@Team
2019-04-07T02:56:43.000000Z
字数 4711
阅读 5672
人人必须要知道的语义分割模型:DeepLabv3+
叶虎
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类,如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。

图1 街景分割
图像分割可以分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),其区别如图2所示。
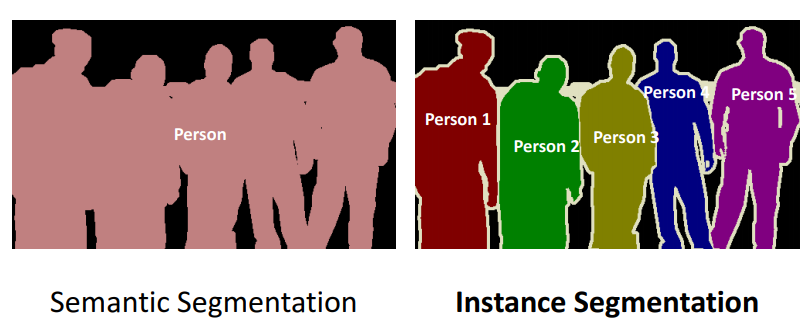
图2 图像分割中的语义分割和实例分割
可以看到语义分割只是简单地对图像中各个像素点分类,但是实例分割更进一步,需要区分开不同物体,这更加困难,从一定意义上来说,实例分割更像是语义分割加检测。这里我们主要关注语义分割。
与检测模型类似,语义分割模型也是建立是分类模型基础上的,即利用CNN网络来提取特征进行分类。对于CNN分类模型,一般情况下会存在stride>1的卷积层和池化层来降采样,此时特征图维度降低,但是特征更高级,语义更丰富。这对于简单的分类没有问题,因为最终只预测一个全局概率,对于分割模型就无法接受,因为我们需要给出图像不同位置的分类概率,特征图过小时会损失很多信息。其实对于检测模型同样存在这个问题,但是由于检测比分割更粗糙,所以分割对于这个问题更严重。但是下采样层又是不可缺少的,首先stride>1的下采样层对于提升感受野非常重要,这样高层特征语义更丰富,而且对于分割来说较大的感受野也至关重要;另外的一个现实问题,没有下采样层,特征图一直保持原始大小,计算量是非常大的。相比之下,对于前面的特征图,其保持了较多的空间位置信息,但是语义会差一些,但是这些空间信息对于精确分割也是至关重要的。这是语义分割所面临的一个困境或者矛盾,也是大部分研究要一直解决的。
对于这个问题,主要存在两种不同的解决方案,如图3所示。其中a是原始的FCN(Fully Convolutional Networks for Semantic Segmentation),图片送进网络后会得到小32x的特征图,虽然语义丰富但是空间信息损失严重导致分割不准确,这称为FCN-32s,另外paper还设计了FCN-8s,大致是结合不同level的特征逐步得到相对精细的特征,效果会好很多。为了得到高分辨率的特征,一种更直观的解决方案是b中的EncoderDecoder结构,其中Encoder就是下采样模块,负责特征提取,而Decoder是上采样模块(通过插值,转置卷积等方式),负责恢复特征图大小,一般两个模块是对称的,经典的网络如U-Net(U-Net: Convolutional Networks for Biomedical Image Segmentation。而要直接将高层特征图恢复到原始大小是相对困难的,所以Decoder是一个渐进的过程,而且要引入横向连接(lateral connection),即引入低级特征增加空间信息特征分割准确度,横向连接可以通过concat或者sum操作来实现。另外一种结构是c中的DilatedFCN,主要是通过空洞卷积(Atrous Convolution)来减少下采样率但是又可以保证感受野,如图中的下采样率只有8x,那么最终的特征图语义不仅语义丰富而且相对精细,可以直接通过插值恢复原始分辨率。天下没有免费的午餐,保持分辨率意味着较大的运算量,这是该架构的弊端。这里介绍的DeepLabv3+就是属于典型的DilatedFCN,它是Google提出的DeepLab系列的第4弹。
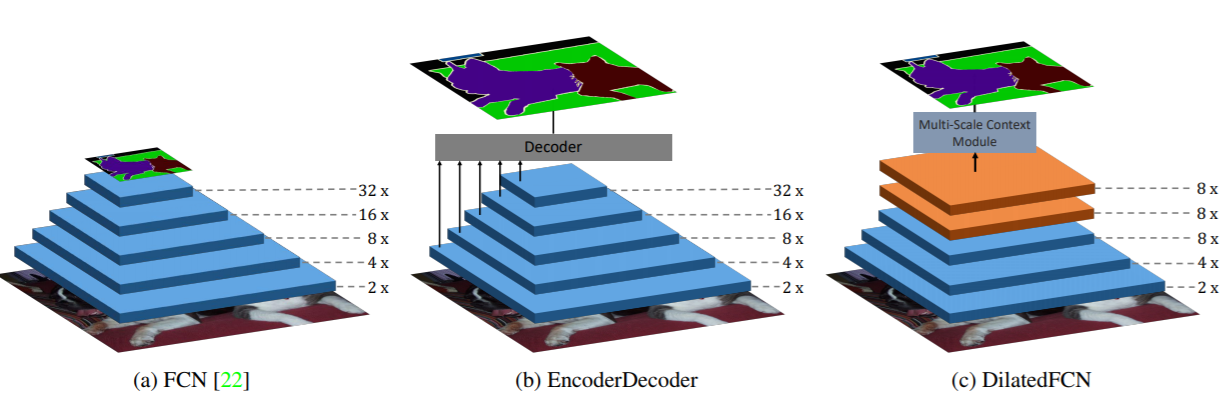
图3 语义分割不同架构(来源:https://arxiv.org/abs/1903.11816)
整体架构
DeepLabv3+模型的整体架构如图4所示,它的Decoder的主体是带有空洞卷积的DCNN,可以采用常用的分类网络如ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),主要是为了引入多尺度信息;相比DeepLabv3,v3+引入了Decoder模块,其将底层特征与高层特征进一步融合,提升分割边界准确度。从某种意义上看,DeepLabv3+在DilatedFCN基础上引入了EcoderDecoder的思路。
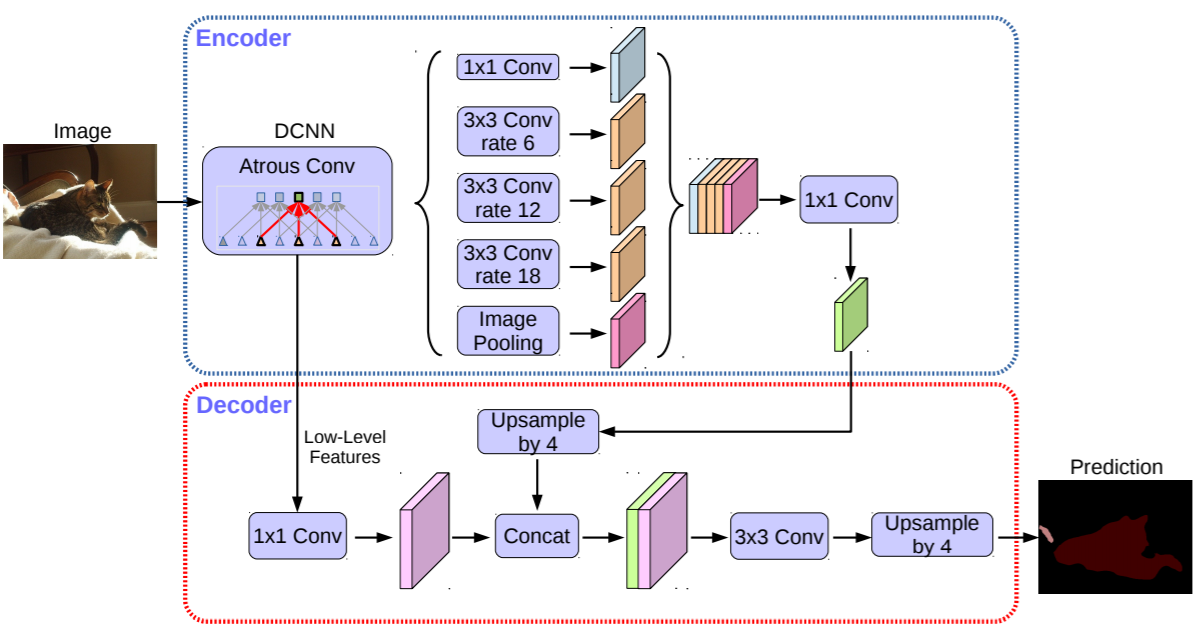
图4 DeepLabv3+模型的整体架构
对于DilatedFCN,主要是修改分类网络的后面block,用空洞卷积来替换stride=2的下采样层,如下图所示:其中a是原始FCN,由于下采样的存在,特征图不断降低;而b为DilatedFCN,在第block3后引入空洞卷积,在维持特征图大小的同时保证了感受野和原始网络一致。
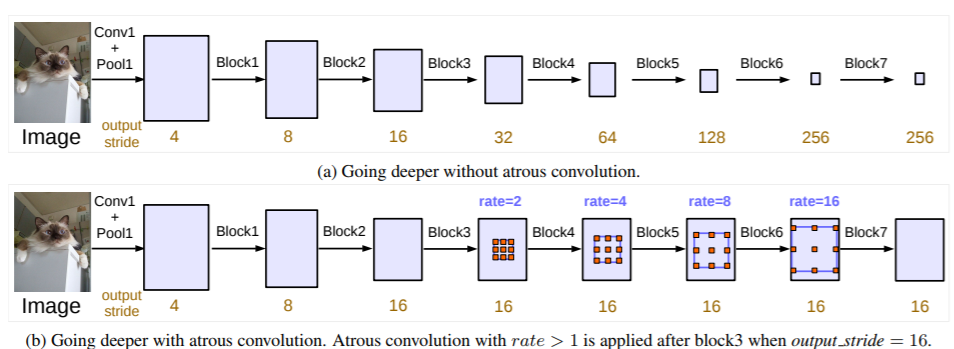
图5 DilatedFCN与传统FCN对比
在DeepLab中,将输入图片与输出特征图的尺度之比记为output_stride,如上图的output_stride为16,如果加上ASPP结构,就变成如下图6所示。其实这就是DeepLabv3结构,v3+只不过是增加了Decoder模块。这里的DCNN可以是任意的分类网络,一般又称为backbone,如采用ResNet网络。

图6 output_stride=16的DeepLabv3结构
空洞卷积
空洞卷积(Atrous Convolution)是DeepLab模型的关键之一,它可以在不改变特征图大小的同时控制感受野,这有利于提取多尺度信息。空洞卷积如下图所示,其中rate(r)控制着感受野的大小,r越大感受野越大。通常的CNN分类网络的output_stride=32,若希望DilatedFCN的output_stride=16,只需要将最后一个下采样层的stride设置为1,并且后面所有卷积层的r设置为2,这样保证感受野没有发生变化。对于output_stride=8,需要将最后的两个下采样层的stride改为1,并且后面对应的卷积层的rate分别设为2和4。另外一点,DeepLabv3中提到了采用multi-grid方法,针对ResNet网络,最后的3个级联block采用不同rate,若output_stride=16且multi_grid = (1, 2, 4), 那么最后的3个block的rate= 2 · (1, 2, 4) = (2, 4, 8)。这比直接采用(1, 1, 1)要更有效一些,不过结果相差不是太大。

图7 不同rate的空洞卷积
空间金字塔池化(ASPP)
在DeepLab中,采用空间金字塔池化模块来进一步提取多尺度信息,这里是采用不同rate的空洞卷积来实现这一点。ASPP模块主要包含以下几个部分:
(1) 一个1×1卷积层,以及三个3x3的空洞卷积,对于output_stride=16,其rate为(6, 12, 18) ,若output_stride=8,rate加倍(这些卷积层的输出channel数均为256,并且含有BN层);
(2)一个全局平均池化层得到image-level特征,然后送入1x1卷积层(输出256个channel),并双线性插值到原始大小;
(3)将(1)和(2)得到的4个不同尺度的特征在channel维度concat在一起,然后送入1x1的卷积进行融合并得到256-channel的新特征。
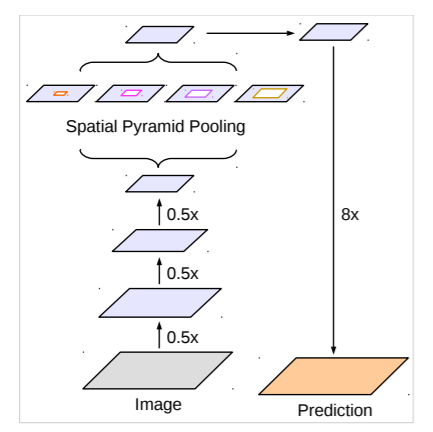
图8 DeepLab中的ASPP
ASPP主要是为了抓取多尺度信息,这对于分割准确度至关重要,一个与ASPP结构比较像的是[PSPNet](Pyramid Scene Parsing Network)中的金字塔池化模块,如下图所示,主要区别在于这里采用池化层来获取多尺度特征。

图9 PSPNet中的金字塔池化层
此外作者在近期的文章(Searching for Efficient Multi-Scale Architectures for Dense Image Prediction)还尝试了采用NAS来搜索比ASPP更有效的模块,文中称为DPC(Dense Prediction Cell),其搜索空间包括了1x1卷积,不同rate的3x3空洞卷积,以及不同size的平均池化层,下图是NAS得到的最优DPC,这是人工所难以设计的。
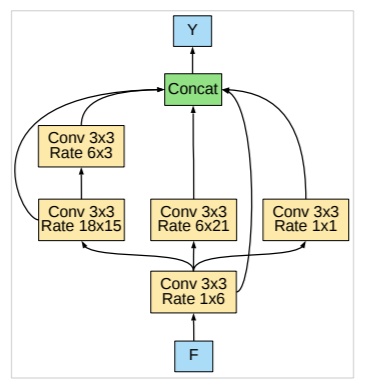
图10 最优DPC
Decoder
对于DeepLabv3,经过ASPP模块得到的特征图的output_stride为8或者16,其经过1x1的分类层后直接双线性插值到原始图片大小,这是一种非常暴力的decoder方法,特别是output_stride=16。然而这并不利于得到较精细的分割结果,故v3+模型中借鉴了EncoderDecoder结构,引入了新的Decoder模块,如下图所示。首先将encoder得到的特征双线性插值得到4x的特征,然后与encoder中对应大小的低级特征concat,如ResNet中的Conv2层,由于encoder得到的特征数只有256,而低级特征维度可能会很高,为了防止encoder得到的高级特征被弱化,先采用1x1卷积对低级特征进行降维(paper中输出维度为48)。两个特征concat后,再采用3x3卷积进一步融合特征,最后再双线性插值得到与原始图片相同大小的分割预测。
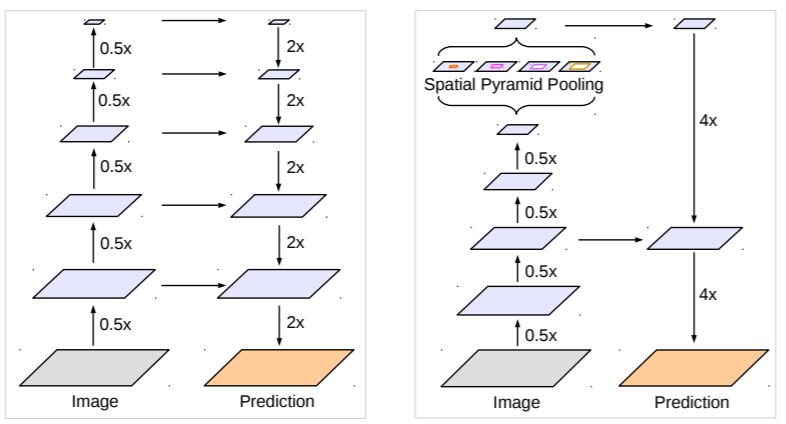
图11 DeepLab中的Decoder
改进的Xception模型
DeepLabv3所采用的backbone是ResNet网络,在v3+模型作者尝试了改进的Xception,Xception网络主要采用depthwise separable convolution,这使得Xception计算量更小。改进的Xception主要体现在以下几点:
(1)参考MSRA的修改(Deformable Convolutional Networks),增加了更多的层;
(2)所有的最大池化层使用stride=2的depthwise separable convolutions替换,这样可以改成空洞卷积 ;
(3)与MobileNet类似,在3x3 depthwise convolution后增加BN和ReLU。
采用改进的Xception网络作为backbone,DeepLab网络分割效果上有一定的提升。作者还尝试了在ASPP中加入depthwise separable convolution,发现在基本不影响模型效果的前提下减少计算量。

图12 修改的Xception网络
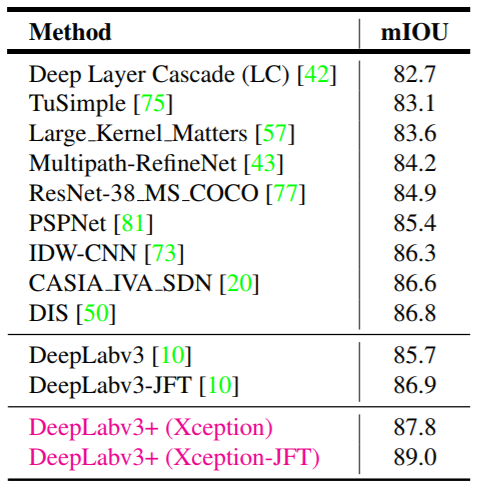
结合上面的点,DeepLabv3+在VOC数据集上的取得很好的分割效果:
关于DeepLab模型的实现,Google已经开源在tensorflow/models,采用Google自家的slim来实现的。一点题外话是,作者最近有研究了NAS在分割网络的探索,叫做Auto-DeepLab(Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation),不同于前面的工作,这个真正是网络级别的NAS,其搜索空间更大。
小结
DeepLab作为DilatedFCN的典范还是值得学习的,其分割效果也是极其好的。但是由于存在空洞卷积,DeepLab的计算复杂度要高一些,特别是output_stride=8,对于一些要求低延迟的场景如无人车,还是需要更加轻量级的分割模型,这也是近来的研究热点。
