@Team
2019-07-28T16:24:02.000000Z
字数 7971
阅读 3417
《Computer vision》笔记-MobileNetV3(9)
石文华
1、相关工作:
设计深度神经网络结构以实现精度与效率的最佳权衡是近年来研究的热点。新的手工结构和算法神经结构搜索都对这一领域的发展起到了重要作用。Squeezenet[22]广泛使用1X1卷积,其挤压和扩展模块主要集中于减少参数数量。最近的工作将重点从减少参数转移到减少操作数(MADD)和实际预测的延迟。MobileNetv1[19]采用了深度可分离卷积,大大提高了计算效率。MobileNetv2[39]通过引入一个具有反向残差和线性瓶颈的资源高效块来扩展这一点。shufflenet[49]利用组卷积和信道shuffle操作来进一步减少MADD。CondenseNet[21]在训练阶段学习分组卷积,以保持层之间有用的密集连接,以便特征重用。shiftnet[46]建议移位操作与点向卷积交错,以取代昂贵的空间卷积。
2、高效的移动端网络模块
(1)、MobileNetV1[17]引入深度可分离卷积作为传统卷积层的有效替代,深度可分卷积通过将空间滤波与特征生成机制分离,有效地分解传统卷积。深度可分卷积由两个独立的层定义:用于空间滤波的轻量级深度卷积和用于特征生成的1x1点卷积。具体来说就是深度卷积中一个卷积核通道上只有一维,负责特征图的一个通道,一个通道只被一个卷积核卷积,深度卷积完成后的输出特征图通道数与输入层的通道数相同。1x1点卷积能够对特征图起到降维或升维的操作,将上一层的特征图在深度方向上进行加权组合,生成的新的特征图的大小与输入数据大小一致,主要作用是组合各通道的特征信息。
(2)、MobileNetV2[37]引入了线性瓶颈和倒残差结构,以便利用问题的低秩性质使层结构更加有效,MobileNetV2版本中的残差结构先用逐点卷积升维并使用Relu6激活函数,接着使用深度卷积,同样使用Relu6激活函数,再使用逐点卷积降维,降维后使用Linear激活函数。这种结构在输入和输出处保持了紧凑的表示,同时在内部扩展到高维特征空间,以增加非线性每个通道转换的表达能力。

(3)、MnasNet[41]建立在MobileNetV2结构上,通过在瓶颈结构中引入Squeeze-and-excitation 轻量级attention模块(SE模块),该模块位于深度卷积之后,能够让网络模型对特征进行校准,使得有效的权重大,无效或效果小的权重小。该模块主要包含Squeeze和Excitation两部分,Squeeze即压缩操作,对特征图使用全局平均池化(global average pooling)。经过压缩操作后特征图被压缩为1×1×C向量。Excitation即激励操作,由两个全连接层组成,第一个层先将全连接维度降下来,之后第二个再将维度恢复回1×1×C,得到各个通道的权重,最后各通道权重值分别和原特征图对应通道的二维矩阵相乘。
3、新型架构设计
基于互补搜索技术和新颖架构设计相结合的下一代MobileNets,MobileNetV3通过结合硬件感知网络架构搜索(NAS)和NetAdapt算法对移动端的cpu进行调优,然后通过新的架构改进对其进行改进。MobileNetV3可以看做是在V1,V2基础上进行的改进,因此V3拥有V1,V2的那些有效的模块:深度可分离卷积、批归泛化、反向残差结构、线性瓶颈结构、平均池化等。V3中新的特性有:5x5的深度卷积、SE模块、以及改进的激活函数h-swish。
(1)、5x5的深度卷积,这个特性是使用NAS计算发现的,深度卷积中使用5x5大小的卷积核比使用3x3大小的卷积核效果更好,准确率更高。
(2)、SE模块,MobileNetV3的SE模块被运用在线性瓶颈结构最后一层上,代替V2中最后的逐点卷积,改为先进行SE操作再逐点卷积。

(3)、改进的激活函数。在论文《Concentrated-comprehensive convolutions for lightweight semantic segmentation》中引入了一种称为swish的非线性,当作为ReLU的替代时,它可以显著提高神经网络的精度,非线性定义为:

因为要在移动设备上计算sigmoid函数,所以swish的计算量对移动端来说太大了,因此并不适合轻量级神经网络。于是将sigmoid函数替换为计算量少很多的分段线性硬模拟:ReLU6(x+3)/6,swish的硬版本也变成了:
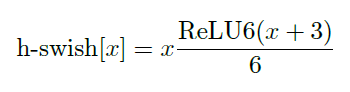
sigmoid、h-sigmoid、swish、h-swish激活函数的比较:
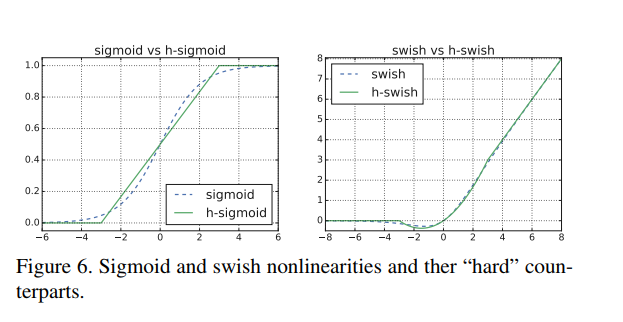
实验中,所有这些函数的硬版本在精度上没有明显的差异,但是从部署的角度来看,它们具有多种优势。首先,几乎所有的软件和硬件框架上都可以使用ReLU6的优化实现。其次,在量化模式下,它消除了由于近似sigmoid的不同实现而带来的潜在的数值精度损失,运行快,但相比ReLU,这一非线性改变将模型的延时增加了15%。需要注意一点的是,swish的大多数好处都是通过只在更深的层中使用它们实现的。因此,在新的架构中,只在模型的后半部分使用h-swish。
4、MobileNetV3网络结构
mobilenetv3有两种型号:mobilenetv3-large和mobilenetv3-small。分别针对高资源使用案例和低资源使用案例。这些模型是通过NAS和Netadapt进行网络搜索并结合人工定义的网络改进而创建的。网络如下:
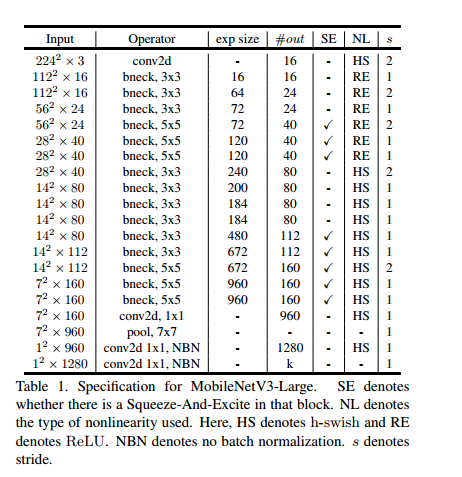
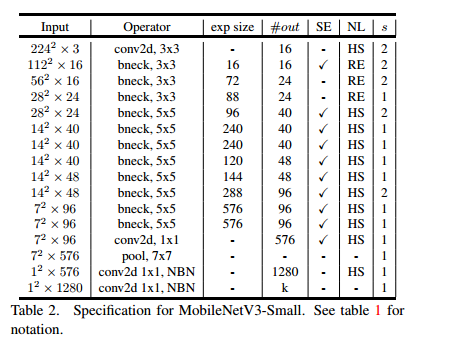
5、实验部分
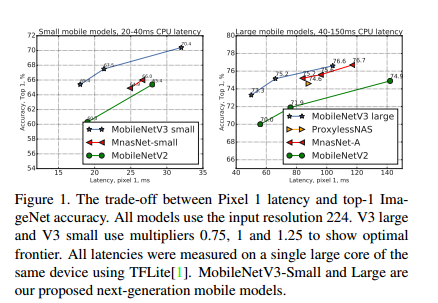
(1)模型优于当前的技术水平,如mnasnet[43]、proxylessnas5和mobilenetv2[39],如下图所示:
(2)不同像素手机的浮点性能、以及量化结果:

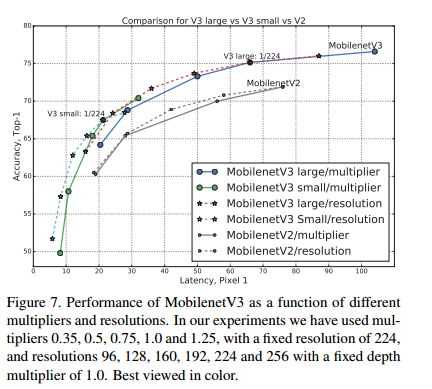
(3)、不同的分辨率以及不同的模型深度的精度对比,分辨率分别选择的是[96,128,160,192,224,256],深度分别选为原来的[0.35,0.5,0.75,1.0,1.25]。可见,其实resolution对于精度以及速度的平衡效果更好,可以达到更快的速度,同时精度没有改变模型深度精度低,反而更高。
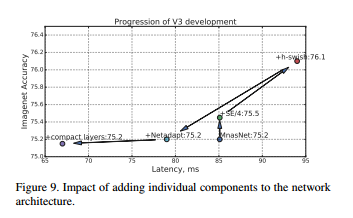
(4)、将mobilenet v3应用于SSD-Lite在COCO测试集的精度结果。观察可以发现,在V3-Large上面,mAP没有特别大的提升但是速度确实降低了一些的。
6、代码
激活函数H_swish=x*relu6(x+3)/6
import torch.nn as nnclass Hswish(nn.Module):def __init__(self,inplace=True):super(Hswish,self).__init__()self.relu6=nn.ReLU6(inplace)def forward(self,x):return x*self.relu6(x+3.)/6class Hsigmoid(nn.Module):def __init__(self,inplace=True):super(Hsigmoid,self).__init__()self.relu6=nn.ReLU6(inplace)def forward(self,x):return self.relu6(x+3.)/6.
SE模块:
import torch.nn as nnfrom torchsummary import summaryclass SEModule(nn.Module):'''reduction参数:是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。'''def __init__(self,in_channels,reduction=4):super(SEModule,self).__init__()self.avg_pool=nn.AdaptiveAvgPool2d(1)self.fc=nn.Sequential(nn.Linear(in_channels,in_channels//reduction,bias=False),nn.ReLU(True),nn.Linear(in_channels // reduction, in_channels, bias=False),Hsigmoid(True))def forward(self,x):n,c,_,_=x.size()out = self.avg_pool(x).view(n, c)out = self.fc(out).view(n, c, 1, 1)return x * out.expand_as(x)if __name__ == "__main__":SE=SEModule(in_channels=12)print(SE)summary(SE, (12, 224, 224))
MobileNetV3的Block:
class Identity(nn.Module):def __init__(self,in_channels):super(Identity,self).__init__()def forward(self,x):return x"""MobileNetV3的Block三个必要步骤:1×1卷积,由输入通道,转换为膨胀通道;3×3或5×5卷积,膨胀通道,使用步长stride;1×1卷积,由膨胀通道,转换为输出通道。两个可选步骤:SE结构:Squeeze-and-Excite;连接操作,Residual残差;步长为1,同时输入和输出通道相同;其中激活函数有两种:ReLU和h-swish。"""class Bottleneck(nn.Module):def __init__(self,in_channels,out_channels,exp_size,kernel_size,stride,dilation=1,se=False,nl='RE'):super(Bottleneck,self).__init__()assert stride in [1,2]#当stride为1且输入和输出通道一样时,才使用resnet的连接方式self.use_res_connect = (stride == 1 and in_channels == out_channels)"""选择使用的激活函数类型"""if nl=='HS':act=Hswishelse:act=nn.ReLU"""是否使用SE,不使用的话就什么都不做(Identity)"""if se:SELayer=SEModuleelse:SELayer=Identityself.conv=nn.Sequential(#pwnn.Conv2d(in_channels,exp_size,1,bias=False),nn.BatchNorm2d(exp_size),act(True),#dwnn.Conv2d(exp_size, exp_size, kernel_size, stride, (kernel_size - 1) // 2 * dilation,dilation, groups=exp_size, bias=False),nn.BatchNorm2d(exp_size),SELayer(exp_size),act(True),#pw-linearnn.Conv2d(exp_size,out_channels,1,bias=False),nn.BatchNorm2d(out_channels))def forward(self,x):if self.use_res_connect:return x+self.conv(x)else:return self.conv(x)
MobileNetV3网络代码:
class MobileNetV3(nn.Module):def __init__(self, nclass=1000, mode='large', width_mult=1.0, dilated=False):super(MobileNetV3, self).__init__()if mode == 'large':# k, exp_size, c, se, nl, slayer1_setting = [# k, exp_size, c, se, nl, s[3, 16, 16, False, 'RE', 1],[3, 64, 24, False, 'RE', 2],[3, 72, 24, False, 'RE', 1], ]layer2_setting = [[5, 72, 40, True, 'RE', 2],[5, 120, 40, True, 'RE', 1],[5, 120, 40, True, 'RE', 1], ]layer3_setting = [[3, 240, 80, False, 'HS', 2],[3, 200, 80, False, 'HS', 1],[3, 184, 80, False, 'HS', 1],[3, 184, 80, False, 'HS', 1],[3, 480, 112, True, 'HS', 1],[3, 672, 112, True, 'HS', 1],[5, 672, 112, True, 'HS', 1], ]layer4_setting = [[5, 672, 160, True, 'HS', 2],[5, 960, 160, True, 'HS', 1], ]elif mode == 'small':layer1_setting = [# k, exp_size, c, se, nl, s[3, 16, 16, True, 'RE', 2], ]layer2_setting = [[3, 72, 24, False, 'RE', 2],[3, 88, 24, False, 'RE', 1], ]layer3_setting = [[5, 96, 40, True, 'HS', 2],[5, 240, 40, True, 'HS', 1],[5, 240, 40, True, 'HS', 1],[5, 120, 48, True, 'HS', 1],[5, 144, 48, True, 'HS', 1], ]layer4_setting = [[5, 288, 96, True, 'HS', 2],[5, 576, 96, True, 'HS', 1],[5, 576, 96, True, 'HS', 1], ]else:raise ValueError('Unknown mode.')# building first layerself.in_channels = int(16 * width_mult)self.conv1 = ConvBNswish(3, self.in_channels, 3, 2, 1)# building bottleneck blocksself.layer1 = self.make_layer(Bottleneck, layer1_setting,width_mult)self.layer2 = self.make_layer(Bottleneck, layer2_setting,width_mult)self.layer3 = self.make_layer(Bottleneck, layer3_setting,width_mult)if dilated:self.layer4 = self.make_layer(Bottleneck, layer4_setting,width_mult, dilation=2)else:self.layer4 = self.make_layer(Bottleneck, layer4_setting,width_mult)# building last several layersclassifier = list()if mode == 'large':last_bneck_channels = int(960 * width_mult) if width_mult > 1.0 else 960self.layer5 = ConvBNswish(self.in_channels, last_bneck_channels, 1)classifier.append(nn.AdaptiveAvgPool2d(1))classifier.append(nn.Conv2d(last_bneck_channels, 1280, 1))classifier.append(Hswish(True))classifier.append(nn.Conv2d(1280, nclass, 1))elif mode == 'small':last_bneck_channels = int(576 * width_mult) if width_mult > 1.0 else 576self.layer5 = ConvBNswish(self.in_channels, last_bneck_channels, 1)classifier.append(SEModule(last_bneck_channels))classifier.append(nn.AdaptiveAvgPool2d(1))classifier.append(nn.Conv2d(last_bneck_channels, 1280, 1))classifier.append(Hswish(True))classifier.append(nn.Conv2d(1280, nclass, 1))else:raise ValueError('Unknown mode.')self.classifier = nn.Sequential(*classifier)self.init_weights()def make_layer(self, block, block_setting, width_mult, dilation=1):layers = list()for k, exp_size, c, se, nl, s in block_setting:out_channels = int(c * width_mult)stride = s if (dilation == 1) else 1exp_channels = int(exp_size * width_mult)layers.append(block(self.in_channels, out_channels, exp_channels, k, stride, dilation, se, nl))self.in_channels = out_channelsreturn nn.Sequential(*layers)def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)if m.bias is not None:nn.init.zeros_(m.bias)def forward(self, x):x = self.conv1(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.layer5(x)x = self.classifier(x)x = x.view(x.size(0), x.size(1))return x
参考:
https://blog.csdn.net/Chunfengyanyulove/article/details/91358187
https://arxiv.org/pdf/1905.02244.pdf
