@Team
2019-08-13T04:58:57.000000Z
字数 6877
阅读 1902
《Computer vision》笔记-shufflenet(10)
石文华
1、前言
卷积神经网络在计算机视觉任务中表现优异,但由于嵌入式设备内存空间小,能耗要求低,因此需要使用更加高效的模型。例如,与单纯的堆叠卷积层相比GoogLeNet增加了网络的宽度但降低了复杂度,SqueezeNet在保持精度的同时大大减少参数和计算量,ResNet利用高效的bottleneck结构实现惊人的效果,Xception中提出深度可分卷积概括了Inception序列,MobileNet利用深度可分卷积构建的轻量级模型获得了不错的效果,Senet(取得了 ImageNet 2017 的冠军)引入了一个架构单元对 Channel 之间的信息进行显式建模,它以很小的计算成本提高了性能。而ShuffleNet主要使用了pointwise group convolution(分组的1×1卷积核)代替密集的1×1卷积来减小计算复杂度(因为作者发现,对于resnext中的每个residual unit,1×1卷积(逐点卷积)占据93.4%的运算)。同时为了消除pointwise group convolution带来的副作用,提出了一个新的channel shuffle操作来使得信息能够在特征通道上进行交叉流动,因此shuffleNet在保持原有准确率的条件下大大降低计算量。
2、 分组卷积(group convolution)和通道重排(Channel shuffle)
分组卷积是在通道上采用稀疏连接方式,将特征图在通道上切分为多个组(可以想象成一根甘蔗,横着切成多份),然后通过确保每个卷积只在相应的输入信道组上运行,来减少了计算量。为什么计算量会减少呢。假设input的特征图大小是W*H*C1,output的特征图大小是W*H*C2,卷积核大小为1*1的卷积,那么如果不采用分组卷积的话,卷积的计算量为1*1*C1*C2*W*H,如果采用分组卷积,将特征图按照通道分为g分,那么每一份的大小是W*H*C1/g,由于输出通道最终为C2,所以平分下来每一份单独卷积之后的输出也只需要C2/g个通道就行了,因此对于每一份来说,它的计算量为1*1*C1/g*C2/g*W*H,所以g份总的计算量为g*(1*1* C1/g*C2/g *W*H)=1*1*C1*C2*W*H/g。可以发现,分为g份,计算量就降低到1/g。分组卷积有个缺点就是每个输出通道只能从有限输入通道获得信息,即一个分组的输出只和这个分组的输入有关,阻止通道组之间的信息流的流动,限制了模型表达能力。
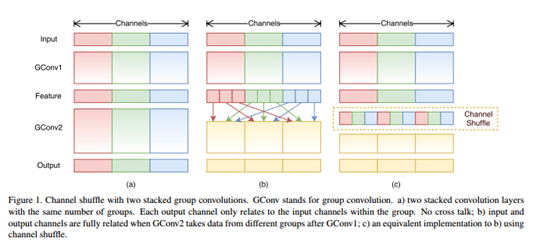
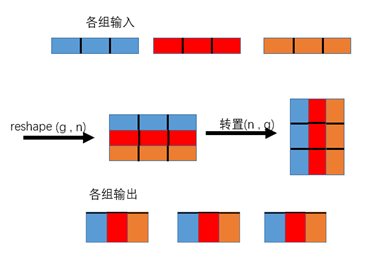
上图表示用两个叠加的分组卷积进行信道shuffle操作。gconv代表分组卷积。a)中两个具有相同组数的叠加卷积层。每个输出通道仅与组内的输入通道相关。没有信息交流;b)中当gconv1之后gconv2从不同分组获取部分通道信息;c)是b)中通道重排的等效实现,将每个 group 分为更小的n个 subgroup,然后将每个 subgroup 输出分散到每个 group 下一层输入。具体来说就是加入 GConv1 有 g x n 个输出通道,则首先将输出通道变维为 (g, n),再转置,最后展开成一维送入下一个层,这样就实现了通道重排,如下所示:
3、ShuffleNet Units
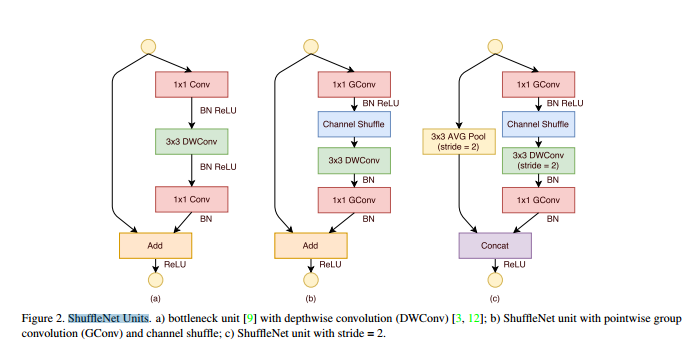
利用channel shuffle操作的优点,提出了一种专为小型网络设计的ShuffleNet unit。从图2(a)中可以看到ShuffleNet unit采用残差单元的设计原理。不同之处在于将之前残差单元分支中的3*3卷积改用为深度可分离卷积(DWConv)。然后,将第一个1×1层替换为1x1的pointwise group convolution(GConv),然后进行channel shuffle操作,形成channel shuffle单元,如图2(b)所示。第二个pointwise group convolution(GConv)的目的是为了恢复通道尺寸使其能够和快捷路径的特征图进行Add运算。为了简单起见,第二个GConv之后没有使用channel shuffle操作。对于带下采样功能的 ShuffleNet unit,参见图2(c):(1)在快捷路径上添加一个3×3的AVG Pool;(2)用concat连接替换元素加操作(Add),从而弥补了分辨率减小而带来的信息损失。
4、模型结构
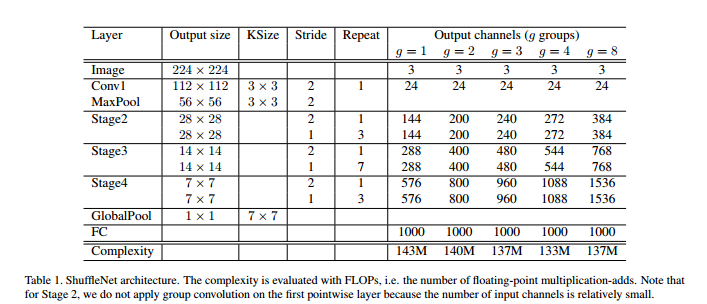
该网络有三个阶段组成,对应的分辨率分别是图中的28,14,7,对应的shuffle util重复次数分别是3,7,3。每个阶段的第一个shuffle util块的步幅为2,同一个阶段下的shuffle util中的其他超参数保持不变,shuffle util的瓶颈通道的数量设置为每个shuffle util单元输出通道的1/4。
5、改进(shufflenet v2)
(1)有效的网络架构设计推导出的一些实用指南:
(Ⅰ)G1:相等的通道宽度可最大限度地降低内存访问成本(MAC);
(Ⅱ)G2:过多的组卷积会增加MAC;
(Ⅲ)G3:网络碎片降低了并行度;
(Ⅳ)G4:逐元素操作的执行时间是不可忽略的;
基于上述指导原则和研究,有效的网络架构应该:
(Ⅰ)使用“平衡卷积"(相等的通道宽度);
(Ⅱ)注意使用组卷积的成本;
(Ⅲ)降低碎片程度;
(Ⅳ)减少逐元素操作。
(2)ShuffleNet V2
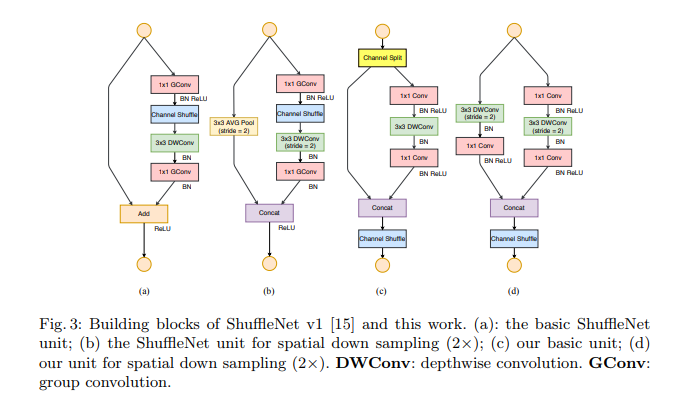
上图(a)(b)是shufflenet v1中的结构,在ShuffleNet v1中采用了两种技术:逐点组卷积和瓶颈状结构。然后引入“channel shuffle”操作以实现不同信道组之间的信息通信并提高准确性。根据指导原则,逐点组卷积和瓶颈结构都会增加MAC(G1和G2),使用太多组违反了G3。在直连通道中进行逐元素相加的操作也是不合需要的(G4)。
因此,为实现高模型容量和效率,关键问题是如何保持大量且同样宽的信道,既没有密集卷积也没有太多组。为了达到上述目的,我们引入了一个名为channel split的简单运算符。如上图(c)所示。在每个单元的开始处,c个特征通道的输入被分成两个分支,分别具有c−c′和c′个通道(为简单起见,c′=c/2)。按照G3,一个分支是恒等函数。另一个分支由三个卷积组成,这三个卷积具有相同的输入和输出通道以满足G1。不同于ShuffleNetV1,两个1×1的卷积不再是分组的了。这部分是为了遵循G2,部分原因是拆分操作已经产生了两个组。卷积后,两个分支连接在一起。因此,通道数保持不变(G1)。然后使用与ShuffleNet V1中相同的“channel shuffle“操作来实现两个分支之间的信息通信。shuffle后,进入了下一个网络块。请注意,ShuffleNet v1中的“Add“操作不再存在。ReLU和depthwise convolutions等元素操作仅存在于一个分支中。此外,三个连续的元素操作,”Concat“,“Channel Shuffle”和”Channel Split“,合并为单个逐元素操作。根据G4,这些更改是有益的。
对于空间下采样,该单元稍作修改,如上图(d)所示。删除了channel split。因此,输出通道的数量加倍。还需要注意的是,shufflenetv2在全局平均池化之前添加额外的1×1卷积层来混合特征。
6、代码:
(1)Conv-Bn-Relu moduule
"""Conv-Bn-Relu moduule"""class ConvBnRelu(nn.Module):def __init__(self,in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,relu6=False):super(ConvBnRelu,self).__init__()self.conv=nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False)self.bn=nn.BatchNorm2d(out_channels)self.relu=nn.ReLU6(inplace=True) if relu6 else nn.ReLU(inplace=True)def forward(self,x):x=self.conv(x)x=self.bn(x)x=self.relu(x)return x
(2)channel_shuffle
def channel_shuffle(x,groups):n,c,h,w=x.size()channels_per_group=c//groupsx = x.view(n, groups, channels_per_group, h, w)x = torch.transpose(x, 1, 2).contiguous()x = x.view(n, -1, h, w)return x
(3)ShuffleNetUtil(V1)
class ShuffleNetUtil(nn.Module):def __init__(self,in_channels,out_channels,stride,groups,dilation=1):super(ShuffleNetUtil,self).__init__()self.stride=stride #步幅self.groups=groups #分组self.dilation=dilation #空洞率assert stride in [1,2,3] #inter_channels=out_channels//4 #瓶颈通道的数量if(stride>1):self.shortcut = nn.AvgPool2d(3, stride, 1)out_channels -= in_channelselif(dilation>1):out_channels-=in_channelsif in_channels==24:g=1else:g=groupsself.conv1=ConvBnRelu(in_channels,inter_channels,1,groups=g)self.conv2=ConvBnRelu(inter_channels,inter_channels,3,stride,dilation,dilation,groups)self.conv3=nn.Sequential(nn.Conv2d(inter_channels, out_channels, 1, groups=groups, bias=False),nn.BatchNorm2d(out_channels))def forward(self,x):out=self.conv1(x) #分组卷积out=channel_shuffle(out,self.groups) #channle shuffleout=self.conv2(out) #深度可分卷积out=self.conv3(out) #分组卷积,不进行激活if self.stride > 1:x = self.shortcut(x) #下采样功能的 ShuffleNet unit中,需要将x的分辨率降低,然后才能concat连接,使用concat连接这样做的目的主要是降低计算量与参数大小out = torch.cat([out, x], dim=1)elif self.dilation > 1: #如果采用空洞卷积的话,也是采用concat的连接方式out = torch.cat([out, x], dim=1)else: #残差块里面如果没有降低分辨率的,连接方式使用加操作(Add)out = out + xout = F.relu(out)return out
(4)DWConv
class DWConv(nn.Module):def __init__(self,in_channels,out_channels,kernel_size,stride=1,padding=0, dilation=1,bias=False):super(DWConv,self).__init__()self.conv=nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding, dilation, groups=in_channels, bias=bias)def forward(self,x):return self.conv(x)
(5)ShuffleNetV2Util
class ShuffleNetV2Util(nn.Module):'''有效的网络架构设计推导出的一些实用指南:(Ⅰ)G1:相等的通道宽度可最大限度地降低内存访问成本(MAC);(Ⅱ)G2:过多的组卷积会增加MAC;(Ⅲ)G3:网络碎片降低了并行度;(Ⅳ)G4:逐元素操作的执行时间是不可忽略的;基于上述指导原则和研究,有效的网络架构应该:(Ⅰ)使用“平衡卷积"(相等的通道宽度);(Ⅱ)注意使用组卷积的成本;(Ⅲ)降低碎片程度;(Ⅳ)减少逐元素操作。'''def __init__(self,in_channels,out_channels,stride,dilation=1):super(ShuffleNetV2Util,self).__init__()assert stride in [1,2,3]self.stride = strideself.dilation = dilationinter_channels = out_channels // 2 #channel splitif(stride>1 or dilation>1):#带下采样的模块,左边的路径的特征图也需要进行相应的下采样,同时也不使用channel splitself.branch1=nn.Sequential(DWConv(in_channels,in_channels,3,stride, dilation, dilation),nn.BatchNorm2d(in_channels),ConvBnRelu(in_channels,inter_channels,1))self.branch2=nn.Sequential(#如果带下采样的模块,右侧的路径有所不同,也就是不需要进行channel splitConvBnRelu(in_channels if (stride > 1) else inter_channels,inter_channels, 1),DWConv(inter_channels,inter_channels,3,stride,dilation, dilation),nn.BatchNorm2d(inter_channels),ConvBnRelu(inter_channels,inter_channels,1))def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)if m.bias is not None:nn.init.zeros_(m.bias)def forward(self,x):if(self.stride==1 and self.dilation==1):#如果不进行下采样,则左路不需要做任何运算x1,x2=x.chunk(2,dim=1)#torch.chunk(input, chunks, dim),与torch.cat()的作用相反。注意,返回值的数量会随chunks的值而发生变化.out=torch.cat((x1, self.branch2(x2)), dim=1)else:out=torch.cat((self.branch1(x), self.branch2(x)),dim=1)out=channel_shuffle(out,2)#参数2表示groups为2组,因为分成两条路径,生成两组特征图return out
参考:
https://mp.weixin.qq.com/s/-AJ3RQK9vpV1rYNk4CLQ_A
https://mp.weixin.qq.com/s/0MvCnm46pgeMGEw-EdNv_w
https://arxiv.org/pdf/1707.01083.pdf
https://arxiv.org/pdf/1807.11164.pdf
