@Pigmon
2017-11-27T09:08:01.000000Z
字数 1245
阅读 1668
Robot Perception 笔记
实习
Robust Robot Perception
主要应用
个人机器人,无人车,无人机
传感器
照片(RGB)
Depth map (D)
热成像(Thermal)
点云(LiDar)
Neuromorphic(?)
1. 3D End-to-End Processing
3D 目标识别
识别出 3D 空间中的物体,并得到3D包围盒。
输入特征:
- 照片
- Depth Map
输出:
- 分类
- 3D 包围盒
Depth Map
通过多视图几何方式得到3D空间中点的深度信息。
假设得到对同一场景的2个视图,2个相机的Y轴没有相对移动,那么可以假设2个视图在同一个逻辑平面上,对应点也在同一条水平线上。
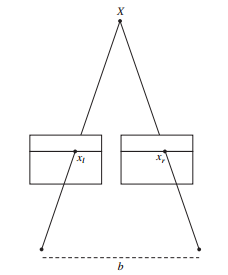
这样称2个视图经过了矫正。
在这种情况下,计算深度,即空间点的深度可以通过以下公式:
来计算。其中是焦距,是两个相机之间的距离,和是两个图像点的轴坐标。相机之间的线段称为基线。
流程
- 将 Depth map 当作图像的额外通道,编码进图像作为输入特征。
- 2D 边缘检测
- 2D 包围盒提议
- 2D 目标检测
- 2D 实例分割
- Coarse Pose Classification(?)
- 点云对齐
- 3D Amodal Detection Result(?)应该是 3D Model Dectection Result 吧?
3D Region Proposal Network
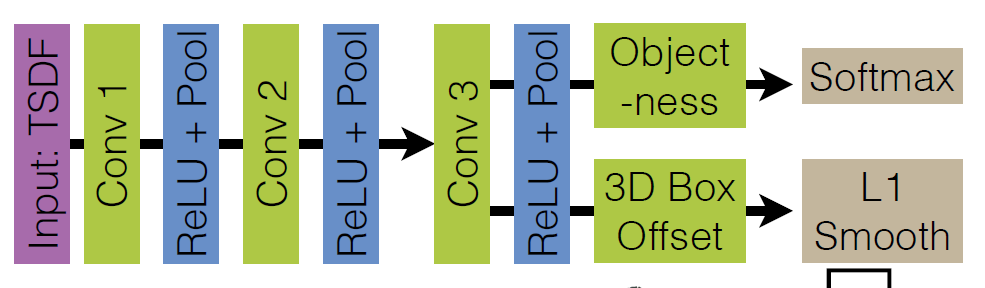
结构和 Faster R-CNN 类似,卷积网络后面跟上两个分支,一个用于分类,一个用于包围盒回归。
输入:TSDF,是什么?
输出:Objectness 分数?包围盒(矫正前?)
3D Object Recognition Network
跟上面那个区别是卷积层后面接了全连接层,具体信息文档里没有交待。
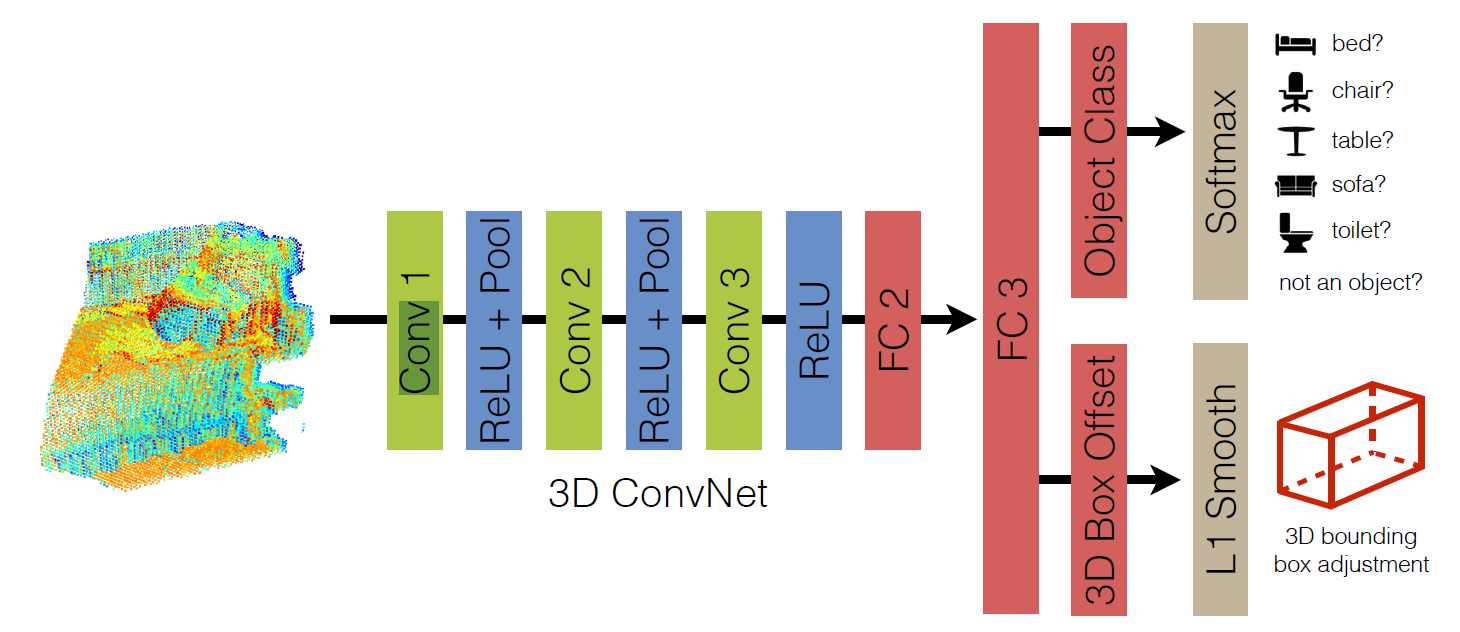
这个图的意思是输入只有点云数据吗?
Marvin
3D Convolutional Deep Belief Network (3D DBN)
输入的 3D volume
shape completion
没说 和 分别是什么,应该一个是输入数据,一个生成数据。
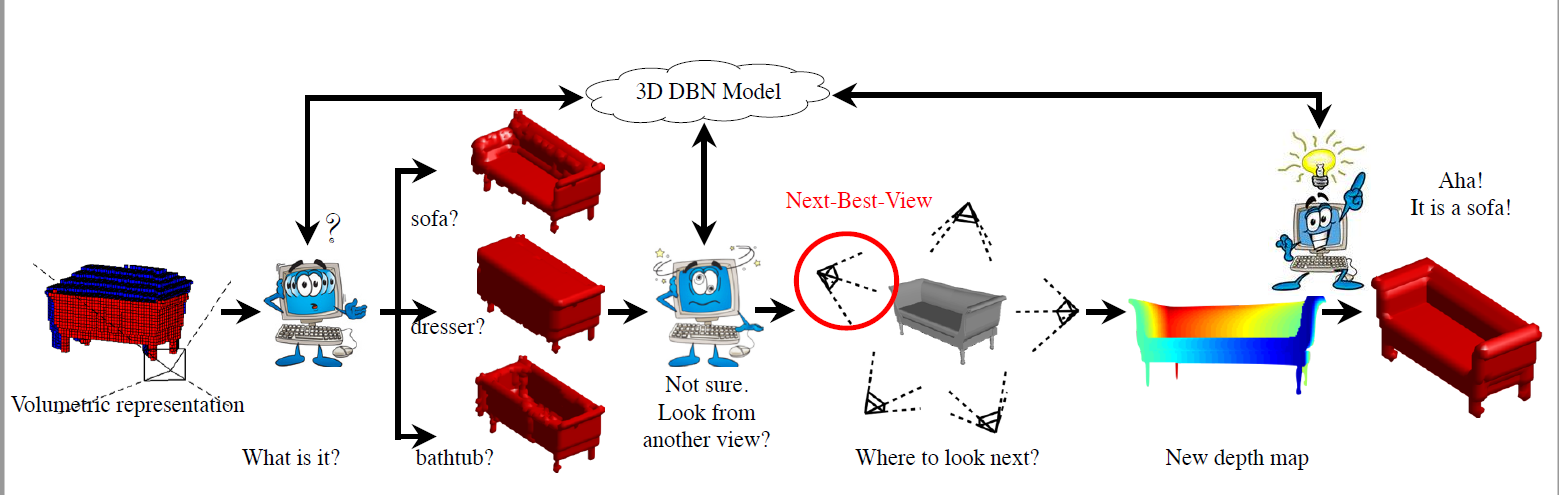
3D Deep Learning for SLAM
SLAM
Simultaneous localization and mapping 同时定位与地图构建
TODO
自动驾驶中的应用
TORCS
The Open Racing Car Simulator
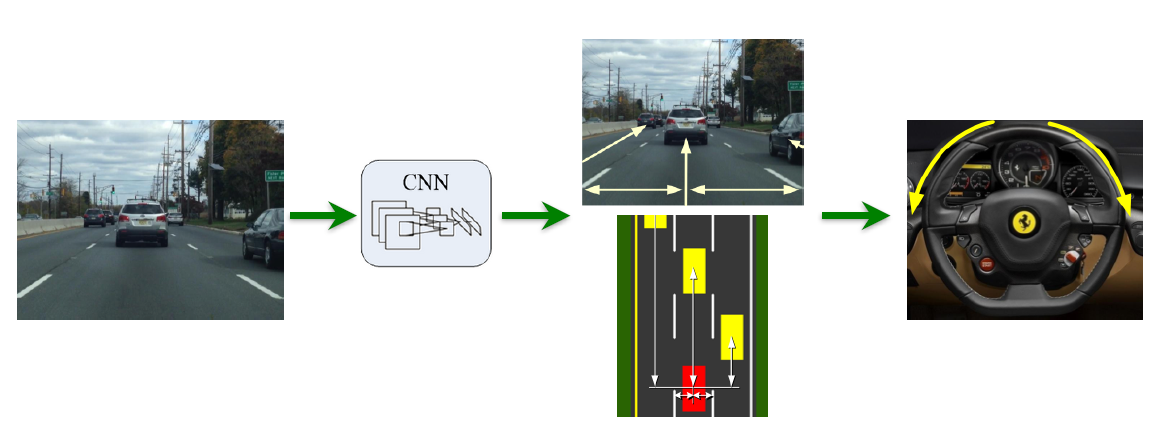
Direct Perception
传统方法:Mediated Perception
看图的意思是找到交通参与者的包围盒,快要碰撞的时候转向避开的意思?
Direct Perception
家用机器人初始化过程的假想描述
Far from 看懂
