@Team
2019-11-11T04:58:03.000000Z
字数 3086
阅读 2960
《Computer vision》笔记-Res2Net(11)
石文华
https://arxiv.org/pdf/1904.01169.pdf
一、概述
多尺度特征表示对于许多视觉任务至关重要,backbone CNN的最新进展不断显示出更强的多尺度表示能力,从而在广泛的应用中获得一致的性能增益,然而,现有的方法大多是以分层的方式来表示多尺度特征的。论文提出的新的cnn构造块res2net,通过在一个residual块内构造分层的类residual连接来实现,res2net在粒度级别上表示多尺度特征,并增加每个网络层的感受野。它可以插入到很多SOTA的backbone CNN模型中,比如:ResNet,ResNeXt和DLA,将这些SOTA模型作为基准模型,构造对应的res2net模型,发现性能优于作为基准的SOTA模型。同时对具有代表性的计算机视觉任务,如目标检测、类激活映射和显著目标检测的进一步消融研究和实验结果验证了res2net相对于最新基线方法的优越性。
二、介绍
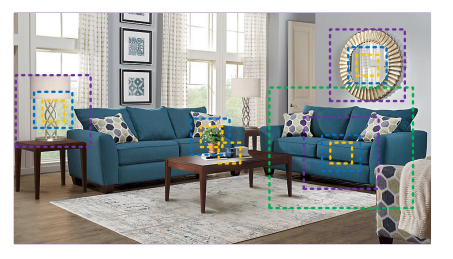
视觉图案在自然场景中通常是以多尺度形式出现,如上图所示。首先,同样的物体可能以不同的尺寸出现在图片中,例如,不同位置的沙发以及杯子的尺寸都是不同的。第二,待检测对象的上下文信息可能比它本身占的区域更多。例如,我们需要依赖于大桌子作为上下文来更好地判断放在它上面的小黑点是杯子还是笔筒。第三,从不同尺度的感知信息来理解如细粒度分类和语义分割的任务是非常重要的。因此,设计用于视觉任务的多尺度表示的良好特征是至关重要的,这些任务包括:图像分类、目标检测、注意力预测、目标跟踪、动作识别、语义分割、显著目标检测、对象提议、骨架提取、立体匹配和边缘检测等。
多尺度特征已经被广泛应用于传统特征设计和深度学习中。在视觉任务中获得多尺度表示需要特征提取者使用大量不同范围的感受野来描述不同尺度下的对象的整体/局部/上下文等信息。卷积神经网络(CNNs)通过卷积算子的堆叠自然地学习到由粗到细的多尺度特征。CNNs这种固有的多尺度特征提取能力,为解决众多视觉任务提供了有效的表征,如何设计更高效的网络体系结构是进一步提高cnns性能的关键。
早期的架构如alexnet和vggnet通过不同的堆叠层表示多尺度特征。随后,通过使用具有不同卷积核大小的conv层(例如inceptions)、残差模块(例如resnet)、密集连接(例如densenet)和分层聚合(例如dla)等等来提高多尺度能力的表达。可以看出cnn结构的发展已经显示出一种更有效和高效的多尺度表示的趋势。
作者提出的多尺度方法是指在更精细的层次上有多个可用的感受野。为了实现这个目标,用一组更小的滤波器组替换n个通道中的3×3滤波器,每个滤波器组都有w个通道(在不丧失通用性的情况下,使用n=s×w,s表示分组数)如图2所示,将n个通道的特征图分为4组,这些较小的滤波器组以类似于分层的残差的样式连接,以增加输出特征可以表示的尺度的数量,具体地说,一组滤波器首先从一组输入特征映射中提取特征。然后,前一组的输出特征与另一组输入特征映射一起发送到下一组滤波器,此过程重复多次,直到处理完所有输入特征映射。最后,将来自所有组的特征映射连接起来,进过1×1滤波器,以将信息融合在一起,得到多尺度特征。
三、相关工作
1、相关的骨干网介绍
alexnet和vggnet通过堆叠卷积核的方式进行特征提取,这意味着每个特征层都有一个相对固定的感受野。googlenet利用不同大小的并行滤波器来增强多尺度表示能力,但这种能力往往受到计算约束的限制。ResNet引入了短连接,在获得更深层的网络结构的同时缓解了梯度消失问题,在特征提取过程中,短连接允许卷积算子的不同组合,从而产生大量多尺度特征。DenseNet中密集连接的层使网络能够处理尺寸变化大的对象。dpn将resnet与densenet相结合,使resnet的特征重用能力和densenet的特征探索能力充分结合。最近提出的DLA方法在树结构中结合了分层树结构使网络具有更强的分层多尺度表示能力。
2、需要多尺度特征表示的相关视觉任务
cnns的多尺度特征表示对许多视觉任务都具有重要意义,包括目标检测、人脸分析、边缘检测、语义分割、显著目标检测等。
(1)目标检测,如fpn方法引入特征金字塔,从单个图像中提取不同尺度的特征。SSD方法利用不同阶段的特征图处理不同尺度的视觉信息。
(2)图像分割,如最早的全卷积网络(FCN),还有就是deeplab的空洞卷积模块,在保持空间分辨率的同时进一步扩展了感受野,以及利用空间金字塔池化进一步提取多尺度特征。
(3)显著目标检测,精确定位图像中的显著对象区域需要确定对象显著性的大范围的上下文信息,以及精确定位对象边界的小范围特征,如使多尺度深度特征、上下文深度特征、多级卷积特征、以及引入密集的短连接,在每一层提供丰富的多尺度特征图用于显著目标检测。
3、相关的新进展
1、Big-Little Net 由不同计算复杂度的分支组成的多分支网络。
2、Octave Conv 将标准卷积分解为两个分辨率,以处理不同频率的特征。
3、HRNet在网络中重复执行多尺度融合以增强高分辨率表示。
四、网络结构
1、Res2Net Module
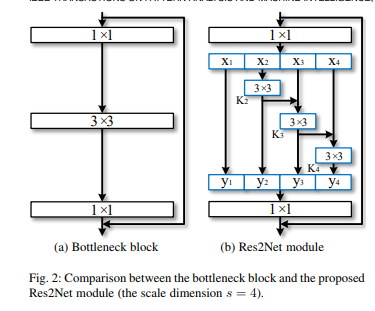
用更小的滤波器组替换原来残差块里的一组3×3滤波器,同时以层次化的残差连接方式连接不同的滤波器组,如下图所示:
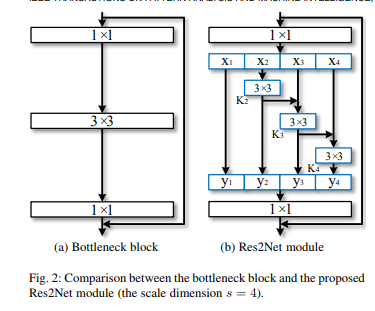
由图可以看到,在1×1卷积之后,将特征映射均匀地分割成S个特征映射子集,用Xi表示,其中i ∈ { 1, 2,…,S}。与输入特征图相比,每个特征子集Xi具有相同的空间大小,但通道数是原来的1/s。除X1外,每个Xi都有相应的3×3卷积(用Ki表示,用yi表示Ki的输出)。特征子集Xi加上Ki-1的输出作为Ki的输入,为了在增加s的同时减少参数,省略了X1的3×3卷积。因此,yi可以写成:
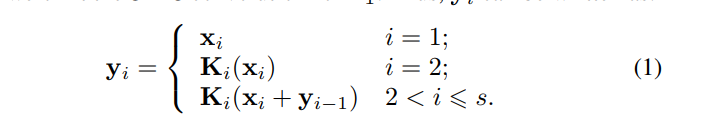
3×3卷积运算Ki从特征子集{xj,j≤i}接收特征信息。特征子集xj经过3×3卷积算子时,输出的结果可以具有比xj更大的感受野,因此Res2Net模块的输出包含不同的数量的不同感受野大小/尺度的特征组合。为了更好地融合不同尺度下的信息,我们将所有的子集的输出连接起来并通过1×1卷积运算来更有效地融合特征。s可作为尺度的控制参数。更大的s允许学习具有更大感受野的特征信息,而连接所引入的计算/内存开销却很少,因此可以忽略不计。
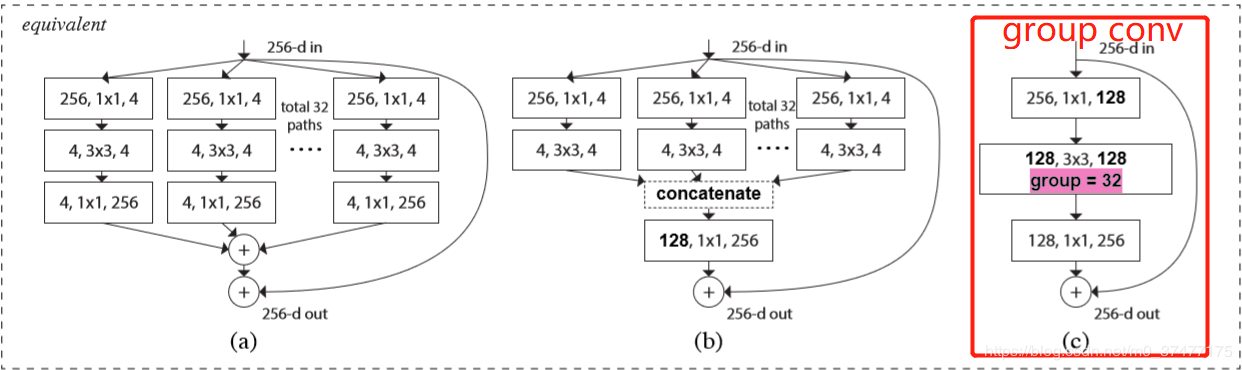
2、与Dimension cardinality和SE模块集成
Dimension cardinality本质上就是分组卷积的运用,如下图所示:
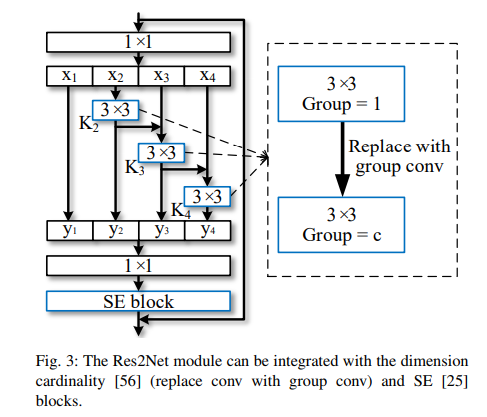
而SE块通过显式地建模信道之间的相互依赖性来自适应地重新校准信道特征响应。我们在Res2Net模块的残差连接之前添加SE块,如下图所示:
五、实验部分
表1显示了ImageNet数据集上的top1和top5的测试误差:

表2:ImageNet数据集上深层网络的top1和top5的测试误差:
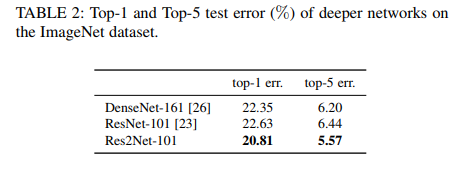
表3:ImageNet数据集上不同尺度的Res2Net-50的top1和top5的测试误差。参数w是滤波器的通道数,s是分组数。
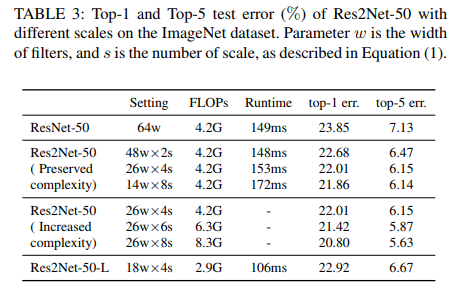
表四是不同模块组合的对照结果:
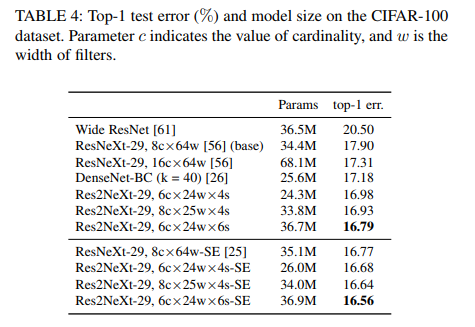
图5,不同超参数的对照试验(cifar100上的实验)
表5:PASCAL VOC07和COCO数据集上的目标检测结果,使用AP(%)和AP@IoU=0.5(%)进行测量。RES2NETs与同类相比具有类似的复杂性:
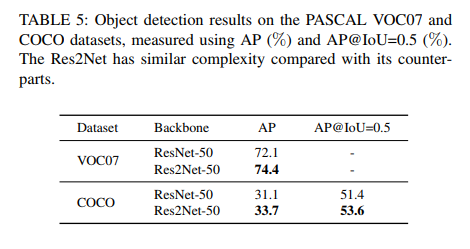
表6:COCO数据集上不同大小目标检测的平均精度(AP)和平均召回率(AR)。
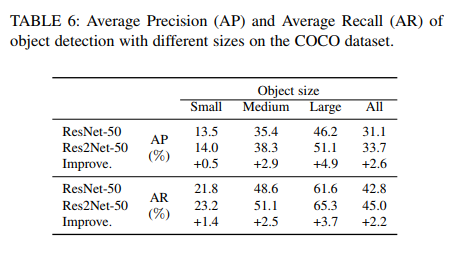
表7:语义分割:
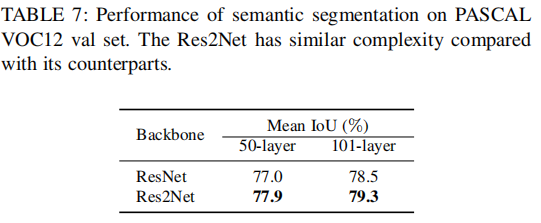
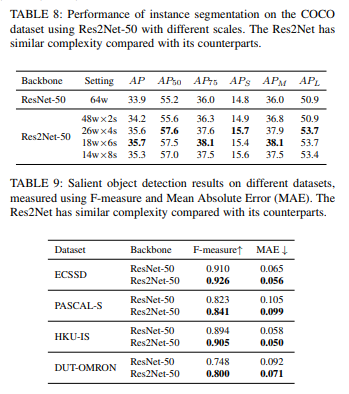
表8:实例分割,表9,:显著性检测,表10:关键点估计