@liuhui0803
2016-08-14T23:21:34.000000Z
字数 25725
阅读 4825
无服务器体系结构
无服务器 DevOps 体系结构 云计算
摘要:
无服务器是软件体系结构世界中的热门话题。在这一领域我们已经看到很多书籍、开源框架、大量不同类型的供应商和产品,甚至专门的会议活动。但无服务器到底是什么,为什么值得(或不值得)考虑该技术?希望本文能为你提供一些启发。
正文:
无服务器体系结构是指大量依赖第三方服务(也叫做后端即服务,即“BaaS”)或暂存容器中运行的自定义代码(函数即服务,即“FaaS”)的应用程序,AWS Lambda是目前最著名的供应商。通过采用这样的方式并将大部分行为移至前端,这种体系结构使得应用程序内部不再需要具备传统的“始终运行”的服务器系统。取决于具体情况,尽管对供应商依赖增加了,并且(目前)配套服务还不成熟,但此类系统依然可以大幅降低运维成本和复杂度。
无服务器是软件体系结构世界中的热门话题。在这一领域我们已经看到很多书籍、开源框架、大量不同类型的供应商和产品,甚至专门的会议活动。但无服务器到底是什么,为什么值得(或不值得)考虑该技术?通过出版物的进化这篇文章,希望能针对这些问题向你提供一些启发。
首先我们要介绍无服务器到底是“什么”,在介绍这种技术的优势和劣势时我会尽量保持中立 – 下文将分别探讨这些问题。
无服务器是什么?
与软件行业很多其他趋势类似,关于“无服务器”到底是什么并没有一个清晰直观的看法,而涉及到两个截然不同但又相互重叠的领域后,问题就更突出了:
- “无服务器”这个称呼最早被用于描述大量或完全依赖(“位于云中的”)第三方应用程序/服务管理服务器端逻辑和状态的应用程序。这些程序通常是使用可通过云访问的数据库(例如Parse、Firebase)、身份验证服务(例如Auth0、AWS Cognito)等庞大生态系统的“富客户端”应用程序(例如只包含一个页面的Web应用或移动应用)。这类服务以往也被叫做“(移动)后端即服务”,下文会将其简称为“BaaS”。
- “无服务器”也可以指部分服务器端逻辑依然由应用程序开发者来编写的应用程序,但与传统体系结构的不同之处在于,这些逻辑运行在完全由第三方管理,由事件触发的无状态(Stateless)暂存(可能只存在于一次调用的过程中)计算容器内。(感谢ThoughtWorks在他们最近的Tech Radar中对这种情况的定义。)这种做法可以看作“函数即服务/FaaS”。AWS Lambda是目前最流行的FaaS实现,但除此之外也有其他实现。下文将使用“FaaS”作为无服务器这种运用方式的简称。
“无服务器”的起源
“无服务器”这个词并不好理解,因为有很多应用程序的服务器硬件与进程运行在不同位置,但与传统方式的差异之处在于,构建和支持“无服务器”应用程序的组织并不需要考虑服务器或进程,这些东西可以外包给供应商。
这个词首次出现大概是在2012年,包含在Ken Fromm撰写的这篇文章中。Badri Janakiraman说他也在这段时间前后在持续集成和托管服务式的源代码控制系统领域听到过这个词,但并不是用来代表某个公司自己的服务器。这种用法侧重的是基础结构的开发,并未将其纳入具体产品。
当亚马逊于2014年发布AWS Lambda后,2015年这个词开始变得广为人知,亚马逊在2015年7月发布API网关后这个词也变得愈加热门。这里有一个例子,API网关公布后,Ant Stanley写了一篇有关无服务器的帖子。2015年10月,亚马逊的re:Invent大会中有一场名为“使用AWS Lambda搭建的无服务器公司”的讲话,其中介绍了PlayOn! Sports这家公司。2015年底,“Javascript Amazon Web Services(JAWS)”开源项目更名为无服务器框架(Serverless Framework),使得这一势头愈加热烈。
快进到今天(2016年中期),我们可以看到更多范例,例如最近举办的无服务器大会以及各种无服务器供应商,从产品描述到工作岗位介绍,都在广泛使用这个词。无论怎样,“无服务器”这个词成了“网红”。
本文将主要介绍上文提到的第二个领域,因为这个领域是最新出现的,与我们以往对技术体系结构的看法有更大不同,并且围绕无服务器这个词在这个领域有更多宣传炒作。
然而这些概念其实是相互关联,实际上甚至会逐渐会聚的。例如Auth0就是个很好的例子 – 这个技术最开始属于BaaS形式的“身份验证即服务”,但随着Auth0 Webtask的发布开始步入FaaS领域。
在很多情况下,当开发一款“BaaS形式”的应用程序时,尤其是在开发“富”Web应用而非移动应用时,可能依然需要一定数量的自定义服务器端功能。此时FaaS函数是一种很好的解决方案,尤其是需要在某种程度上与正在使用的某些BaaS服务进行集成时。这类功能的例子包括数据验证(防范仿冒客户端)以及计算密集型处理(例如图片或视频操作)等。
举几个例子
UI驱动的应用程序
想象一个包含服务器端逻辑,面向客户端的传统三层系统。例如典型的电商应用(可以说在线宠物店吗?)
传统体系结构看起来类似下图,假设服务器端使用Java实现,并使用HTML/Javascript组件作为客户端:

这种体系结构下的客户端会显得相当笨重,系统中身份验证、页面导航、搜索、事务等大部分逻辑都是由服务器应用程序实现的。
如果使用无服务器体系结构,看起来将会是这样:

这是个大幅简化的视图,尽管如此其中也包含大量显著改动。请注意这并非为了向你推荐迁移时所要使用的架构,此处使用的这种架构仅仅为了介绍无服务器相关概念!
- 我们删掉了原始应用程序中的身份验证逻辑,并使用第三方BaaS服务代替。
- 作为BaaS的另一个例子,我们让客户端直接访问数据库子集(用于列出产品),而该数据库完全由第三方承载(例如使用AWS Dynamo)。我们还为访问数据库的客户端提供了不同的安全配置文件,这样即可从任何服务器资源访问数据库。
- 上两点引出了非常重要的第三点:一些原本位于宠物店服务器上的逻辑,例如追踪用户会话,理解应用程序的UX结构(例如页面导航),从数据库读取并转换为可用视图等,现在被放入到客户端中。实际上客户端现在已经变成了一个单页应用程序(Single Page Application)。
- 我们希望将一些与UX有关的功能继续保留在服务器上,例如计算密集型功能或需要访问大量数据的功能。“搜索”就是个很好的例子。搜索功能无需使用持续运行的服务器,而是可以用一个能通过API网关(下文将详细介绍)响应Http请求的FaaS函数来实现。可以通过这样的客户端或服务器函数从同一个数据库中读取产品数据。
由于原本的服务器是通过Java实现的,而AWS Lambda(本例中使用的FaaS供应商)支持通过Java实现的函数,无须彻底重写即可将搜索功能的代码从宠物店服务器直接移至宠物店搜索函数。 - 最后还可以使用另一个FaaS函数取代原本的“购买”功能,但出于安全考虑依然将其保留在服务器端,而非在客户端重新实现。这也是一种API网关的前端。
消息驱动的应用程序
另一个例子是后端数据处理服务。假设编写的某个以用户为中心的应用程序需要快速响应UI请求,但你希望随后能记录发生的所有类型的操作。例如在线广告系统,用户点击广告后你希望非常快速地将用户重定向至目标广告,但为了向广告主收费,与此同时你还希望记录已发生点击这件事。(这并不是虚构的例子,我以前在Intent Media所属的团队就因为这个原因重新设计了自己的系统。)
传统方式下这种系统的体系结构可能是类似这样的:“广告服务器”会以同步的方式响应用户(由于只是例子,我们并不需要关心具体的交互),同时需要向渠道发布一条消息并由负责更新数据库的“点击处理器”应用程序以异步的方式处理,例如扣掉广告主的部分预算。

在无服务器的世界中,这个系统应该是这样的:

和上一个例子相比,本例中两种体系结构的差异很小。我们将需要长期运行的消费者应用程序替换为一个在供应商提供的事件驱动的上下文中运行的FaaS*函数*。请注意该供应商同时提供了消息代理(Message Broker)和FaaS环境,这两个系统非常紧密地相互结合在一起。
通过实例化(Instantiating)函数代码的多个副本,FaaS环境可以并行处理多个点击,这主要取决于最初流程的编写方式,同时这也是一个需要考虑的新概念。
理解“函数即服务”
上文已多次提到FaaS这种想法,但还需要深入考虑一下这到底是什么意思。为此我们一起看看亚马逊Lambda产品的公开描述。我将这些描述划分成几点,下文将分别展开介绍。
AWS Lambda可供你在无须供应或管理服务器的情况下运行自己的代码。(1) ... 借助Lambda,你可以为几乎任何类型的应用程序或后端服务运行所需代码 (2) - 所有环境完全无须管理,只需要上传自己的代码,Lambda将自动完成运行代码所需的一切条件 (3) 并可进行伸缩 (4) 你的代码将实现高可用。你可以将代码设置为通过其他AWS服务自动触发运行 (5) 或直接从任何Web或移动应用内部调用 (6)。
- 从本质上来说,FaaS意在无须自行管理服务器系统或自己的服务器应用程序,即可直接运行后端代码。其中所指的 - 服务器应用程序 - 是该技术与容器和PaaS(平台即服务)等其他现代化体系结构最大的差异。
回想上文列举的点击处理系统那个例子,可以用FaaS取代点击处理服务器(可能是物理计算机,但绝对需要运行某种应用程序),这样不仅不需要自行供应服务器,也不需要全时运行应用程序。 - FaaS产品不要求必须使用特定框架或库进行开发。在语言和环境方面,FaaS函数就是常规的应用程序。例如AWS Lambda的函数可以通过‘一等公民’Javascript、Python以及任何JVM语言(Java、Clojure、Scala)等实现。然而Lambda函数也可以执行任何捆绑有所需部署构件的进程,因此可以使用任何语言,只要能编译为Unix进程即可(参阅下文的Apex)。FaaS函数在体系结构方面确实存在一定的局限,尤其是在状态和执行时间方面,这些会在下文详细介绍。
再次回想上文提到的点击处理范例,在迁往FaaS的过程中,唯一需要修改的代码是“主方法/启动”代码,其中可能需要删除顶级消息处理程序的相关代码(“消息监听器接口”的实现),但这可能只需要更改方法签名即可。在FaaS的世界中,代码的其余所有部分(例如向数据库执行写入的代码)无须任何变化。 - 由于无须运行任何服务器应用程序,相比传统系统,部署方法会有较大变化 – 将代码上传至FaaS供应商,其他事情均可由供应商完成。目前这种方式通常意味着需要上传代码的全新定义(例如上传zip或JAR文件),随后调用一个专有API发起更新过程。
- 横向伸缩过程是完全自动化且有弹性的,由供应商负责管理。如果系统需要并行处理100个请求,你自己无须任何额外配置,供应商可全部搞定。负责执行你的函数的‘计算容器’只会短暂存在,FaaS供应商将完全根据运行时需求自动供应和撤销。
继续回到点击处理器那个例子。假设某天运气好,客户的广告点击量是平时的10倍。点击处理应用程序能否顺利处理?例如我们的代码能否同时处理多条消息?就算能处理,只使用一个应用程序实例是否足以应对激增的负载?如果可以运行多个进程,是否要自动伸缩,或者需要手工修改配置?如果使用FaaS,需要在编写函数的过程中就考虑到这些问题,但随后将由FaaS供应商自动完成伸缩相关的任务。 - FaaS中的函数可以通过供应商定义的事件类型触发。对于亚马逊AWS,此类触发事件可以包括S3(文件)更新、时间(计划任务),以及加入消息总线的消息(例如Kinesis)。通常你的函数需要通过参数指定自己需要绑定到的事件源。对于点击处理程序,我们假设已经使用了可被FaaS支持的消息代理。如果不支持,则需要换为使用可支持的,并且也可能需要更改消息的创建方。
- 大部分供应商还允许函数作为对传入Http请求的响应来触发,通常这类请求来自某种该类型的API网关(例如AWS API网关、Webtask)。我们在宠物店例子中为“搜索”和“下单”函数使用了这种触发方式。
状态
在本地(机器/实例范围内)状态方面FaaS函数会遇到很多局限。简而言之你需要假设对于函数的任何调用,你所创建的任何进程内或主机状态均无法被任何后续调用所使用。包括内存(RAM)中的状态以及写入本地磁盘的状态。换句话说,从部署单位的角度来看,FaaS函数是无状态的。
虽然影响因素还有很多,但这会对应用程序体系结构产生巨大影响。“十二要素应用(Twelve-Factor App)”这一概念也存在完全相同的局限。
考虑到这种局限,备选方案有哪些?通常这意味着FaaS函数可能是天然无状态的,例如只是单纯对输入内容提供功能的转换,或者可以使用数据库、跨应用程序缓存(例如Redis)或网络文件存储(例如S3)跨越不同请求存储状态,以进一步将其作为其他请求的输入。
执行时间
FaaS函数通常会对每次调用可以执行的时间长度有所限制。目前AWS Lambda函数只能运行不超过5分钟,超过这一时间将被终止。
这意味着如果不进行重构,某些类型的“长寿”任务不适合使用FaaS函数,例如可能需要创建多个相互协调的FaaS函数,而在传统环境中只需要用一个“长寿”的任务同时负责协调和执行。
启动延迟
目前来说,FaaS函数需要等待多长时间才能响应请求,这取决于多种因素,具体时间可能介于10毫秒到2分钟之间。听起来很糟糕,但我们一起用AWS Lambda作为例子更深入地看看这个问题。
如果函数使用Javascript或Python实现并且不大(例如不到五百行代码),那么运行该函数的开销通常绝对不会超过10-100毫秒。更大的函数偶尔可能需要更长时间。
如果你的Lambda函数是通过JVM实现的,由于JVM需要逐渐启动,响应时间偶尔可能会显得较长(例如超过10秒)。然而只有在下列情况下才会存在这样的问题:
- 不同调用之间偶尔需要以超过10分钟的间隔处理函数处理事件。
- 流量突然激增,例如通常每秒只需处理10个请求,但突然在不到10秒内需要每秒处理100个请求。
通过用没什么技术含量的手段每5分钟Ping一下函数,使其保活,前一种问题在某些情况下可以避免。
是否需要担心这些问题,主要取决于应用程序的类型和流量模式。我以前加入的一个团队使用Java实现了异步消息处理Lambda应用,该应用每天需要处理数以百亿计的消息,他们就不需要担心启动延迟的问题。话虽如此,如果你要编写一个低延迟的交易应用程序,无论使用什么语言实现,现阶段可能都不会想使用FaaS系统。
无论是否觉得自己的应用会遇到这样的问题,你都需要使用类似生产环境的负载进行测试,看看能获得怎样的性能。如果你的用例目前还无法支持,也许可以过几个月再试试,因为目前FaaS供应商都在努力对这一领域进行完善。
API网关

上文还提到过FaaS一个比较重要的内容:“API网关”。API网关是一种HTTP服务器,通过在配置中定义路由/端点,可将每个路由与某一FaaS函数关联在一起。当API网关收到请求后,会查找与该请求匹配的路由配置,随后调用相应的FaaS函数。通常来说API网关会将Http请求的参数与FaaS函数的输入参数映射在一起。API网关会将FaaS函数的调用结果转换为Http响应,并将其返回给原始调用方。
Amazon Web Services有自己的API网关,其他供应商也提供了类似的能力。
除了最基本的请求路由,API网关还可以执行身份验证、输入验证、响应代码映射等功能。你可能会从直觉上纳闷这样做是否真是个好办法,先把这个想法暂时放一放,下文还将进一步介绍。
API网关+FaaS的用例之一是在无服务器系统中创建以Http为前端的微服务,并通过FaaS获得伸缩、管理,以及其他各类收益。
目前与API网关有关的工具还非常不成熟,因此使用API网关定义应用程序这种做法很可能需要你足够大胆。
工具
上文有关API网关工具还不成熟的观点实际上也适用于整个无服务器FaaS大环境。不过凡事总有例外,例如Auth0 Webtask对于工具开发的重视远远超过开发者UX的完善。Tomasz Janczuk在最近举办的无服务器大会上也很好地阐述了自己对相关工具的重视。
总的来说,无服务器应用的调试和监控都很麻烦,我们也会在下文详细介绍这个问题。
开源
无服务器FaaS应用程序的主要收益之一在于可以透明地实现生产运行时供应,因此目前开源对这一方式的意义并不像对于Docker和容器等技术的意义那么大。未来我们可能会看到一些主流的FaaS/API网关平台可以支持在“本地”,或开发者的工作站上运行。IBM OpenWhisk就是此类实现的一个例子,我们很期待看到类似这样的实现最终能获得更大范围的采用。
尽管除了运行时实现,已经有开源的工具和框架可以为定义、部署、运行提供帮助。例如无服务器框架使得API网关+Lambda的使用过程变得比AWS更简单,虽然这种方式大量依赖Javascript,但如果你要编写JS API网关应用,绝对值得一试。
另一个例子是Apex,这个项目可以“更轻松地构建、部署和管理AWS Lambda函数”。Apex尤其有趣的一点在于,该技术可供你用亚马逊不直接支持的语言开发Lambda函数,例如Go语言。
无服务器不是什么?
至此本文已经介绍了“无服务器”是好几个不同概念的结合,例如“后端即服务”和“函数即服务”,并且还对第二个概念进行了详细的介绍。
在开始介绍这一技术最重要的收益和不足之处前,我还想进一步谈谈这一概念的定义,至少要讨论一下无服务器“不是”什么。我曾发现很多人(包括我自己以前)对这些概念感到困惑,因此有必要进行澄清。
与PaaS相比
考虑到无服务器FaaS函数其实非常类似于12要素应用,那么无服务器是否像Heroku一样仅仅是另一种类型的“平台即服务”(PaaS)?引用Adrian Cockcroft的观点作为答案吧。
“如果你的PaaS可以非常高效地在20毫秒内启动实例,并将该实例运行0.5秒,那就将其称之为‘无服务器’吧。 —— @adrianco”
换句话说,大部分PaaS应用程序并不适合针对每个请求让整个应用程序上线并下线,而FaaS平台就是为实现这一做法而生的。
但那又怎样,如果我精通12要素应用的开发,具体如何写代码其实也没什么不同?没错,但应用的运维方式会有翻天覆地的变化。我们都是精通DevOps的工程师,对运维和开发的重视程度是相同的,对吧!
FaaS和PaaS在运维方面的最大差异在于伸缩。大部分PaaS依然需要考虑伸缩,例如对于Heroku,到底需要运行几个Dyno?但FaaS应用程序完全无须考虑这些问题。就算配置PaaS应用程序进行自动伸缩,但也无法在特定请求层面上做到这一点(除非具备非常有针对性的流量塑形配置文件),因此在成本方面FaaS应用程序效率更高。
尽管能获得这样的收益,又为什么还要继续使用PaaS?原因有很多,工具和API网关的成熟度可能是其中最重要的。另外12要素应用在PaaS中的实现为了进行优化可能需要使用应用内只读缓存,FaaS函数还无法支持这种技术。
与容器相比
使用无服务器FaaS的另一个原因在于避免在操作系统层面或更底层的层面管理计算过程。平台即服务(例如Heroku)也能实现这一点,但上文已经介绍过PaaS与无服务器FaaS的差异。容器是另一种流行的过程抽象方式,例如Docker已成为此类技术最明显的例子。我们还发现诸如Mesos和Kubernetes等容器承载系统正在开始普及,这些技术可以将特定应用程序从操作系统级别的部署中抽象出来。另外还有云端承载的容器平台,例如Amazon ECS和Google Container Engine,这些技术与无服务器FaaS类似,可以让用户完全无须管理自己的服务器系统。那么容器技术的发展势头这么迅猛,还需要考虑无服务器FaaS吗?
我对于PaaS的主要观点依然适用于容器技术,对于无服务器FaaS来说,伸缩是自动实现的,是透明的,是非常细化的。容器平台目前还无法满足这些特征。
另外我想说的是,虽然过去几年来容器技术的流行度与日俱增,但这个技术依然尚未成熟。这不是说无服务器FaaS更成熟,只不过无论如何你只能在各种都不完善的技术中做出选择。
不过也要承认,随着时间流逝,这些争议终将消失。虽然容器平台目前还做不到无服务器FaaS那样程度的无需管理、自动伸缩等特性,但我们也注意到诸如Kubernetes的“Horizontal Pod Autoscaling”等技术正在继续向着这个目标努力。我认为这些功能会逐渐包含某些非常智能的流量模式分析,以及与负载更为密切相关的衡量指标。并且Kubernetes的快速演化也许很快就能为我们提供一个极为简单稳定的平台。
考虑到无服务器FaaS和托管式容器在管理和伸缩方面的差距,选择的余地也将缩小,可能只需要考虑应用程序的风格和类型。例如对于事件驱动的应用,并且每个应用程序组件只需要处理少数类型的事件,此时FaaS将是最佳选择;对于包含很多入口点,由同步请求驱动的组件,则更适合使用容器。我预计5年内很多应用程序和团队将同时使用这两种体系结构,很期待尽快看到这样的使用模式日益涌现。
#NoOps
无服务器并不是指‘无须运维’,取决于你在无服务器的道路上能走多远,可能是指“无须内部系统管理员”。这方面需要考虑两个重要问题。
首先,“运维”不光是服务器本身的管理,还意味着监控、安全、网络,以及大部分情况下必不可少的生产调试和系统伸缩。无服务器应用中依然存在这些问题,需要制定相应的策略。某些情况下无服务器世界中的运维可能更难,主要因为这还是一种比较新的技术。
其次,就算系统本身的管理工作也是存在的,只不过将其外包给了无服务器技术供应商。这不是什么坏事,很多东西都被我们外包了。但取决于你希望实现的精确程度,这种做法是好是坏还有待商榷,无论哪种方式,在某种程度上这样的抽象都有可能渗漏,你必须意识到依然是由人类系统管理员在为你的应用程序提供支持。
Charity Majors在最近举办的无服务器大会上针对这个话题做了一次非常棒的演讲,建议当本次演讲发布到网上后大家都能去看看。在这之前你可以阅读她写的这篇以及这篇文章。
存储过程即服务
我发现无服务器FaaS还有着“存储过程即服务”的特征。我觉得这一特征主要源自很多FaaS函数(包括我在本文中用到的那些)都是围绕数据库访问编写的小规模代码片段。如果我们对FaaS的全部应用仅限于此,那么这名字还是很贴切的,但由于这只是FaaS各种能力中的一部分,对FaaS的这种看法实际上是一种无效的约束。

“我担心如果无服务器服务终将变成类似存储过程的技术,一个原本挺好的想法可能很快欠下一大堆技术债。 —— @skamille”
话虽如此,依然有必要考虑FaaS是否会遇到一些与存储过程相同的问题,例如在上述引用的推文中Camille提到的有关技术债的担忧。使用存储过程的过程中我们学到了很多经验,有必要在FaaS的世界中仔细反省一下这些问题,看看是否会出现类似的情况。存储过程所面临的一些问题包括:
- 通常需要供应商明确指定的语言,或至少需要供应商针对某一语言指定的框架/扩展。
- 由于需要在数据库的上下文情境中执行因此难以进行测试。
- 很难像对待“一等公民应用程序”那样实现版本控制/处理。
并非所有存储过程的实现都会遇到上述问题,但我以前的工作中都遇到过。FaaS是否也存在此类问题:
目前我所接触过的FaaS实现都无须担心(1),这一条可以划掉了。
对于(2),由于需要面对的“仅仅是代码”,单元测试过程将与其他任何代码一样易行。集成测试则是另一个截然不同(并且非常合理)的问题,下文将详细介绍。
对于(3),需要再次重申,由于FaaS函数面对的“仅仅是代码”,因此版本控制很好实现。但在应用程序打包方面目前还没有出现较为成熟的模式。上文提到的无服务器框架提供了自己的打包模式,AWS也于2016年5月在无服务器大会上宣布自己也会开发一种打包技术(“Flourish”),但目前这依然是一个值得我们关注的问题。
收益
上文主要定义并解释了无服务器体系结构的含义。下文将探讨用这种方式设计和部署的应用程序所能获得的收益和存在的不足。
需要注意的是,其中一些技术还很新。截止撰写本文时,最领先的FaaS实现AWS Lambda诞生也还没超过2年。因此再过两年后,目前我们所获得的一些收益看上去可能也像是炒作,而目前的一些不足之处届时可能也已经妥善解决了。
由于这些结论尚未经过大范围的实践证实,你在决定使用无服务器技术前一定要慎重考虑。希望本文列出的利弊清单可以帮你顺利做出决策。
首先准备展望一下美好生活,说说无服务器技术能带来的优势。
降低运维成本
从本质上来看,无服务器技术实际上是一种外包解决方案。该技术可以让你雇佣别人代替你管理服务器、数据库,甚至应用程序逻辑。由于使用的都是可以同时被他人共用的预定义服务,这里也存在着很大的规模经济效益,当一个供应商可以同时运行数千个类似的数据库时,每个用户支付的费用自然更低。
对你来说,成本的降低共体现在两方面:基础结构成本和人员(运维/开发)成本。虽然部分成本收益可能只来源于与其他用户分享基础结构(硬件、网络),但人们这样做的预期在于大部分情况下相比自行开发和托管的系统,用在外包无服务器系统上的时间会少很多(因此可以降低运维成本)。
然而这种收益和基础结构即服务(IaaS)或平台即服务(PaaS)所提供的收益并无太大区别。但我们可以通过两种主要方式对这些收益进行扩展,分别是无服务器BaaS和无服务器FaaS。
BaaS – 降低开发成本
IaaS和PaaS基于这样的一种前提:服务器和操作系统的管理工作可成为一种商品化的服务。然而无服务器后端即服务可以让整个应用程序组件成为商品化的服务。
身份验证就是个很好的例子。很多应用程序需要开发自己的认证功能,其中通常会包含诸如注册、登录、密码管理、与其他认证服务供应商的集成等功能。总的来说大部分应用程序的此类逻辑都是类似的,因此诞生了类似Auth0这样的服务,可以让我们将已经创建好的认证功能集成在自己的应用程序中,无须自行开发。
BaaS数据库也是类似的情况,例如Firebase的数据库服务。一些移动应用程序团队发现让自己的客户端直接与服务器端的数据库进行通信,往往会采用这样的做法。BaaS数据库避免了大部分数据库管理负担,此外这类服务通常还提供了可满足无服务器应用所需模式的,用于为不同类型用户提供所需认证方法的机制。
取决于你的知识背景,这些方式可能会让你感到坐立不安(别着急,具体原因会在下文不足之处一节详细介绍),但不可否认的是,很多打造出成功产品的成功公司所依赖的绝不仅仅是自己服务器端运行的代码。Joe Emison 在最近举行的无服务器大会上针对这个话题给出了几个例子。
FaaS – 伸缩成本
正如上文所述,无服务器FaaS的好处之一在于“横向伸缩是完全自动化高弹性的,且将由服务供应商负责管理”。这种做法可以提供诸多收益,但从最基本的基础结构层面来说,最大的收益在于你只用为自己需要的计算能力付费,而在AWS Lambda这样的服务中甚至可以将计费粒度细化至100毫秒。取决于流量规模和类型,这一特性可能会为你提供巨大的经济效益。
范例 – 偶发请求
假设你运行的某个服务器应用程序只需要每分钟处理1个请求,每个请求的处理需要花费50毫秒,而一小时的时间内CPU平均使用率为0.1%。从某种观点来看,这样的使用模式无疑是极为低效的,但如果有其他1000个应用程序和你共享CPU,大家都可以用这一台服务器顺利完成自己的任务。
无服务器FaaS就是为了解决这种低效问题,并能帮你降低成本。在这个场景中你每分钟只需要为100毫秒的计算时间付费,只占时间总量的0.15%。
这种方式还能提供下列连锁收益:
- 对于未来出现的,对负载要求非常低的微服务,可支持将整个组件拆分为不同的逻辑/领域,哪怕这种细化程度的运维成本原本根本不支持这样做。
- 这样的成本收益还能促进民主化。很多公司或团队很可能想要尝试一些新技术,如果通过FaaS满足自己的计算需求,“试水”产生的运维成本将显得微乎其微。实际上如果你的所有工作负载相对较小(但也并非完全微不足道),甚至可能不需要为计算能力支付任何费用,因为某些FaaS供应商提供的“免费层”服务就足够了。
范例 – 不均匀的流量
再看看另一个例子。假设你的流量特征呈现明显的“峰谷”,也许基准流量仅为每秒20个请求,但每五分钟会遇到一次每秒200个请求(常规数量的10倍)并持续10秒钟的情况。出于范例的目的,我们假设基准性能就已经让服务器满载运行,但你不希望在峰值时期延长响应时间。如何解决这个问题?
在传统环境中,为了应对峰值需求可能需要将硬件总容量提升10倍,但这样的容量只在4%的总运行时间内可以得到充分利用。自动伸缩功能在这里可能并不是一种好的做法,因为新的服务器实例需要一定时间“热身”才能正常运转,但当新实例启动完成后,峰值时期已经结束了。
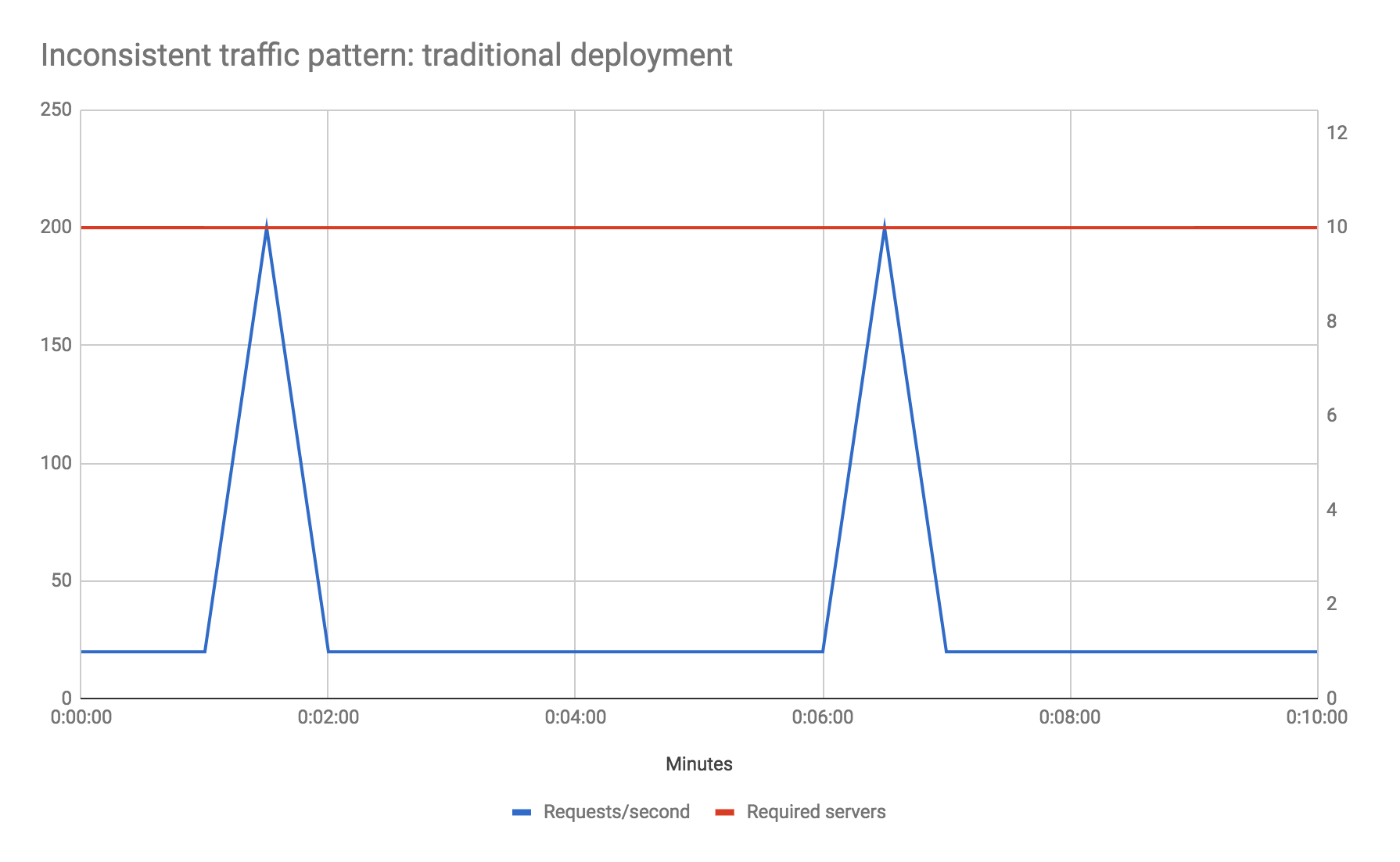
不过在无服务器FaaS环境中这一切不再是问题。甚至无须执行任何额外操作,可以直接认为流量是均匀分布的,并且只需要为峰值时期使用的额外计算资源付费。
很明显,为了凸显无服务器FaaS在节约成本方面所提供的巨大收益,这里列举的例子是很有针对性的,目的在于证明除非流量非常均匀一致,并且能充分利用整个服务器系统的全部资源,否则仅从伸缩的角度来看,使用FaaS可以帮你节约大量成本。
但上述例子中有个问题需要注意:如果你的流量是均匀的并且始终能够充分利用服务器资源,你可能无法获得这样的成本收益,此时使用FaaS反而可能会花更多钱。因此需要针对当前供应商的成本,以及传统方式下同等容量、全时间运行的服务器成本进行一定的权衡,看看自己能否接受这样的成本。
优化是节约某些成本的根本
关于FaaS的成本还有个有趣的问题:对自己的代码进行任何性能优化,不仅可以加快应用运行的速度,而且取决于所选供应商计费粒度的细化程度,还会对运维成本的降低立刻产生直接影响。举例来说,如果目前每个操作需要花费1秒钟,但将时间缩短至200毫秒,无须改动基础结构即可在计算成本方面立即节约80%。
简化运维管理
本节内容尤其需要注意:运维方面的某些问题对无服务器来说还较为麻烦,目前我们只准备谈谈该领域一些新出现的积极意义…
在无服务器BaaS端,运维管理工作比其他体系结构更简单的原因非常明显:支持的组件数量越少,工作量也就越低。
FaaS端的特征比较多,下文将深入介绍其中的几个。
FaaS伸缩能力提供的收益不仅限于成本
从上文的内容来看,伸缩是一种新特征,但也要注意FaaS的伸缩功能不仅可以降低计算成本,而且可以降低运维管理成本,因为伸缩工作可以自动完成。
如果伸缩过程是手工进行的,在最理想情况下,例如有专人负责给服务器阵列添加或删除实例,但如果使用FaaS可以完全忽略这一问题,让FaaS供应商代替你对自己的应用程序进行伸缩。
就算在非FaaS体系结构中可以使用“自动伸缩”,但这一过程依然需要设置和维护,FaaS完全无须执行这样的操作。
同理,因为伸缩是由供应商针对每个请求/事件分别进行的,你甚至再也不需要考虑自己最多可以处理多少并发请求才不至于耗尽所有内存或导致性能显著下降这样的问题,至少对于通过FaaS承载的组件无须考虑。由于负载可能激增,下游数据库和非FaaS组件也需要针对这种情况做好充分考虑。
降低程序包和部署的复杂度
虽然API网关本身比较复杂,但相比部署整个服务器,打包和部署FaaS函数的过程已大幅简化。只需要将代码编译并打包为zip/jar格式,随后上传即可。无须puppet/chef,无须启动/停止Shell脚本,无须考虑是否要在计算机上部署一个或多个容器。对于新手甚至无须打包代码,可以直接在供应商的控制台内编写代码(当然不推荐用这种方式编写生产代码!)。
这个过程很简单,在一些团队中可以提供巨大的收益:整个无服务器解决方案无须进行任何系统管理。
平台即服务(PaaS)解决方案也能提供类似的部署收益,但正如上文对FaaS和PaaS对比时提到的,FaaS的伸缩优势是独一无二的。
上市时间/实验
“简化运维管理”是工程师很熟悉的收益,但这对业务意味着什么?
最显著的意义在于成本:运维所需时间更少 = 运维需要的人员更少。但目前我认为最重要的意义在于“上市时间”。随着团队和产品变得愈加精益(Lean)和敏捷,我们会希望持续尝试新事物并快速更新现有系统。虽然直接重新部署即可对稳定状态的项目进行快速迭代,但更出色的新想法到首次部署能力使得我们能用最小阻力和最低成本完成各种新实验。
FaaS*新想法到首次部署*的特性很适合某些情况,尤其是对于通过供应商生态系统内已经成熟的事件触发简单函数这种情况。举例来说,假设你的组织正在使用类似Kafka的消息系统AWS Kinesis将不同类型的实时事件广播到整个基础结构。借助AWS Lambda,可以在几分钟内为这种Kinesis流开发并部署新的生产事件监听器,一天之内就可以完成各种不同类型的实验!
对于基于Web的API,由于存在各种不同用例,不能说真能有效简化运维,但各种开源项目和小规模的实现正在朝着这一目标努力。下文将进一步介绍。
“更绿色的”计算?
过去几十年来,全球数据中心的数量和规模都有了爆发式增长,这些数据中心的能耗,以及构建众多服务器、网络交换机等设备所需的物理资源用量也水涨船高。苹果、谷歌,以及其他类似的公司都开始谈到要将自己的数据中心部署在距离可再生能源更近的地区,以降低此类设施对化石燃料的用量。
这种显著增长的部分原因在于有越来越多的服务器大部分时候都是闲置的,但依然需要开机运行。
商用和企业环境中数据中心内典型的服务器在全年时间内只用到了运算能力总量的5-15%。
-- 福布斯
这样的效率实在非常低,并会对环境产生巨大影响。
一方面这要“归功于”云基础结构,因为企业可以根据需要随时“购买”更多服务器,不再需要预先妥善规划并供应所有必要的服务器。然而有人可能会争辩说,如果大量此类服务器用完之后置之不理,不进行妥善的容量管理,服务器供应过程的简化只会让整个情况变得更糟。
无论使用自行托管、IaaS或PaaS基础结构解决方案,我们依然需要决定应用程序在未来数月甚至数年内的容量需求。这一过程通常需要谨慎,没错,容量管理与过渡供应会导致上文提到的低效率问题。但在使用无服务器方法后,我们再也不需要自行确定有关容量的决定,反而可以让无服务器技术供应商根据自己的需求实时提供足够的计算容量。随后供应商可根据自己所有客户的需求确定自己的总容量需求。
这种差异可以让整个数据中心内所有资源得到更充分的利用,相比传统的容量管理方法可大幅降低对环境的影响。
不足之处
亲爱的读者朋友们,希望上面提到的各种显著优势能让你满意,因为随后我们要用现实“打脸”了。
无服务器体系结构很多方面让人欣喜,如果不是感觉这种技术为我们做出了很多美妙承诺,我根本不愿意花时间介绍,但各种优势和收益都是需要付出代价的。其中一些代价是这种概念与生俱来的,无法通过进一步发展彻底解决,考虑使用无服务器技术时绝对不能忽略这些问题。另外有些代价来自无服务器技术目前的实现,随着进一步完善这些问题有望得到顺利解决。
与生俱来的劣势
供应商控制
与任何外包策略类似,你需要将某些系统的控制权拱手让给第三方供应商。此类控制力的缺乏可能体现为系统停机、非预期的限制、成本变动、功能缺失、强迫的API升级等。上文曾经提过的Charity Majors在这篇文章中“权衡”一节详细探讨了这个问题:
[供应商的服务]如果足够智能,会对你使用服务的具体方式施加非常强大的约束,这样供应商才能以符合自己可靠性目标的方式供应这些服务。用户获得灵活性和丰富选项的同时,也会导致混乱和不可靠。如果平台供应商需要在你的幸福和数千个其他客户的幸福之间做出选择,他们绝对会选择“大多数” — 这也是他们应该做的。
多租户问题
多租户是指用同一台硬件甚至同一个托管应用程序,为多个客户(或租户)运行多个软件实例的做法。这种策略是实现上文所提到规模经济效益的关键。服务供应商会尽一切努力为自己的客户营造一种感觉,让客户认为自己是这套系统唯一的用户,优秀的服务供应商在这方面通常都做得很好。但凡事不可能完美,有时候多租户解决方案可能会造成一些问题,例如安全(一个客户可以看到另一个客户的数据)、健壮性(一个客户的软件错误导致其他客户的软件出错)、以及性能(高负荷客户导致其他客户的系统运行缓慢)。
无服务器系统也会面临这类问题,很多其他类型的多租户服务也不例外。但因为很多无服务器系统是新出现的,相比其他已经逐渐成熟的系统,无服务器可能会遇到更多此类问题。
供应商锁定
所有涉及第三方的系统都会遇到类似的问题:无服务器供应商锁定。大部分情况下,无论你使用了某一供应商的哪些无服务器功能,在另一个供应商的环境中这些功能都会使用不同的实现方式。如果想要更换供应商,除了需要更新自己的运维工具(部署、监控等)外,八成还要更改代码(例如为了匹配不同的FaaS接口),甚至如果相互竞争的供应商在行为的实现上有差别,可能需要更改自己的决策或体系结构。
就算可以为生态系统的部分内容更换供应商,在其他体系结构组件上依然可能存在锁定。例如,假设你正在使用AWS Lambda对来自AWS Kinesis消息总线的事件做出响应,AWS Lambda、Google Cloud Functions以及Microsoft Azure Functions之间的差异可能非常小,但依然无法将后两个供应商的实现直接挂接到AWS Kinesis流。这意味着无法将代码从一个解决方案移动或迁移至另一个解决方案,除非同时移动基础结构中的其他组件。
最终就算能找到某种方法通过其他供应商的服务重新实现整个系统,取决于新供应商所提供的服务,可能依然需要进行迁移。举例来说,如果从某个BaaS数据库切换至另一个,源数据库和想要换为使用的目标数据库提供的导出和导入功能可以满足你的需求吗?就算能满足,又需要付出多少成本和精力?
目前新出现了一种也许能缓解此类问题的方法:对多个无服务器供应商的服务进行普适的抽象,下文将详细介绍。
安全顾虑
这个问题本身就足以单独撰文介绍,拥抱全新的无服务器方法会让你面临大量安全问题,例如下文列举了两个例子,除此之外需要考虑很多。
- 你使用的每个无服务器供应商会增加你自己生态系统内所需安全实现的数量,并会增加面对恶意行为时的攻击面,有可能导致攻击成功率增加。
- 如果直接通过移动平台使用BaaS数据库,将丧失传统应用程序在服务器端提供的防护屏障。虽然这并不会直接造成严重后果,但依然需要在应用程序的设计和开发过程中给予更充分的考虑。
跨客户端平台重复实现相同的逻辑
在使用“完整BaaS”体系结构后,不需要在服务器端编写任何自定义逻辑,所有逻辑都位于客户端。对于第一个客户端平台来说这也许不算什么问题,可一旦需要支持更多平台,就必须重新实现相关逻辑的子集,在传统的体系结构中是不需要这样做的。举例来说,如果在此类系统中使用了BaaS数据库,所有客户端应用(也许有Web,以及原生iOS和原生Android应用)都需要与供应商提供的数据库通信,此时就需要了解如何从数据库架构映射至应用程序逻辑。
此外如果任何时候想迁移到新数据库,还需要跨越所有不同客户端重复编写代码并对各种改动进行协调。
丧失优化服务器的能力
对于“完整BaaS”体系结构,无法为了提升客户端性能而对服务器端的设计进行优化。“前端的后端(Backend For Frontend)”这种模式会对服务器上整个系统的部分底层内容进行某种程度的抽象,这种做法在一定程度上可让客户端执行速度更快,对于移动应用程序还有助于降低能耗。目前“全面的BaaS”已经可以使用这样的模式。
需要澄清的是,这里以及上文提到的劣势适用于所有自定义逻辑都位于客户端,仅后端服务需要由供应商提供的“完整BaaS”体系结构。为了缓解这些问题可以考虑采用FaaS或其他类型的轻量级服务器端模式,以将某些逻辑转移到服务器上。
无服务器FaaS不支持服务器内状态
在介绍过几个有关BaaS的劣势后,再来谈谈FaaS吧。上文我曾提到:
在本地…状态方面FaaS函数会遇到很多局限。你需要假设对于函数的任何调用,自己创建的任何进程内或主机状态均无法被任何后续调用所使用…
另外还提过,为了克服这些局限可考虑采用“十二要素应用”中的第六个要素:
十二要素进程是无状态并且无共享(Share-nothing)的。任何需要持久保存的数据必须存储在有状态的后端服务中,通常可选择使用数据库。
-- 十二要素应用
Heroku建议考虑这种方法,在使用PaaS时这些规则可以放宽,但使用FaaS时往往无法通融。
那么如果无法保存在内存中,FaaS的状态要存储在哪里?上文的引言中提到可以使用数据库,大部分情况下可以使用速度足够快的NoSQL数据库、进程外(Out-of-process)缓存(例如Redis),或外部文件存储(例如S3)等选项。但这些方式的速度比内存中或计算机内持久存储的速度慢很多,因此还需要妥善考虑自己的应用程序是否适合这些方式。
这方面另一个不容忽视的问题是内存中缓存。很多需要从外部读取大量数据集的应用会将数据集的部分内容缓存在内存里。你可以通过数据库中的“参考数据”表读取数据并使用诸如Ehcache等技术,或者从指定了缓存头的Http服务读取,此时内存中的Http客户端即可提供本地缓存。对于FaaS实现,可以将这些代码保存在应用中,但缓存很少能提供太多收益(可能完全无用)。只要缓存在首次使用时完成“热身”,随着FaaS实例被撤销这些缓存将毫无用处。
为了缓解这个问题可以不再假设存在进程中缓存,并使用诸如Redis或Memcached等低延迟的外部缓存,但这样做(a)需要执行额外的工作,并且(b)取决于具体用例可能会对性能产生极大影响。
实现方面的劣势
上文提到的劣势很可能会伴随无服务器技术一生。虽然可以通过各种缓解解决方案加以改进,但很可能无非根除。
然而其他劣势纯粹是由于现阶段该技术本身不够完善所致。随着供应商继续重视并不断投入,以及/或在社区的帮助下,这些问题有望彻底得到解决。只不过目前这些问题还比较突出…
配置
AWS Lambda函数没提供任何配置选项。一个都没。甚至环境变量都无法自行配置。如何针对环境的某些特定本质用不同特征运行同一个部署构件?不行。你必须自行调整部署构件,甚至可能需要使用不同的嵌入式配置文件。这种“吃相”实在很丑。无服务器框架可以帮你完成必要的改动,但这样的改动依然必不可少。
我有理由相信亚马逊正在解决这个问题(可能很快就会搞定),不知道其他供应商是否存在类似问题,但将这个问题放在开头恰好是为了证明这一技术目前确实还比较先进,有各种不足之处。
自己对自己发起的DoS攻击
为什么说任何时候使用FaaS都需要购者自慎(Caveat Emptor)?有另一个很有趣的例子。目前AWS Lambda会对用户可并发执行的Lambda数量进行限制,假设上限是1000,这意味着任何特定时间点下你最多只能同时执行1000个函数,如果需要执行更多将开始受到限制,被加入等待队列,并/或导致整体执行速度放缓。
这里的问题在于这个限制会应用给你的整个AWS帐户。一些组织会为生产和测试环境使用同一个AWS帐户,这意味着如果组织内部某人在执行一种全新类型的负载测试,尝试执行超过1000个并发Lambda函数,这几乎等同于不小心对自己的生产环境发起了DoS攻击。晕…
就算为生产和开发环境使用不同的AWS帐户,一个超载的Lambda(例如正在忙于处理客户批量上传操作)将可能导致其他由Lambda提供的实时生产API变得响应速度缓慢。
其他类型的AWS资源可以通过不同的安全和防火墙等手段,针对环境上下文情境和应用范围进行分隔,Lambda也需要类似的机制,我相信很快就会有的,但目前只能自己小心了。
执行时间
上文提到过AWS Lambda函数如果执行时间超过5分钟将被终止,预计这个限制很快将被取消,但我更感兴趣的是AWS解决这个问题的方法。
启动延迟
上文提到过我的另一个顾虑,FaaS函数等待多久才能获得响应,如果时不时需要在AWS上使用通过JVM实现的函数,这一点将尤为重要。如果你用到这样的Lambda函数,可能需要十多秒才能启动。
希望以后AWS能通过各种缓解措施改善启动速度,目前这一问题可能妨碍到某些用例中JVM Lambda的使用。
关于AWS Lambda的具体问题就是这些。我相信其他供应商私底下肯定也隐瞒了很多类似的问题。
测试
无服务器应用的单元测试其实相当简单,原因上文已经说过了:你所编写的任何代码“仅仅是代码”,而不是要使用的各种自定义库,也不是需要实施的各种接口。
然而无服务器应用的集成测试过程较为困难。在BaaS的世界中只能使用外部提供的系统,而不能使用(举例来说)自己的数据库,那么集成测试也要使用外部系统吗?如果要,这些外部系统与测试场景的匹配程度如何?能否轻松地组建/撤销所需状态?供应商能否针对负载测试提供单独的计费策略?
如果想将多个外部系统桩(Stub)在一起用于集成测试,供应商是否提供了本地的桩模拟器?如果有提供,桩的保真度如何?如果供应商没有提供桩又该如何自行实现?
FaaS领域也存在类似的问题。目前大部分供应商并未向用户提供可用的本地实现,因此你只能使用普通的生产实现。这意味着所有集成/接受度测试都必须远程部署并使用远程系统执行。更糟糕的是,上文提到的问题(无法配置,跨帐户执行的限制)也会对测试方式产生影响。
说这个问题很严重,部分原因在于我们在无服务器FaaS中使用的集成单位(例如每个函数)远远小于其他体系结构,因此相比其他类型的体系结构,此时将更依赖于集成测试。
Tim Wagner(AWS Lambda总经理)在最近的无服务器大会上简单提到了他们正在解决与测试有关的问题,但听起来测试工作对云的依赖会更高。这也许是一个适合勇敢者的全新世界,但我会怀念在自己笔记本上脱机对整个系统进行完整测试的日子。
部署/打包/版本控制
这是FaaS面临最具体的一个问题。目前我们还缺乏一种将一系列函数打包成应用程序的足够好的模式。造成这个问题的原因在于:
- 对于整个逻辑应用程序中的每个函数,可能都需要单独部署一个FaaS构件。如果(假设)你的应用程序使用JVM实现,其中包含20个FaaS函数,那就需要将JAR部署20次。
- 同时这也意味着无法以原子级的方式部署一组函数。你可能需要关闭可能触发该函数的任何事件源,部署整个组,然后重新打开事件源。对零停机应用程序来说这是个很麻烦的问题。
- 最后这还意味着应用程序缺乏版本控制机制,无法实现原子级回滚。
再次需要提醒,目前有一些意在解决这类问题的开源项目,然而只有在供应商的支持下此类问题才能顺利解决。为了解决部分此类问题,AWS最近在无服务器大会上公布了一个名为“Flourish”的新技术,但具体细节尚未公布。
发现
与上文提到的有关配置和打包的问题类似,跨越不同FaaS函数的发现能力目前也缺乏一种足够好的模式。虽然这个问题不是FaaS独有的,但FaaS函数细化的本质,以及应用程序/版本定义的缺乏会让这个问题变得更严重。
监控/调试
目前只能使用供应商提供的监控和调试工具,无法使用第三方工具。某些情况下这样也可以接受,但对AWS Lambda来说,自带的工具功能过于简陋,这方面我们更希望有开放的API和第三方服务。
API网关定义和“管太宽”的API网关
最近一次ThoughtWorks Technology Radar活动讨论了API网关“管太宽”的问题。虽然这个链接主要讨论了一般意义上的API网关,但正如上文所说,这些内容也适用于FaaS API网关。这里的问题在于API网关提供了在自己的配置/定义等领域内执行大量特定应用程序的能力,通常很难针对这些逻辑执行测试和版本控制等操作,甚至有时逻辑本身的定义也很难。如果能像应用程序中的其他部分一样将此类逻辑留在程序代码中,这样的方式往往效果更好。
对于亚马逊的API网关,就算最简单的应用程序,目前也只能使用该网关特定的概念和配置。也正是因此出现了诸如无服务器框架和Claudia.js等开源项目,这类项目可以帮助开发者忽略具体实现的相关概念,更顺利地使用常规代码。
虽然API网关很容易会变得异常复杂,但随着技术的进一步完善,我们有望能用上帮助自己完成这些工作,并能通过推荐的使用模式帮我们远离这些陷阱的工具。
行动推迟
上文曾经提到,无服务器并不是指“无须运维”,在监控、体系结构伸缩、安全、网络等方面依然要做很多工作。但依然有一些人(也许我也算其中之一,这是我的错)会将无服务器描述为“无须运维”,主要原因在于当你开始使用之后,很容易会忽略掉与运维有关的活动:“瞧啊,都不用装操作系统!”这种想法的危险之处在于很容易陷入一种虚假的安全感中。也许你的应用可以顺利运行,但在不知情的情况下被Hacker News报道之后,突然激增十倍的流量产生了近乎于DoS的攻击,然后就没有然后了……
与上文列举的有关API网关的其他问题一样,教育是解决这类问题的良药。使用无服务器系统的团队需要提前考虑运维活动,供应商和社区需要通过各种教学内容帮助他们了解这一技术的真正意义。
无服务器技术的未来
这篇无服务器体系结构的介绍文章已经逐渐到达尾声。作为收尾,我将谈谈未来几个月甚至几年里,无服务器技术可能的发展方向。
弥补劣势
上文已经多次提到,无服务器技术是新事物。尽管上文已经列举了该技术的一些劣势,但写出来的仅仅只是一部分。无服务器后续发展的重要方向之一是弥补固有劣势,消除,或至少改善实施方面的不足。
工具
在我看来,无服务器FaaS目前最大的问题在于工具的缺乏。部署/应用程序捆绑、配置、监控/日志,以及调试,这些工具都存在严重不足。
亚马逊已公布但尚未公开技术细节的Flourish项目也许能起到一定帮助。这则消息让人期待的另一个原因在于,该技术将会是开源的,这样就可以对不同供应商的应用程序进行移植。就算没有Flourish,我们同样期待未来一两年里开源世界中能出现类似的技术。
监控、日志、调试,所有这一切都将由供应商负责实现,但对BaaS和FaaS领域都是巨大的促进。相比使用ELK等技术的传统应用,至少目前AWS Lambda的日志功能还很不能让人满意。但我们已经注意到在现在这样的早期阶段,这一领域已经出现了几个第三方的商用和开源工具(例如IOPipe和lltrace-aws-sdk),但是距离类似New Relic这样的技术还有很长的路要走。希望AWS除了为FaaS提供更完善的日志解决方案外,也能像Heroku和其他厂商那样让我们更容易地融入第三方日志服务。
API网关工具还有很大改进空间,其中一些改进可能来自Flourish,或依然在继续完善的无服务器框架等类似技术。
状态管理
FaaS缺乏服务器内状态,这一点对很多应用程序来说不是什么大问题,但也会对一些应用程序产生严重影响。例如很多微服务应用程序为了改善延迟会用到一定规模的进程中状态缓存。类似的连接池(连接到数据库,或通过持久的Http连接连接到其他服务)则又是另一种形式的状态了。
对于大吞吐率的应用程序,一种解决方法是让供应商延长函数实例的寿命,借此使用常规的进程中缓存方法改善延迟。但这种方法并非总是有效,因为不能为每个请求提供“温”缓存,而且用传统方式部署,并使用了自动伸缩能力的应用也面临类似的困扰。
另一种更好的解决方案是以延迟极低的连接访问进程外(Out-of-process)数据,例如用极低延迟的网络开销查询Redis数据库。考虑到亚马逊已经在自家的Elasticache产品中提供了托管式的Redis解决方案,并且他们已经使用置放群组(Placement Group)实现EC2(服务器)实例的相对共置(Relative co-location),这样的做法似乎无法获得足够的延展性。
我觉得更可行的情况是,我们将看到不同类型的应用程序体系结构会开始考虑非进程中状态的约束问题。对于低延迟应用程序实例,也许可以用普通服务器处理初始请求,通过本地和外部状态收集处理该请求所需的全部上下文,随后将包含完整上下文情境的请求交给自身无须查询外部数据的FaaS函数场来处理。
平台的改进
目前,无服务器FaaS的某些劣势主要源自平台本身的实现方式。执行时间、启动延迟、无法分隔的执行限制,这是目前最主要的三大劣势。也许可以通过新的解决方案解决这些问题,或可能需要付出额外的成本。例如我觉得启动延迟这个问题可以通过允许客户为FaaS函数请求2个始终可用,并且延迟足够低的实例的方式加以缓解,只不过客户需要为这样的可用性额外支付一笔费用。
当然,平台自身的继续完善不光是为了解决现有的这些问题,无疑还会提供更多让人激动的新功能。
教育
通过加强教育,也可以缓解不同供应商所提供的无服务器技术固有的一些劣势。每个使用此类平台的人都需要积极考虑将自己的生态系统托管在一个或多个应用程序供应商的平台上,这样的做法到底意味着什么。例如有必要考虑类似这样的问题:“是否有必要考虑使用来自不同供应商的平行解决方案,以防一个供应商的服务故障对我产生较大影响?如果部分服务故障,应用程序又该如何优雅地降级?”
技术运维方面也需要进行教育。目前有很多团队的“系统管理员”数量大幅减少,而无服务器技术还会让这种情况更严峻。但系统管理员的职责不仅仅是配置Unix服务器和Chef脚本,这些人通常也活跃在技术支持、网络、安全等一线领域。
在无服务器世界中,真正的DevOps文化变得愈加重要,因为依然有大量与系统管理无关的活动需要完成,并且通常将由开发者负责。但对大部分开发者和技术领导者来说,这些工作并非他们的本职任务,因此适当的教育以及与运维人员更为密切的合作将变得至关重要。
提高透明度/为供应商确定更清晰的预期
最后终于谈到了缓解措施方面,随着对供应商的托管能力愈加依赖,我们对不同供应商的平台会产生怎样的预期,供应商对此必须更加明确。虽然平台迁移工作很难,但至少是可行的,客户会逐渐带着自己的业务逃离不可靠的供应商。
新兴模式
除了半生不熟的底层平台,对于如何以及何时使用无服务器体系结构这样地问题,我们的理解依然还很浅显。目前很多团队会出于投石问路的考虑将各种想法付诸于无服务器平台,希望这些先驱们好运!
但是用不了多久我们就会开始看到各种推荐的实践模式日益涌现。
某些实践可能专注于应用程序的体系结构。例如FaaS函数在开始显得笨重之前能达到多大规模?假设能以原子级的方式部署一组FaaS函数,创建这种分组的最佳方式是什么?这种方式能否与目前我们将逻辑与微服务结合在一起所用的方法严格匹配?体系结构的差异是否要求我们转向截然不同的方向?
将这些问题进一步扩展,在FaaS和传统的“始终在线”持久运行的服务器组件之间创建混合体系结构的最佳方法是什么?将BaaS引入现有生态系统的最佳做法是什么?反过来看,哪些征兆意味着全面或大部分以BaaS为主的系统需要开始接受或使用更多自定义服务器端代码?
我们还会看到大量新兴的使用模式。媒体转换是FaaS的标准用例之一:“当有比较大的媒体文件存储到S3 Bucket后,自动运行进程在另一个Bucket中为该文件创建小体积的版本。”但为了确定某一具体用例是否适合无服务器方法,我们还需要进一步分析更多使用模式。
除了应用程序体系结构,一旦相关工具进一步完善后,我们还将看到各种推荐的运维模式。如何从逻辑上将FaaS、BaaS,以及传统服务器组成的混合体系结构中的日志汇总到一起?关于服务的发现有什么好办法?对于以API网关作为前端的FaaS Web应用程序该如何进行金丝雀发布?如何对FaaS函数进行最高效的调试?
超越“FaaS化”
目前我见到的大部分FaaS运用场景主要是将现有代码/设计想法用“FaaS”的方式实现出来,也就是将其转换为一系列无状态的函数。这种做法挺强大,但我也期待着能实现进一步的抽象甚至形成一种语言,使用FaaS作为底层实现为开发者提供FaaS收益,而无须实际将自己的应用程序看作一系列相互独立的函数。
例如我不知道谷歌是否在自己的Dataflow产品中使用了FaaS实现,但我完全可以设想有人创造了能实现类似作用的产品活开源项目,并使用FaaS作为实现。这里可以用Apache Spark作为类比。Spark是一种大规模数据处理工具,提供了非常高程度的抽象,可支持使用Amazon EMR/Hadoop作为自己的底层平台。
测试
正如上文“劣势”中所述,对无服务器系统来说,在集成和接受度测试方面还有很长的路要走。我们会看到不同供应商分别提出自己的建议,其中一些可能会用到云服务,同时我猜测可能还会有像我这样的“保守派”供应商会提出另一种方案,借助何种方案可以在自己的开发计算机上完成一切测试任务。估计最终我们将看到各种得体的解决方案,分别可用于联机和脱机测试,不过可能还要等几年。
“可移植”的实现
目前所有流行的无服务器实现都以部署到第三方供应商在云中的系统内为前提。这是无服务器的优势之一,可以减少需要我们维护的技术数量。但这就产生了一个问题,如果有公司希望在自己的系统中运行这些技术,并将其以一种内部服务的方式交付该怎么办?
类似的,目前的所有实现在集成点(Integration point)方面都有自己的偏好:部署、配置、函数接口等。这就会造成上文提到过的供应商锁定的局面。
为了缓解这些顾虑,期待能看到各种可移植的实现,下文将首先谈谈上面的第二点。
针对供应商的实现进行的抽象
我们已经开始看到类似无服务器框架和Lambada框架这样的开源项目。这些项目的想法在于让我们忽略实际部署位置和方法,以一种中立的开发方式编写和运维无服务器应用。就算目前仅仅在AWS API网关 + Lambda,以及Auth0 Webtask之间,如果能根据每个平台的运维能力轻松进行切换,那也是极好的。
我觉得只有在出现大量此类标准化产品之后才能实现这种程度的抽象,但好在这种想法可以通过循序渐进的方式逐步实现。我们可以从一些跨供应商的部署工具着手,甚至可以考虑上文提的AWS Flourish,并以此为基础逐渐构建出更多功能。
这方面有个比较棘手的问题:在尚未实现标准化的情况下对FaaS编码接口的抽象进行建模,预计这样的进展会首先出现在非专有的FaaS技术中。例如我认为在AWS S3或Kinesis Lambdas实现抽象之前,可能首先会完成对Lambda的Web请求和调度(“Corn”)的实现。
可部署的实现
使用无服务器技术,但不使用第三方供应商的服务,这样的做法听起来有些奇怪,但可以考虑这些情况:
- 也许有一家大型技术组织,希望开始为所有移动应用程序开发团队提供类似Firebase的数据库体验,但想使用现有的数据库体系结构作为后端。
- 希望为某些项目使用FaaS风格的体系结构,但出于合规性/法律等问题的考虑,需要在“本地”运行自己的应用程序。
上述任何一个用例都可以在不使用外部供应商托管服务的情况下通过无服务器的方式获得收益。这样的做法是有先例的,例如平台即服务(PaaS)。最初流行的PaaS都是基于云平台的(例如Heroku),但人们很快发现在自己系统中运行PaaS环境也能带来大量收益,这就是所谓的“私有PaaS”(例如Cloud Foundry)。
可以想象,与私有PaaS实现类似,开源和商用的BaaS和FaaS等概念的实现将愈加流行。Galactic Fog是在这一领域应用尚处在早期阶段的开源项目的典范,他们就使用了自己的FaaS实现。与上文提到的供应商抽象的观点类似,我们可能会看到一些循序渐进的方法。例如Kong项目是一种开源的API网关实现,虽然在撰写本文时尚未与AWS Lambda集成(但据说这个问题正在着手处理中),但实现后就可以为我们提供很多有趣的混合方法。
社区
真心希望无服务器社区能够发展壮大。目前全球范围内围绕该技术已经有一个大会以及大量聚会活动。希望这一领域也能像Docker和Spring那样在全球发展出更多更大规模的社区。更多大会,更庞大的社区,以及各种在线论坛,借此帮助大家跟上技术的发展。
结论
虽然名称容易让人产生歧义,但“无服务器”这种风格的体系结构可以帮助我们减少在自己服务器端系统上运行的应用程序代码数量。这是通过两种技术实现的:后端即服务(BaaS),借此可将第三方远程应用程序与我们的前端应用直接进行紧密的集成;以及函数即服务(FaaS),借此可将不间断运行的组件中执行的服务器端代码转移到短暂运行的函数实例中执行。
无服务器技术并不是所有问题的最终答案,如果有人跟你说这种技术将彻底取代现有体系结构,你需要小心对待。如果想现在就涉足无服务器,尤其是FaaS领域,也需要更加谨慎。虽然这种技术已经产生了累累硕果(伸缩、节约开发工作量等),但依然有(调试、监控等领域的)困难在下个角落等着你。
这些收益并不会被人们快速淡忘,毕竟无服务器体系结构的积极意义实在是太大了,例如降低运维和开发成本,简化运维管理,降低对环境的影响等。对我来说,影响力最大的收益依然是减少打造全新应用程序组件时的反馈环路(Feedback loop),我是“精益(Lean)”方法的铁粉,主要是因为我觉得尽可能先于最终用户从技术中获得反馈,这种做法可以为我带来大量价值,当无服务器技术能够与这样的理念相符后也可以缩短我将应用投放时长所需的时间。
无服务器系统依然处在襁褓中。未来几年里该技术还有很大的进步空间,我已经迫不及待想看看这个技术将如何融入现有的体系结构大家族中。
致谢
感谢下列人员对本文提出的宝贵意见:Obie Fernandez、Martin Fowler、Paul Hammant、Badri Janakiraman、Kief Morris、Nat Pryce、Ben Rady、Carlos Nunez、John Chapin、Robert Bagge、Karel Sague Alfonso、Premanand Chandrasekaran、Augusto Marietti、Roberto Sarrionandia。
感谢Badri Janakiraman和Ant Stanley针对这一术语的起源提供的意见。
感谢我之前就职于Intent Media时所在团队成员提供的帮助,他们适当的怀疑精神让我对这一新技术产生了更深入的理解,谢谢你们:John Chapin、Pete Gieser、Sebastián Rojas,以及Philippe René。
最后还要感谢所有对这一话题发表过感想的人,尤其是本文链接所引用内容的作者。
关于本文作者

Mike Roberts
Mike是一位工程主管,目前居住在纽约市。虽然目前大部分时间都在管理人员和团队,但他也负责管理代码,尤其是Clojure,他对软件体系结构有着深入的见解。他对无服务器体系结构抱有审慎乐观的态度,认为这种技术也许担的上目前所获得的一些炒作。
本文作者:Mike Roberts,阅读英文原文:Serverless Architectures
