@Team
2018-11-18T09:09:13.000000Z
字数 5106
阅读 2478
《Computer vision》笔记-ResNet(4)
石文华
1、前言:
深度卷积神经网络为图像分类带来了一系列突破。深度网络可以以端到端多层方式集成低/中/高级特征用于分类或者回归,并且可以通过堆叠层的数量(深度)来丰富特征的“级别”。仅仅通过堆叠更多的层,随着网络深度的增加,准确度变得饱和,然后迅速下降。这种退化不是由过拟合和引起的。模型达到一定深度时,更多层导致更高的训练误差,如下图所示:

随着深度的增加,网络效果不好,那是因为存在着梯度消失和梯度爆炸的原因,它从一开始就阻碍了收敛。虽然这个问题在很大程度上可以通过归一化初始化和层归一化(BN)来缓解。
2、核心结构:
resnet在2015年举办的ILSVRC中获得了分类任务第一名,同时,在 ImageNet detection, ImageNet localization,COCO detection, 和 COCO segmentation等任务中也是第一名。
如下图所示是resNet的核心结构:
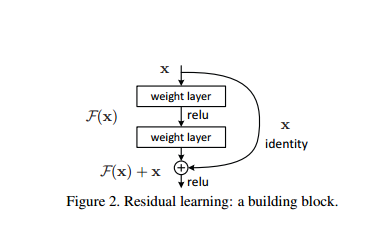
可以看到结果中有两种mapping,一种是identity mapping,也就是图中的x直接跳过几个层,将前面学到的特征表达能力传到后面去,另外一种是residual mapping,也就是被跳过的那几层,称为残差,即图中的F(x)那部分.resNet的设计思想是假设设计好的网络存在最优的网络层次,那么很深的网络中就会有很多冗余的层,如果能够将这些冗余的层能够完成恒等映射,使得已经达到最优特征表达的输入在经过这些冗余的层后得到的输出完全相同,使得网络一直保持最优状态,如果没有达到最优,那么它也会学到一些有用的信息。恒等变换的意思是经过冗余的层之后学到的参数能够使得输出H(x)=x,而大量实验表明,直接学习这种形式的恒等映射非常困难,而resNet加入了残差项,也就是使H(x)=F(x)+x,直接学习让F(x)=0,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛.下图分别是普通的网络结构和残差网络结构:
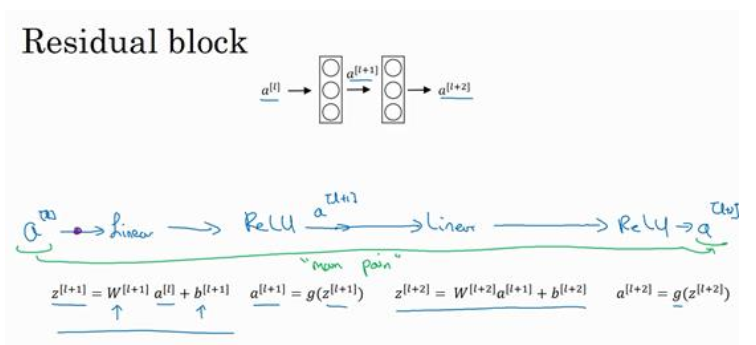
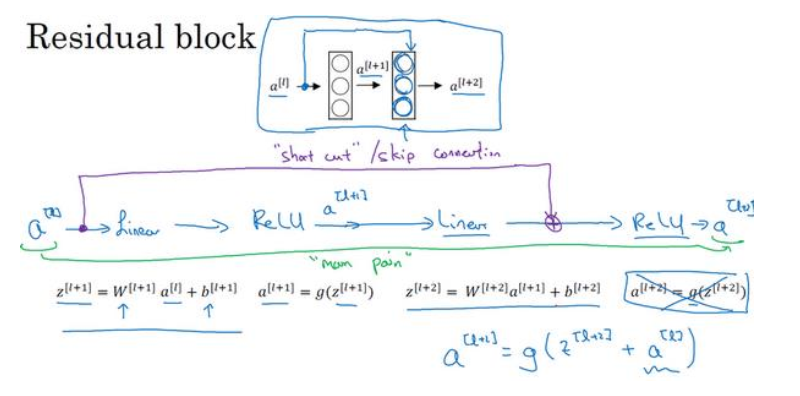
对于普通的网络结构,假设输入是a[l],那个经过两个层之后,信息流变换的过程如下:
Z[l+1]=W[l+1]*a[l]+b[l+1]
a[l+1]=g(Z[l+1])
Z[l+2]=W[l+2]*a[l+1]+b[l+2]
a[l+2]=g(Z[l+2])
而当加了identity mapping之后,信息流的输出变为a[l+2]=g(Z[l+2]+a[l]).
如果a[l]达到最优了,要完成恒等映射,对于普通网络来说,就要使得g(Z[l+2])=a[l],对于残差结构是g(Z[l+2]+a[l])=a[l],假设使用relu函数,那么直接将Z[l+2]置成0要比拟合出各种参数使得g(Z[l+2])=a[l]要跟容易得多(Z[l+2]等于0之后,g(Z[l+2]+a[l])=a[l]简化成g(a[l])=a[l],而使用的激活函数是relu函数,所以左右两边相等).
3、网络结构
普通网络变成残差网络只需要每两层增
加一个捷径,构成一个残差块就可以了,如下图所示:
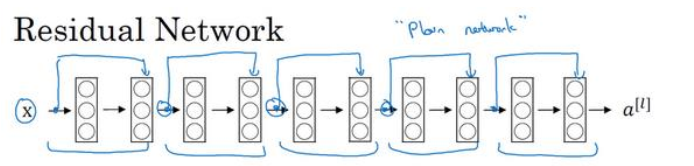
当然,里面并不一定都是VGG结构一样,都采用的是3*3大小的卷积核,也可以加上1*1卷积核,降低计算量和参数量,如下图所示:
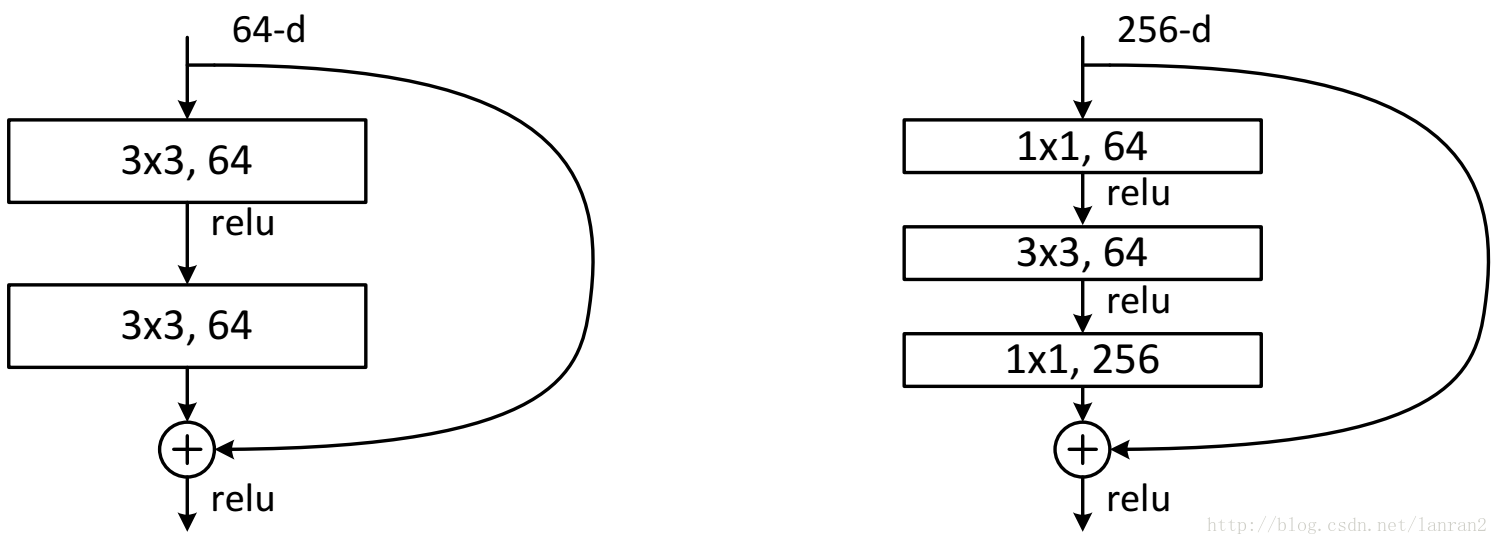
另外一点需要注意的是,F(x)和x是按照channel维度相加的,所以当维度不同的时候,可以将不能匹配的部分用0填充,也可以引入一个卷积操作,用来调整x的channel维度:H(x)=F(x)+Wx,这里的W是卷积操作(类似于1*1的卷积形式)。
4、改进
上述的resNet的结构可以用如下比较通用的公式进行表示:
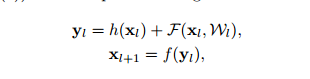
但是它不能完全认为是Identity Mapping,原因在于最后addition后面接了一层ReLU,如果去掉这个relu层,使得所有”shortcut“分支都为identity mapping(h(x) = x),公式简化为:
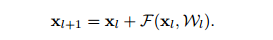
进行多次迭代运算:xl+2 = xl+1 + F(xl+1; Wl+1) = xl + F(xl; Wl) + F(xl+1; Wl+1),得到:
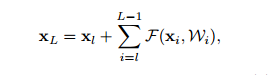
上述公式表示的是深层L和浅层l之间的关系,假设损失函数为loss,那么反向传播公式为(链式法则):
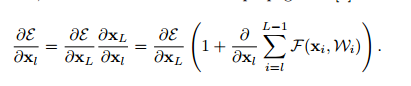
可以看到第l层的梯度信息与两部分有关:第L层的梯度值(第一部分),也就是说两层之间梯度信息无障碍传递了,以及后面一分部(第二部分)。由于第二部分并不会一直等于-1,所以第l层并不会产生梯度消失,
以上优点只有在identity mapping假设成立的基础上(h(x) = x 和 f(x) = x),所以ResNet要尽量保持两点:1)不轻易改变”shortcut“分支的值,保证其identity性;2)addition之后不再接改变信息分布的层,如BN层。因为它会影响信息传递,从而影响训练。
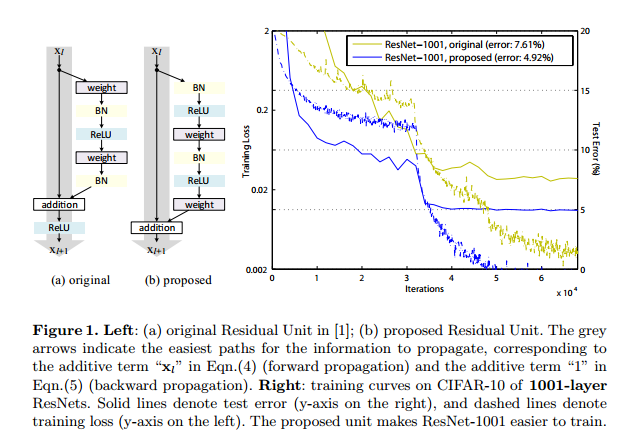
上图表示的是原始的resNet结构和改进后的结构(a表示的是原始结构,b表示的是改进后的结构)以及它们效果的对比情况,可以发现b结构的效果更佳。原因在于b结构的反向传播符合identity mapping的假设(没有改变”shortcut“分支的值),使得信息可以在整个网络里自由地前向传播和后向传播,更容易优化,同时还使用了BN层作为Pre-activation,起到了正则化的作用。
5、代码:
加载数据:
import torchfrom torchvision import datasets,transformsimport osimport matplotlib.pyplot as pltimport time#transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等。#DataLoader读入的数据类型是PIL.Image#这里对图片不做任何处理,仅仅是把PIL.Image转换为torch.FloatTensor,从而可以被pytorch计算transform = transforms.Compose([transforms.Scale([224,224]),transforms.ToTensor(),#transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])#训练集train_set = datasets.CIFAR10(root='drive/pytorch/Alexnet/', train=True, transform=transform, target_transform=None, download=True)#测试集test_set=datasets.CIFAR10(root='drive/pytorch/Alexnet/',train=False,download=True,transform=transform)trainloader=torch.utils.data.DataLoader(train_set,batch_size=32,shuffle=True,num_workers=0)testloader=torch.utils.data.DataLoader(test_set,batch_size=32,shuffle=True,num_workers=0)classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')(data,label)=train_set[64]print(classes[label])
查看数据:
X_example,y_example=next(iter(trainloader))print(X_example.shape)img=X_example.permute(0, 2, 3, 1)print(img.shape)import torchvisionimg=torchvision.utils.make_grid(X_example)img=img.numpy().transpose([1,2,0])import matplotlib.pyplot as pltplt.imshow(img)plt.show()
使用预训练的模型进行迁移学习:
from torchvision import modelsresnet=models.resnet50(pretrained=True)for parma in resnet.parameters():parma.requires_grad = Falseresnet.fc = torch.nn.Linear(2048,10)cost=torch.nn.CrossEntropyLoss()optimizer=torch.optim.Adam(resnet.fc.parameters(),lr=0.0001)import torch.optim as optim #导入torch.potim模块import timefrom torch.autograd import Variable # 这一步还没有显式用到variable,但是现在写在这里也没问题,后面会用到import torch.nn as nnimport torch.nn.functional as Fepoch_n=5for epoch in range(epoch_n):print("Epoch{}/{}".format(epoch,epoch_n-1))print("-"*10)running_loss = 0.0 #定义一个变量方便我们对loss进行输出running_corrects=0for i, data in enumerate(trainloader, 1): # 这里我们遇到了第一步中出现的trailoader,代码传入inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels#inputs=inputs.permute(0, 2, 3, 1)#print("hahah",len(labels))y_pred = resnet(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了_,pred=torch.max(y_pred.data,1)optimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度loss = cost(y_pred, labels) # 计算损失值,criterion我们在第三步里面定义了loss.backward() # loss进行反向传播,下文详解optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程running_loss += loss.item() # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次running_corrects+=torch.sum(pred==labels.data)if(i % 2 == 0): # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(i,running_loss/i,100*running_corrects/(32*i)))
参考文献:
https://www.cnblogs.com/shouhuxianjian/p/7766441.html
http://www.myzaker.com/article/5997f9f51bc8e01202000015/
https://www.sohu.com/a/163256797_697750
https://blog.csdn.net/xxy0118/article/details/78324256
https://blog.csdn.net/lanran2/article/details/79057994
https://www.toutiao.com/a6605451533502906893/
https://blog.csdn.net/lanran2/article/details/80247515
Andrew Ng 《Deep Learning》
