@Team
2018-04-17T03:06:50.000000Z
字数 3234
阅读 4320
你知道如何计算CNN感受野吗?这里有一份详细指南
叶虎
本文翻译自A guide to receptive field arithmetic for Convolutional Neural Networks,原作者保留版权。
感受野(receptive field,RF)也许是CNN中最重要的概念之一,从文献上来看,它应当引起足够的重视。目前所有最好的图像识别方法都是在基于感受野理念来设计模型架构。然而,据我所知,目前并没有一个完整的教程来介绍如何计算并可视化一个CNN的感受野。这篇文章将填补这一空白,这里介绍CNN特征图可视化的一种新方法,可视化可以显示感受野信息,并且给出一个完整的感受野计算公式,它适用于任何CNN架构。我也实现了一个简单的程序来验证这个计算公式,任何人都可以利用该公式计算它们所设计的CNN的感受野,从而对所设计的架构有更多的认识。
要阅读这篇文章,你必须要熟悉CNN的核心概念,特别是卷积和池化操作。你可以通过阅读这篇论文(A guide to convolution arithmetic for deep learning)来复习CNN的基础知识。如果你对CNN有一定的了解,你将用不了半个小时来看完。这篇文章实际上是在这篇论文基础上完成的,使用相同的符号标记。
如果你想学习CNN如何应用在图像识别上,可以阅读这篇文章。
固定大小的CNN特征图可视化
感受野指的是一个特定的CNN特征(特征图上的某个点)在输入空间所受影响的区域。一个感受野可以用中心位置(center location)和大小(size)来表征。然而,对于一个CNN特征来说,感受野中的每个像素值(pixel)并不是同等重要。一个像素点越接近感受野中心,它对输出特征的计算所起作用越大。这意味着某一个特征不仅仅是受限在输入图片中某个特定的区域(感受野),并且呈指数级聚焦在区域的中心。这个重要的发现会在下一篇文章中讲。现在,我们关注如何计算一个特定感受野的中心位置和大小。
图1为给出了某些感受野实例。其中输入特征图大小为,采用的卷积参数如下:卷积核大小,padding大小,步长。经过一次卷积之后,得到大小为的输出特征图(绿色)。在这个特征图上继续采用相同的卷积,得到一个的特征图(橙色)。输出特征图的大小可以通过如下公式计算(参考A guide to convolution arithmetic for deep learning):

为了简化讲解,这里假定CNN架构是对称的,并且输入图片是方形的。因此所有的卷积层的所有参数在两个维度上都是相同的。如果CNN架构或者输入图片是非对称的,你可以为各个维度单独计算特征图的属性。
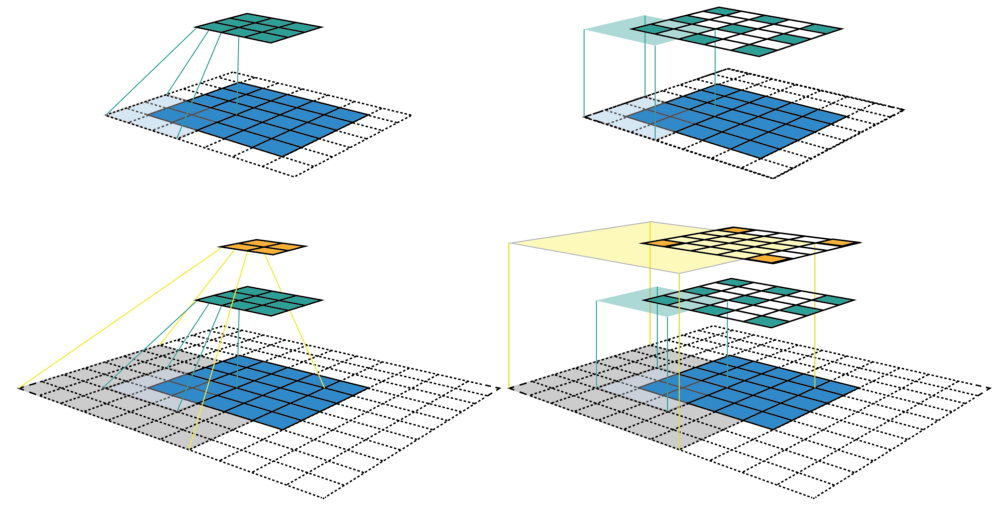
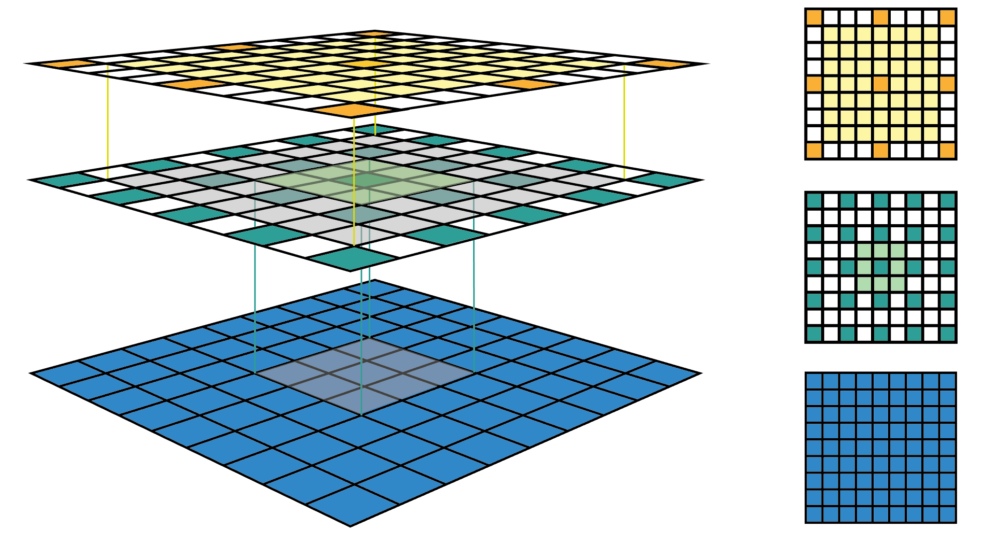
图1的左栏给出了CNN特征图可视化最常用的方式。在这个可视化中,我们可以看到每个特征图所包含的特征数,但是很难知道每个特征的感受野的中心位置和大小,对于深度CNN,我们没有办法追踪到感受野信息。右栏给出的是固定大小的CNN可视化,所有的特征图固定大小并保持与输入特征图大小一致,这可以解决前面的问题。每个特征被标记在其感受野所在的中心(从而定位出感受野中心位置)。由于一个特征图中所有的特征都有相同大小的感受野,我们可以简单地在每个特征周围画出一个边界框,从而获得感受野的大小。我们也没有必要将这个边界框向下映射到输入层,因为特征图已经与输入层具有相同的大小。图2给出了另外一个实例,其中输入特征图更大,为,与前面例子采用相同的卷积。图的左栏和右栏分别给出了固定大小CNN特征图的3D和2D可视化。可以看出感受野大小增加迅速,以至于第二个特征层的中心特征的感受野已经覆盖了整个输入特征图。这在深度CNN中是一个很重要的设计理念以提升性能。
感受野计算公式
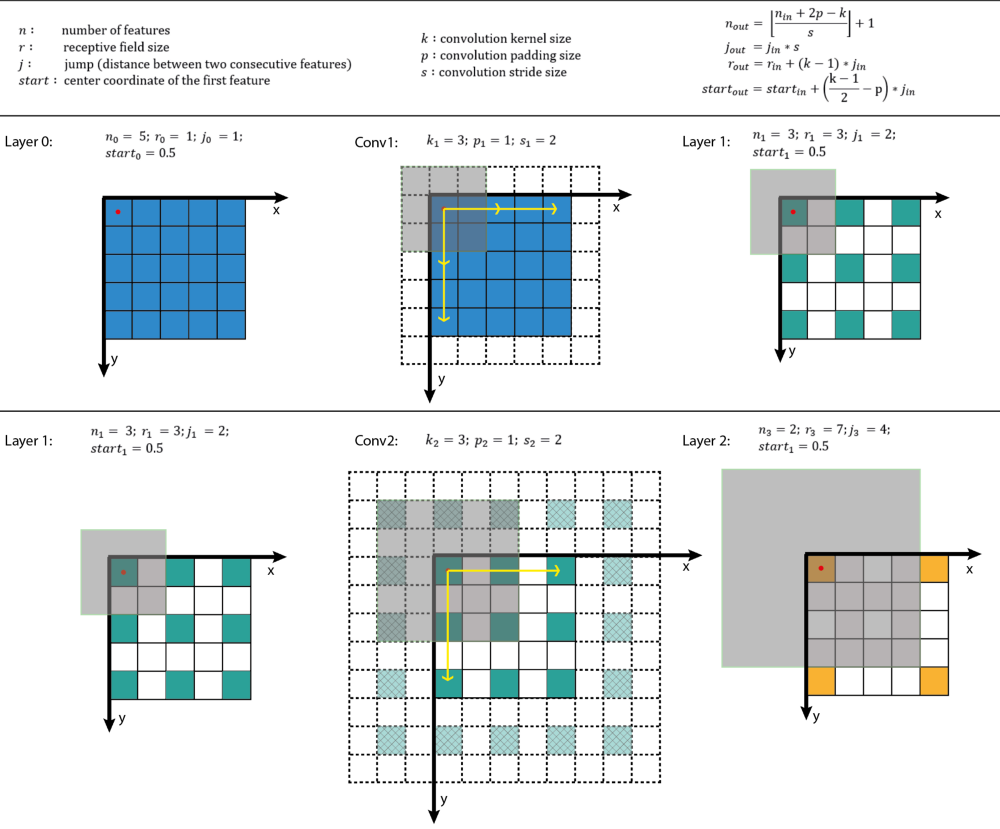
为了计算CNN每一层的感受野,除了要知道特征图每个维度的特征数,还需要记录每一层的其他信息,这包括当前层的感受野大小,两个相邻特征的距离(跳跃的距离,如前面可视化所示),和左上角特征(第一个特征)的中心坐标。注意感受野(其实是特征图第一个特征的感受野)的中心坐标就等于这个特征的中心坐标,就如前面可视化中所示。当采用的卷积其核大小为,padding大小为,步长为,输出特征图的感受野可以按照如下公式计算:

- 第一个式子根据输入特征图大小以及卷积参数计算输出特征图大小,前面已经说过。
- 第二个式子计算输出特征图的特征间的间隔,其等于上一层的间隔值乘以卷积的步长,所以间隔值将是按照步长呈指数级增长。
- 第三个式子计算输出特征图的感受野大小,其等于前一层感受野大小加上,所以感受野是呈指数级增加,并且还有一个因子。
- 第四个式子计算输出特征图的第一个特征感受野的中心坐标,其等于第一层的中心坐标加上,再减去,注意两项都要乘以前一层的间隔距离以得到实际距离。
对于第一层,一般是输入图片,其各项值为:。图3给出了一个如何计算感受野的实例,图中的坐标系统中,输入层的第一个特征中心位置记为。通过利用上面公式迭代地进行计算,你可以计算出CNN中所有特征图的感受野信息。
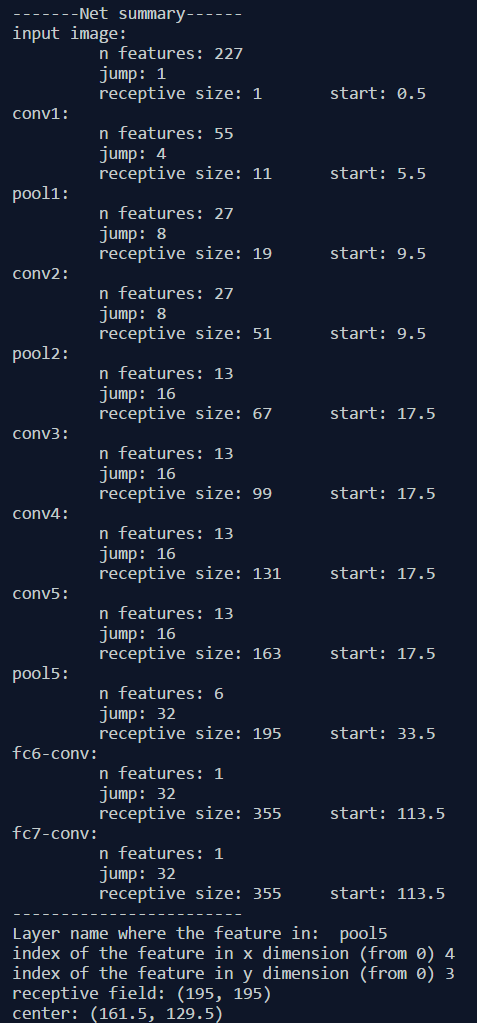
我也写了一个简单的Python程序来计算某个特定CNN架构的各个层的感受野信息。它可以通过输入某一个特征图的姓名或者索引值,给出相应的感受野大小和位置信息。下面的图给出了在AlexNet上的计算结果:
附文
对于感受野大小的计算,另外有一个博客(Calculating Receptive Field of CNN)给出一个更简洁的计算公式,对于第层的感受野大小计算如下:
其中是第层的感受野大小,而是当前层的卷积核大小,是第层的步长。从这个公式可以看到,相比前一层,当前层的感受野大小在两层之间增加了 ,如果stride大于1的话,这是一个指数级增加。这个公式也可以这样理解,对于第 层,其卷积核为 ,那么相比前一层需要计算 个位置(或者神经元,意思是 层的一个位置在 层的视野大小是 ),但是这些位置要一直向前扩展到输入层。对于第一个位置,扩展后的感受野为 ,正好是前一层的感受野大小,但是对于剩余的 个位置就要看stride大小,你需要扩展到前面所有层的stride(注意不包括当前层的stride,当前层的stride只会影响后面层的感受野),所以需要乘以 ,这样剩余 个位置的感受野大小就是 ,和第一个位置的感受野加到一起就是上面的公式了。。其实这个公式算是整合了前面的公式2和公式3(第一层的),两个本质上是一致的,不过如果你仅想计算感受野大小可以用这个公式更方便。
小结
在CNN中,感受野应该是一个很重要的东西,但是往往被大家忽略,在我看到的文献中,图像分割模型DeepLab就提到了感受野大小的问题,但是那里并没有给出计算公式,如果采用上面的公式就可以快速得到结果。对于图像分割,感受野大小对分割效果是有很大影响的,所以DeepLab采用了扩展卷积(Atrous Convolution, Dilated Convolution)来增加感受野大小。对于空洞卷积来说,你可以将其转化为普通卷积(卷积核大小增加)来计算特征图的感受野。另外,上面的公式同样适用于池化层,因为其在结构上与卷积层是类似的。
