@liuhui0803
2017-11-28T10:14:32.000000Z
字数 4404
阅读 3321
产品中的机器学习:从已受训模型到预测服务器
机器学习 Pickle Python 服务器 Pmml
经过无数个日夜的努力工作,从功能开发进展到交叉验证,终于实现了自己期待已久的预测分数。结束了吗?嗯,考虑到自己那么棒,你决定开发一个可以根据自己训练好的模型,按需进行预测的微服务。那么应该怎么做?本文将介绍不同的实现选项,随后会介绍ContentSquare为预测服务器构建技术架构时使用的解决方案。
那些应当避免的事情
假设某个项目需要训练模型,那么你可能会考虑在项目中增加一个服务器层。这也叫做整体式(Monolithic)架构,有点像大型机时代的老古董。模型的训练和实时预测服务的提供是两种截然不同的任务,理应由不同组件负责处理。同时我也觉得,如果只是希望调整模型本身,就没必要准备一整套满足所有需求的服务器,反之亦然,将所有训练代码部署到服务器端也是没必要的,这纯粹是浪费。最后同样重要的是,古话说“兔子不吃窝边草”,这不无道理。
因此更适合的做法是将训练工作独立于服务器进行。这样就可以在本地计算机或训练用的集群上完成所有数据处理工作,将模型训练好之后再放到服务器上发布到生产环境。
那么具体该怎么做?
老实说,方法有很多。我会介绍其中部分方法,随后讲讲ContentSquare在为自动化区域识别(Zone recognition)算法设计整个架构时采取的解决方案。
如果你只对我们最终选择的解决方案感兴趣,那么可以直接调到本文末尾处阅读。
那些应当做的事情
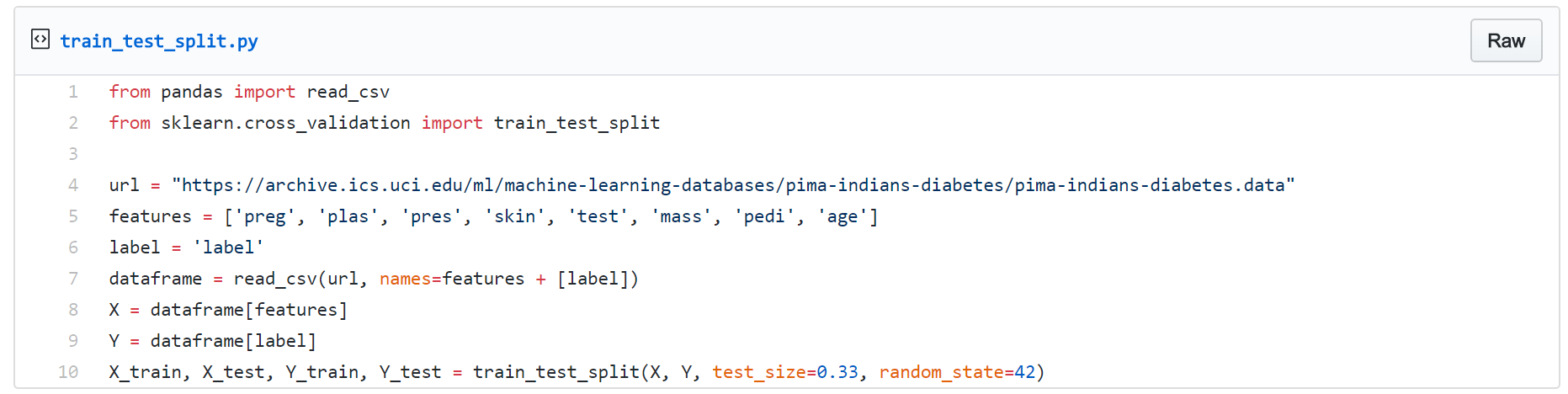
我们的参考范例是一种对经典皮马印第安人糖尿病数据集进行的逻辑回归,该数据集包含8个数值特征以及一个二进制标签。我们使用下列Python代码训练并测试数据集。
模型系数转移(Model coefficients transfer)方法
拆分数据后,即可开始训练LogReg并将其系数(Coefficient)保存为一个json文件。

将系数保存到安全的位置后,便可以使用其他任何语言或框架重现这个模型。具体来说,我们可以将这些系数写入到服务器配置文件中。随后服务器启动后,便可以通过从配置文件获得的恰当权重初始化Logreg模型。太棒了!
这种方式最大的优势在于,无论对编程语言和库有怎样的需求,训练过程和服务器都是完全独立的。
然而这种方式经常会造成一个疏忽:特征工程(Feature engineering),或者更具体来说:机器学习的阴暗面。通常来说我们很少会使用原始(Raw)数据直接训练模型,训练之前总会需要对原始数据进行一定的预处理。例如常见的标准化或PCA,以及各种类型的外来特性转换(Exotic transformation)。
如果打算将预处理环节也包含在服务器端,必须意识到对训练过程进行的哪怕最微小的改动也应该完全在服务器端重现,也就是说,两方都需要发布一个新的版本。如果你总是通过调整特征工程方面的内容来改善结果,那么所有工作量都会翻倍,并且会产生很多重复工作。
更重要的是,不知道你具体情况如何,但在核心实现没有任何改变的情况下为服务器发布新版本,这样的做法对我来说需要不小的勇气。我是指,对于训练环节来说,有必要的话我可以接受随时发布新版,或者重新发布修订后的新模型,但对于服务器还是不希望这样做,毕竟从设计的角度来看,就算模型有变化,服务器也应当能按照原本的预期正常运行(见图2)。
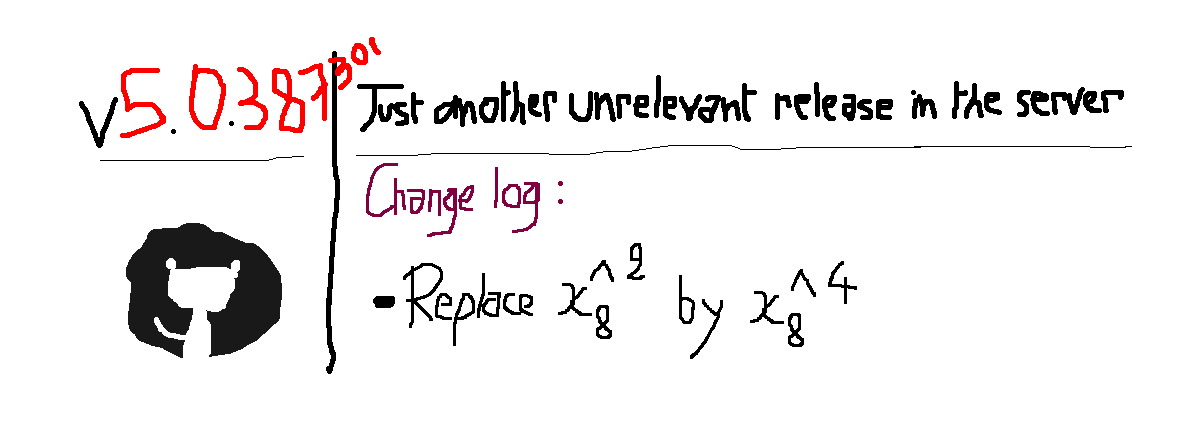
图2:某台预测服务器的第387301次发布(没错,这里用了夸张的手法),原因仅仅在于特征工程方面一个很小的改动,其实这个改动并不会影响到服务器的运行。这样做并不好。
PMML方法
另一种方法是使用库或者某种标准,借此让自己同时描述模型本身以及预处理操作。而PMML就是这样的一种标准化措施,可以使用XML格式的文件描述机器学习的流程。通过这种文件我们可以同时描述预测模型以及数据转换过程。试试看吧!

在这个例子中我们使用sklearn2pmml导出模型,并对“mass”特征应用对数变换。输出文件的结果如下:

尽管PMML无法支持所有可用的机器学习模型,但在解决这个问题方面确实起到了很大的效果(详情可参阅PMML官方参考文档)。然而,如果打算使用PMML也要注意,该技术目前还缺乏对很多自定义转换的支持。一起来看看另一个例子,这一次针对“age”特征使用了名为is_adult的自定义转换。
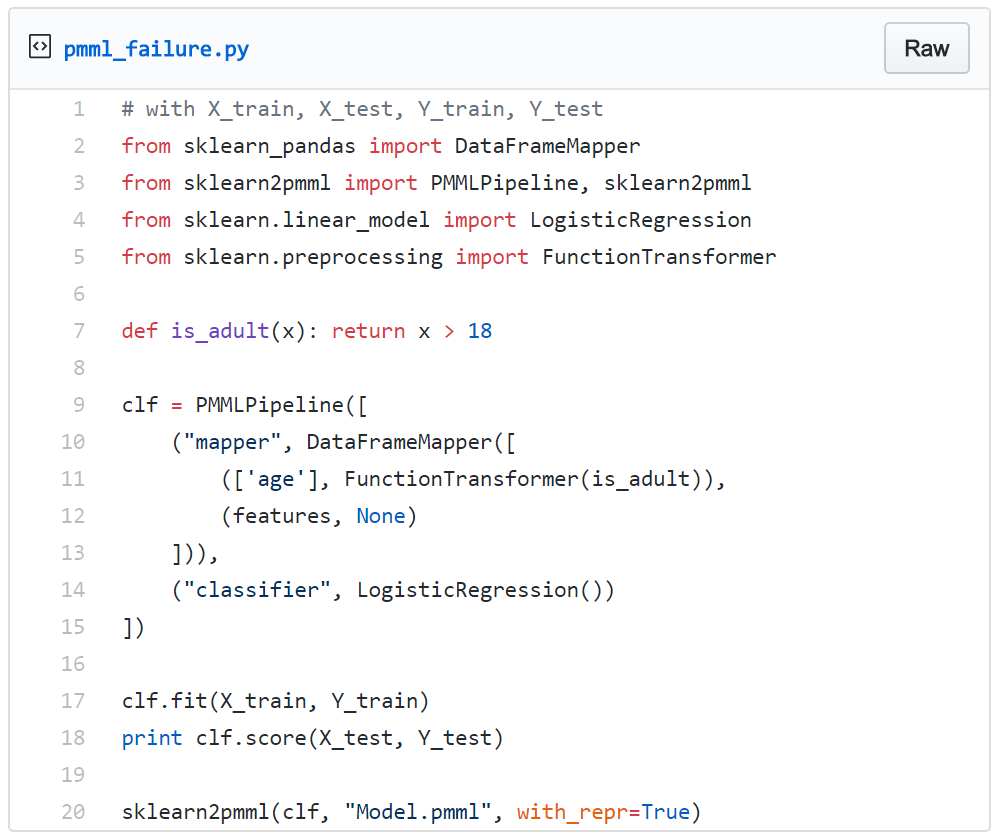
结果当然会失败,并显示了下列错误信息,称PMML的支持有限:The function object (Java class net.razorvine.pickle.objects.ClassDictConstructor) is not a Numpy universal function。
简而言之,如果坚持使用标准模型和转换,PMML将会是最适合的选项。但如果希望在此基础上使用自定义内容,那也不用着急,还有别的选项。继续读下去吧。
自定义DSL/Framework的方法
除了使用PMML,我们还可以构建自己的PMML。没错!我不是指完全照搬现有的PMML,而是使用某种DSL或框架将训练端所做的成果转换到服务器端。很酷吧!数月的辛苦工作,这么简单就可以搞定了。这种解决方案很赞,但不幸的是并非所有人都有足够的资源从零开始构建这一切,但如果你有条件,这样做绝对是值得的。你甚至可以通过这种方式发布机器学习即服务平台,就像prediction.io那样。酷毙了对吧!
(既然提到了机器学习SaaS解决方案,我觉得这是一种很有前景的技术,可以解决本文提到的很多问题。然而不管什么技术,知道如何自行实现,总是能让人获益的。)
我们最终的做法
接下来还请大家注意,上文提到的方法有一个共同之处:这些方法都将预测模型看作一种“配置”,而不是我们通常视作的“独立程序”或将所需的全部内容都包含其中的黑盒子,因此也可以更方便地移植(见图3)。

图3:上图:模型描述转移方法,服务器加载配置并用配置创建模型。下图:黑盒子转移方法,服务器单独加载模型本身。
黑盒子方法
为了将已训练的模型以及预处理*步骤作为封装后的整体传输给服务器,我们需要执行所谓的序列化(Serialization)或编组(Marshalling)操作,借此将不同对象转换为适合存储或传输的数据格式。我们需要的一切都可以装在这个黑盒子里,最终可以获得一个能够接受原始输入随后输出预测结果的物件(见图4)。
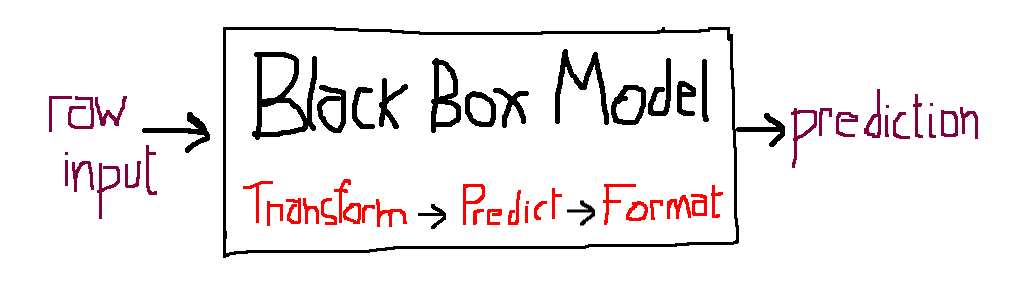
图4:独立的已训练模型已经准备好透明地集成于服务器端。
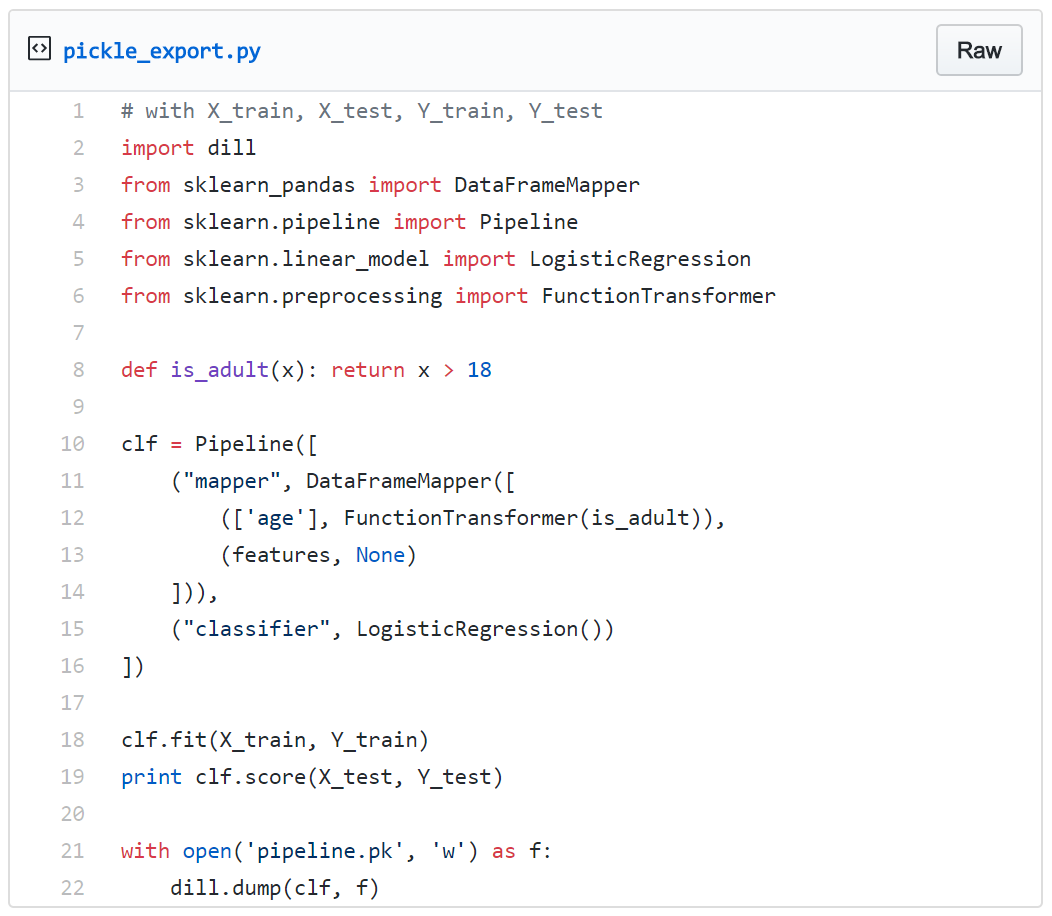
试试看使用来自Scikit-learn的Pipeline构建这个黑盒子,并使用Dill库进行序列化。我们将继续使用上面提到的,PMML无法支持的自定义转换:is_adult。
把这些东西都加载到服务器端。
为了更好地模拟服务器环境,可以试着在训练模块无法访问的位置运行流程。此外要注意,无论使用任何库构建模型,都必须在服务器环境中安装对应的库。例如,如果你在训练过程中使用了Pandas和Sklearn,那么在服务器端除了安装Flask、Django或其他任何需要在服务器上使用的库,也别忘了在服务器上安装Pandas和Sklearn。
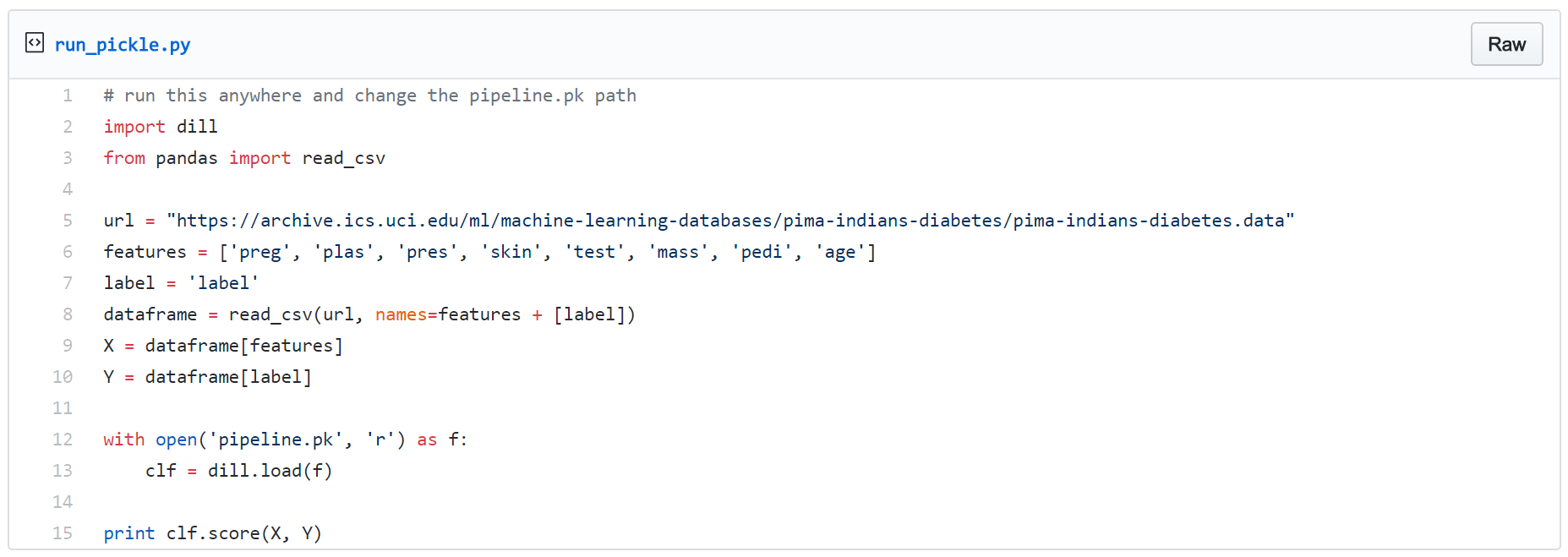
这个结果证明,就算使用了自定义转换,我们依然可以自行创建独立的流程。另外请注意,is_adult是个很简单的例子,只是为了起到示例作用。实践中的自定义转换往往会比它复杂很多。
这种方法最大的挑战在于,围绕Pickle会遇到一些麻烦的小问题。因此我想分享一些自己过去实践中积累的经验和心得:
- 尽可能避免从其他Python脚本导入(当然从库导入是可以的):
例如:假设在上文的例子中is_adult是从另一个文件from other_script import is_adult导入的。此时将无法通过任何序列化库,例如Pickle、Dill或Cloudpickle进行序列化,因为这些库默认就不能对导入的内容序列化。为此可以将流程用到的所有内容放置在创建该流程所用的同一个脚本中。然而如果确实因为一些原因不能将所有内容放在同一个文件中,此时始终都可以替换import other_script by execfile("other_script")。当然,我也觉得这种做法不怎么好看,但要么这样做,要么将一切放在同一个脚本中,你自己决定吧。当然如果你有更酷的解决方案,我也很乐意听听你的看法。 - 避免使用lambda,一般来说这种东西很难序列化。虽然Dill可以对Lanbda序列化,但标准的Pickle库是不支持的。当然,你可以选择使用Dill,没错,但是这样做也需要当心!Scikit-learn的一些组件会使用标准的Pickle进行序列化操作,例如
GridSearchCV。因此需要进行序列化的可能不仅是Dill的那堆东西,同时还有Pickle的那堆东西。
这个例子可以告诉你如何避免使用Lambda:假设你使用的不是简单的is_adult,而是def is_bigger_than(x, threshold): return x > threshold。你希望为DatafameMapper中的“age”列应用x -> is_bigger_than(x, 18)。那么此时你不能:FunctionTransformer(lambda x: is_bigger_than(x, 18))),而是应该使用:FunctionTransformer(partial(is_bigger_than, threshold=18)),搞定! - 当卡在某个环节后,可以大胆尝试其他Pickle库,另外别忘了,一切问题都有解决方案。然而当你真的遇到非常棘手无法解决的问题,乒乓球或桌上足球也许会帮你找到能帮你的人。
最后,对于黑盒子方法,不仅会遇到特征工程工作中可能遇到的各类怪异问题,并且整个流程的方方面面都可能遇到更怪异的情况,例如让自定义的计分方法进行交叉验证,或者构建自定义的估算函数等!
演示
出于演示的目的,我重新写了上文所涉及脚本的简洁版本。我们将使用Sklearn和Pandas进行训练,并在服务器端使用Flask。此外还将在流程中使用序列化后的GridSearchCV。不用迟疑,演示代码库已发布。这里包含了两个软件包,第一个用于模拟训练环境,第二个用于模拟服务器环境。
另外请注意,现实应用中的情况远比演示代码更复杂,因此你很可能还需要使用编排机制处理模型的发布和转移。换句话说,你还需要妥善设计训练环节和服务器之间的链接。
作者:Amine Baatout,阅读英文原文:Machine Learning in Production, From trained models to prediction servers
