@Pigmon
2017-11-20T16:05:48.000000Z
字数 4743
阅读 1701
Mask R-CNN (无原文)
文献阅读
论文主页:https://arxiv.org/abs/1703.06870
注:RoI (Region-of-Interest)
IoU:2 个区域交集 与 并集 的比例
Abstract
我们提出了一个用于对象实例分割的简单,灵活而通用性好的框架。我们的方法有效地检测图像中的目标,同时为每个实例生成高质量的分割掩膜。Mask R-CNN 通过添加用于预测目标掩膜的分支来扩展 Faster R-CNN,该分支与包围盒识别的分支并行。Mask R-CNN 训练简单,相对于 Faster R-CNN 只增加较少的开销...可以应用到其他的领域如姿态识别...实验数据...
3. Mask R-CNN
Mask R-CNN 的概念很简单:Faster R-CNN 中,每个候选目标,类别标签和包围盒偏移都有2个输出;为此我们增加了第3个分支用来输出物体的掩膜。这是一种直观而自然的想法。但是,新增的掩膜输出与类别和包围盒不同,它需要对目标的空间布局进行更细致的提取。接下来,我们会对 Mask RCNN 的关键部分进行说明,包括像素到像素对齐(pixel-to-pixel alignment),这也是 Fast/Faster RCNN 中的主要缺陷。
Faster R-CNN : 我们首先快速的回顾一下 Faster R-CNN detector [34]。Faster R-CNN 有 2 个阶段。第一个阶段我们称之为 RPN (Region Proposal Network),作用是提出候选的目标包围盒。第二个阶段是对 Fast RCNN [12] 的增强,它使用 RoIPool 从每个候选包围盒提取特征,然后进行分类和包围盒回归(bounding-box regression)。两个阶段的特征共享,用以更快的推理(inference)。建议阅读文献 [21] 了解 Faster R-CNN 与其他框架的比较。
Mask R-CNN: 采用相同的 2 阶段过程,其中第一个阶段,也就是 RPN 阶段是跟 Faster RCNN 相同的。在第二个阶段中,在并行的进行分类和包围盒偏移计算的同时,Mask R-CNN 同时为每个 RoI 输出一个二进制掩膜。这里分类是依赖于掩膜预测(mask predictions)的 (e.g. [32, 10, 26] ),这是Mask R-CNN 和其他框架的主要区别。我们的方法也遵循 Fast RCNN 的思路:包围盒的分类和回归并行进行,这样相比原始 RCNN [13] 的多阶段流程是大大简化的。
训练期间,我们为每个抽样 RoI 定义了一个多任务损失函数,公式为:。其中分类损失函数 和包围盒损失函数 与文献[12]中的定义相同。在掩膜分支,每个 RoI 有一个 维的输出,对 的分辨率生成一个 位的掩膜,对应 个类别。为此,我们应用了逐像素 Sigmoid, 并将 定义为平均二元交叉熵损失函数(average binary cross-entropy loss)。对于一个与 Ground Truth 类别 对应的 RoI , 只定义在第 个掩膜上。(其他掩膜输出对损失函数没有贡献)
我们对 的定义能让网络为每个类别生成掩膜,同时不会造成类别之间的冲突;对于用来选择输出掩膜的类别标签,我们使用一个专用的分类分支去预测。这样会解除掩膜和类别预测之间的耦合。这与将FCN [29] 应用于语义分割的常见做法(使用逐像素softmax和多项交叉熵损失函数)不同。在他们的方法中,掩膜和类别会有冲突;而我们的方法就不存在这个问题,因为我们使用逐像素 Sigmoid 和 二元损失函数。之后我们会通过实验数据来说明,这个公式是我们获得良好实例分割结果的关键。
掩膜表示:掩膜编码的是输入对象的空间布局。因此,相对于不可避免的与全连接层的短输出向量(short output vectors by fully-connected layers)冲突的类别标签或者包围盒偏移,提取掩膜的空间结构可以自然的被卷积所提供的像素到像素的对应关系解决。
具体的说,我们从每一个使用 FCN [29] 的 RoI 预测一个 的掩膜。这样,掩膜分支中的每一个层都可以维护一个明确的 的对象空间布局,而不需要把它折叠成(collapsing it into)一个缺乏空间维度信息的向量表示。与之前那些为了预测掩膜而将全连接层重新排序的方法 [32, 33, 10] 不同,我们使用的全卷积表示需要的参数更少,准确率更高。
这种像素到像素的行为需要 RoI 特征——本身就是小特征图,可以更好的保留逐像素的空间对应关系。因此我们开发了 层,并把它作为掩膜预测中的关键角色。
RoIAlign:RoIPool [12] 是从RoI提取小特征图(例如,)的标准操作。 RoIPool 首先将浮点型 RoI 量化到特征图的离散粒度,然后将该量化的 RoI 细分为多个空间区块(量化的),最后汇总每个区块覆盖的特征值(通常通过最大池化)。 通过在一个连续的 x 坐标上计算 ,其中 16 是特征图的步长(Stride),小数部分被舍去,这样就执行了量化操作;同样的,在把特征图分割成空间区块(例如,)的过程里,也执行了量化。这些量化导致了 RoI 和特征之间不对齐(misalignments)。虽然这样对于小的偏移是鲁棒的,不会影响分类,但对于掩膜预测这种要求像素级精度的操作来说,它带来的负面影响还是很大的。
为了解决这个问题,我们提出了 层,移除了 RoIPool 粗糙的量化操作,将提取的特征与输入对齐。我们的主要改动很简单:不去量化 RoI 边界或者区块 (也就是说,用 代替 )。对于每个 RoI 区块上的 4 个均匀采样区域中的输入特征,我们使用双线性插值 [22] 来计算它们的确切数值,并将结果聚合(使用最大值或平均值)。
从本文 4.2 节可以看到,RoIAlign 带来的提升是很显著的。我们也对比了 [10] 中提出的 RoIWarp。与 RoIAlign 不同,RoIWarp 忽略了对齐问题,并且和 RoIPool 一样采取了量化操作。所以,虽然 RoIWarp 也和 [22] 出于同样的动机采用了双线性重采样(bilinear resampling),它相对于 RoIPool 并没有太大改善,如实验数据所示(更多细节看 Table 2c),这充分说明了对齐的的重要性。
网络架构:为了展示我们的方法的通用性,我们采用了多个架构来实现 Mask R-CNN。为了清楚起见,我们区分:(i) 用于在整张图像上进行特征提取的骨干卷积架构,与 (ii) 【用于包围盒识别(分类和回归) 和 用于分别在每个 RoI 上进行掩膜预测】的网络头(network head)。
我们使用 网络-深度-特征(network-depth-features)这个命名规则来表示骨干架构。我们评估了深度为 50 和 101 层的 ResNet [19] 和 ResNeXt [40]。在 ResNets [19] 的 Faster R-CNN 的原始实现中,在第 4 阶段的最后一个卷积层提取特征,我们将其称为 C4。以这个例子来说,这个骨干是 ResNet-50 的网络被表示为 ,这种命名方法在文献 [19, 10, 21, 36] 都有使用。
我们还探索了最近被 Lin 在文献 [27] 中提出的一个更有效的方法,叫做特征金字塔网络(FPN)。FPN 采用一个横向连接的自顶向下架构,以一个 单尺度的输入 来构建网络中(in-network)的特征金字塔。具有 FPN 架构的 Faster R-CNN 根据尺度在特征金字塔的不同层提取 RoI 特征,该方法的其他部分与 vanilla ResNet 类似。在 Mask R-CNN 中使用 ResNet-FPN 骨干架构,其特征提取的准确率和速度都有非常显著的提升。阅读文献 [27] 以进一步了解 FPN。
对于网络头(network head),我们沿用了前人工作中的构架,但我们增加了一个全卷积的分支用于掩膜预测。特别的,我们扩展了 ResNet [19] 和 FPN [27] 两个文献中的 Faster R-CNN 的 box heads。如 图3 (在文档最下面) 所示。ResNet-C4 骨干架构的头包含了 ResNet 的第 5 阶段,这是计算密集的。对于FPN,骨干已经包含了res5,因此可以使用包含更少的过滤器的头,进而提升效率。
我们留意到,我们的掩膜分支的结构非常简单。更复杂的结构可能会带来效率的提升,但不在本文的讨论范围内。
3.1 Implementation Details
我们根据现有的 Fast/Faster R-CNN 工作 [12, 34, 27] 来设置超参数。虽然在文献 [12, 34, 27] 中,这些超参数是为了目标检测而设置的,但我们发现它们在实例分割系统中同样适用。
训练:跟在 Fast R-CNN 中一样,一个 RoI 如果跟 ground-truth 包围盒有至少 0.5 的 IoU 的话,即认为是正,否则为负。掩膜损失函数 只定义在正的 RoI 上。掩膜的目标是 RoI 和它相关的 ground-truth 掩膜之间的交集。
我们采用了 image-centric 训练 [12]。图像被缩放为尺度(短边)为800像素 [27]。一个 GPU 上的一个 mini-batch 有 2 张图像,每张图像有 N 个采样 RoI,正负比例为 1:3 [12] 。在 C4 骨干架构中 N 为 64 (与文献 [12, 34] 相同),在 FPN 中 N 是 512(与文献 [27] 相同)。我们在一个 8 GPU (这样 mini-batch 就是 16 个)的平台上训练 160k 个迭代,学习率为 0.02,每 120k 个迭代减少 10%。我们设置 weight decay 为 0.0001,momentum 为 0.9。
根据文献 [27],RPN 锚点跨越 5 个尺度和 3 个纵横比。方便起见,RPN 并没有和 Mask R-CNN 共享特征,除非特别指定。在本文中,RPN 和 Mask R-CNN 具有相同的骨干架构,所以它们是可以共享(特征?参数?)的。
推论:测试中,C4 骨干 [34] 的 proposal 数量(proposal number)为 300,FPN [27] 为 1000。对于这些 proposal ,我们在非极大值抑制 [14] 操作之前运行一个包围盒预测分支。随后对于分数最高的 100 个包围盒运行掩膜分支。虽然这和训练过程中的并行计算不同,它还是提高了推理速度,并且提升了准确率(因为使用了更少,更精确的 RoI)。掩膜分支对每个 RoI 预测出 K 个掩膜,但只使用第 k 个掩膜,其中 k 是由分类分支预测出来的类别。 的浮点数掩膜缩放到 RoI 的尺寸,然后以 0.5 为阈值进行二值化。
注意因为我们仅对分数最高的 100 个包围盒进行掩膜计算。对于其对应的 Faster R-CNN,Mask R-CNN 增加了边缘运行时间。(对于常规模型大约 20%)
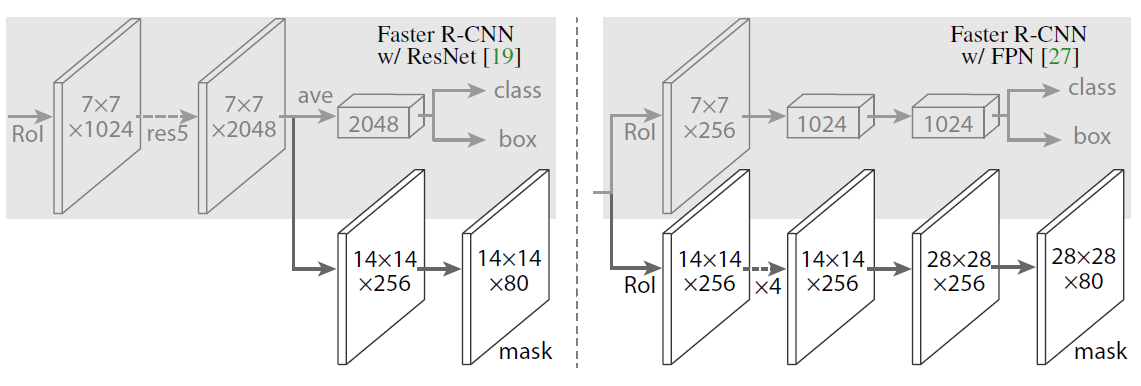
Fig 3
头架构:我们扩展了 2 个现有的 Faster R-CNN 头 [19, 27]。左 / 右 两个图分别表示了 ResNet C4 和 FPN 骨干架构的情况,两边都添加了掩膜分支。数字表示分辨率和通道数。箭头表示卷积,反卷积或者全连接层,可以从上下文中区分出来。(卷积后分辨率不变,反卷积后分辨率增大)卷积核都是 的,除了输出层是 的;反卷积核是步长为 2 的 的。激活函数用 ReLU [30]。
左边:‘res5’ 表示 ResNet 的第 5 部分,为了简化我们做了一些修改:第一个卷积操作是在一个 的 RoI上,并且步长改为 1 (原来是 步长 2)
右边: 代表 4 个连续的卷积。
