@Team
2018-01-12T07:17:43.000000Z
字数 1876
阅读 3584
LSTM文本分类实战
lstm nlp
什么是文本分类
文本分类在文本处理中是很重要的一个模块,它的应用也非常广泛,比如:垃圾过滤,新闻分类,等等。传统的文本分类方法的流程基本是:1.预处理:首先进行分词,然后是除去停用词;2.将文本表示成向量,常用的就是文本表示向量空间模型;3.进行特征选择,这里的特征就是词语,去掉一些对于分类帮助不大的特征。常用的特征选择的方法是词频过滤,互信息,信息增益,卡方检验等;4.接下来就是构造分类器,在文本分类中常用的分类器一般是SVM,朴素贝叶斯等;5.训练分类器,后面只要来一个文本,进行文本表示和特征选择后,就可以得到文本的类别。
深度学习进行文本分类
前面介绍了传统的文本分类做法,传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。利用深度学习做文本分类,首先还是要进行分词,这是做中文语料必不可少的一步,这里的分词使用的jieba分词。
深度学习处理文本分类问题中,词语的表示不用one-hot编码,而是使用词向量(word embedding),词向量是词语的一种分布式表示,Hinton最早再1986年就提出了。分布式表示可以这么理解,举个例子,假设有三个词语‘水’,‘冰’,‘冰水’,如果使用one-hot编码,那就编码成:水[1,0,0],冰[0,1,0],冰水[0,0,1]。这就代表了向量空间的第一个维度表示的是‘水’,第二个维度表示的是‘冰’,第三个维度表示的是‘冰水’,每个维度表示的含义不同,而且每个词语的向量之间的夹角都是90度,即使在语义上相似的词语,也无法体现出来。假如我们使用分布式表示,用二维向量表示这个词语,我们指定第一维的含义是‘水’,第二维的含义是‘冰’,那么第一个词语‘水’表示为[1,0],第二个词语’冰‘表示为[0,1],那么‘冰水’既有水也有冰,可以表示为[0.5,0.5],这样的分布式表示,既降低了维度,也体现了语义信息。现在最常用的词向量的分布式表示就是word2vec,是由Tomas Mikolov在2013年提出的,是一种无监督,训练出的词向量具备稠密,包含语义信息的特点。
使用深度学习进行文本分类,不需要进行特征选择这一步,因为深度学习具有自动学习特征的能力。
使用LSTM进行文本分类
前面已经说了词语的表示了,那么在LSTM中,一句话应该如何建模表示呢?“作者 在 少年 时 即 喜 阅读 ,能 看出 他 精读 了 无数 经典,因而 他 有 一个 庞大 的 内心 世界。”这是段分好词的话,将每个词语的词向量按顺序送进LSTM里面,最后LSTM的输出就是这段话的表示,而且能够包含句子的时序信息。
现在我们来搭建一个基于LSTM的文本分类的模型,其结构图如下:
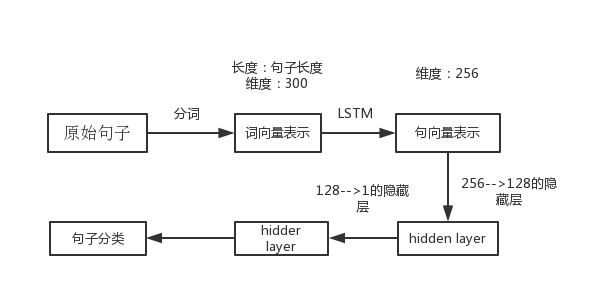 .实验用的语料是商品评论的预料,分为两类,一类是好评,一类是差评。代码用PyTorch写的,下面附上部分代码:
.实验用的语料是商品评论的预料,分为两类,一类是好评,一类是差评。代码用PyTorch写的,下面附上部分代码:
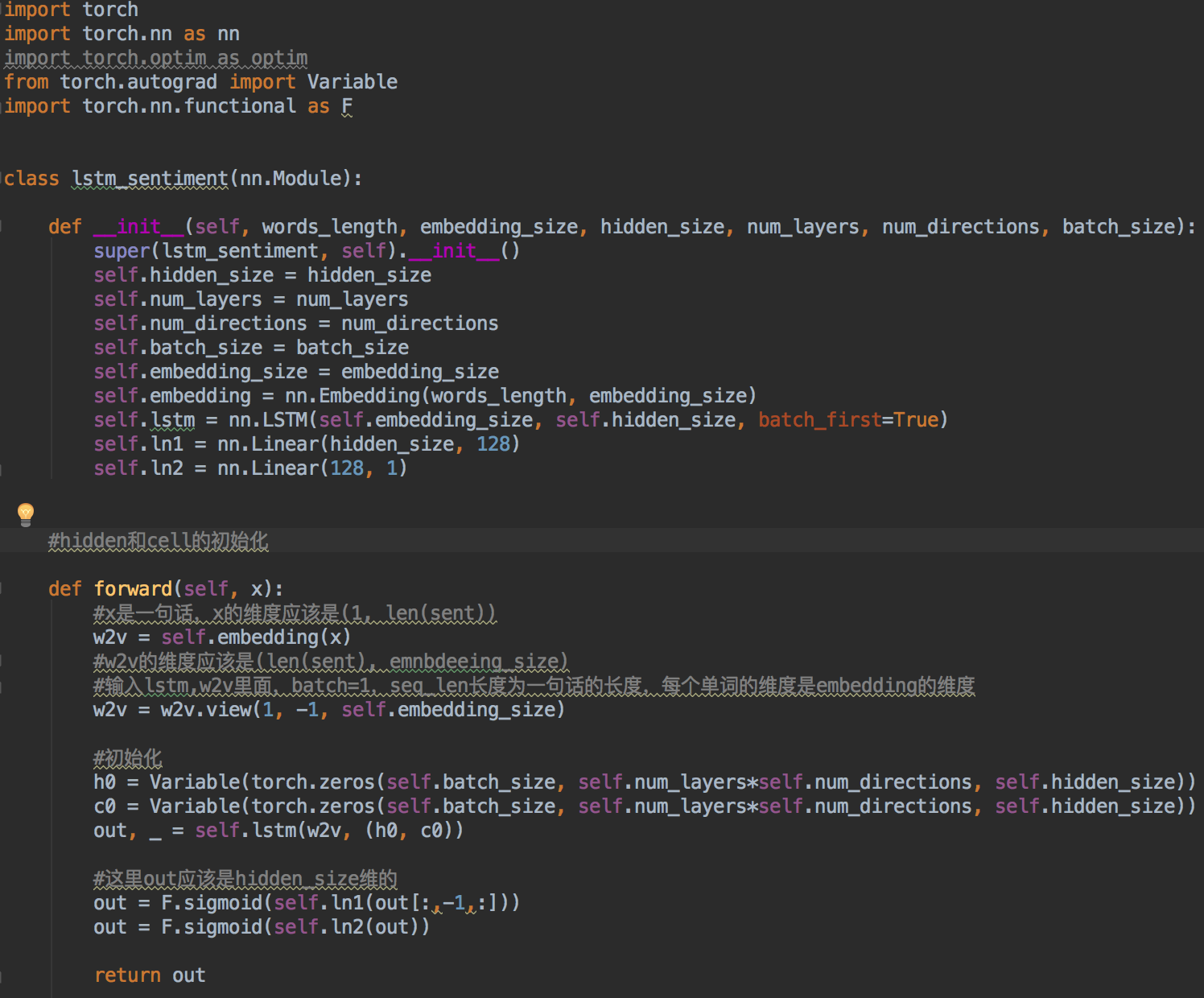
这里我没有没有用word2vec预训练词向量,用了PyTorch里面的nn.Embedding()函数,将one-hot编码的词向量,转换为300维的词向量,并且在训练过程中不断更新词向量。最终的输出通过一个sigmoid函数是因为希望输出在0~1之间,因为数据的标签就是差评为0,好评为1.
下面是训练部分的代码:
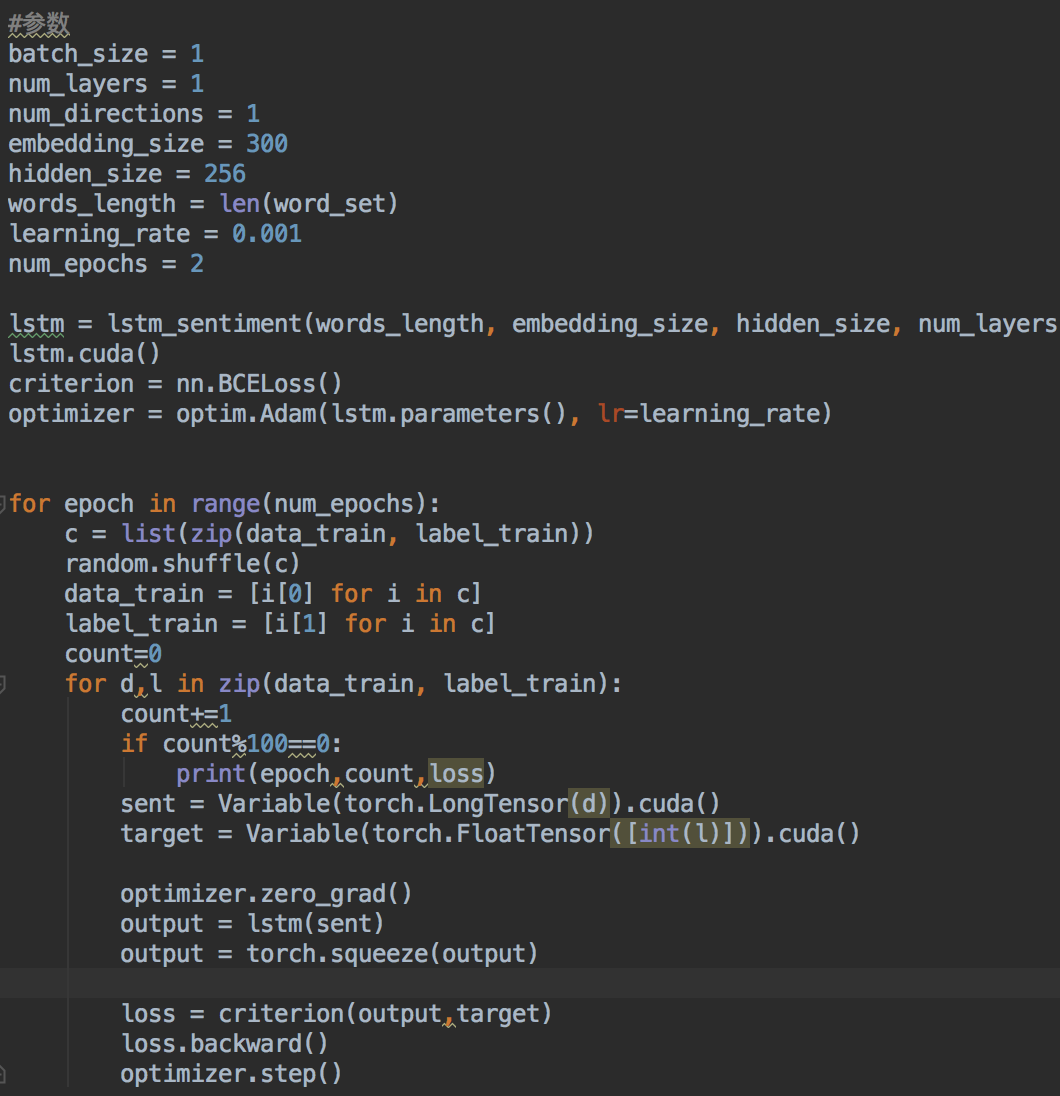
前面是一些参数选择,这里的词向量选择的300维,损失函数是交叉熵损失函数。模型训练最终在3轮之后就收敛了,总共训练数据大概2W条,其中三分之二训练,三分之二测试,准确率在91%左右,这对于短文本分类是一个不错的结果了。还有一个值得讨论的问题,在测试时,我设定当模型输出值小于0.5时,是差评;大于0.5时,是好评。但是这个阈值是可调的,通过调整这个阈值,也能提高模型预测的准确率。模型完整代码以及数据在github上。包括cpu版和gpu版,gpu版大概训练时间是20多分钟,cpu版没有测试。
参考:1.http://kexue.fm/archives/3414/
2.https://zhuanlan.zhihu.com/p/25928551
3.https://www.qcloud.com/community/article/185672
4.https://zhuanlan.zhihu.com/p/30546071
数据来源:http://kexue.fm/archives/3414/
