@Team
2018-11-24T08:28:17.000000Z
字数 4133
阅读 3800
Inception模型进化史:从GoogLeNet到Inception-ResNet
叶虎
说起CNN分类网络,无法避开的是Google提出的Inception网络。Inception网络开始于2014年的GoogLeNet,并经历了几次版本的迭代,一直到目前最新的Inception-v4,每个版本在性能上都有一定的提升。这里简单介绍Inception网络的迭代史,重点讲述各个版本网络设计所采用的trick,需要说明的是Inception网络相对复杂一些,因为它采用了各式各样的较tricky的模块。

图1 Inception网络与其它网络的性能对比
Inception-v1
Inception-v1就是众人所熟知的GoogLeNet,它夺得了2014年ImageNet竞赛的冠军,它的名字也是为了致敬较早的LeNet网络。GooLenet网络率先采用了Inception模块,因而又称为Inception网络,后面的版本也是在Inception模块基础上进行改进。原始的Inception模块如图2所示,包含几种不同大小的卷积,即1x1卷积,3x3卷积和5x5卷积,还包括一个3x3的max pooling层。这些卷积层和pooling层得到的特征concat在一起作为最终的输出,也是下一个模块的输入。
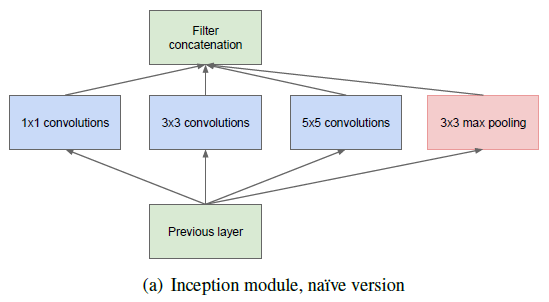
图2 Inception模块的原始版本
但是采用较大的卷积核计算复杂度较大,只能限制特征的channel数量。所以GoogLeNet采用了1x1卷积来进行优化,即先采用1x1卷积将特征的channel数降低,然后再进行前面所说的卷积。这种“瓶颈层”设计也是后面很多网络所常采用的,如ResNet网络。改进后的Inception模块如下图所示:
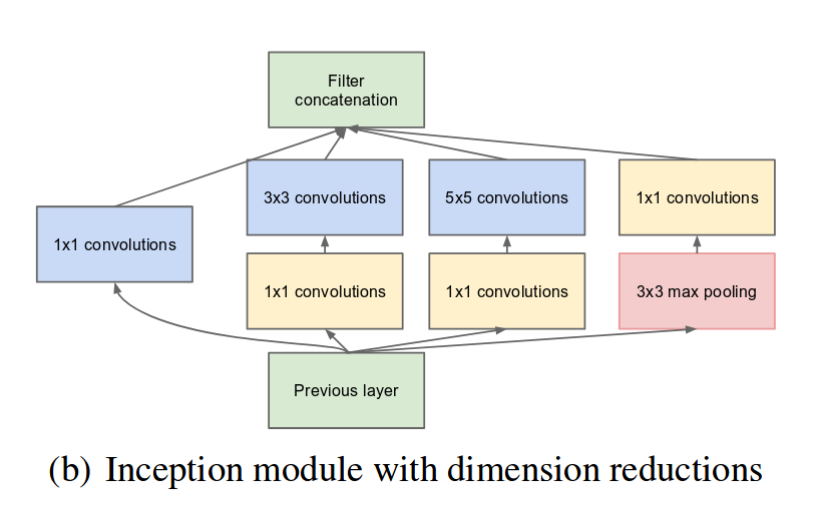
图3 采用1x1卷积改进后的Inception模块
整个GoogLeNet网络是由Inception模块堆积而成,如下图所示,整个网络总共22层:
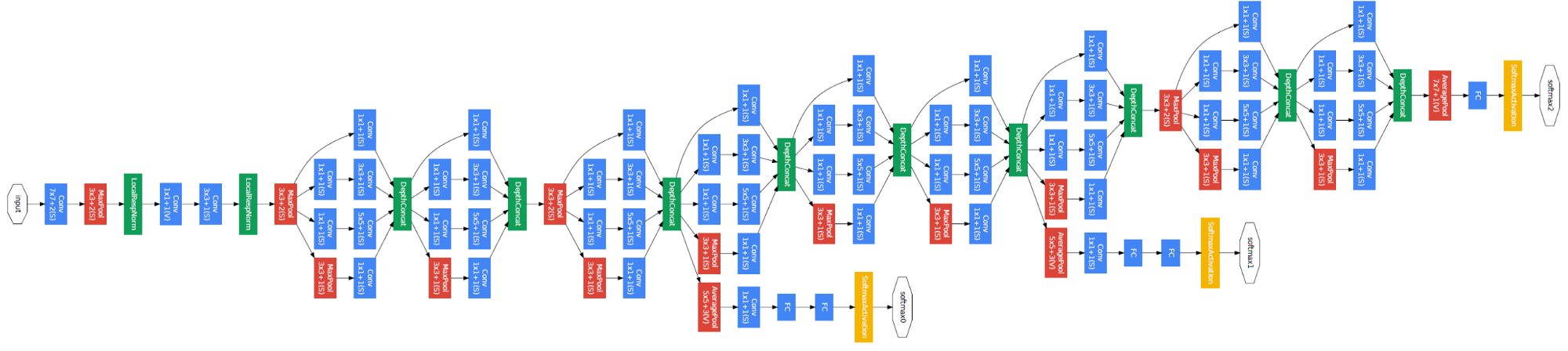
图4 GoogLeNet网络结构
从图中也可以看到,最终的卷积层之后采用Global Average Pooling层,而不是全连接层,这有助于减少参数量,最近的分类网络也基本上是类似的思路。另外值得注意的一点是网络中间层有两个附属的loss,这是一种“深度监督”策略,文中说是为了避免梯度消失问题,也是一种正则化手段。
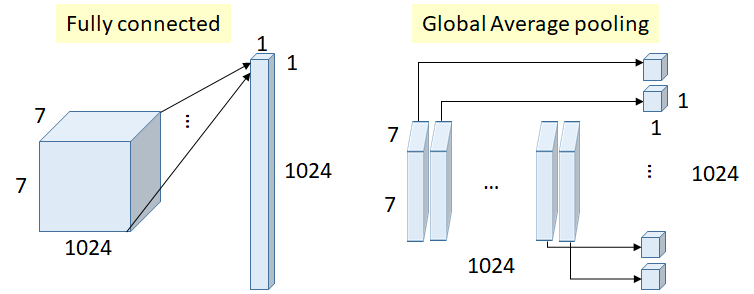
图5 采用Global Average Pooling层替换FC层
Inception-v2
在Inception-v2网络,作者引入了BN层,所以Inception-v2其实是BN-Inception,这点Google在Inception-v4的paper中进行了说明。目前BN层已经成为了CNN网络最常用的一种策略,简单来说,就是对中间特征进行归一化。采用BN层后,一方面可以使用较大的学习速率,加快收敛速度,另外一方面,BN层具有正则化效应(虽然有一些对BN层的理论分析,但是仍有争议)。BN层的原理如下所示:

首先计算特征的mean和var,然后进行归一化,但是为了保证一定的可变度,增加了gamma和beta两个训练参数进行缩放和偏移。在训练过程,还要记录两个累积量:moving_mean和moving_var,它是每个训练step中batch的mean和var的指数加权移动平均数。在inference过程,不需要计算mean和var,而是使用训练过程中的累积量。这种训练和测试之间的差异性是BN层最被诟病的,所以后面有一系列的改进方法,如Group Norm等。
Inception-v3
Inception-v3引入的核心理念是“因子化”(Factorization),主要是将一些较大的卷积分解成几个较小的卷积。比如将一个5x5卷积分解成两个3x3卷积:
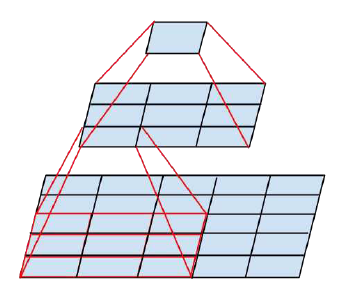
图6 采用两个3x3卷积替换5x5卷积
可以计算,采用5x5卷积,参数量是5x5=25,而两个3x3卷积的参数量是3x3+3x3=18,参数量减少了28%,但是两者效果是等价的(感受野)。据此,改进了GoogLeNet网络中的Inception模块:
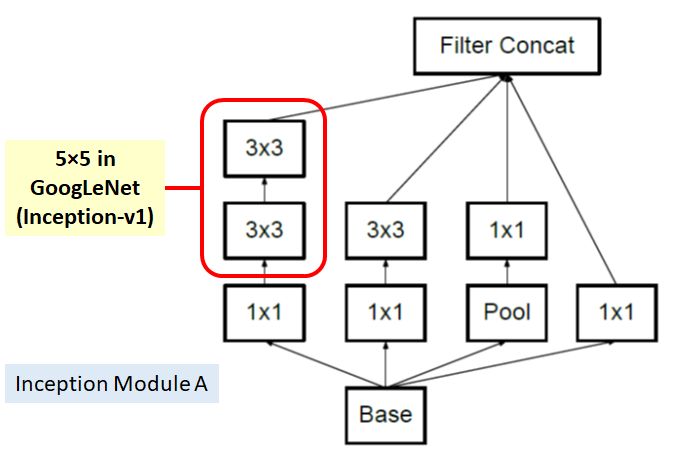
图7 Inception-v3中的Inception模块A
另外的一个因子化,是将nxn的卷积分解成1xn和nx1卷积,如对3x3卷积进行分解:
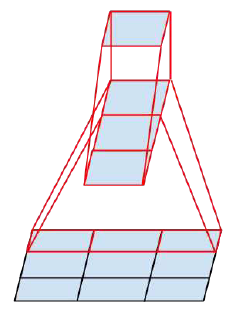
图8 3x3卷积分解成1x3和3x1两个卷积
同样地,这种分解也在保证效果相同下降低参数量。据此,提出了改进的Inception模块B:
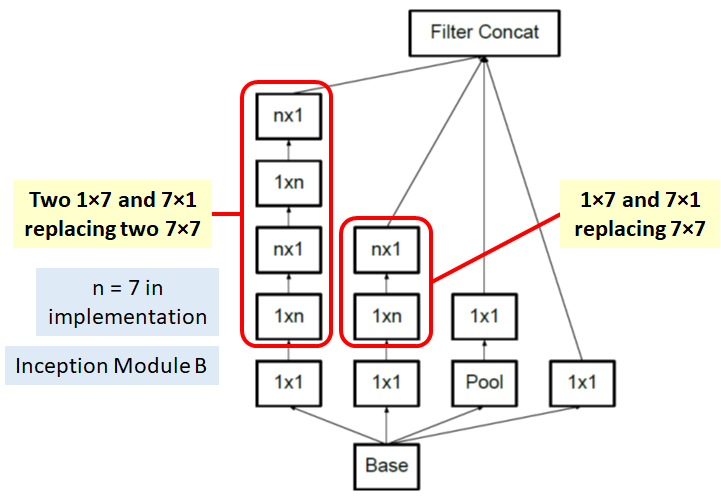
图9 Inception-v3中的Inception模块B
但是作者在实际中发现这种结构不适合较早的层,只适合中等大小的特征(对于mxm大小的特征m的值在12-20之间)。而对于高级特征(m较小的后面层),作者提出了Inceptionmo模块C,其特点是卷积组被扩展以产生更多不一样的特征:

图10 Inception-v3中的Inception模块C
Inception-v3的另外的一个改进是不再直接使用max pooling层进行下采样,因为这样导致信息损失较大。一个可行方案是先进行卷积增加特征channel数量,然后进行pooling,但是计算量较大。所以作者设计了另外一种方案,即两个并行的分支,如图11 所示,一个是pooling层,另外一个卷积层,最后将两者结果concat在一起。这样在使用较小的计算量情形下还可以避免瓶颈层,这种策略其实在ShuffleNet网络中也采用了,看来多读paper还是有用的,可以借鉴别人论文的优点。

图11 Inception-v3中的下采样模块
组合3个改进的Inception模块,最终的Inception-v3网络如下图12所示,较早的层采用模块A,中间层采用模块B,而后面层采用模块C。这中间有点复杂,如果想深入理解网络的整体结构,可以参考一下google的开源实现(slim/inception-v3)。特别要注意的一点是Inception-v3的默认输入大小是299x229,而不是常规的224x224。
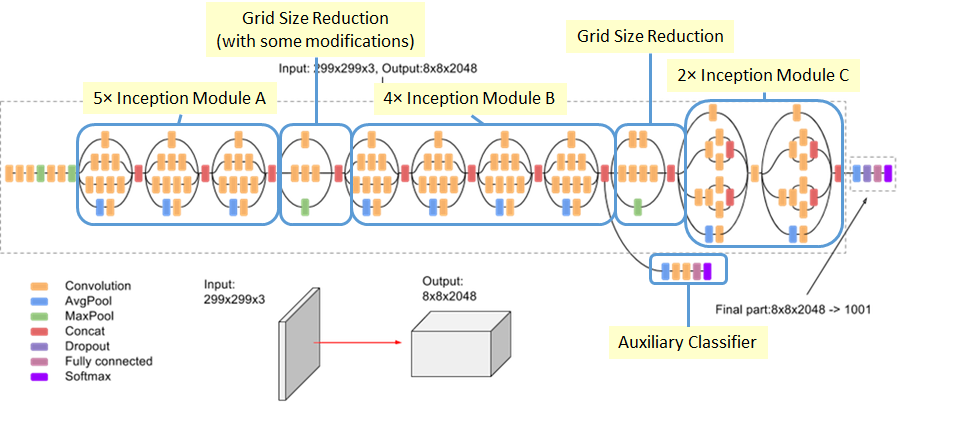
图12 Inception-v3网络结构
Inception-v3也像GoogLeNet那样使用了深度监督,即中间层引入loss。另外一点是Inception-v3采用了一种Label Smoothing技术来正则化模型,提升泛化能力。其主要理念是防止最大的logit远大于其它logits,因为可能会导致过拟合。具体实现比较简单,即改变one-hot编码的label即可:
new_labels = (1 — ε) * one_hot_labels + ε / K
其中K是类别数,而ε=0.1是一个超参数。
Inception-v4
Inception-v4是对原来的版本进行了梳理,因为原始模型是采用分区方式训练,而迁移到TensorFlow框架后可以对Inception模块进行一定的规范和简化。Inception-v4整体结构如图13所示,网络的输入是299x299大小。在使用Inception模块之前,有一个stem模块,如右图所示,这个模块在Inception-v3网络也是存在的,它将输出35x35大小的特征图。
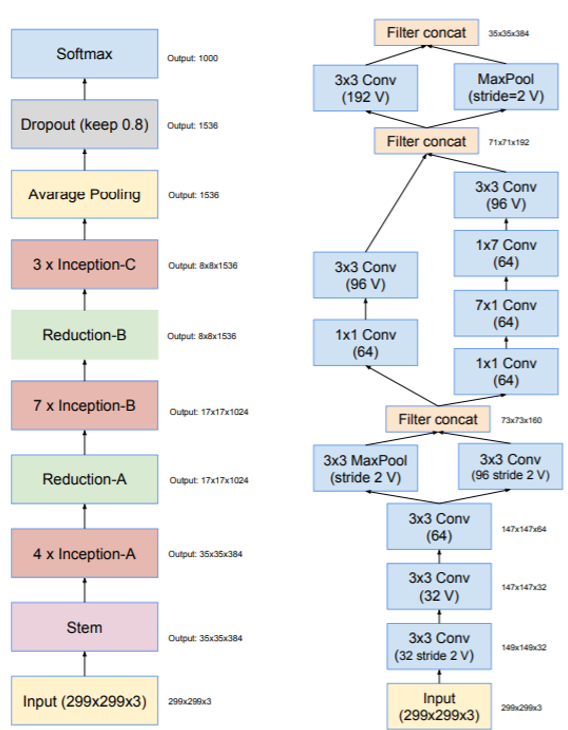
图13 Inception-v4网络结构
Inception-v4中的Inception模块分成3组,基本上与Inception-v3网络是一致的,但有细微的变化,如下图所示:

图14 Inception-v4网络的Inception模块
Inception-ResNet
Inception-ResNet网络是在Inception模块中引入ResNet的残差结构,它共有两个版本,其中Inception-ResNet-v1对标Inception-v3,两者计算复杂度类似,而Inception-ResNet-v2对标Inception-v4,两者计算复杂度类似。Inception-ResNet网络结构如图15所示,整体架构与Inception类似,右图两个分别是Inception-ResNet-v1和Inception-ResNet-v2网络的stem模块结构,也即是Inception-v3和Inception-v4网络的stem模块。

图15 Inception-ResNet网络结构与stem模块
Inception-ResNet-v1的Inception模块如图16所示,与原始Inception模块对比,增加shortcut结构,而且在add之前使用了线性的1x1卷积对齐维度。对于Inception-ResNet-v2模型,与v1比较类似,只是参数设置不同。

图16 Inception-ResNet-v1的Inception模块
不同Inception网络的在ImageNet上的对比结果如下表所示,可以看到加入残差结构,并没有很明显地提升模型效果。但是作者发现残差结构有助于加速收敛。所以作者说没有残差结构照样可以训练出很深的网络。

小结
从最初的GoogLeNet,到最新的Inception-ResNet,Inception网络在不断的迭代中越来越好,相比其它模型,Inception网络相对来说更复杂一些,主要在于模块比较复杂,而且采用的模块也是多样化。未来的话,可能需要AutoML来设计更好的模块结构。
参考
- GoogLeNet/Inception-v1: Going Deeper with Convolutions.
- BN-Inception/Inception-v2: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
- Inception-v3: Rethinking the Inception Architecture for Computer Vision.
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- Review: Inception-v4 — Evolved From GoogLeNet, Merged with ResNet Idea (Image Classification)
- A Simple Guide to the Versions of the Inception Network
