@Team
2018-12-24T13:06:16.000000Z
字数 7427
阅读 7470
Numerical Coordinate Regression=高斯热图 VS 坐标回归
黄海安
论文地址:https://arxiv.org/abs/1801.07372
开源地址:https://github.com/anibali/dsntnn
1 创新点
这篇文章我本人非常喜欢,因为这个问题困扰我很久了,后面会细说。当看到这篇文章的时候我确实蛮激动的,后面发现还有几篇同样思路的论文,看来还是论文看的太少了。
目前的数值坐标回归任务存在于大量的实际需求中,例如人体关键点检测、人脸关键点检测、物体关键点检测和3d姿态,这些问题本质任务都可以归纳为数值坐标回归,故本文研究的是该类问题的一个通用解决办法,不针对具体任务,但为了方便对比,本文还是用人体姿态估计任务来说明。
具体来说目前主流的关键点回归就两种做法:
(1) 采用全连接层直接回归坐标点,例如yolo-v1。该类做法的优点是输出即为坐标点,训练和前向速度可以很快,且是端到端的全微分训练;缺点是缺乏空间泛化能力,也就是说丢失了特征图上面的空间信息。
(2) 采用预测高斯热图方式,然后argmax找出峰值对应的索引即为坐标点,例如cornernet、grid-rcnn和cpn等等。该类做法优点是精度通常高于方法(1);缺点也很明显,从输入到坐标点输出不是一个全微分的模型,因为从heatmap到坐标点,是通过argmax方式离线得到的(其实既然argmax不可导,那就用soft argmax代替嘛,有论文确实是这么做的)。并且由于其要求的输出特征图很大,训练和前向速度很慢,且内存消耗大。
针对上面两种主流方法存在的优缺点,我们是否可以设计一个模型,同时具备方法(1)的全微分训练,也具备(2) 的空间泛化能力。故本文设计了一个differentiable spatial to numerical transform(DSTN)模块来弥补两着的gap,并且设计的模块是没有训练参数的,可以在低分辨率高斯图上预测,主要作用就是让梯度流可以从坐标点流到高斯热图上,而不增加额外参数和计算量。
2 核心思想
首先需要对上面所提到的两种主流方案进行深入分析。
(1) 全连接直接回归坐标点
前面提到了空间泛化这个词,空间泛化是指模型训练期间在一个位置获得的知识在推理阶段推广到另一个位置的能力 ,举例来说,如果我在训练阶段有一个球一直在图片左上角,但是测试阶段球放在了右下角了,如果网络能够检测或者识别出来,那么就说该模型具备空间泛化能力。可以看出坐标点回归任务是非常需要这种能力的,因为我不可能每一个位置的图片都训练到。全卷积模型具备这种能力的原因是权重共享,然而对于全连接层,在2014年的Network in network论文指出fully connected layers are prone to overfitting, thus hampering the generalization ability of the overall network。也就是说如果采用全连接输出坐标点方式是会极大损害空间泛化能力的,其实从理论上也很容易分析出来:在训练阶段有一个球一直在图片左上角,reshape拉成一维向量后,全连接层的激活权重全部在上半部分,而下半部分的权重是没有得到训练的,当你测试时候输入一张球放在了右下角图片,拉成一维向量后,由于下半部分权重失效,理论上是预测不出来的,即没有空间泛化能力。而卷积操作由于权重共享,是可以有效避免的。总结一下:全连接方式所得权重严重依赖于训练数据的分布,非常容易造成过拟合,这个现象我在做关键点项目预测时候发现确实很严重。
(2) 预测高斯热图
这种方法在人体姿态估计领域是主要方法,几乎目前所有新的模型输出都是高斯热图。以单人姿态估计为例,输出是一张仅仅包含一个人的图片,输入是所有关键点的高斯热图,label是基于每个关键点生成的高斯图。如果每个人要回归17个关键点,那么预测输出特征图是(batch,h_o,w_o,17),即每个通道都是预测一个关节点的热图,然后对每个通道进行argmax即可得到整数型坐标。
前面说过基于高斯热图输出的方式会比直接回归坐标点精度更高,原因并不是高斯热图输出方式的表达好,而是由于其输出特征图较大,空间泛化能力较强导致的,那么自然能解释如果我依然采用(1)直接回归坐标的方法预测,但是我不再采用全连接,而是全卷积的方式依然会出现精度低于高斯热图的现象,原因是即使全卷积输出,但是像yolo-v2、ssd等其输出特征图很小,导致空间泛化能力不如方法(2)。
单从数值上来看,肯定是直接回归坐标点方式好啊,因为直接回归坐标点的话,输出是浮点数,不会丢失精度,而高斯热输出肯定是整数,这就涉及到一个理论误差下界问题了。假设输入图片是512x512,输出是缩小4倍即128x128,那么假设一个关键点位置是507x507,那么缩小4倍后,即使没有任何误差的高斯热图还原,也会存在最大507-126*4=3个像素误差,这个3就是理论误差下界。如果缩小倍数加大,那么理论误差下界还会上升。所以目前大部分做法折中考虑速度和精度,采用缩小4倍的方式。
高斯热图回归的loss一般都是mse,这就会出现另一个问题。
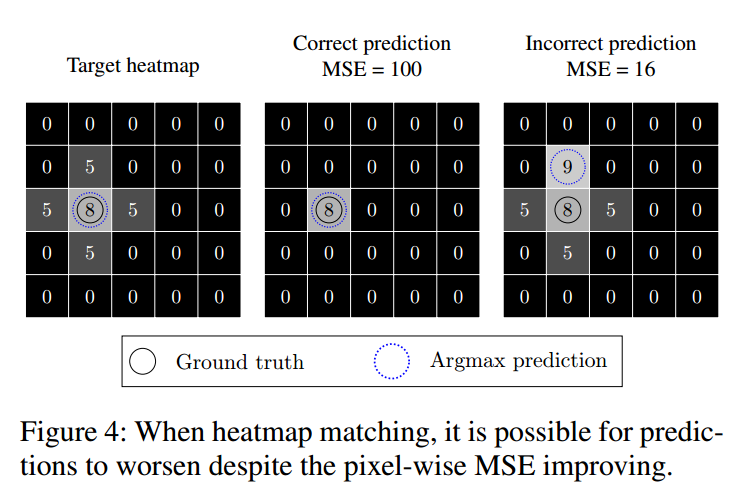
第一幅图是target热图,第二副和第三副图是假设预测出来的两种情况,正常情况下,第二副预测的更准,但是实际上如果采用mse loss,那么第三副图的loss比第二副小,这就出现问题了,会导致预测的关键点是不准确的。
总结一下,虽然高斯热图预测的精度通常高于回归的方法,但是其存在几个非常麻烦的问题:(1) 输出图很大,导致内存占用多、推理和训练速度慢;(2) 存在理论误差下界;(3) mse loss可能会导致学习出来的结果出现偏移;(4) 不是全微分模型;
作者设计的整体流程如下:
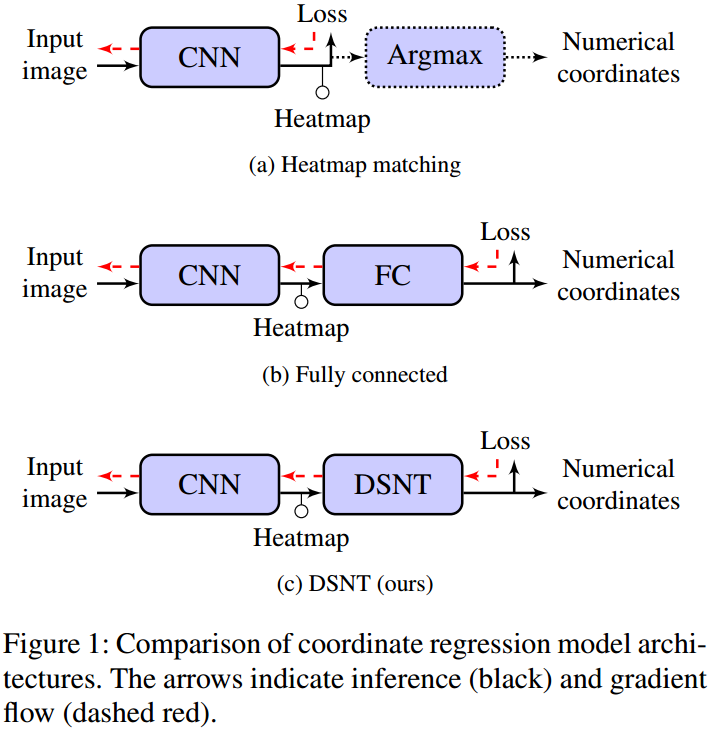
(a)是目前主流做法,可以看出梯度流不是端到端的;(b)是在高斯热图后面连接一个全连接层来直接回归关键点坐标,梯度流是端到端的;(c) 作者提出的DSNT模块做法。
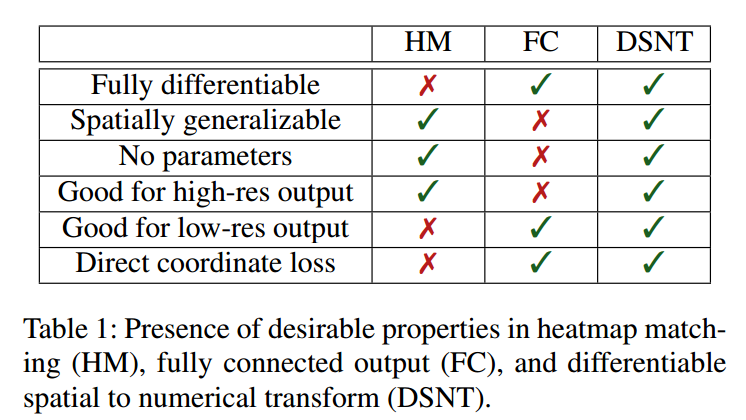
可以看出,方式(a)缺点是不是全微分,低分辨率输出情况下精度较低;(b)的缺点是丢失了空间泛化能力,非常容易过拟合,高分辨率情况下精度不行;而(c)具备了全部优点,个人觉得最大优点是可以在低分辨率情况下得到近似相同精度的结果。实验结果表明,如果CNN模型是ResNet-34,在后面接一个DSNT模块和不接情况下,当输出热图是 7 × 7 pixel时,带DSNT的精度优于不带的90.5%,当输出热图是56x56 pix时候,优于2.0%。也就是说本文方法主要优势是可以进行低分辨率高斯热图预测。

前面分析了半天全卷积的好处,那么自然我们的输出也是采用全卷积方式,并且在全卷积特征图后面接DSNT模块,将空间高斯热图转换为坐标点。本文设计和目前高斯热图预测主要区别是我们并不是强制要求一个loss直接作用到高斯预测热图上,(b)的label就是强制Loss学习到高斯热图,loss直接作用在输出特征图上,而本文采用的是(c),通过优化整个模型输出的预测坐标的损失来间接学习热图,也就是loss是基于预测关键点和真实关键点的,热图的学习完全是网络自发的(也不算自发,加了正则),这就是本文和其他常用做法的最主要区别了,后面会细说。
3 网络结构
下面开始讨论具体实现。首先明确DSNT模块的输入和输出,假设CNN原图输入是(batch,h,w,3),输出是(batch,h//4,w//4,17)表示17个关键点回归,用表示,DSNT作用在每一个通道上,输出是(batch,17,2)表示17个关键点的x,y坐标。
(1) 对每一个通道输出的高斯热图进行normalized,定义为。
忽略归一化分母,可以表示为,作者设计了4种normalized手段,具体为:

可以看出,选择不同的归一化手段,最终结果差距不大,但是由于表中softmax手段优异一些,故作者选择了softmax作为normalized函数。
为啥要归一化到0~1呢?是因为作者希望DSNT输入是一个离散概率分布,后面有用。
(2) 转换为坐标点
先定义两个矩阵X和Y,其宽高和输入DSNT的宽高一致,其具体数值计算为:
,这里m=宽,n=高,这样的做法可以将X和Y坐标值scale到(-1,1)之间。一个特殊实例如下:
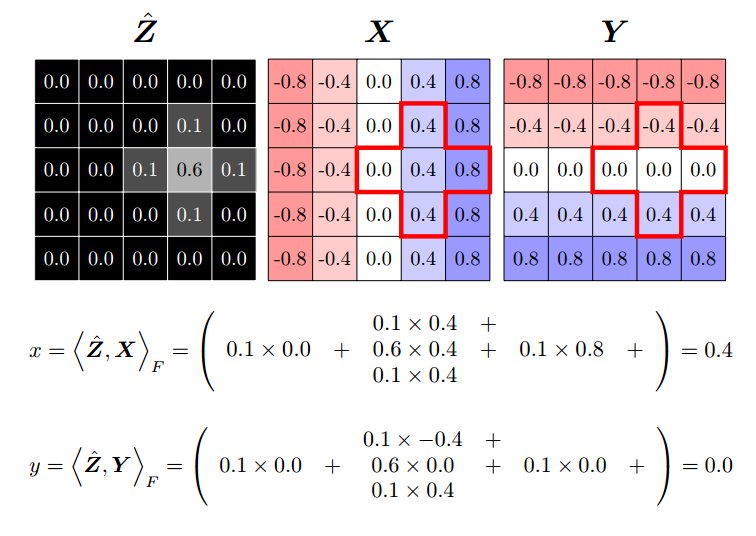
可以看出,x坐标实际上就是和X矩阵进行F范数结果,y坐标实际上就是和Y矩阵进行F范数结果(F范数是欧式空间二范数的推广,计算方法就是逐元素点乘)。可以看出,如果归一化的高斯热图只有一个峰值,那么采用这种变换手段可以直接得到坐标点。这个变换过程就是本文的核心。
好了,由于是0~1,且和为1,那么满足概率分布条件,故可以写成:
c是某一个通道的输出坐标,2个值,上式就是随机变量X和Y的联合概率分布。仔细观察可以发现,通过DSNT变换后得到的2个坐标点,其实就是上述联合分布的均值,写成:
如果大家忘记了均值咋算,那么我贴一张图:

总结,经过上述两步骤后,得到如下汇总式子:
注意看:虽然我们前面都是假设DSNT的输入是高斯热图,但是实际上目前我们没有加入任何先验,让网络学习到高斯热图性质,但是我们仔细看X和Y值,可以看出,在关键点中心点处,X值关于X轴对称,Y值关于Y轴对称,这样的对称属性对生成高斯热图有一定的帮助,网络会倾向于学习出左右和上下对称的热图。如下图所示:

(a)是输入图片,(b)是常用的高斯热图预测额label,而(c)是本文设计的没有加任何高斯约束自动学习出来的热图,虽然和高斯热图还有些差距,但是基本满足关于中心点对称的属性。
作者试图分析了一个问题:没有任何高斯约束的网络训练会不会非常容易受到外点影响,导致训练不稳定?因为一旦预测的热图由max外点干扰,那么后面的DSNT模块肯定就变换错误了,作者说不会,因为在训练时候如果出现这种现象,那么就导致一个非常大的Loss,促使网络慢慢去掉外点干扰。
好了前面基本就讲完了整个网络结构了。下面开始分析Loss。
loss设计就比较简单了,由于是坐标点回归,那么一个非常自然的loss肯定是误差平方和,即:
p是label,是DSNT模块输出值。
我希望大家能知道为何这里的Loss只是两个点之间的二范数而已,但是梯度却是作用在了整个热图上面,原因是这个输出的预测值其实是均值,而对均值有贡献的位置是整个图,故梯度反向时候会作用在整个热图上。
如果仅仅上面这个Loss肯定是可以work的,但是如果没有加入任何约束,那么会出现同一个关键点会产生各种形状的热图,虽然对我们的最终结果没有影响,但是总感觉过于自由了。例如网络可能会学出一种非常大方差和非常小方差的高斯热图,从稳定性方面考虑,那么在实际情况下,我们肯定是需要小方差的高斯热图,而且在实验中发现认为引入一些先验是有助于网络训练的。故我们还要探讨如何加入先验。
加入先验的一种最简单最直接做法就是正则Loss,故我们可以对正则项引入高斯热图先验。总体loss为:
(1) 方差正则
第一种可以想到的正则是控制方差,前面说过我们希望学出高斯热图,且方差要小,那么很自然我们可以写成:
第一个式子是计算方差,只和预测出来的坐标有关,第二个是最终的方差正则项,通过给予x和y方向同样大小的方差约束,就有助于学习出高斯热图。
(2) 分布正则
其实容易想到另一种更好的正则。你希望的不就是要得到高斯热图吗?那么由于你已经变换到了概率分布中,那么我希望他的输出分布是二元高斯,那么肯定用KL散度啊,KL散度大量用于衡量两个分布相似性上,在GAN中应用超级广泛。那么我们有:
是二元高斯分布,这样的设计就可以强制网络学到高斯热图。由于KL散度有:1.永远大于等于0,但是不一定小于1; 2.非对称性,故作者引入了更好的KL散度变种:Jensen-Shannon,其是KL散度的变体,值域范围是0~1,且是对称的。
其实我们可以换一个角度考虑,例如SVM Loss一样,我们可以认为坐标预测的loss是正则Loss,而分布正则的loss是主Loss,从这个角度来看,那么本论文所提方法其实和原始的直接高斯热图回归做法并无不同,还是直接回归高斯热图,不过额外增加了一个坐标回归正则项,为了能得到坐标点,引入了DSNT模块而已。
作者通过实验对比,结果如下:
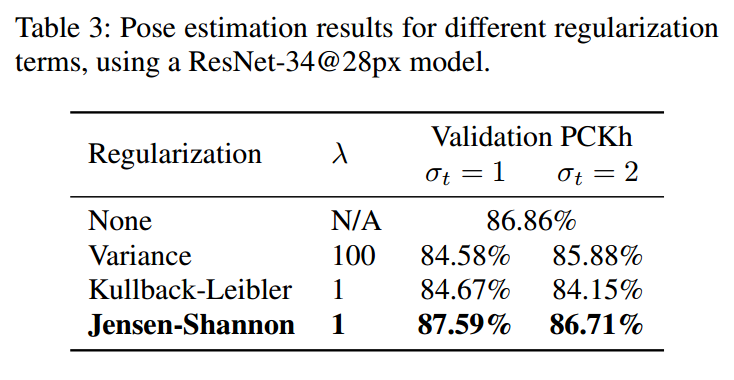
可以看出JS更好一些,故最终最终选择的正则是JS分布正则。

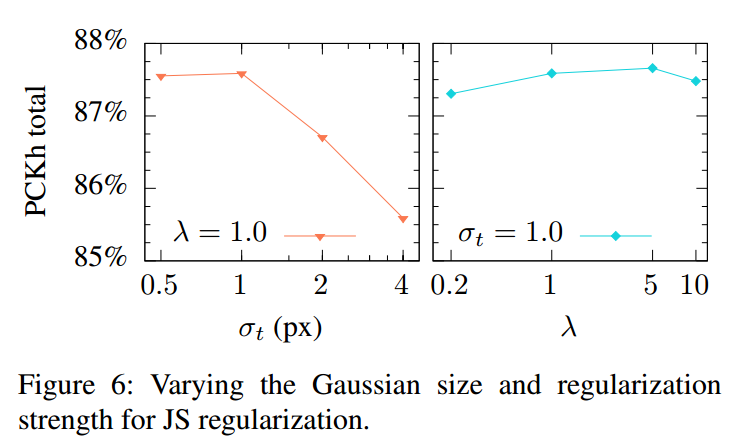
上图是在不同的方差大小情况下学习出的热图形状,可以看出JS正则的效果不错,但是可以看出方差影响很大,这个在具体项目中非常关键,需要小心设计。还可以看出在方差正则中,由于只是限制了方差相等,均值为0,故他无法直接学习出高斯热图,而是将热图分成关节周围的四个斑点。
4 实验
作者设计了2组对比实验,分别是ResNet,通过空洞卷积后,输出热图大小是14x14pix,和Stacked hourglass。输出热图大小是64x64pix。
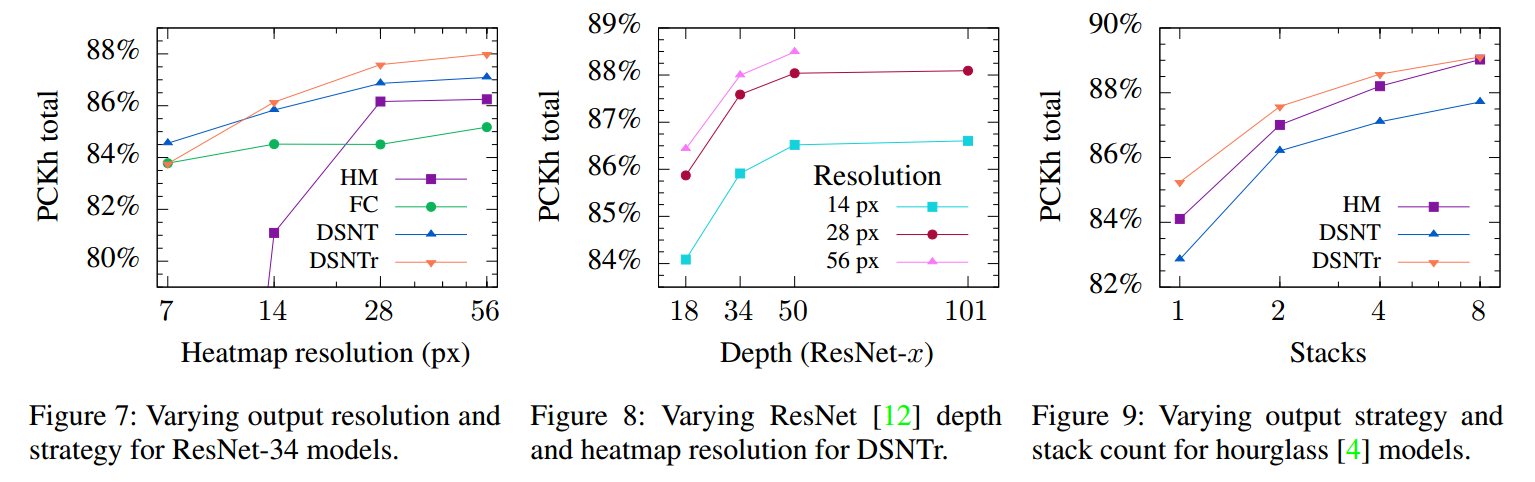
DSNTr是指带正则。先看左图,本文设计的DSNT模块在低分辨率输出情况下有压倒性优势,当高分辨率输出时候依然会好一点,这个好一点应该是弥补理论误差下界导致的,也就是说在高分辨率输出时候优势不大;再看中间图,随着网络深度加深,并不是一直直线上升的,在resnet-50和resnet-101情况下精度几乎没有提升;再看右图,stack的数目增加,精度也可以增加,说明这种网络结构还是不错的。总体而已,加了正则的DSNT方法始终都是最好的。
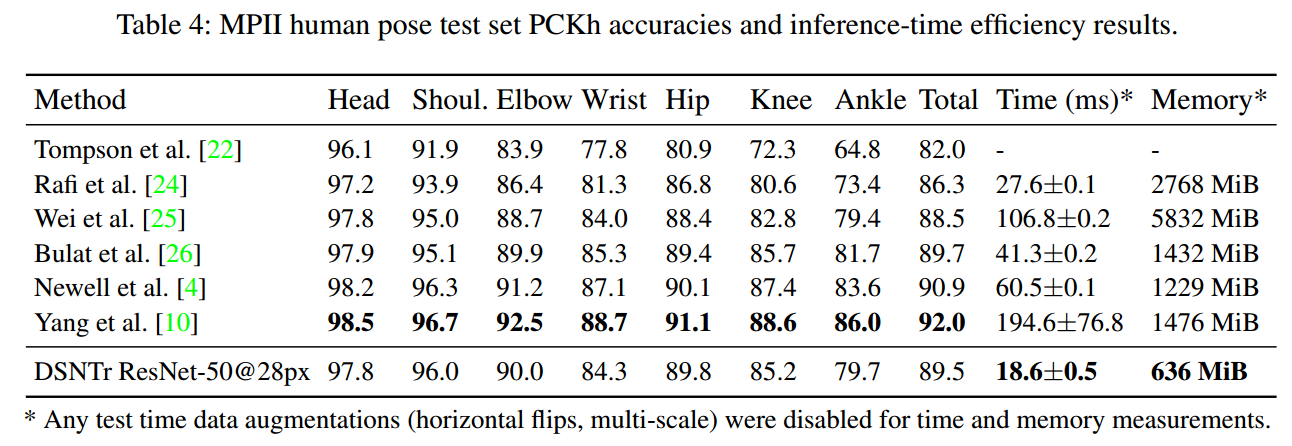
上表可以看出,我们采用了28x28的输出,精度依然非常高,且速度和内存占用都是最小的。
还有一些实验细节,我就不写了,大家有兴趣的可以自己看原文。
5 扩展
纵观全文,感慨颇多。因为我在做关键点热图预测时候,始终无法有效克服这个理论误差下界问题,我的解决办法是:(1)生成高斯热图时候不进行过度量化操作;(2) 图片的裁剪缩放比例不变,而是通过padding来确保输入图片一致;(3) 输出是输入的1/2。通过这些手段,我可以控制理论误差下界低于1个pix,但是依然没有解决本质问题。然后我参考MultiPoseNet做法,尝试了FC,但是如前面所示,非常容易过拟合,主要原因是FC的输入是高斯图,样本过于简单。
其实据我所知,还有一种办法可以克服理论误差下界问题,那就是cornernet做法,学习一个offset,这个offset其实就是误差下界,通过对预测值加上offset,一样是可以有效解决的。
但是目前高斯热图预测的做法最大问题是速度太慢,内存占用太多。而本文的做法在低分辨率情况下依然可以达到很高的精度,这点是我最喜欢的。这样的优点就可以让我将关键点回归和目标检测任务合并输出,同时完成两个任务,如果没有本文做法,由于高斯热图预测需要大分辨率图,而目标检测都是小分辨率图,这个就矛盾了,效果就不太好。
其实高斯热图回归还有一个问题,我暂时不知道如果采用本文预测方式能不能避免,我要做实验才能发现。那就是当关键点和关键点之间的可区分性比较低时候,预测很容易失败,表现为一个输出通道上出现多个高斯峰值,此时argmax就会导致关键点定位失败。目前我的做法就只是让网络充分训练,或者加可判别性特征,或者加可区分的正则loss;或者加强通道间交流例如自注意力机制和grid rcnn做法。
当然如果关键点出现遮挡时候,本文应该也很难有效应对吧。
前面说过,将热图输出转换为回归输出不只是本文这一种做法,还有几篇优秀的问题,后面有空在分析,列表如下:
欢迎交流
