@liuhui0803
2016-10-18T09:18:53.000000Z
字数 4942
阅读 4871
Twitch是如何使用PostgreSQL的
AWS 云计算 工程 Postgresql Twitch
摘要:
Twitch的生产环境使用了大约125个数据库承载OLTP工作负载,这些数据库通常都包含在集群中,其中绝大部分都运行了PostgreSQL。他们使用了一种多地域拓扑,通过高弹性集群容量供应策略防范客户端故障,实现主节点快速故障转移,以及零停机凭据轮换。
正文:
Twitch的生产环境使用了大约125个数据库承载OLTP工作负载,这些数据库通常都包含在集群中。其中有大约4%的数据库运行了MySQL,2%运行Amazon Aurora,其余全部运行了PostgreSQL。我们自行管理着大部分数据库的供应、系统镜像、复制和备份,但大部分新集群都已运行在RDS for PostgreSQL上。
Twitch成立之初使用的原始中央数据库是我们管理过最有趣的集群。总的来说,这个集群的负载均值为每秒超过300,000笔事务。我们通过自行构建和维护的专用基础架构确保这套系统能够稳定、快速地处理所需工作负载。
我们使用了一种多地域拓扑,通过高弹性集群容量供应策略防范客户端故障,实现主节点快速故障转移,以及零停机凭据轮换。
拓扑
直到2015年底,整个集群以及网站和所有其他客户端都运行在我们自建主数据中心内的硬件上。受到AWS易于供应等优势的吸引,我们随后首先迁移了网站。考虑到AWS中的i2.8xlarge实例与我们自由硬件实例的规格类似,相比在自有数据中心内供应宿主机,AWS可实现更快速简单的供应,同时也为了进一步降低写入延迟,我们很快又将主宿主机和主要的可读副本集迁移到了AWS中。
为了简化计划内和紧急情况下的故障转移,我们还在另一个可用区域设置了热备份。在迁移至AWS过程中,我们还为系统镜像升级等事件制订了多个计划内故障转移规划,万幸这些计划都没有用得上。
我们希望能用有弹性的方式供应读取容量,因此所有可读副本都位于一个自动扩缩组(ASG)中,并通过启动配置(Launch Configuration)和Cloud-init自动加入集群。我们还开发了一个小型的运行状况检查HTTP服务,该服务运行于数据库所在宿主机上,该服务仅在副本可读的时候返回运行状况状态,因此可认为不会造成太大的负载。ASG连接到Elastic Load Balancer(ELB),使用前面提到的运行状况检查状态确保不会将查询路由至尚未准备好的宿主机。无法使用ELB的客户端可以通过本地HAProxy路由至可用的AWS副本集。
我们自有数据中心内依然保留了一些客户端应用程序。其中大部分并不需要写入数据,对复制延迟也不敏感,因此为了降低数据中心内部的查询延迟,我们还在自己的硬件上设置了一个可读副本。为了降低从AWS复制到自有数据中心的带宽占用,对于所有不充当可读副本的宿主机,我们只设置了两条传入的复制通信流。借此复制操作会通过串联的方式从一个副本中继至数据中心内的实时可读副本。第二台宿主机是热备宿主机,可在宿主机故障后对复制进行中继。这样客户端即可在数毫秒的时间内进行查询并获得结果,无需再用数毫秒进行查询并额外等待30毫秒让不同数据中心进行轮循。
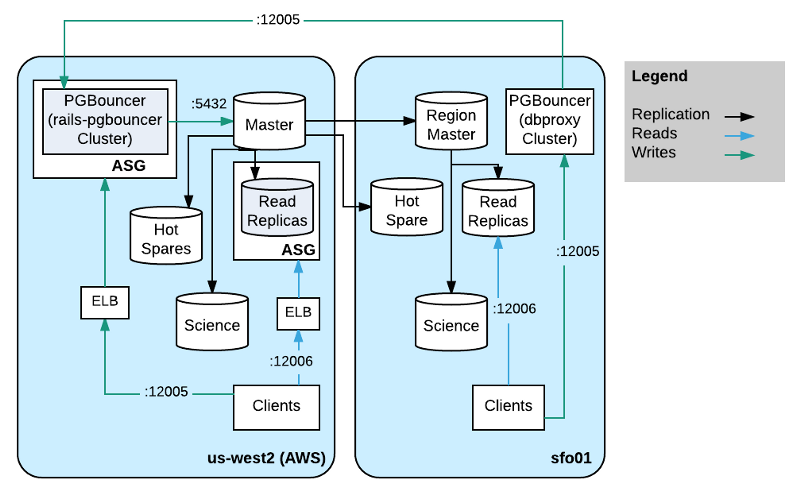
数据科学家、分析师、工程师,以及其他人偶尔可能需要进行即席查询。例如针对点播内容的上传情况生成直方图,每个数据中心内有一台不包含在实时可读集中的宿主机,由于这种宿主机并不是可读副本,因此可以将开销较高的即席查询以及对数据新鲜度不太敏感的报表交给它们处理。我们在这些节点postgresql.conf配置中设置了hot_standby_feedback = off和max_standby_streaming_delay = 6h,这样复制源就不会加重这些节点的负担,复制操作也不会因为多版本并发控制(MVCC)而导致查询被取消。这个做法极为有效,并被用在我们一些比较新的数据库集群中。
角色
凭据
每个团队在数据库中保存了一系列凭据。部分凭据之间存在重叠的现象,其中的关系和列可能被分配了读取和写入的访问权。我们希望实现零停机的凭据轮换,并想减少对这些角色分配读取和写入访问权时可能出现的错误。为此我们创建了3个角色,其中一个是无法登录的一类“组”角色,另外两个角色则从组角色中继承所需的权限。在凭据轮换之外的其他所有时间里,只允许一个具体的角色登录。例如可以创建类似下面这样的新角色:
create role team nologin; -- create a team rolecreate role team_01 with encrypted password ‘md5…’; -- current active rolecreate role team_02 with encrypted password ‘md5…’ nologin; -- disabled rolegrant team to team_01; -- gives team_01 the same rights as teamgrant team to team_02; -- gives team_02 the same rights as team
为了实现零停机凭据轮换,可启用下一个角色,例如:
alter role team_02 login;
随后将该角色及其密码分发给所有客户端,最后可通过下列命令禁用原来的角色:
alter role team_01 nologin;
“昂贵查询”保护
过去几年来,我们经常会发布一些会运行高成本查询的代码,例如进行聚合或顺序扫描的代码。在发布了这种高成本查询后,后端系统会开始占用所有CPU时间,进而导致客户端备份和查询无法及时进行,或由于副本中的MVCC规则而最终失败。为了解决这一问题,我们为每个角色通过相应的statement_timeout设置了每条语句的执行时间上限。
与所指派的权限不同,这些参数是不能继承的,因此必须为每个活跃角色进行设置。
alter user team_01 set statement_timeout = ‘1s’;alter user team_02 set statement_timeout = ‘1s’;
虽然集群负载依然有可能变得很高,但通过这样的设置至少可以为我们提供足够的容量,让不相关的查询能够用更慢的速度获得响应,这总比完全无法获得响应要好。
PGBouncer
由于每个团队都需要访问数据库,因此产生了很多角色。由于可用的PostgreSQL进程数量有限,有时候不同角色需要相互竞争,这意味着一个客户端中存在的瑕疵可能因为耗尽了可用连接导致其他客户端无法访问。为了防止这种问题,我们使用PGBouncer提供了虚拟架构名(Schema name),并为数据库架构提供别名。PGBouncer中的每个虚拟架构都只能接受有限数量个连接,当客户端连接到自己的虚拟架构后,只能耗尽自己的连接池。例如你可以在PGBouncer配置文件中看到下列内容:
[databases]site_sitedb = dbname=sitedb host=127.0.0.1 pool_size=70 port=5432sso_sitedb = dbname=sitedb host=127.0.0.1 pool_size=8 port=5432
上述配置为site角色提供了70个到sitedb的连接,而sso服务可以获得8个连接。
PGBouncer会运行在事务模式下,因此后端将能以尽可能快的速度对其他客户端表现为可用。Go的lib/pq会在查询中使用带参数的匿名预处理语句,这一特性无法用于默认配置的PGBouncer中,否则后端会在 预处理和执行两种状态之间切换。为了解决这一问题,我们为PGBouncer创建了一个可以检测匿名预处理的分支,并能让后端系统一直等待直到执行参数已提供。最新版github.com/lib/pq已经可以通过在连接字符串中指定binary_parameters=yes的方式使用主流版本的PGBouncer。binary_parameters参数主要由lib/pq使用,借此可避免参数化查询的第二次轮循。我们的客户端应用程序已经进行了移植,可继续使用主线版本而非我们自己的分支版本。
路由
由于以单线程应用程序的方式运行PGBouncer,有一度时间CPU长期100%满载,并导致连接停顿。我们有一个专用的初始配置,包含2颗处理器,每颗负责侦听不同端口并将流量重定向至PostgreSQL后端。由于有2颗处理器分摊负载,虽然不再100%满载,但CPU占用率依然很高。在每台运行PGBouncer的宿主机上还运行了HAProxy并负责侦听一个端口,同时为所有PGBouncer进程提供代理服务。这样即可让每台宿主机获得一个单一的客户端端点,进而简化配置。
对于可读副本,PGBouncer和HAProxy都与PostgreSQL运行在同一台宿主机上,并会代理至本地PostgreSQL。
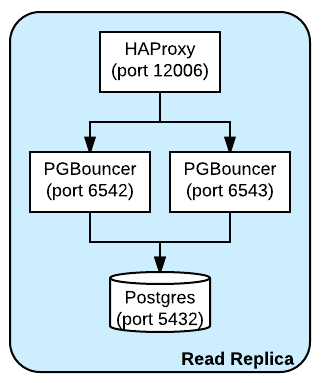
此外还有一个小规模宿主机集群运行了类似的PGBouncer配置,不过它们都指向了主数据库宿主机。PGBouncer集群位于一个ASG中,因此可以轻松缩放,此外还通过ELB指向ASG成员,其中也包含了在一个端口上进行侦听的HAProxy,可将流量代理至本地运行的PGBouncer进程。借助这样的设置,如果需要增加新的主副本,只需要更改集群配置并重启动PGBouncer。借此主副本的增加对客户端将完全透明,不过客户端会在短时间内遇到写入失败的情况。
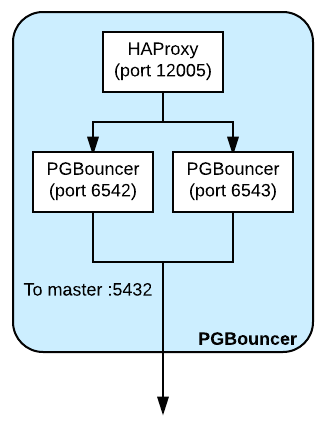
更好的做法是让客户端能够与尽可能接近的后端PGBouncer进行通信。我们一度遇到过这样一个问题:主副本之前有两个PGBouncer集群,一个位于AWS中,另一个位于我们自己的数据中心内。当集群与主副本不在一个地区时,可感知协议的代理遇到了比较大的性能问题,因此我们重新换为使用HAProxy实现跨地区通信,并只使用距离最近的PGBouncer集群。
问题
上文介绍的架构运行得很不错,但也产生了几个问题。
MVCC
PostgreSQL在多版本并发控制(MVCC)方面做的有些差。由于存储工作方式的缘故或可能还有其他原因,副本必须与主要版本在磁盘上保持严格一致。我们曾经看到大量语句由于恢复冲突而被取消这样的错误而无法获得结果集。但通过在每个角色的配置文件中通过statement_timeout和hot_standby_feedback = on设置进行较为激进的限制后,这一问题也不再困扰我们。
连接
Postgresql.conf中max_connections的值会被编码至复制流中,因此无法执行某些操作,例如使用比副本更高的max_connections值从主副本进行复制。为了增大集群中的这个值,只能分别针对每个副本进行设置(还需要重启动),然后使用max_connections的新值对主副本进行故障转移。
大型升级
执行PostgreSQL的大版本升级,例如从9.4升级至9.5,如果数据或负载量非常大,这样的升级需要较长的停机时间或逻辑复制流,而不能使用内建的预写式日志(Write ahead log,WAL)流。如果使用转储和加载的方式,仅数据本身的传输就需要大量时间。此外还有pg_upgrade有可能导致较长的停机时间,或虽然只经历较短停机时间,但在存储完全重写之前可用容量将始终保持低位。
在最近一次大版本升级过程中,我们构建了两个并行集群,为逻辑复制安装了Slony,将数据复制到新集群,并让逻辑工作队列“重播”。这一过程需要数周时间进行规划和设置,数据本身的复制也需要一整天。尽管需要用极长的时间进行准备,但停机时间仅1分钟。
结论
Twitch针对生产环境中的数据存储和分析使用了多种不同技术。
- 对于键值数据,使用Redis当作缓存,磁盘作为持久存储。
- 对于高写入负载数据用例,使用了大量DynamoDB表。
- 数据库之间的迁移工作会将数据流传输至Kinesis。
- 事件流存储在S3中。
- 数据分析选择了Redshift。
- OLTP用例方面,我们依赖PostgreSQL。
这样做是因为我们发现PostgreSQL已经成为一种高性能、可靠的SQL ACID关系型数据库。
作者:Aaron Brashears,阅读英文原文:How Twitch Uses PostgreSQL
