@Team
2020-04-04T10:17:06.000000Z
字数 3512
阅读 3345
SOLO:一次性预测语义类别和实例掩码
石文华
一、前言
与其他许多密集预测任务(语义分割)相比,任意数量的实例使得实例分割更具挑战性。为了预测每个实例的 Mask,主流方法要么遵循“Mask R-CNN”使用的“先检测后分割(detect-then-segment)”策略,要么先预测类别 masks并对每个像素点都赋予一个 embedding 向量,将不同实例的像素点拉开,相同实例的像素点拉近。然后使用聚合后处理方法,将实例区分开来。
SOLO引入“实例类别(instance categories)”的概念,根据实例的位置和大小为实例中的每个像素分配类别,从而将实例 mask 分割很好地转换为可分类的类别问题。现在,实例分割被分解为两个分类任务。此方法具有强大的性能,可达到Mask R-CNN同等的准确性,并且在准确性方面优于最近的singleshot实例分割算法。
二、方法
1、问题表述:
给定任意一张图像,实例分割系统需要判断是否存在语义对象的实例;如果存在,则系统返回相应实例的分割掩码。SOLO框架的核心思想是将实例分割重新定义为两个子问题:类别预测和实例掩码生成。具体来说,就是将输入图像划分成一个统一的网格,即S×S。如果一个对象的中心落在一个网格单元中,该网格单元就要负责:1)预测语义类别;2)分割该对象实例。
2、语义类别(Semantic Category)
对于每个网格,SOLO预测C个维度的输出,以表示语义类别的概率,其中C是类别的个数。这些概率取决于网格单元。如果将输入图像划分成S×S的网格,则输出空间将为S×S×C,如下图(上分支)所示。这样设计基于的一个假定是,S×S网格的每个网格单元必须属于一个单独的实例,因此只属于一个语义类别。在推理过程中,C维度的输出向量表示每个对象实例的类别概率。

3、实例掩码(Instance Mask)
在语义类别预测的同时,每个positive网格也会输出相应的实例掩码,给定一个输入图片,将它划分为个网格,总则共最多有个预测掩码。在输出的3D特征图中,在通道维度上直接对这些掩码进行编码。因此输出的实例掩码的维度就是,第k个通道负责在第(i,j)个网格中分割实例,其中(i,j都是从0开始),因此,在语义类别和掩码之间就构建起了一一对应的关系(如上图Figure 2下分支所示)。
预测实例掩码的直接方法是采用全卷积神经网络,如FCN。然而,传统的卷积运算在空间上具有一定的不变性。空间不变性能提高鲁棒性,因此在图像分类等任务中需要空间不变性。但是这里相反,我们需要一个空间变化的模型,更精确地说,位置敏感的模型,因为我们的分割掩码依赖于网格单元,必须由不同的特征通道分隔开。
我们的解决方案非常简单:受"CoordConv" 算子启发,在网络的初始阶段,直接将标准化后的像素坐标馈送进网络。具体地说,创建了一个与输入具有相同空间大小的张量,该张量包含像素坐标信息,且规范化为[-1,1]。然后,该张量与输入特征concat之后传递到下一层。将输入的坐标信息给到卷积操作,就将空间位置特征添加到传统的FCN模型中。CoordConv也许并不是唯一的选择,比如,半卷积算子也可以,使用CoordConv是因为它简单且易于实现。如果原始特征张量的大小为H×W×D,则新张量的大小为H×W×(D+2),其中最后两个通道为x-y像素坐标。
补充CoordConv如下(https://zhuanlan.zhihu.com/p/39919038):
卷积是等变的,也就是说当每个过滤器应用到输入上时,它不知道每个过滤器在哪。我们可以帮助卷积,让它知道过滤器的位置。这一过程需要在输入上添加两个通道实现,一个在i坐标,另一个在j坐标。我们将这个图层成为CoordConv,如下图所示:

4、构建实例分割
在SOLO中,类别预测和对应的掩码与网格是关联的,即,因此,可以直接得到每个网格的最终实例分割结果,通过将所有网格的分割结果叠加汇总,并且采用非极大值抑制(NMS)方法得到图像最终的实例分割结果。而不再需要其他后处理操作。
三、网络结构
使用特征金字塔结构(FPN),每个层级上通道数为256,这些特征图作为每个预测head的输入。不同的层级上head的权重共享。网格数在不同层级的金字塔上可能不同。
1、Vanilla SOLO(对应的mask预测分支输出通道为)
在每个FPN特征层,附加两个同级子网络,作为预测head,一个用于实例类别预测(top),另一个用于实例掩码分割(bottom)。在掩码分支中,我们将x、y坐标和原始特征拼接起来以编码空间信息。head分支如下图所示:
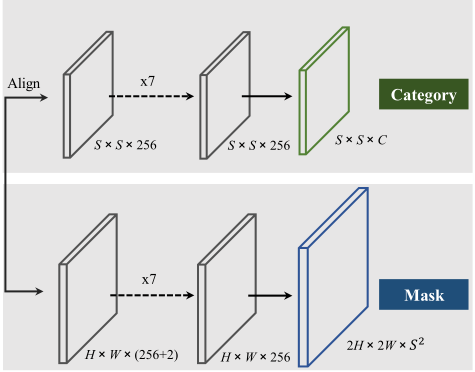
如上图,以256个通道为例。箭头表示卷积或插值。所有卷积大小都是3×3,“Align”表示自适应池化、插值或区域网格插值。在推断过程中,掩码分支输出将进一步上采样到原始图像大小。
2、Decoupled SOLO
可以看到,如果S=20,这样SOLO head的Mask预测分支就会输出400个通道的特征图,其实绝大多数场景中图片都不会有很多实例,因此,作者提出了更有效率的变种Decoupled SOLO,如下:

原始的输出张量 被替换为两个输出张量,和 的element-wise相乘:
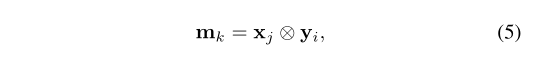
其中 分别表示X的第j个通道图,和Y的第i个通道图。
这两种方式性能相近,Decoupled SOLO降低了输出的维度和所需的GPU内存。
四、SOLO 训练
1、 Label Assignment
对于类别预测分支,需要给出SxS个网格的对象类别概率,如果网格与某 ground truth 掩码的中心区域重叠大于某阈值,则被视为正样本,否则是负样本。给定ground truth 掩码的质心、宽度w和高度h,中心区域由恒定比例因子控制。这里设置=0.2。每个ground truth掩码平均有3个正样本,每个正样本,都有一个二值的掩码。由于有个网格,我们为每个图像设置了个输出掩码,上下两个分支对应关系为k=i⋅S+j。
除了实例类别的标签外,还需要为每个正样本设置了一个二值分割掩码。由于个网格对于个输出掩码。对于每个正样本,标注目标相应的二元掩码。
2、损失函数
定义损失函数如下:
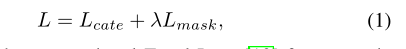
其中, 是针对语义类别分割的Focal Loss,是掩码预测的损失函数,具体如下:
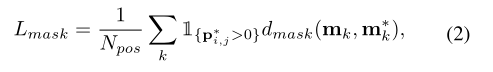
索引(顺序为从上到下、从左到右):
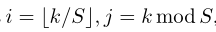
为正样本数,,分别为类别真值和掩码真值。是指示函数,如果,则为1,否则为0。
在实现中,比较了的不同实现:BCE(二元交叉熵损失),Focal Loss 和 Dice Loss。最终选择Dice Loss,因为它在训练中比较稳定且有效。损失函数公式中的λ设为3。 Dice Loss 定义如下:
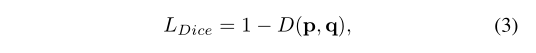
这里的D为 dice 系数,定义如下:
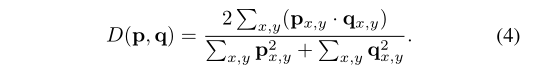
和分别是预测掩码和真实掩码在(x,y)位置的像素值。
五、推理
SOLO的推理非常直接,给定一张输入图片,通过骨干网和FPN得到网格(i,j)位置的类别得分和相对于的掩码(其中,k=i·S+j)。首先使用0.1的置信阈值过滤掉低置信度的预测,然后选择得分最高的500个掩码并将其输入NMS操作,为了将预测的掩码转换为二元掩码,作者使用了阈值0.5,对预测掩码进行二值化。保留其中前100个实例掩码用于评估。
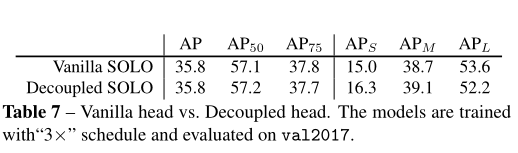
六、实验结果
COCO测试集中的实例分割掩码AP,SOLO的精度超越了Mask R-CNN,相较思路类似的PolarMask也有较大的优势,如下图所示: