@Team
2018-11-30T09:50:37.000000Z
字数 1795
阅读 2034
干货|(DL~4)对象定位和检测
石文华
文章来自:https://leonardoaraujosantos.gitbooks.io
原文作者:Leonardo Araujo dos Santos
1、介绍
在本章中,我们将学习如何使用卷积神经网络来定位和检测图像上的对象。

RCNN
Fast RCNN
Faster RCNN
YOLO
SSD
2、使用回归定位对象
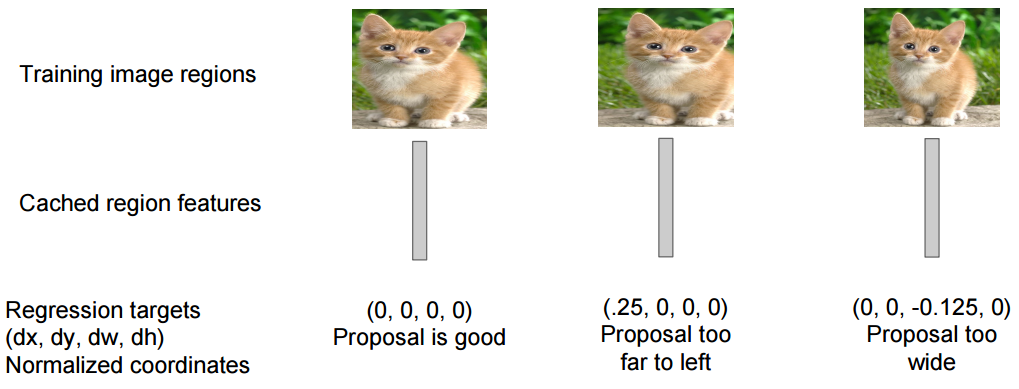
回归返回的是数值数据(实数)而不是类别数据,在例子中,将返回与边界框相关的4个数字(x0,y0,width,height)。使用图像以及它的真实边界框训练目标检测系统,并使用L2距离计算预测边界框与真实边界框之间的损失。

通常,要做的是在最后一个卷积层上附加另一个全连接层(获取也可以使用全局平均池化层)

这样的话只能用于检测一个对象。
3、比较边界框预测的准确率
基本上我们需要比较预测框和真实边界框之间的交并比(IoU)是否大于某个阈值(ex> 0.5)

4、RCNN
RCNN(Regions + CNN)是一种依赖于外部区域提议系统的方法
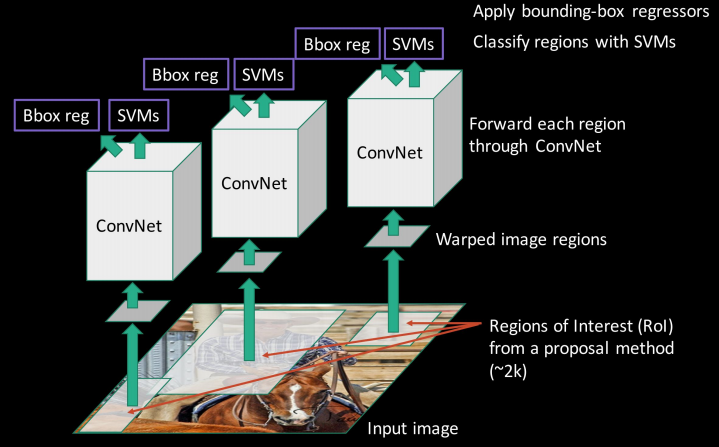
RCNN的问题在于它永远不会变得很快,其训练网络的步骤如下:
1、采取预先训练的imagenet cnn模型(Alexnet,vgg,googleNet,ResNet)
2、使用需要检测的对象+“无对象”类重新训练最后一个全连接层
3、获取所有提议(= ~2000 p / image),调整它们的大小以匹配cnn输入,然后保存到磁盘。
4、训练SVM模型,在对象和背景之间进行分类(每个类一个SVM)
5、边界框回归:训练一个线性回归分类器,它将输出一些校正因子

5、Fast RCNN
Fast RCNN方法从一些外部系统(选择性搜索)接收区域提议。此区域提议的特征图将发送到一个层(Roi Pooling),该层将调整所有区域为固定大小。这是因为全连接层所有输入向量需要具有相同的大小。
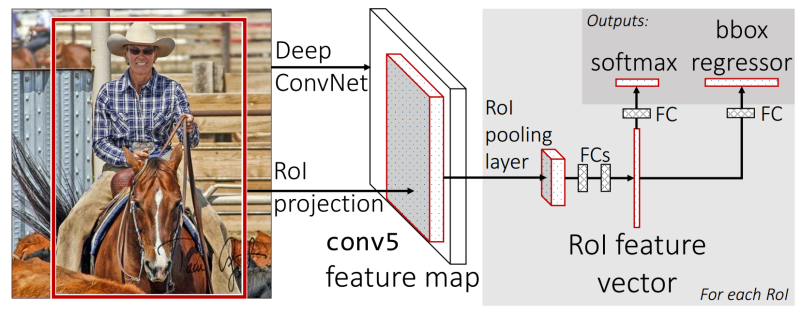
区域提议示例,边界框= [r,x1,y1,x2,y2]


Roi Pooling层
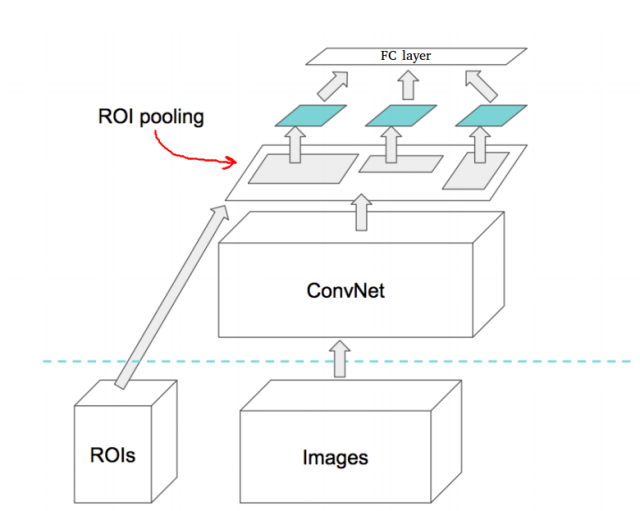
它的作用主要是使不同的区域提议的特征图统一成一样的大小,作为全连接层的输入。因为全连接层网络定义好之后,它的输入维度已经确认,不能改变。
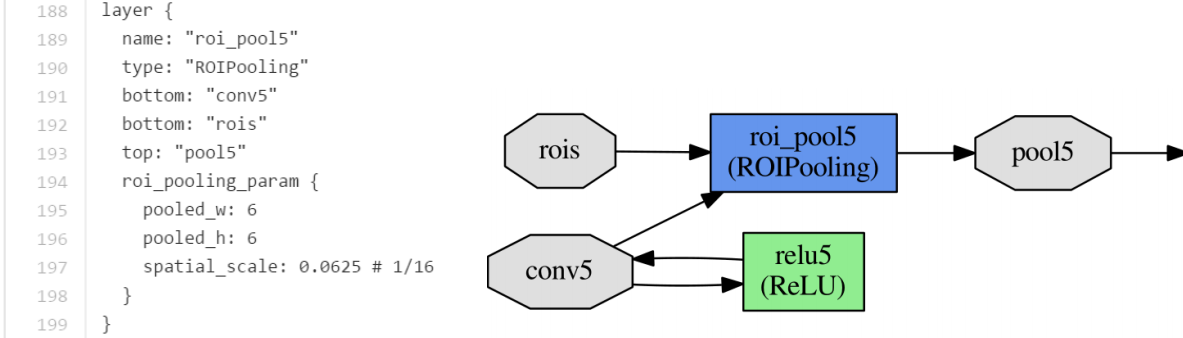
ROI层的输入将是提议区域最后的卷积层激活特征图。例如,考虑以下输入图像及其区域提议。
输入图像:

两题提议区域:

最后一个卷积层的激活(例如:conv5):

对于每个卷积激活(来自上图的每个单元),Roi Pooling层将调整大小,区域提议(红色)将达到全连接层上预期的相同分辨率。例如,将所选单元格视为绿色。
输出将是:


6、Faster RCNN
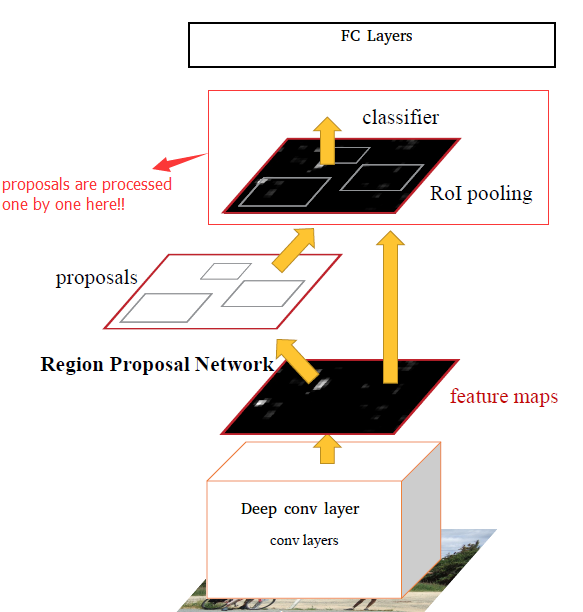
主要思想是使用深层的一些特征图来推断区域提议。
Faster RCNN由两个模块组成。
1、RPN网络(区域提议网络):根据深层的特征图给出一组矩形
2、Fast-RCNN Roi Pooling层:对每个提议的区域进行分类,并优化提议出来的区域的位置。
区域提议网络
1、获得训练过(即imagenet)的卷积神经网络
2、使用使用训练过的模型的卷积层输出的特征图(feature map)
3、训练区域建议网络,该网络将决定图像上是否存在对象,并且还给出框的位置
4、使用ROI池层将所有提议区域重新调整为固定大小后,发送到全连接层以继续分类。

基本上,RPN在feature map上滑动一个小窗口(3x3),将窗口下的特征图分类为对象或非对象,并给出一些边界框位置。
对于每个滑动窗口中心,它创建固定的k锚箱,并将这些箱子分类为对象与否。

Faster RCNN训练
在论文中,每个网络都是单独训练的,但我们也可以联合训练。只考虑模型有4个损失。
1、RPN分类(对象或非对象)
2、RPN边界框提议
3、Fast RCNN分类(普通对象分类)
4、Faster RCNN边界框回归(改进以前的区域框提案)

Faster RCNN结果
resnet 101层模型作为特征提取的Faster RCNN结果如下:

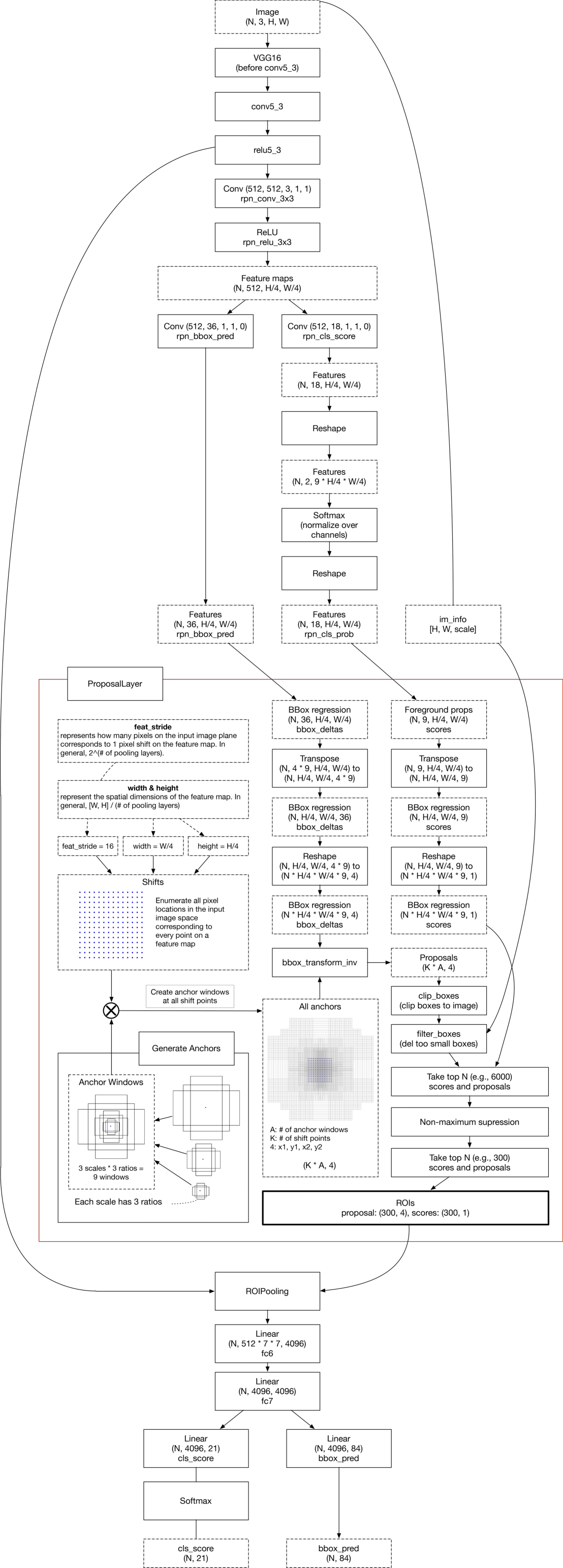
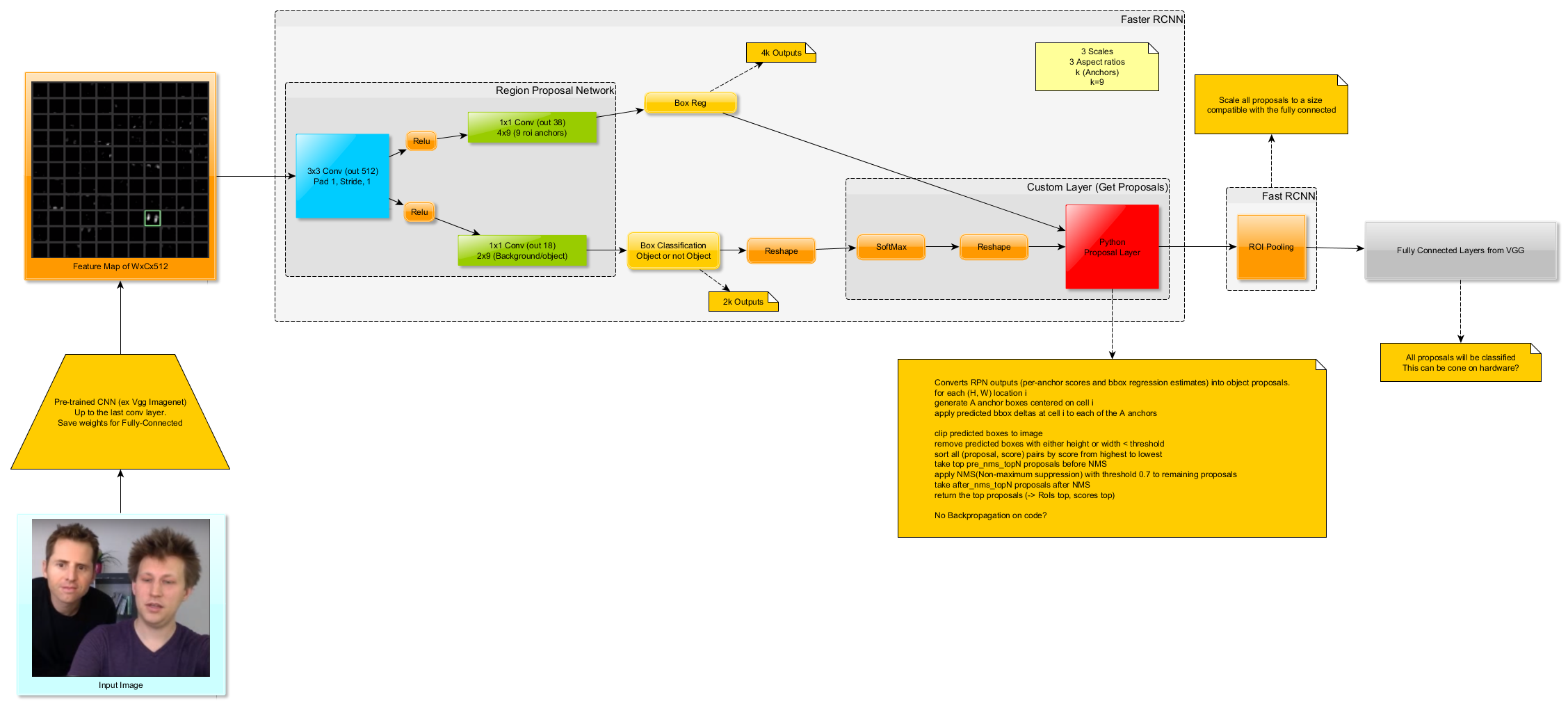
Faster RCNN图
这个图表代表了使用VGG16的Faster RCNN的完整结构,这里找到了一个github项目。它使用一个名为Chainer的框架,它是一个仅使用python(有时是cython)的完整框架。