@Team
2018-11-02T08:13:09.000000Z
字数 4733
阅读 2553
《Computer vision》笔记-GoodLeNet(3)
石文华
GoodLeNet在2014年举办的ILSVRC中获得了分类任务第一名,与同年在分类任务中获得亚军的VGGNet模型相比,它的深度更深,达到22层。该网络引入Inception模块,Inception的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 1*1、3*3 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。。
1、Inception单元结构
最初开始设计的Inception 模块(Native Inception)。它使用 3 个不同大小的滤波器(1x1、3x3、5x5)对输入执行卷积操作,此外它还会执行最大池化。最后将所有子层的输出合并起来,作为输出的特征图。
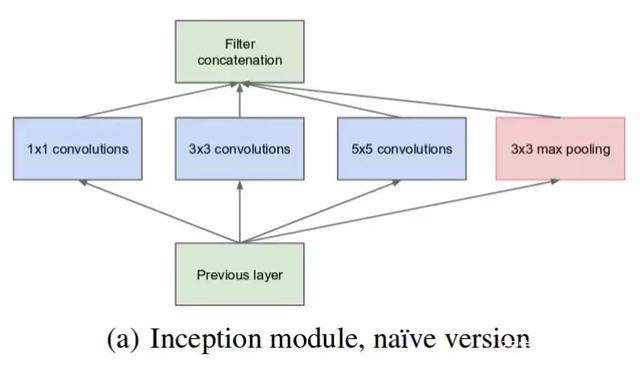
假设输入是28*28*192的特征图。
(1)使用64个1*1卷积核,输出结果会是28*28*64;
(2)使用128个3*3的卷积核,为了使最后不同卷积核得到的特征图合并时维度匹配,padding为same,使得输出维度还是28*28,那么得到的特征图维度是28*28*128.
(3)使用32个5*5的卷积核,padding为same,输出特征图为28*28*32.
(4)使用maxpool,在最大池化之前,设置padding为same。步长为1,然后再进行最大池化,使得输出特征图维度为28*28*192,192个通道数太大,为了避免最后输出时,池化层
占据大多数的通道。使用32个1*1的卷积压缩通道数,最后得到的特征图维度是28*28*32。
将上述输出的特征图叠加在一起,那么最后得到特度特征图大小为28*28*(64+128+32+32),如下图所示:

上述的结构存在一个非常大的问题,就是计算成本特别的大,还是以28*28*192的输入特征图为例子,重点来看5*5的过滤器,由于输出特征图有192个通道,所以一个过滤器的参数为5*5*192。由于期望得到的输出特征图通道为32,长宽为28,所以需要计算28*28*32次。最后乘法运算的总次数为每个输出值所需要执行的乘法运算次数
(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于 1.2 亿(120422400) 。运算成本是非常高的。
解决这个问题的方法就是先使用1*1卷积,压缩通道数,比如像将输入特征图的通道数压缩为16,然后在这个压缩之后的特征图上使用32个5*5的卷积核进行卷积。
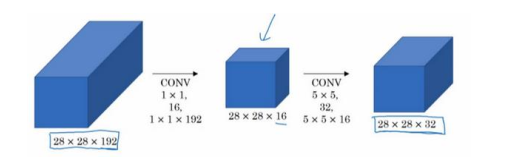
计算量为(1*1*192*28*28*16)+(5*5*16*28*28*32)=2408448+10035200,约等于1204万,相比之前的1.2亿下降到了原来的十分之一。
因此,Native Inception结构使用1*1的卷积之后变为(Inception V1):

利用实现降维的 Inception 模块可以构建 GoogLeNet(Inception v1),其架构如下图所示:

可以发现,网络中间有两个分支,它们是全连接层再加上softmax层,确保了即便是隐藏单元和中间层也参与了特征计算,也能预测图片的分类。它在 Inception 网络中,起到一种调整的效果,并且能防止网络发生过拟合。假设这两个分支的损失值分别是aux_loss_1 ,aux_loss_2,论文中将它们的权重值设置为0.3,从而得到训练时的总损失计算:training.total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2。
2、Inception V2
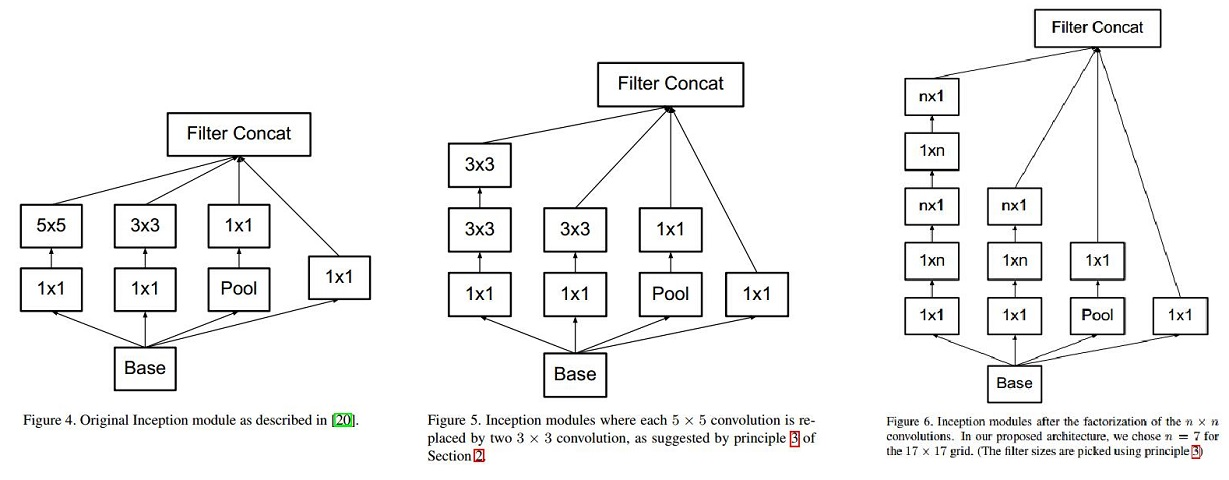
将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度。因为一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍。所以叠加两个 3×3 卷积实际上在性能上会有所提升,将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%。如下图所示:
3、Inception v3
V3整合了前面v2 中提到的所有升级,还使用了RMSProp 优化器、Factorized 7x7 卷积、辅助分类器使用了 BatchNorm;标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合)
注:Inception v4和Inception -resnet可以阅读论文:https://arxiv.org/pdf/1602.07261.pdf
代码:
加载数据:
import torchfrom torchvision import datasets,transformsimport osimport matplotlib.pyplot as pltimport time#transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等。#DataLoader读入的数据类型是PIL.Image#这里对图片不做任何处理,仅仅是把PIL.Image转换为torch.FloatTensor,从而可以被pytorch计算transform = transforms.Compose([transforms.Scale([224,224]),transforms.ToTensor(),#transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])#训练集train_set = datasets.CIFAR10(root='drive/pytorch/inception/', train=True, transform=transform, target_transform=None, download=True)#测试集test_set=datasets.CIFAR10(root='drive/pytorch/inception/',train=False,download=True,transform=transform)trainloader=torch.utils.data.DataLoader(train_set,batch_size=32,shuffle=True,num_workers=0)testloader=torch.utils.data.DataLoader(test_set,batch_size=32,shuffle=True,num_workers=0)classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')(data,label)=train_set[64]print(classes[label])
直接使用Pytorch的models里面预训练好的模型,进行迁移学习,首先先下载模型,然后冻结所有的层,仅对后面全连接层参数进行调整以及后面的AuxLogits和Mixed_7c两个模块的参数更新策略设置为parma.requires_grad=True,允许更新参数,调整之后再进行迁移学习,代码如下:
from torchvision import modelsinceptionv3=models.inception_v3(pretrained=True)import torchimport torch.nn as nnfor parma in inceptionv3.parameters():parma.requires_grad = Falseinceptionv3.fc=nn.Linear(in_features=2048, out_features=10, bias=True)inceptionv3.AuxLogits.fc=nn.Linear(in_features=768, out_features=10, bias=True)for parma in inceptionv3.AuxLogits.parameters():parma.requires_grad=Truefor parma in inceptionv3.Mixed_7c.parameters():parma.requires_grad=True
训练模型:
import torch.optim as optim #导入torch.potim模块import timefrom torch.autograd import Variable # 这一步还没有显式用到variable,但是现在写在这里也没问题,后面会用到import torch.nn as nnimport torch.nn.functional as Foptimizer=torch.optim.Adam(inceptionv3.parameters(),lr=0.0001)epoch_n=5for epoch in range(epoch_n):print("Epoch{}/{}".format(epoch,epoch_n-1))print("-"*10)running_loss = 0.0 #定义一个变量方便我们对loss进行输出running_corrects=0for i, data in enumerate(trainloader, 1): # 这里我们遇到了第一步中出现的trailoader,代码传入inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels#inputs=inputs.permute(0, 2, 3, 1)#print("hahah",len(labels))y_pred = inceptionv3(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了_,pred=torch.max(y_pred.data,1)optimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度loss = cost(y_pred, labels) # 计算损失值,criterion我们在第三步里面定义了loss.backward() # loss进行反向传播,下文详解optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程running_loss += loss.item() # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次running_corrects+=torch.sum(pred==labels.data)if(i % 2 == 0): # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(i,running_loss/i,100*running_corrects/(32*i)))
参考文献:
http://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc
Andrew Ng 《Deep Learning》
https://blog.csdn.net/u014114990/article/details/52583912
