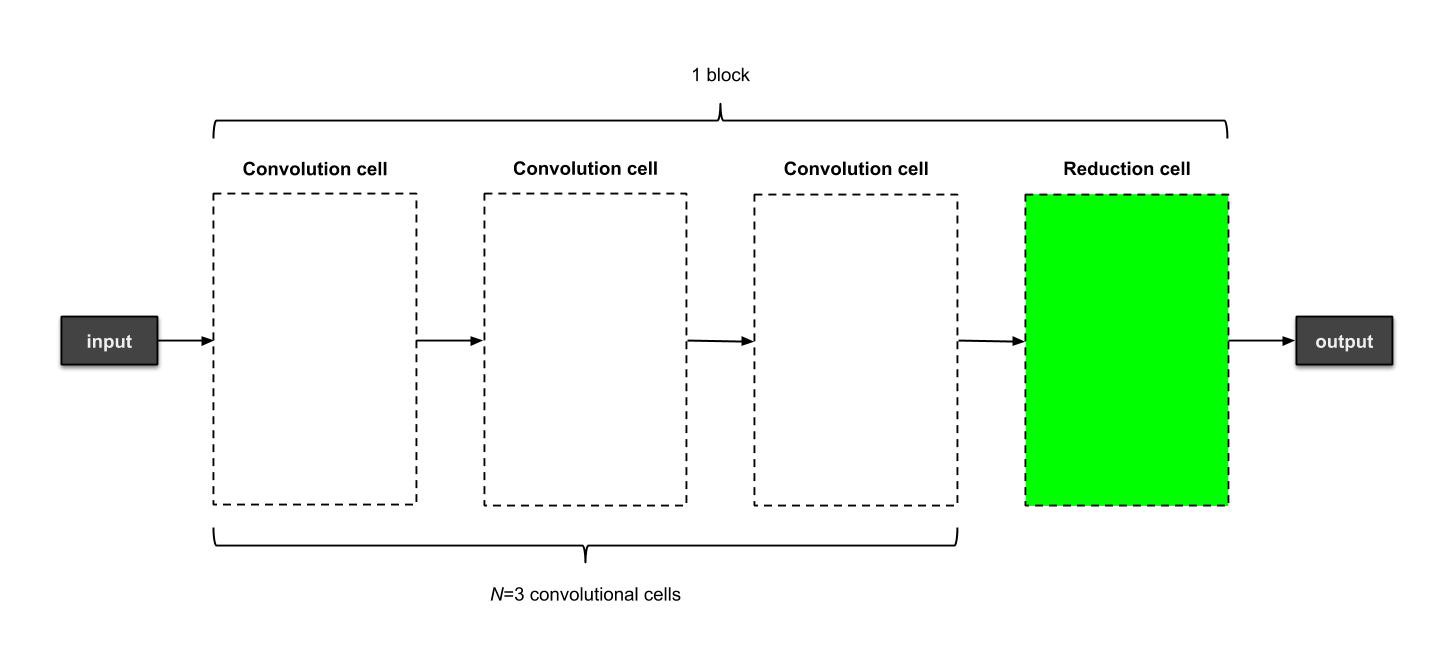
一个从微搜索中生成的子模型,包含一个组件,每个组件包含3个卷积单元和一个下采样单元,每个单元中的操作在这里并没有列出来。
1.2.3 快速前传
下面将介绍我们如何构建以下两个卷积单元。需要注意的是,每个单元最后都是操作。
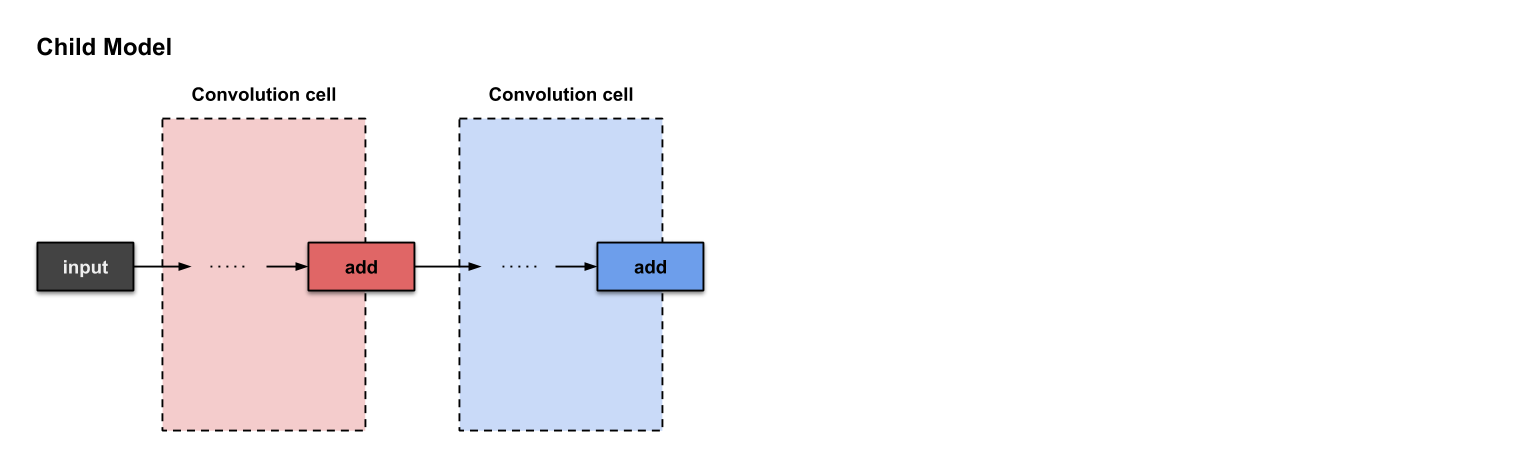
在微搜索中已经构建好的两个卷积单元
在已经构建好的两个卷积单元的基础上,我们开始构建第三个。
1.2.4 卷积单元#3
现在,让我们一起准备下第三个卷积单元。

在微搜索中准备第三个卷积单元
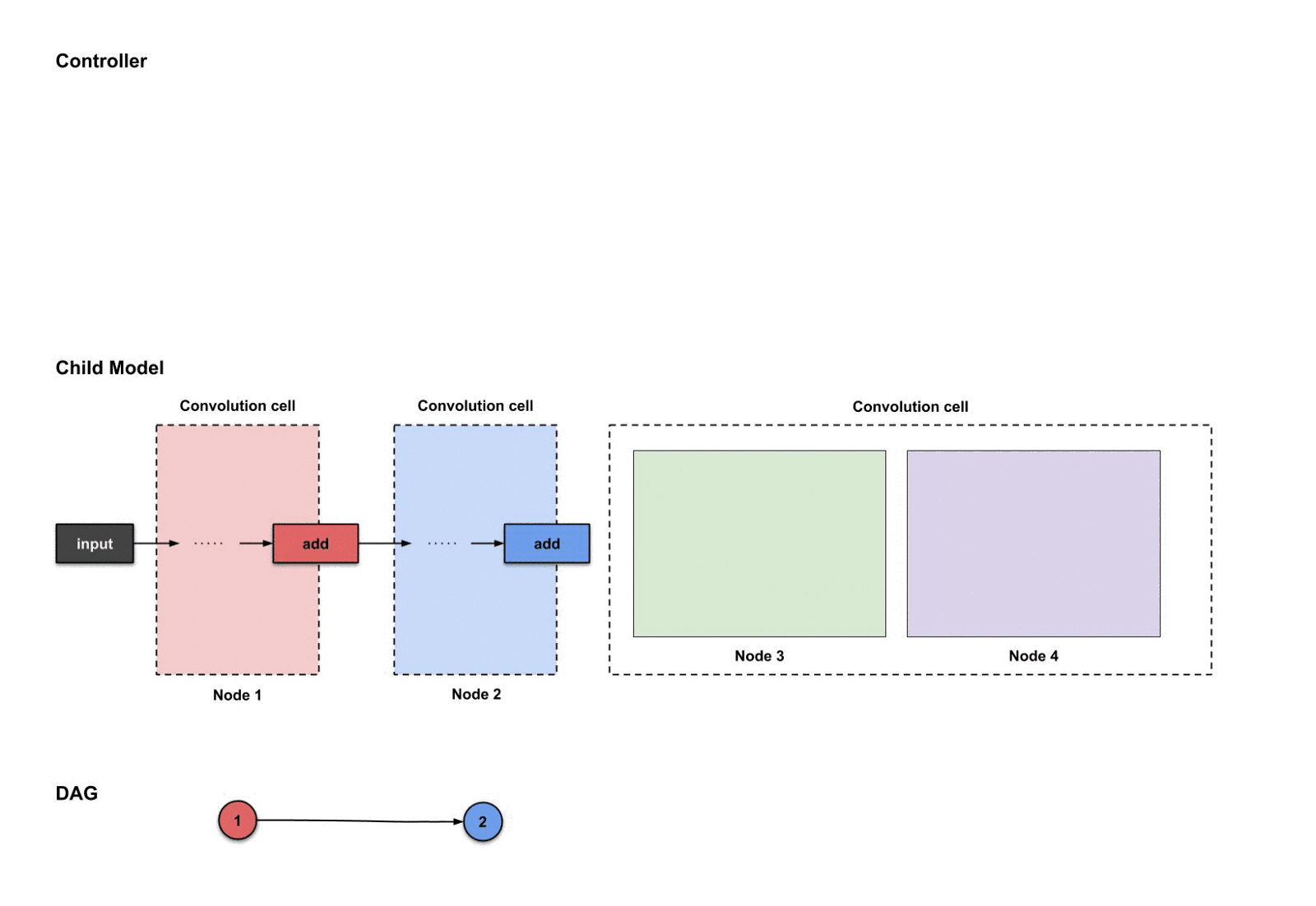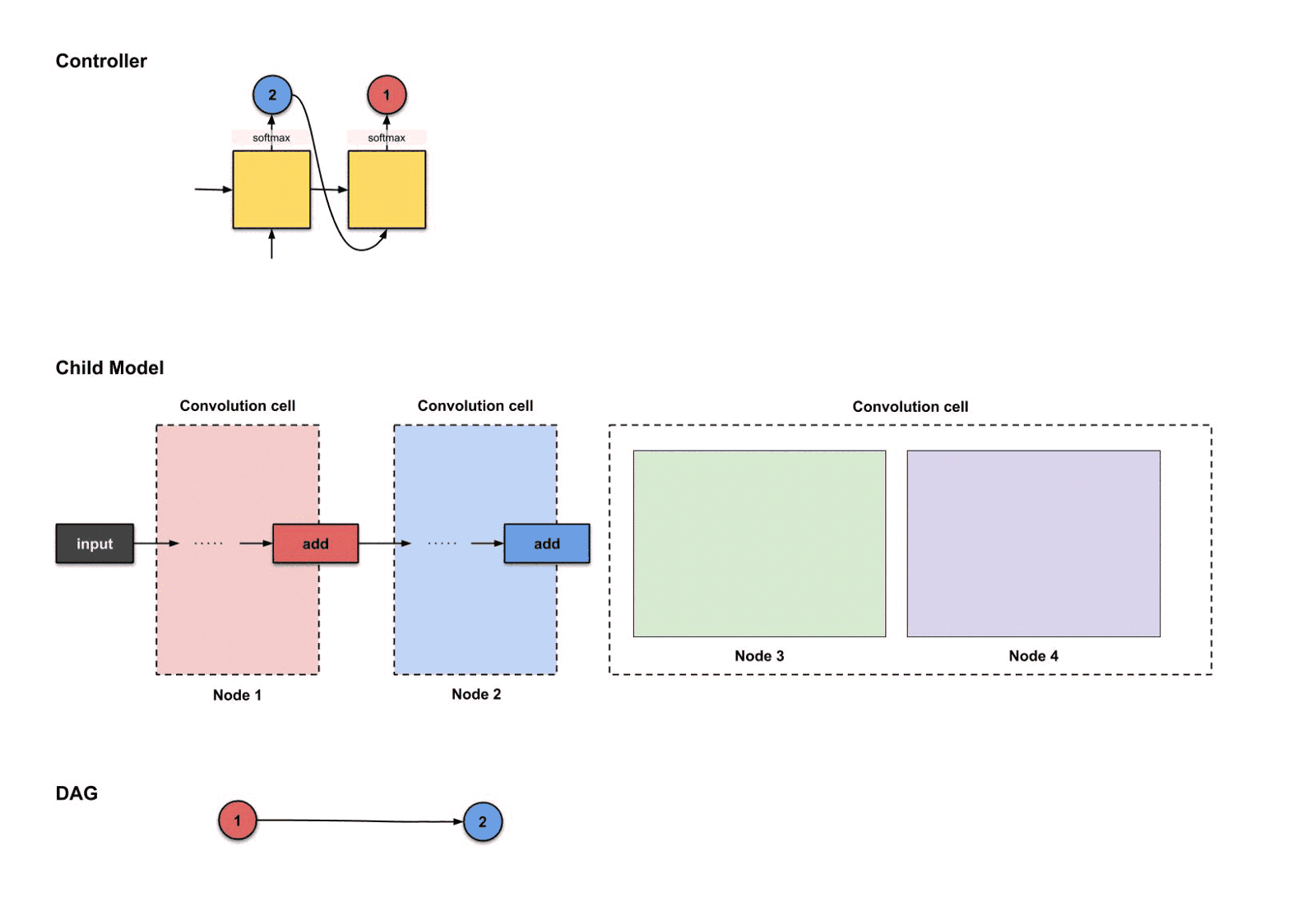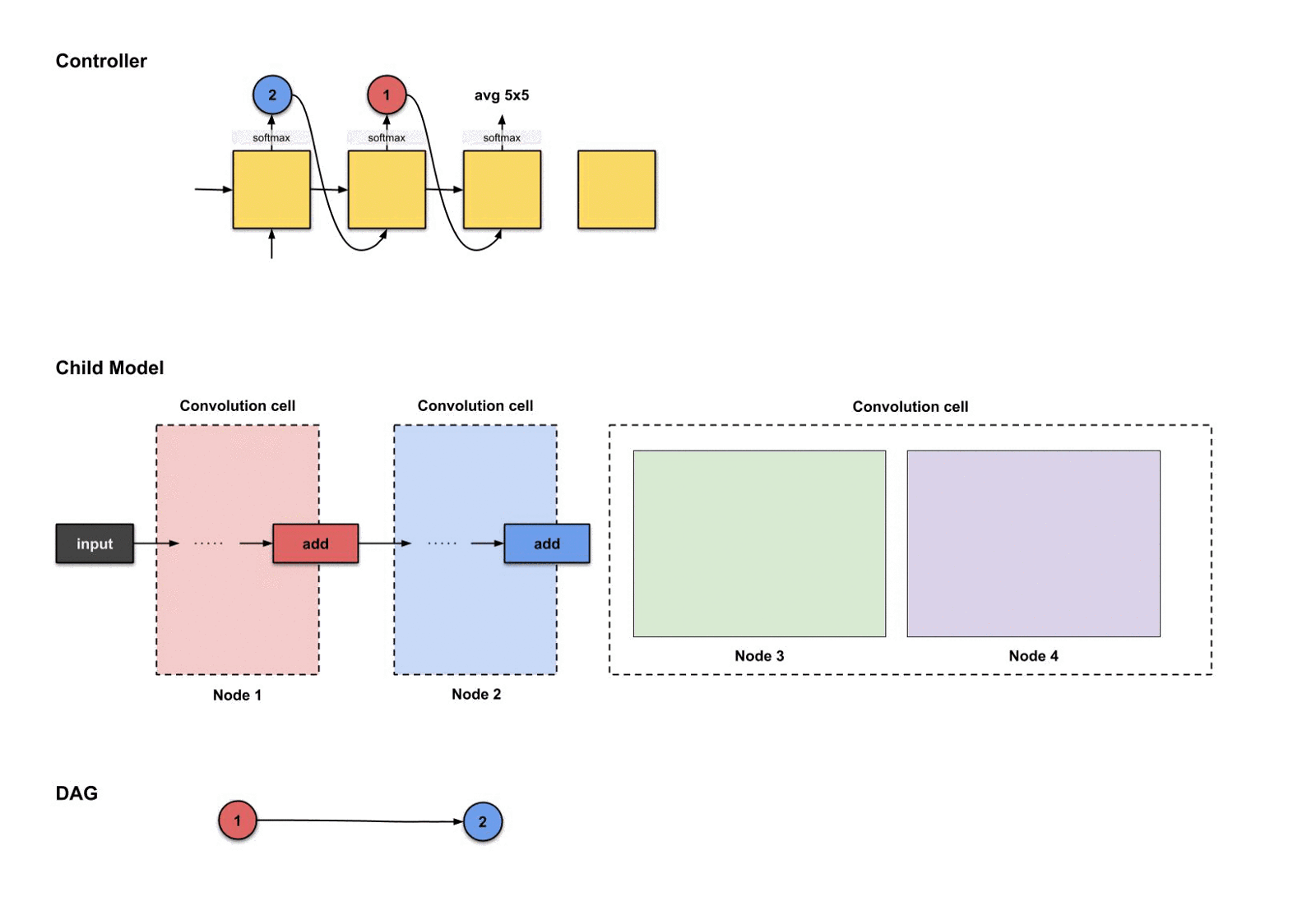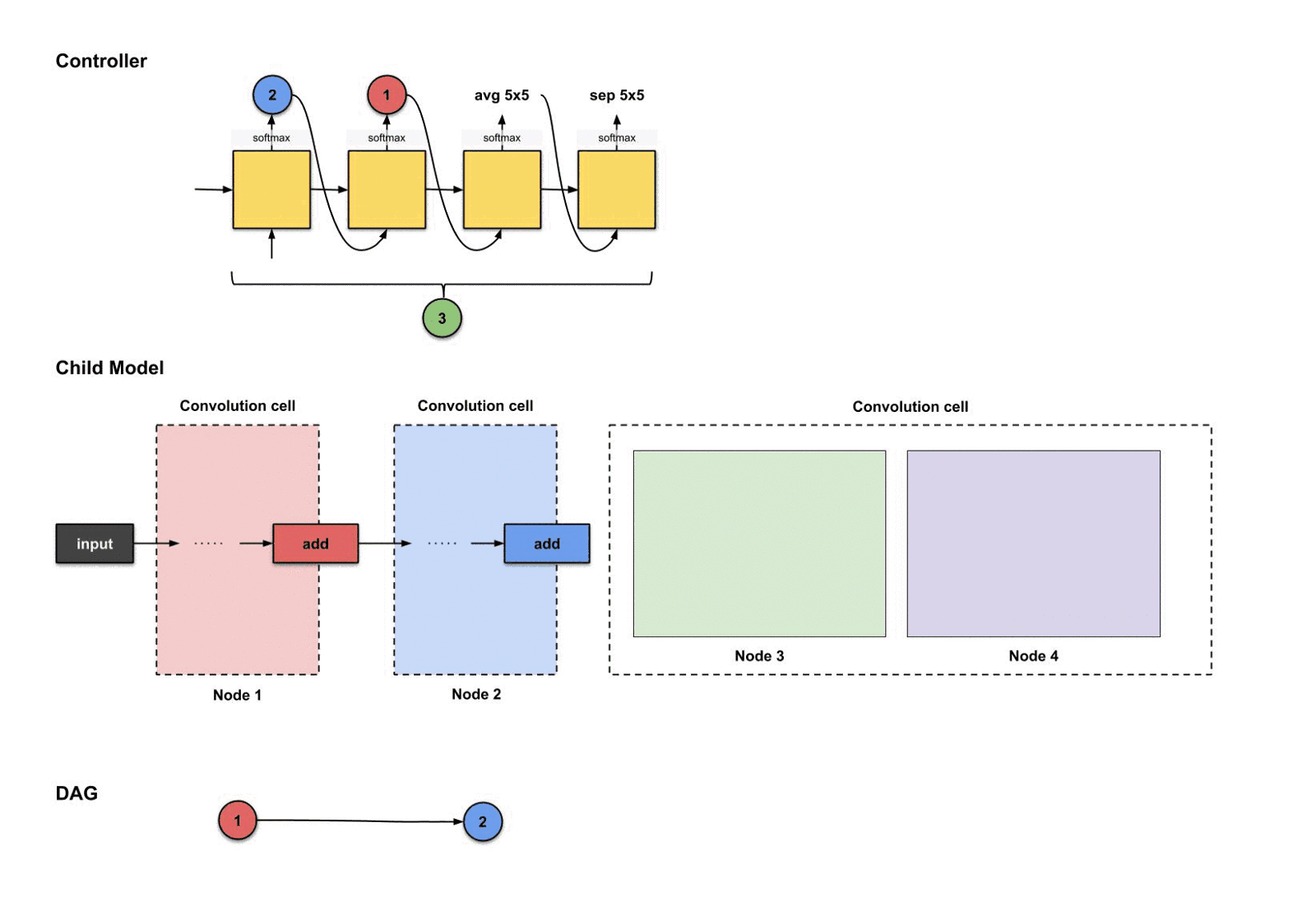
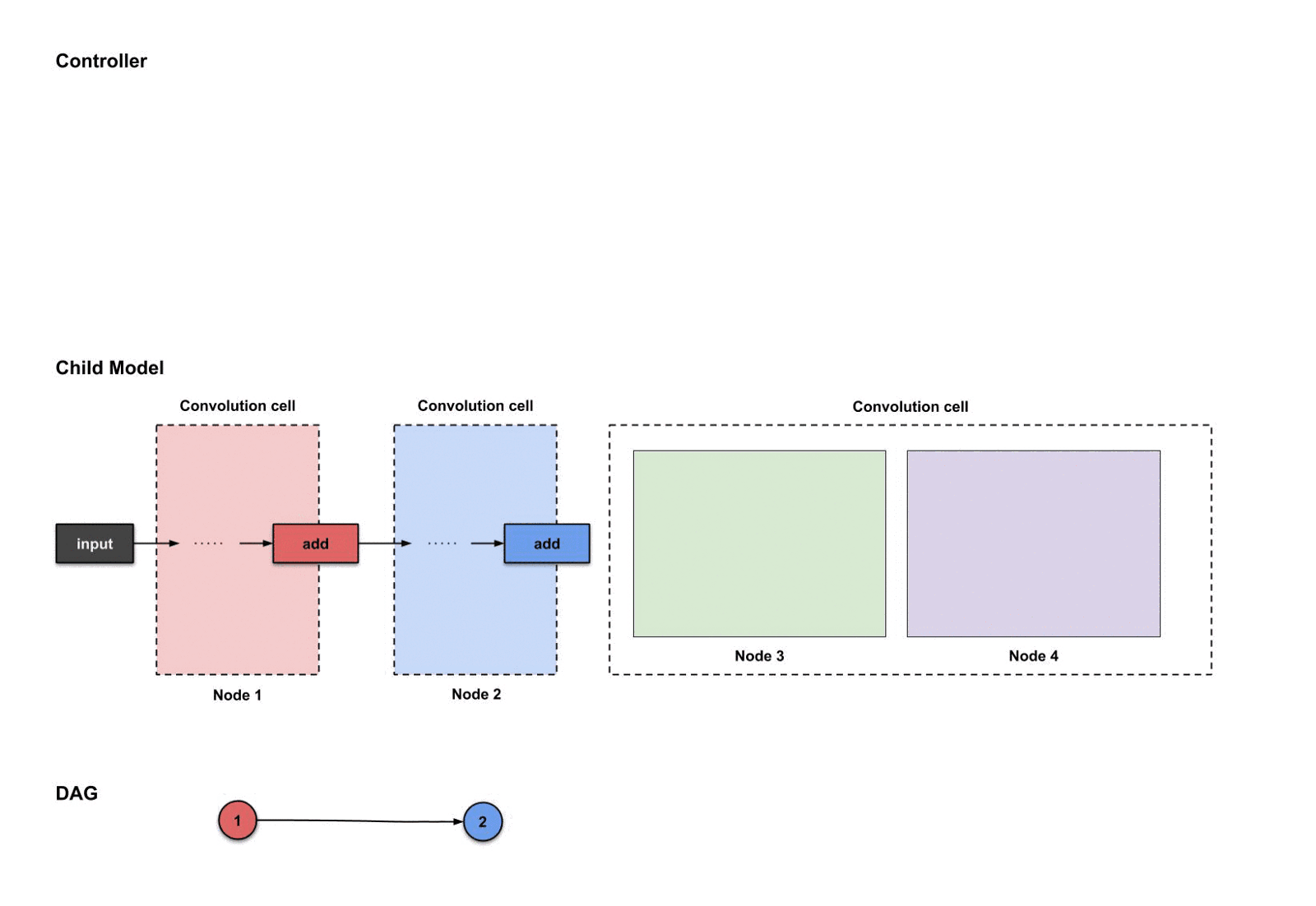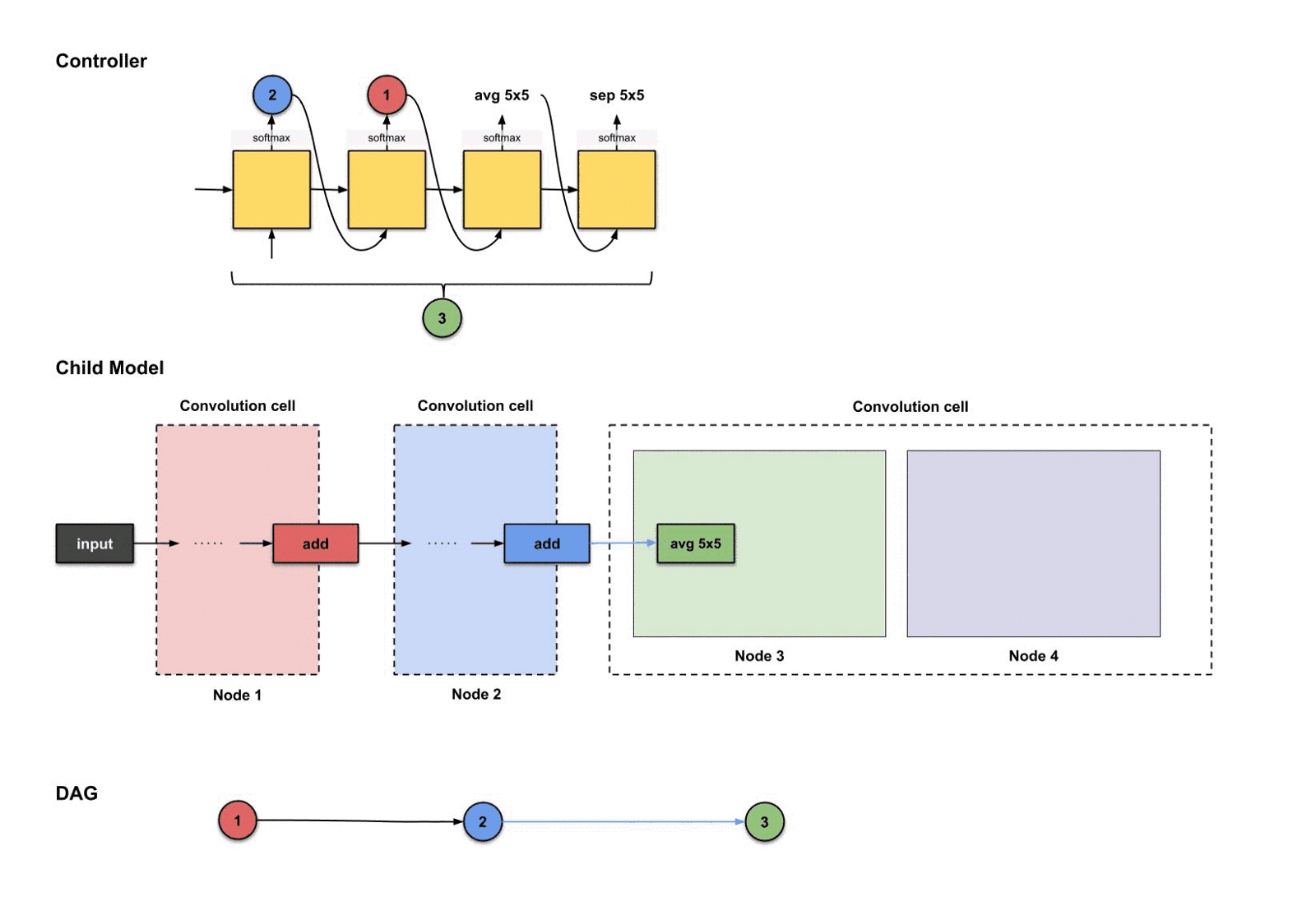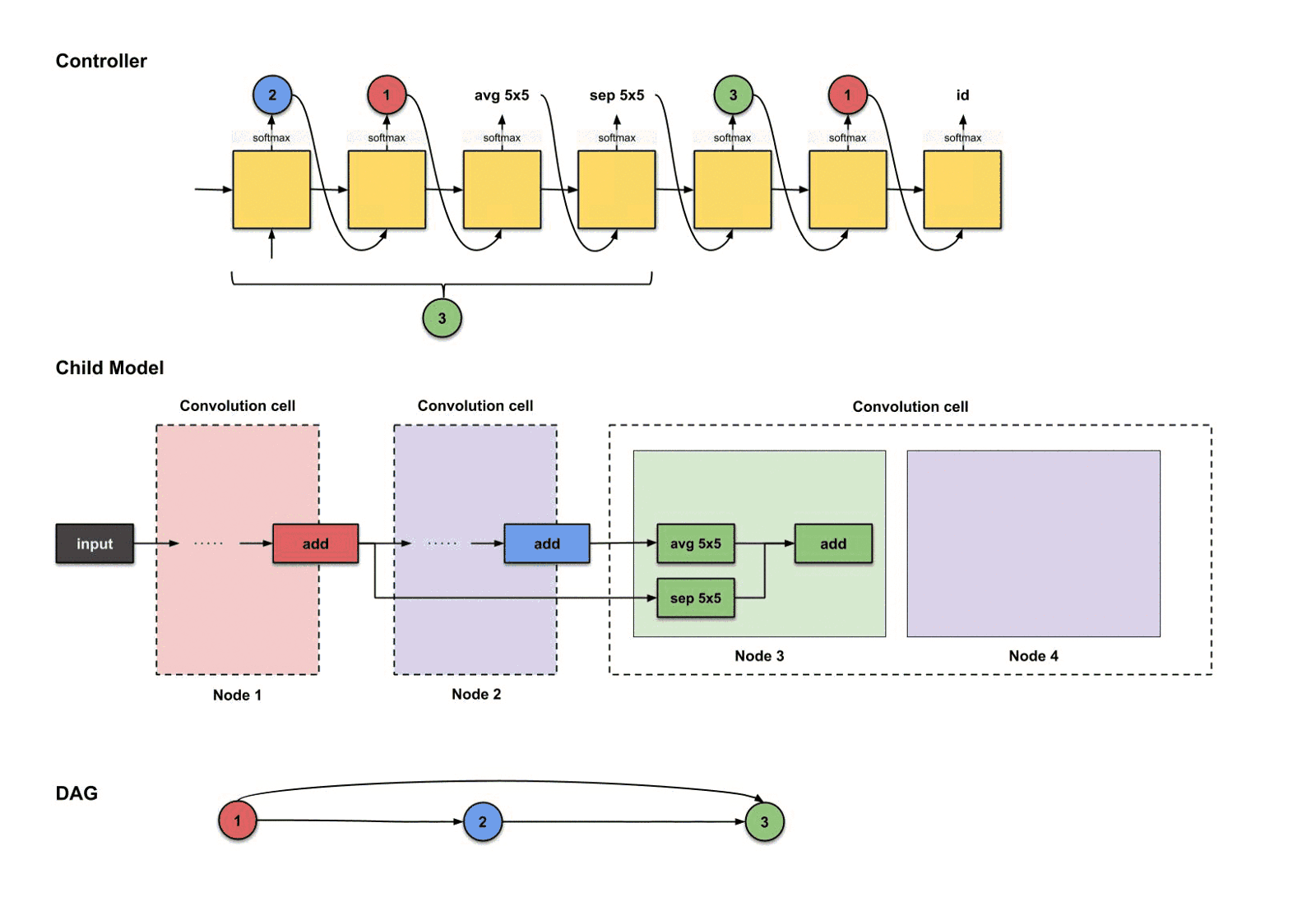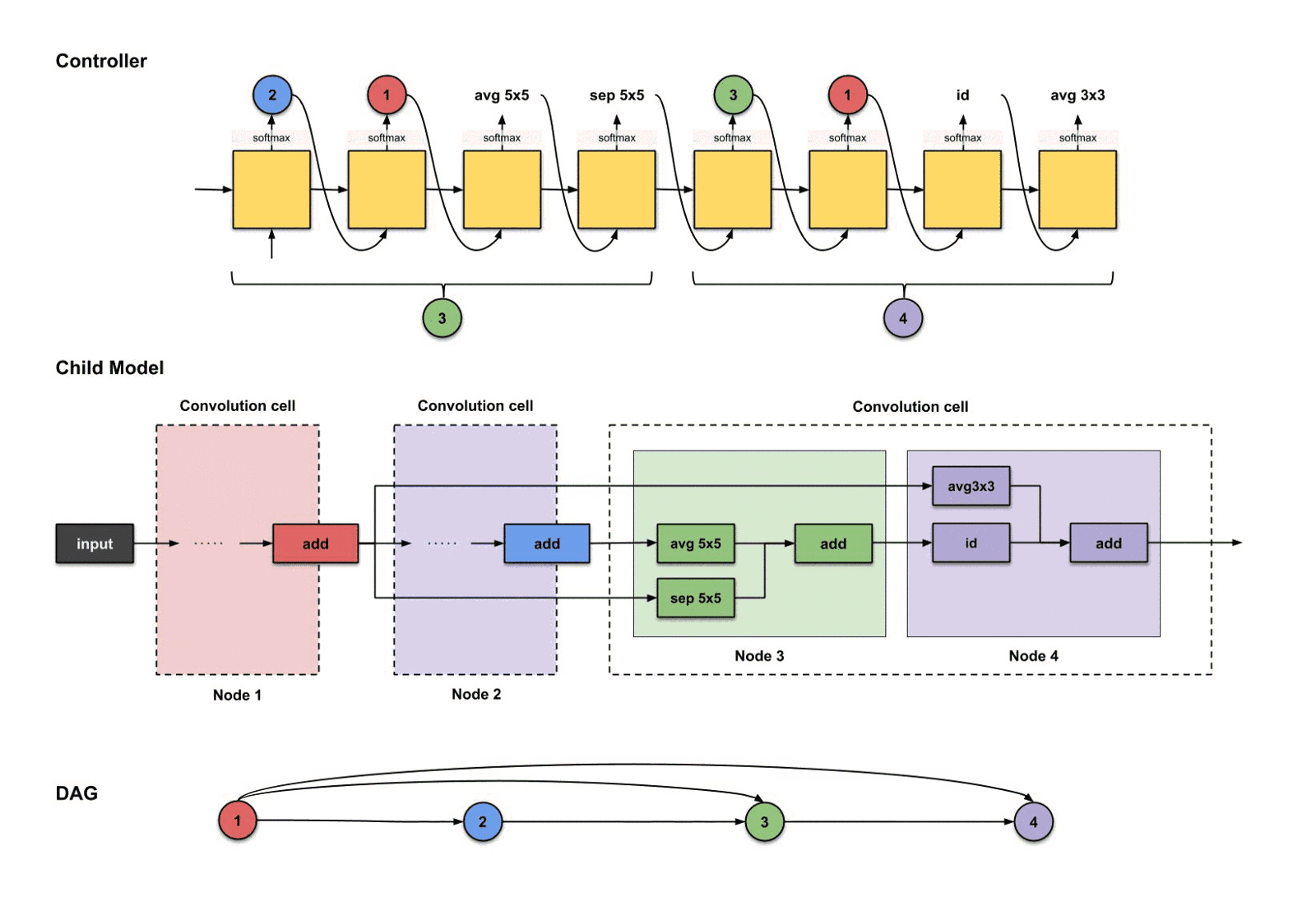
每个卷积单元假设有四个节点。前两个节点——其实就是当前单元之前的两个单元。剩下的两个节点则是由我们现在开始构建的。以下是标注出来的节点:
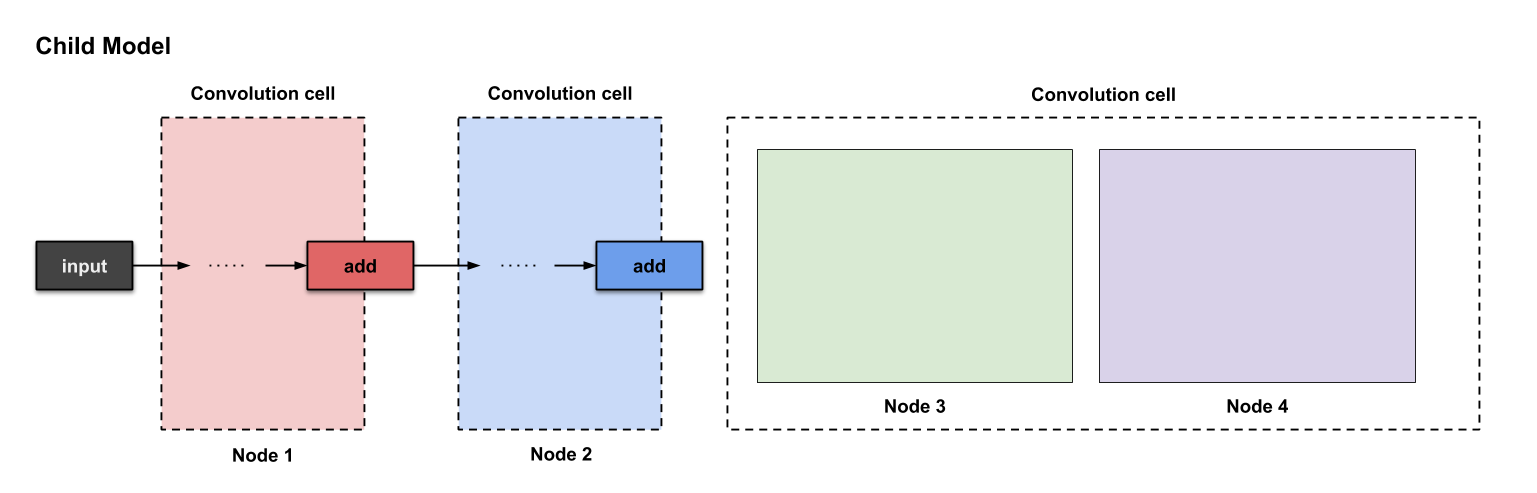
构建卷积单元#3时对应的四个节点
从这部分开始,你可以忘记“卷积单元”这个标签,而只需要关注“节点”标签。如果你想知道这些节点是否会在构建每个卷积单元时变化,答案是,是的。每个单元都会在这个行为中分配节点。
你也可能想知道,既然我们已经在节点1和节点2(也就是单元1和单元2)里面构建了操作,那么在这些节点里还需要构建什么东西呢?问得好!
1.2.5 卷积单元#3:节点1(红色)与节点2(蓝色)
对于每个我们构建的单元来说,头两个节点不是一定要构建的,但应该成为其他节点的输入。在我们的例子中,既然我们构建了四个节点,那么节点1和节点2就成为了节点3和节点4的输入。所以我们不需要对节点1和节点2做任何事情,只需要继续构建节点3和节点4就可以了。
1.2.6 卷积单元#3:节点3(绿色)
我们构建单元就从节点3开始。和宏搜索里控制器需要挑选两个决策不同的是,微搜索里控制器需要挑选四个决策(或者说两组决策)。
- 需要连接的两个节点
- 对需要连接的两个节点各自的两个操作
根据这四个决策,控制器将执行四次。以下是执行过程:
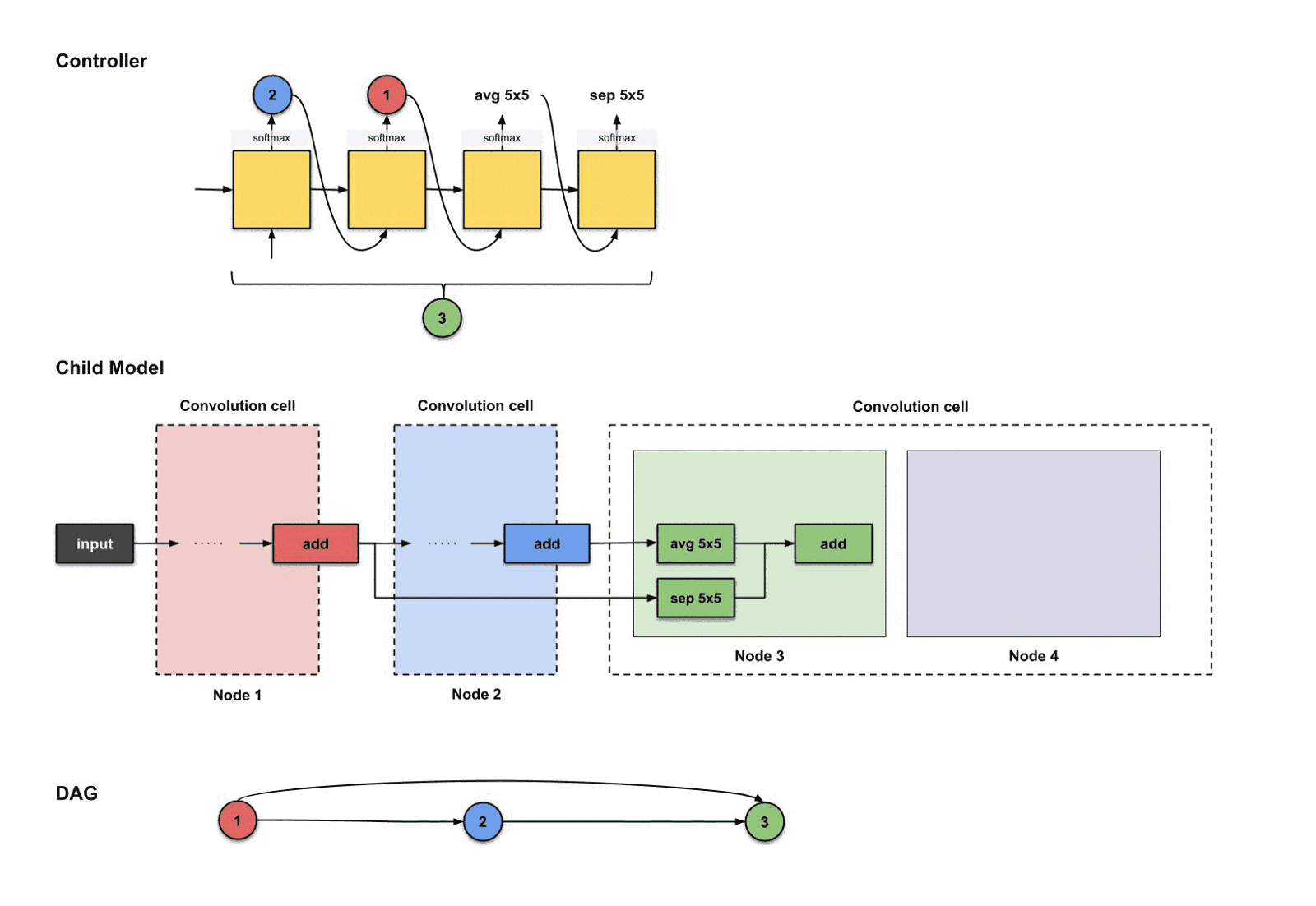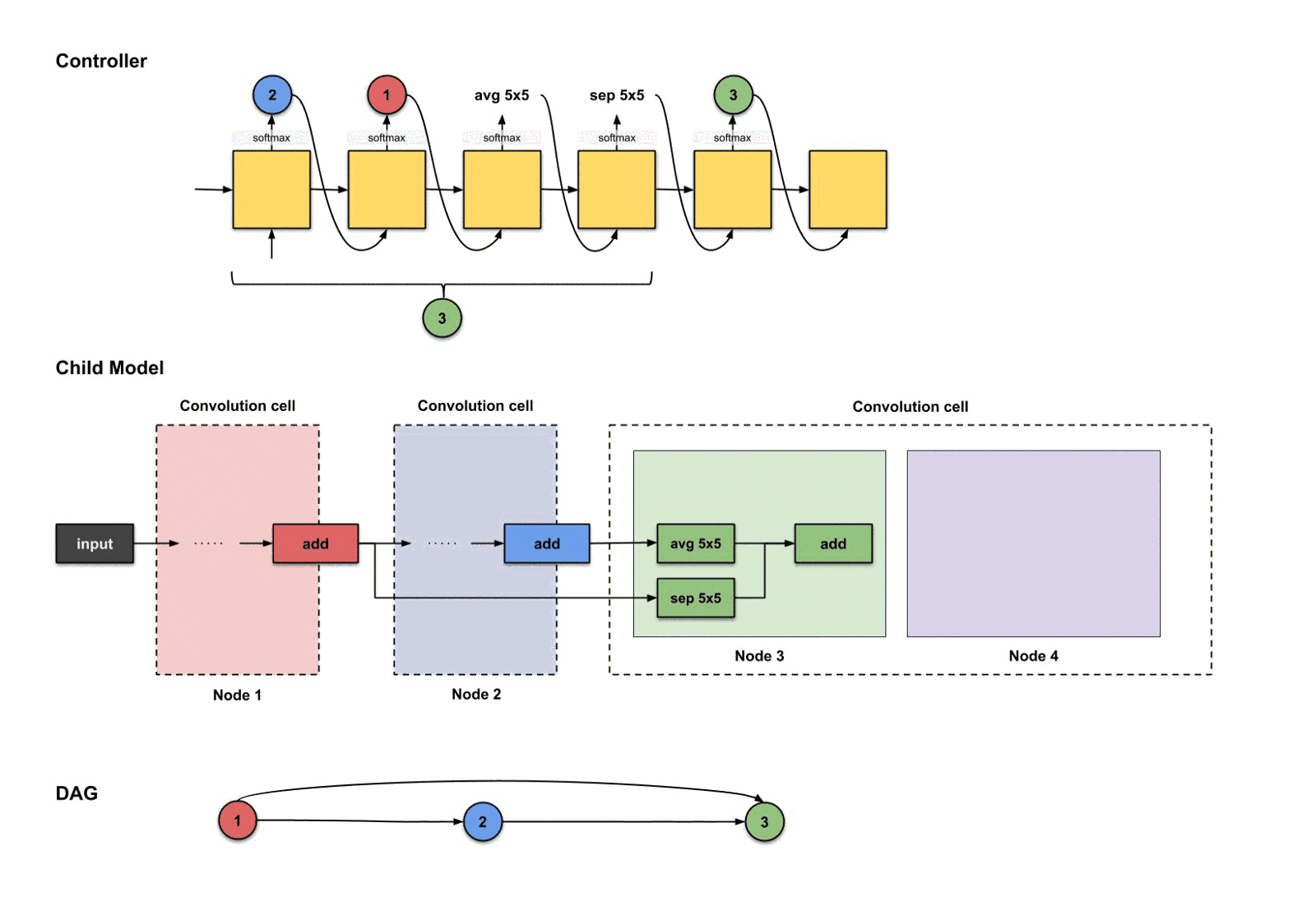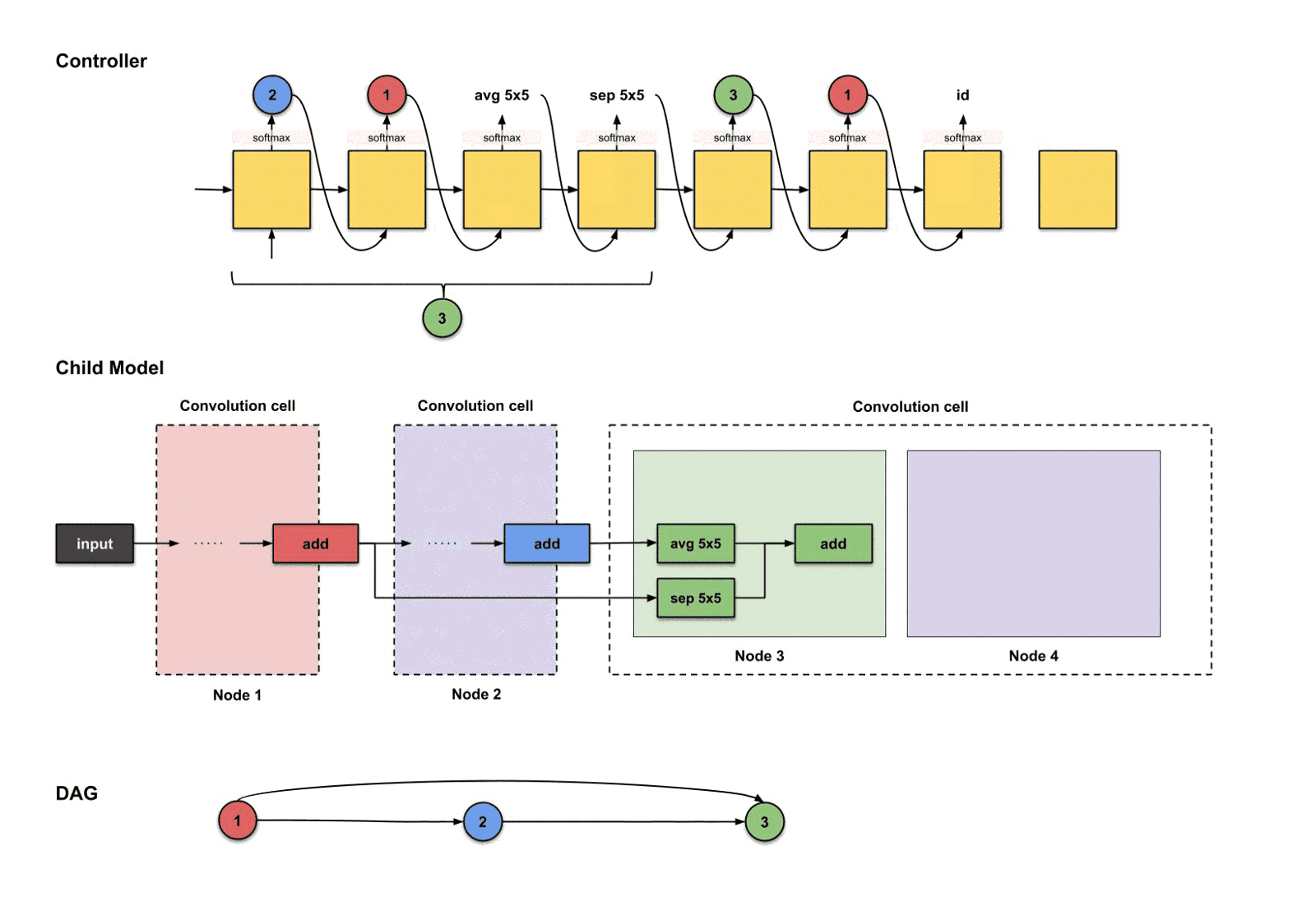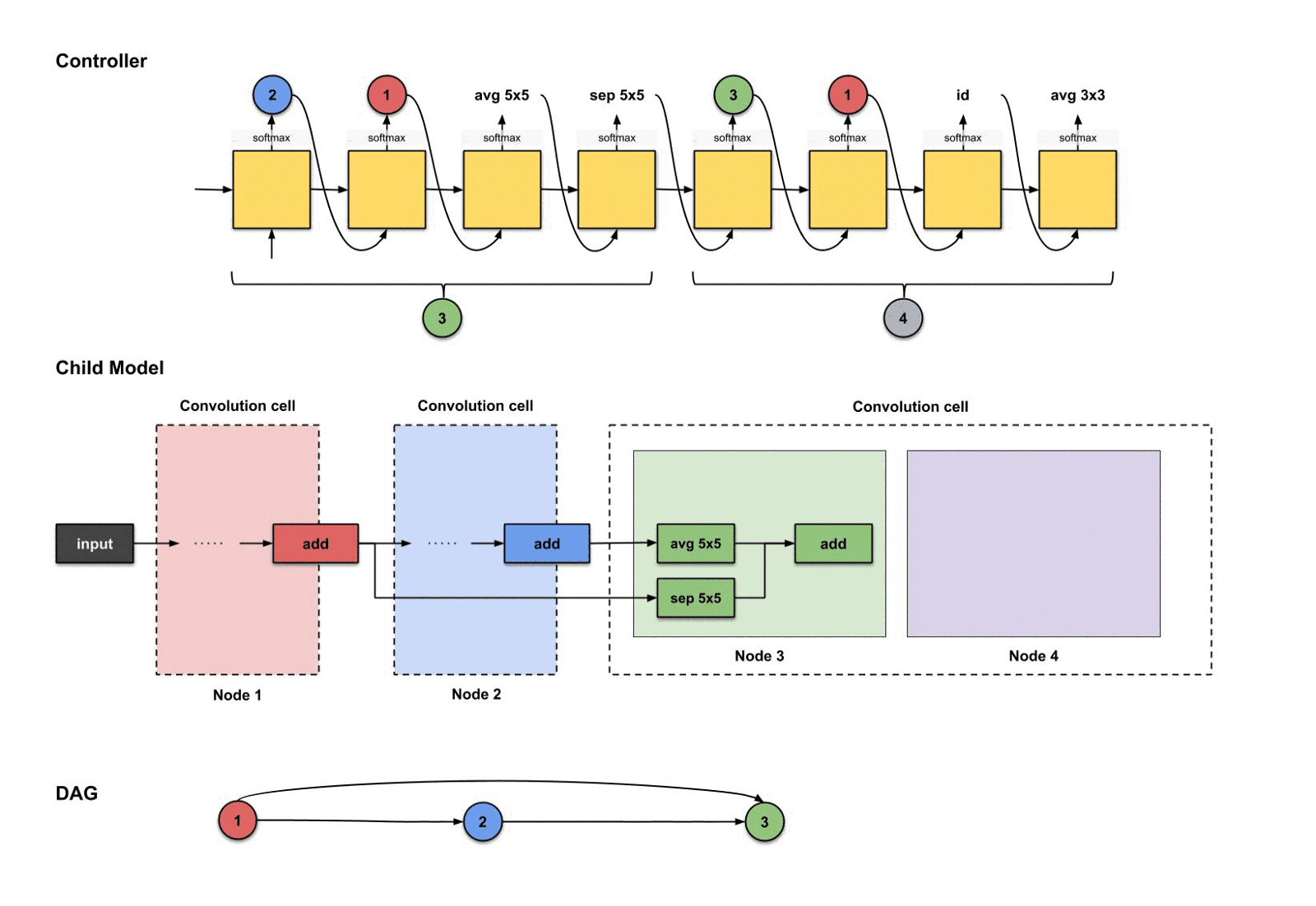
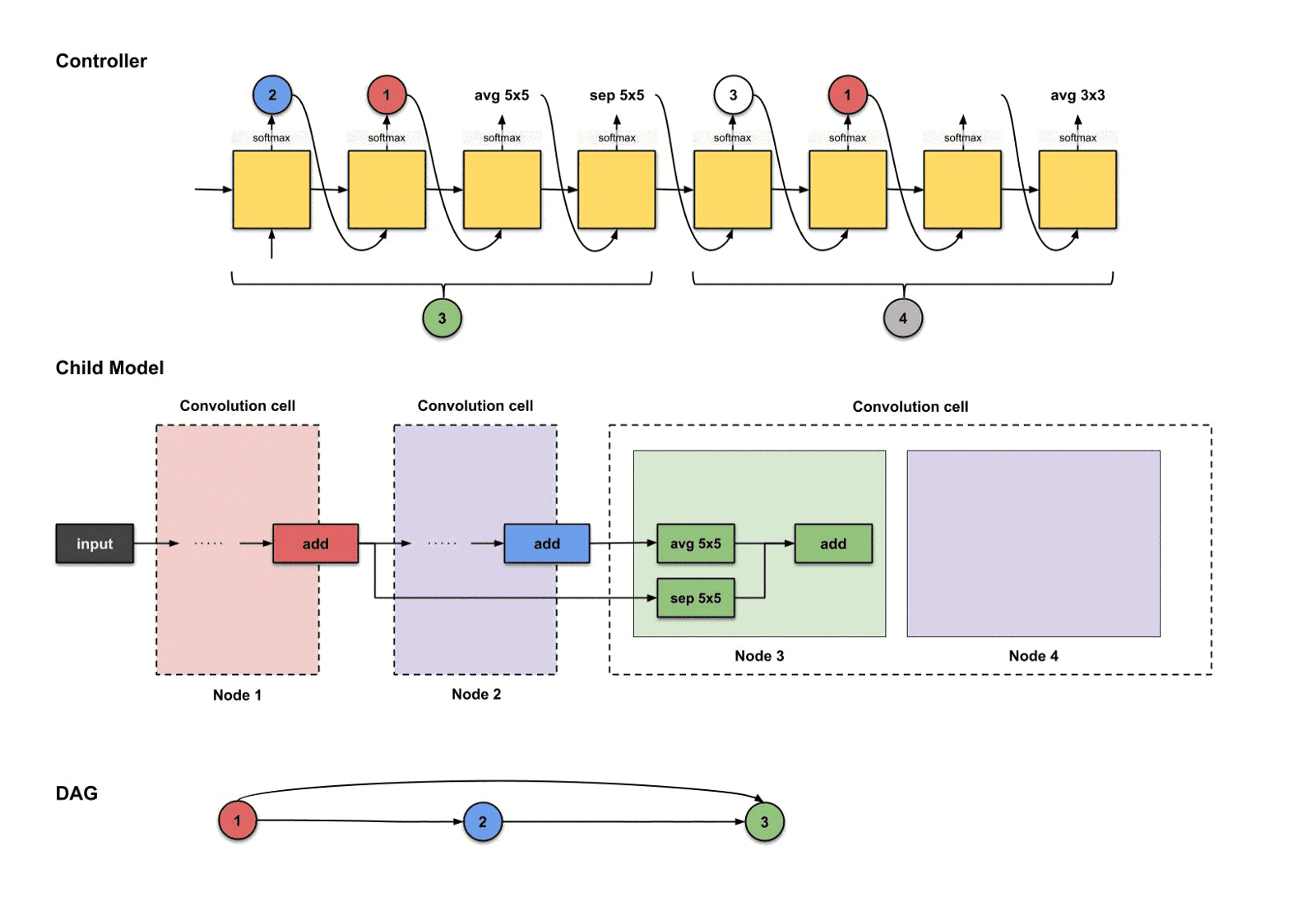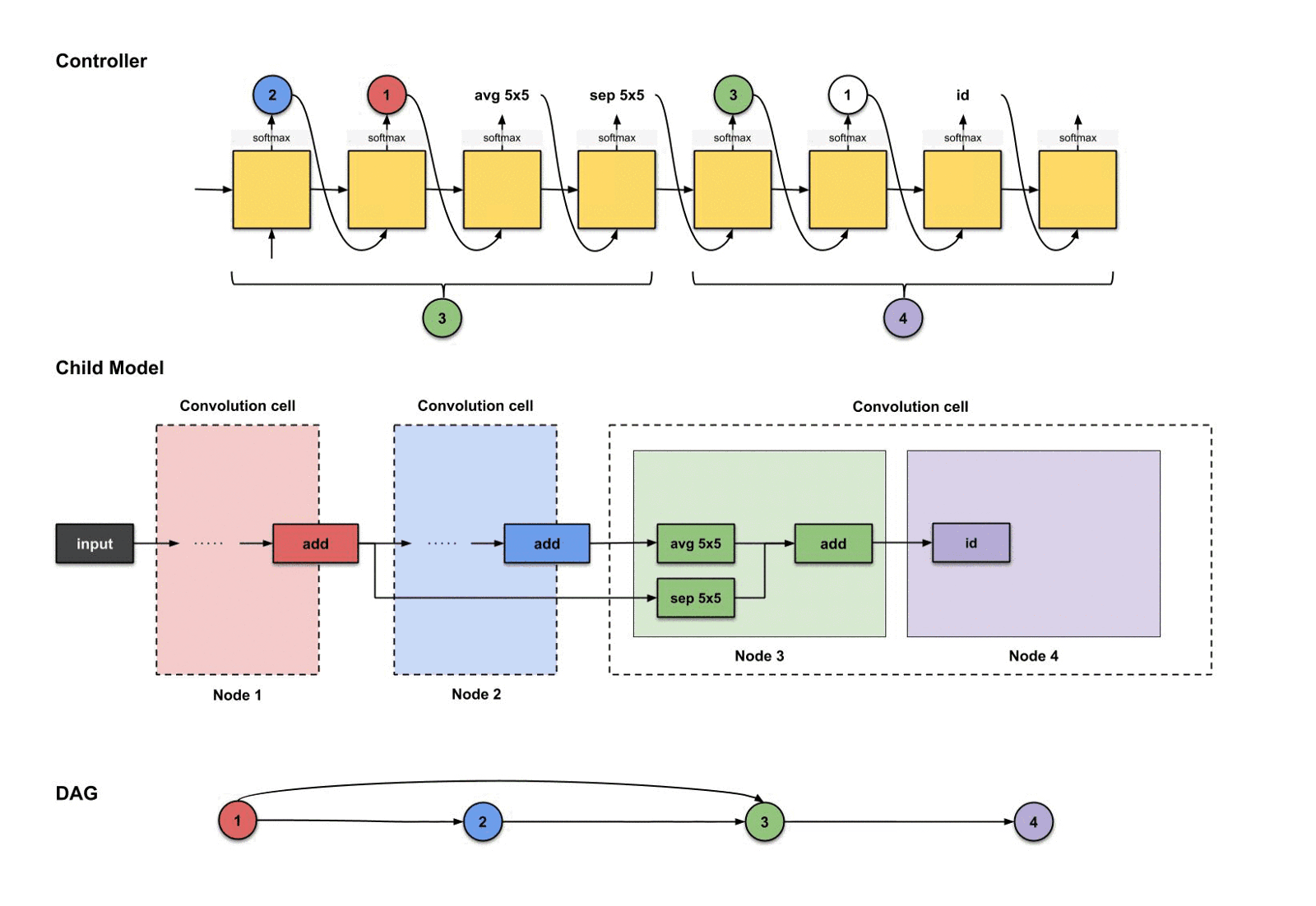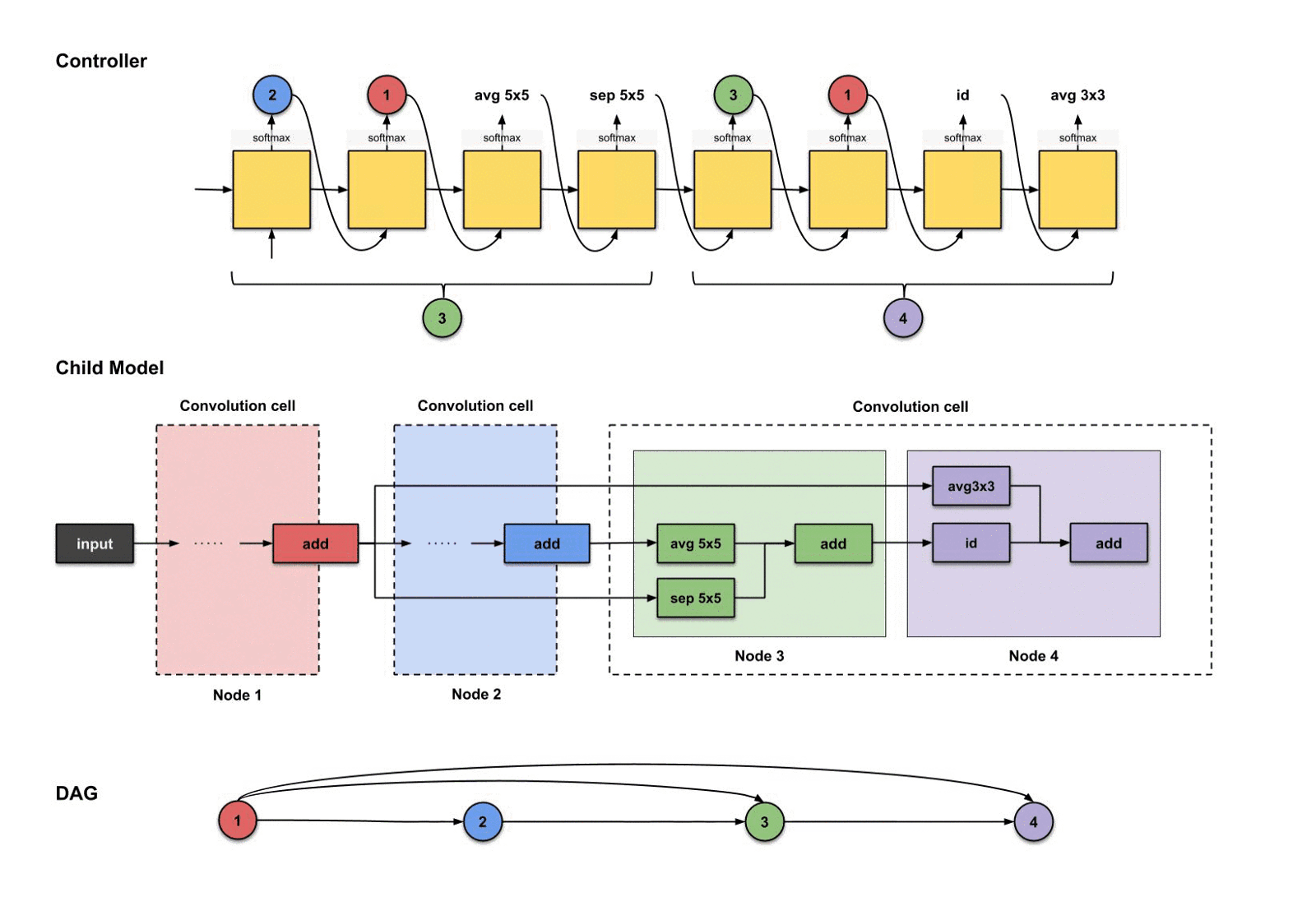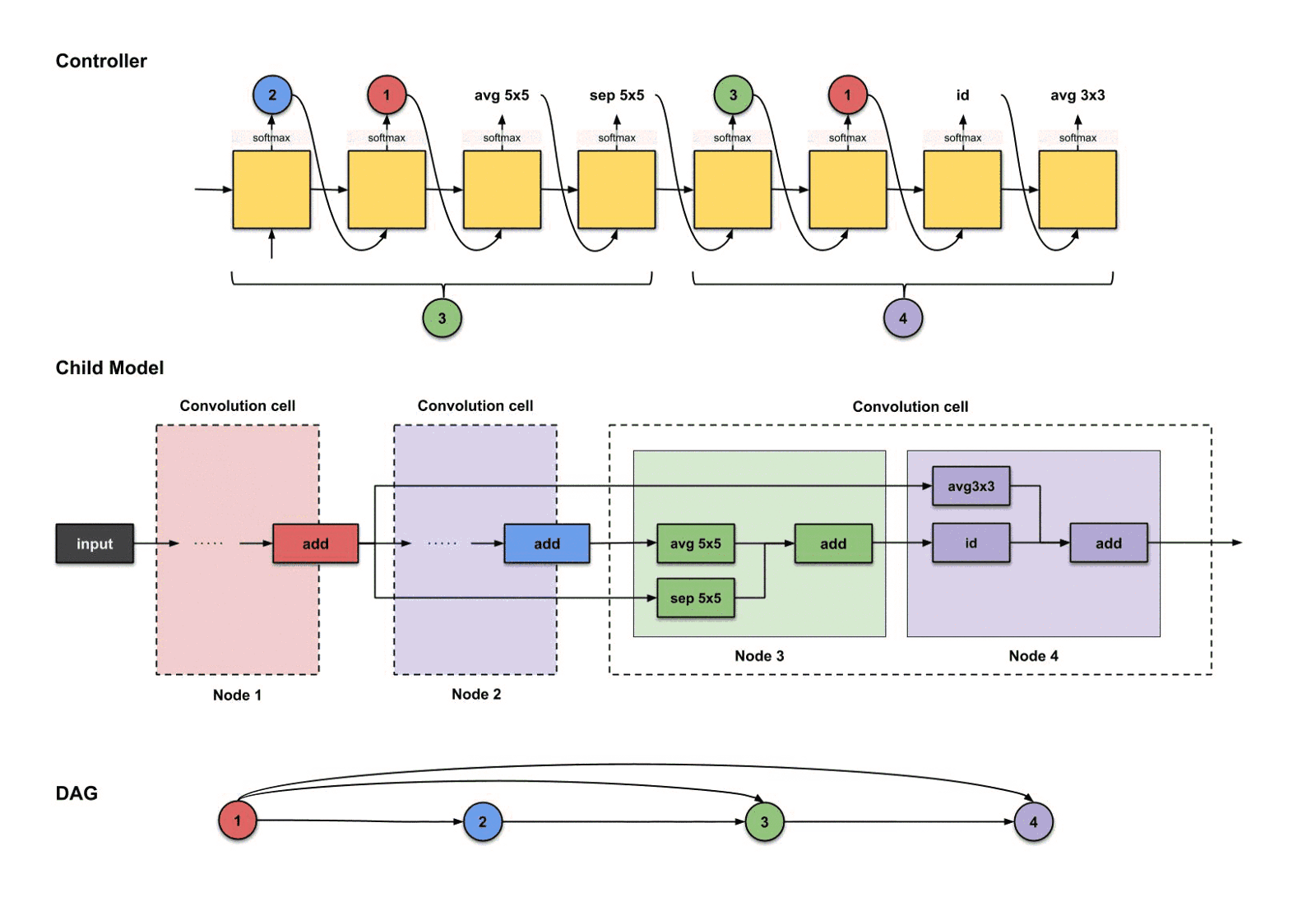
控制器前四步的输出分别是(),用来构建节点3
从上面的图我们可以看到控制器从前四步执行中挑选了。那么这些决策如何翻译成子模型的结构呢?如下:

控制器前四部执行结果是如何翻译过来构建节点3
从上面的图可以看出,发生了三件事情:
- 节点2(蓝色)的输出执行了操作。
- 节点1(红色)的输出执行了操作。
- 上面两个操作的结果一起执行了操作。
1.2.7 卷积单元#3:节点4(紫色)
对于节点四,我们重复同样的步骤。现在控制器由三个节点(节点1,2和3)可以挑选了.下面控制器生成了。
控制器前四步的输出分别是(),用来构建节点4
翻译并构建的过程如下:
控制器前四部执行结果是如何翻译过来构建节点4
从上面的图可以看出,发生了三件事情:
- 节点3(绿色)的输出执行了操作。
- 节点1(红色)的输出执行了操作。
- 上面两个操作的结果一起执行了操作。
这样我们就完成了卷积单元#3的构建过程了。
1.2.8 下采样单元
还记得每个卷积单元,我们都需要一个下采样单元吗?在这个教程里,,而我们刚刚构建了第三个卷积单元,所以是时候构建一个下采样单元了。正如前面所说,下采样单元的设计与卷积单元的设计非常类似,区别只是那些操作的步长为2而已。
1.2.9 结束语
这就是整个使用微搜索生成子模型的过程。希望对于你们(读者)来说内容不会太多,我(作者)第一次读这篇文章的时候就是这种感受。
2.注释
因为这篇文章主要介绍的是宏搜索和微搜索,所以我(作者)还有很多小细节(特别是迁移学习方面)的东西没有说。简单介绍一下:
- ENAS的高效在哪里?答:迁移学习。如果两个节点之间的计算过程之前已经完成(训练),那么卷积核的权重与卷积(用来保持输出通道数,前面并没有提到)就会被复用。这就是为什么ENAS比他的前辈们要更快。
- 当不需要跳跃连接时,控制器仍然可以挑选决策。
- 对于控制器来说,有六种可用的操作:卷积核大小为和的卷积与深度可分离卷积(depthwise-separable convolution),卷积核为的最大池化(max pooling)和平均池化(average pooling)。
- 了解每个单元末端的拼接(concatenate)操作,这是用来收紧(tie up)任意节点的松尾(loose end)。
- 简要了解一下策略梯度算法(REINFORCE)的强化学习。
3.总结
3.1宏搜索(对于整个网络)
最终的子模型如下所示:
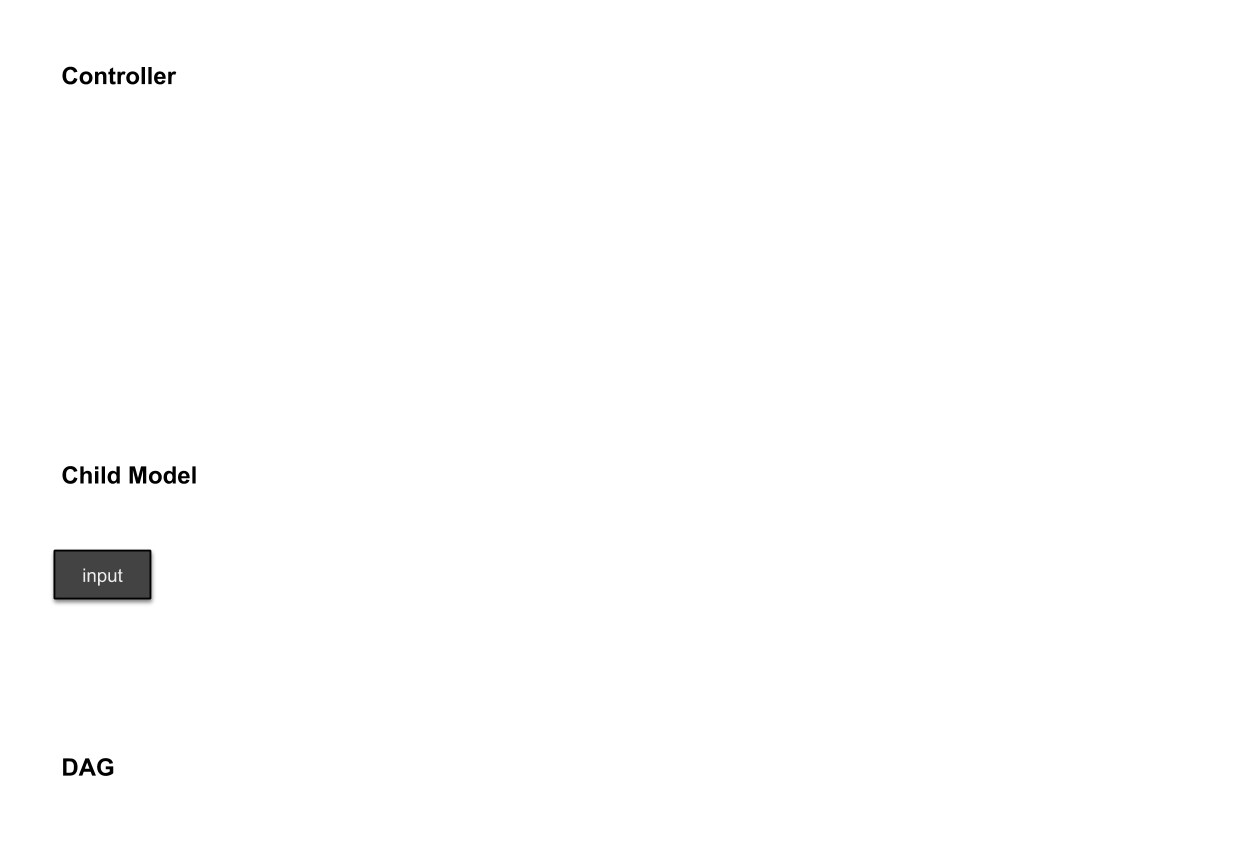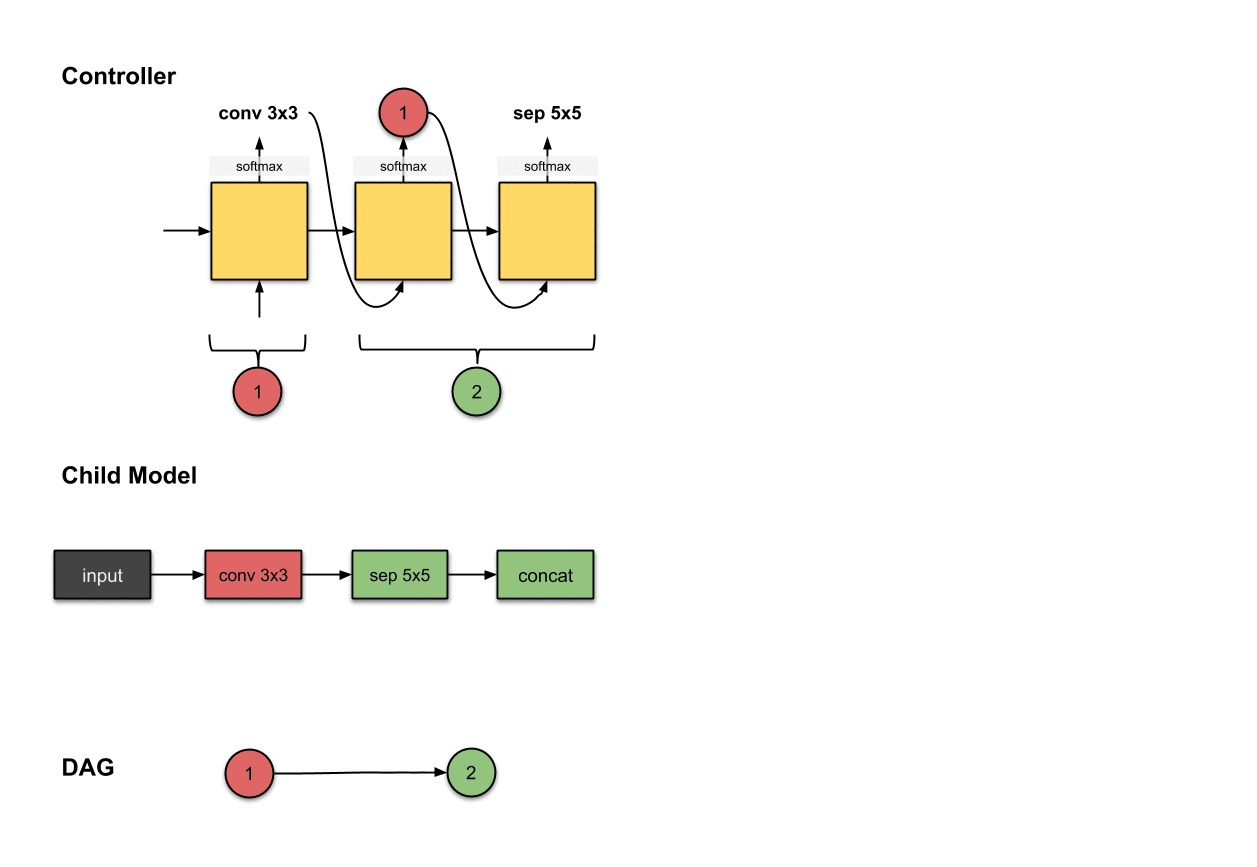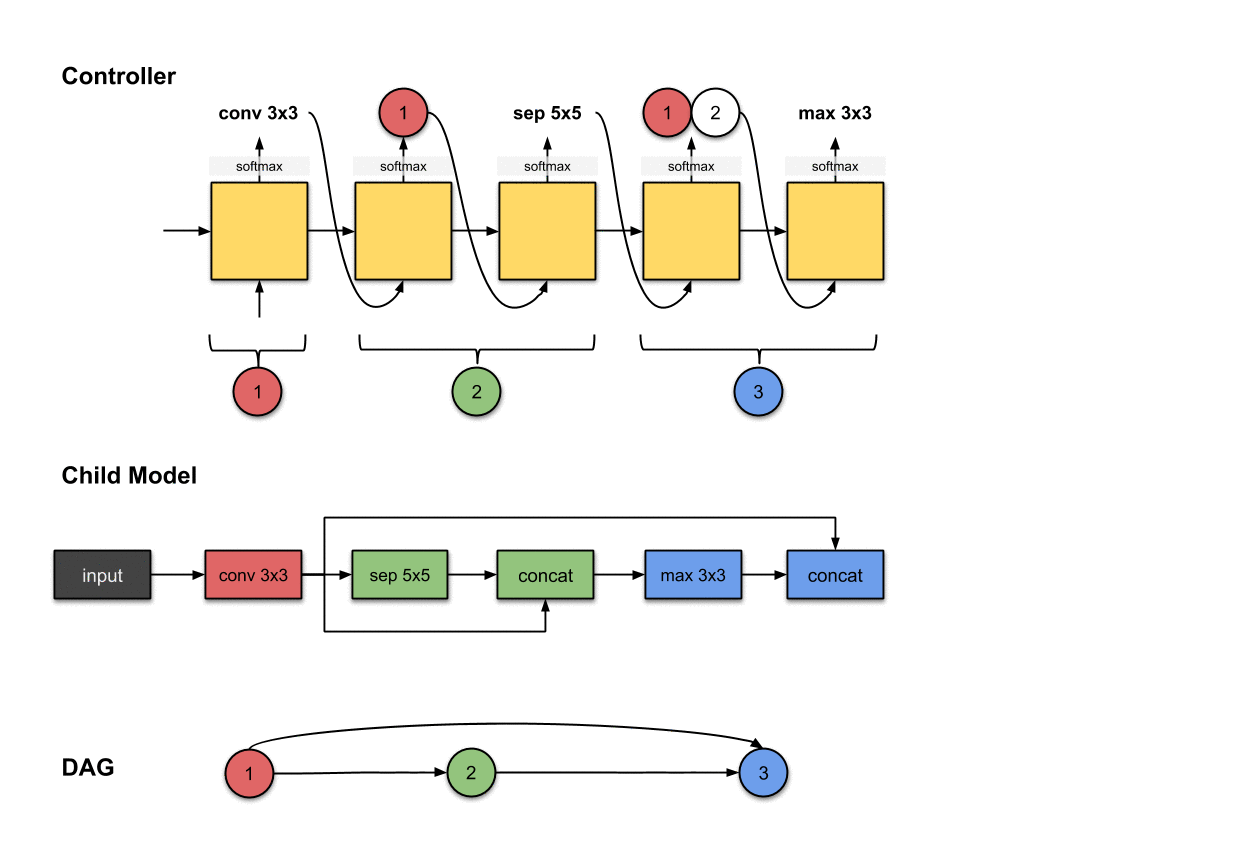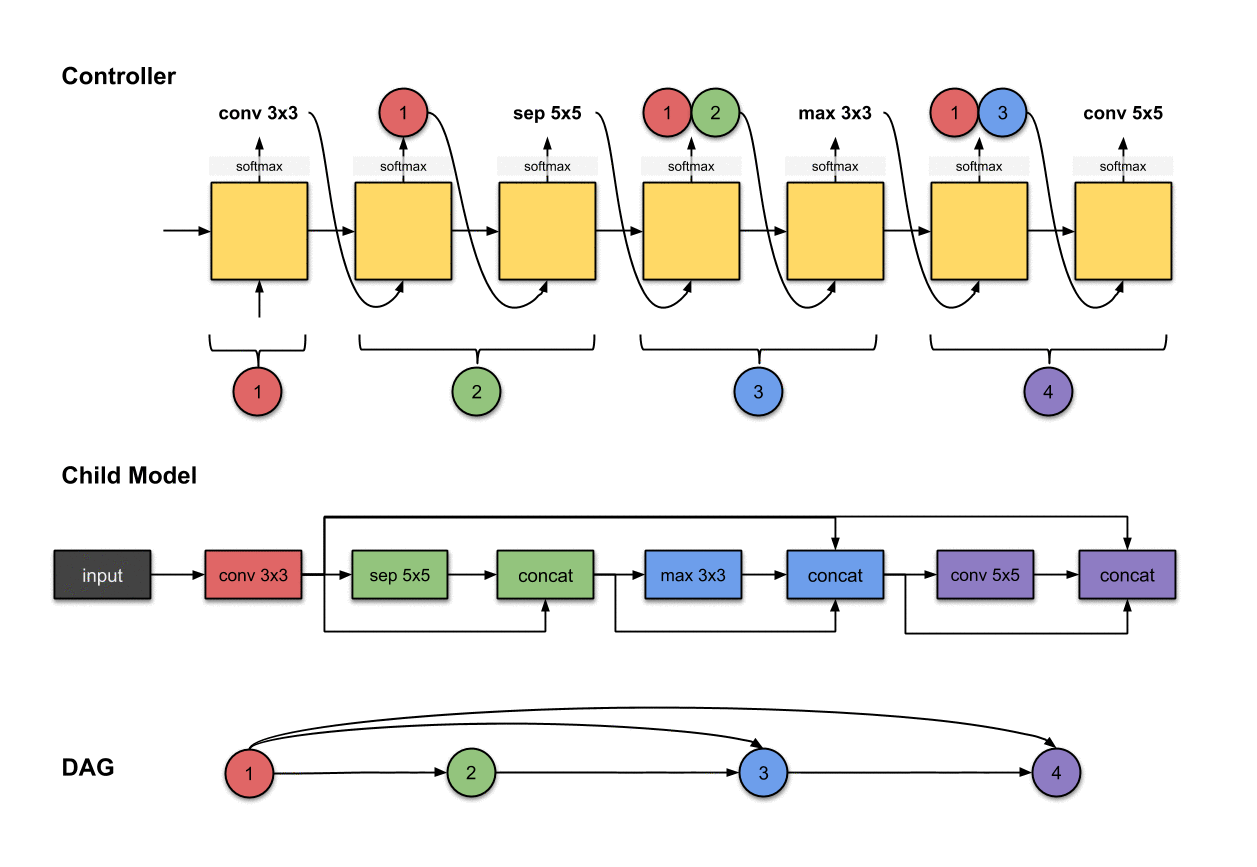
使用宏搜索生成一个卷积神经网络
3.2微搜索(对于一个卷积单元)
这里只展示最终子模型的一部分。
使用微搜索生成一个卷积神经网络。这里只展示整个结构的一部分。
4.相关实现
5.参考文献
[1]: Zoph B, Le Q V. Neural architecture search with reinforcement learning[J]. arXiv preprint arXiv:1611.01578, 2016.
[2]: Zoph B, Vasudevan V, Shlens J, et al. Learning transferable architectures for scalable image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8697-8710.
[3]: Pham H, Guan M Y, Zoph B, et al. Efficient neural architecture search via parameter sharing[J]. arXiv preprint arXiv:1802.03268, 2018.
[4]: Liu H, Simonyan K, Vinyals O, et al. Hierarchical representations for efficient architecture search[J]. arXiv preprint arXiv:1711.00436, 2017.
[5]: Real E, Aggarwal A, Huang Y, et al. Regularized evolution for image classifier architecture search[J]. arXiv preprint arXiv:1802.01548, 2018.
[6]: Liu C, Zoph B, Neumann M, et al. Progressive neural architecture search[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 19-34.
[7]: Jin H, Song Q, Hu X. Efficient neural architecture search with network morphism[J]. arXiv preprint arXiv:1806.10282, 2018.
[8]: Kandasamy K, Neiswanger W, Schneider J, et al. Neural architecture search with bayesian optimisation and optimal transport[C]//Advances in Neural Information Processing Systems. 2018: 2020-2029.
[9]: Xie S, Zheng H, Liu C, et al. SNAS: stochastic neural architecture search[J]. arXiv preprint arXiv:1812.09926, 2018.
[10]: Liu H, Simonyan K, Yang Y. Darts: Differentiable architecture search[J]. arXiv preprint arXiv:1806.09055, 2018.
[11]: Larsson G, Maire M, Shakhnarovich G. Fractalnet: Ultra-deep neural networks without residuals[J]. arXiv preprint arXiv:1605.07648, 2016.
[12]: Brock A, Lim T, Ritchie J M, et al. SMASH: one-shot model architecture search through hypernetworks[J]. arXiv preprint arXiv:1708.05344, 2017.
[13]: Liu C, Chen L C, Schroff F, et al. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation[J]. arXiv preprint arXiv:1901.02985, 2019.
[14]: Liu C, Zoph B, Neumann M, et al. Progressive neural architecture search[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 19-34.
