@liuhui0803
2017-04-01T07:39:22.000000Z
字数 6340
阅读 3818
使用Emoji(而非数学知识)进行深度学习
机器学习 深度学习 Emoji TensorFlow 购物
摘要:
主营“代购服务”的Instacart通过深度学习技术,结合店铺位置和商品陈列等信息对取货顺序进行优化,提高购物效率。
正文:
本文最初发布于原作者Jeremy Stanley的博客,经原作者授权由InfoQ中文站翻译并分享。
借助Keras和Tensorflow,使用深度学习技术对购物清单进行排序。
日常采买很麻烦。
商店很大,商品陈列很复杂,很容易逛到迷失其中。你想买的鹰嘴豆泥可能摆在乳品区、熟食区,甚至其他你根本想不到的地方。如何在商店里快速准确地找到自己想买的东西,这是个很艰巨的任务。
Instacart的目标是帮助客户从数百个零售商合作伙伴处订购上百万种产品。我们“购物顾问”团队中成千上万的成员必须能准确地在数千个店铺快速找到客户想要购买的商品。因此必须想方设法让这一过程尽可能快速。

深度学习技术“加持”的购物体验
深度学习入门
通过仔细评估购物顾问为通过应用下单的数百万顾客挑选商品的过程,我们构建了一个模型,这个模型可以预测顾问通过怎样的顺序来取货可以实现最高效率。随后当顾问接到新订单后,我们会使用预测结果为他们提供最优化的取货顺序。
这个方法可以让顾问的每次取货过程节约一分钟。考虑到业务的庞大规模,每次取货节约一分钟,等于每年可以节约618年的购物时间。

那么到底该怎么做?首先,我们没有自己的仓库,不能精确了解每个店铺的仓储情况或陈列布局。此外,由于这个问题在顺序方面的本质特征,传统的机器学习方法(我们❤️ XGBoost)也提供不了什么帮助。

于是我们应用了一些深度学习技术。
进行过的测试
我们进行了一次测试,将每批商品(一位顾客选择要购买的一系列商品)随机分配给四种清单排序算法之一:
- Control(红色):按照部门随机排序,同部门内商品按字母顺序排序;
- Human(绿色):使用店铺陈列布局按照店铺走道排序,同走道内商品按字母顺序排序;
- TSP(青色):使用跨部门商品挑选平均时间构建的“巡回推销员”解决方案,同部门内商品按字母顺序排序;
- Deep(紫色):最终的深度学习架构,直接对每批中的不同商品进行排序。
随后我们研究了每种排序方式在购物速度(Y轴)和每批所含商品数量(X轴)之间的关系:
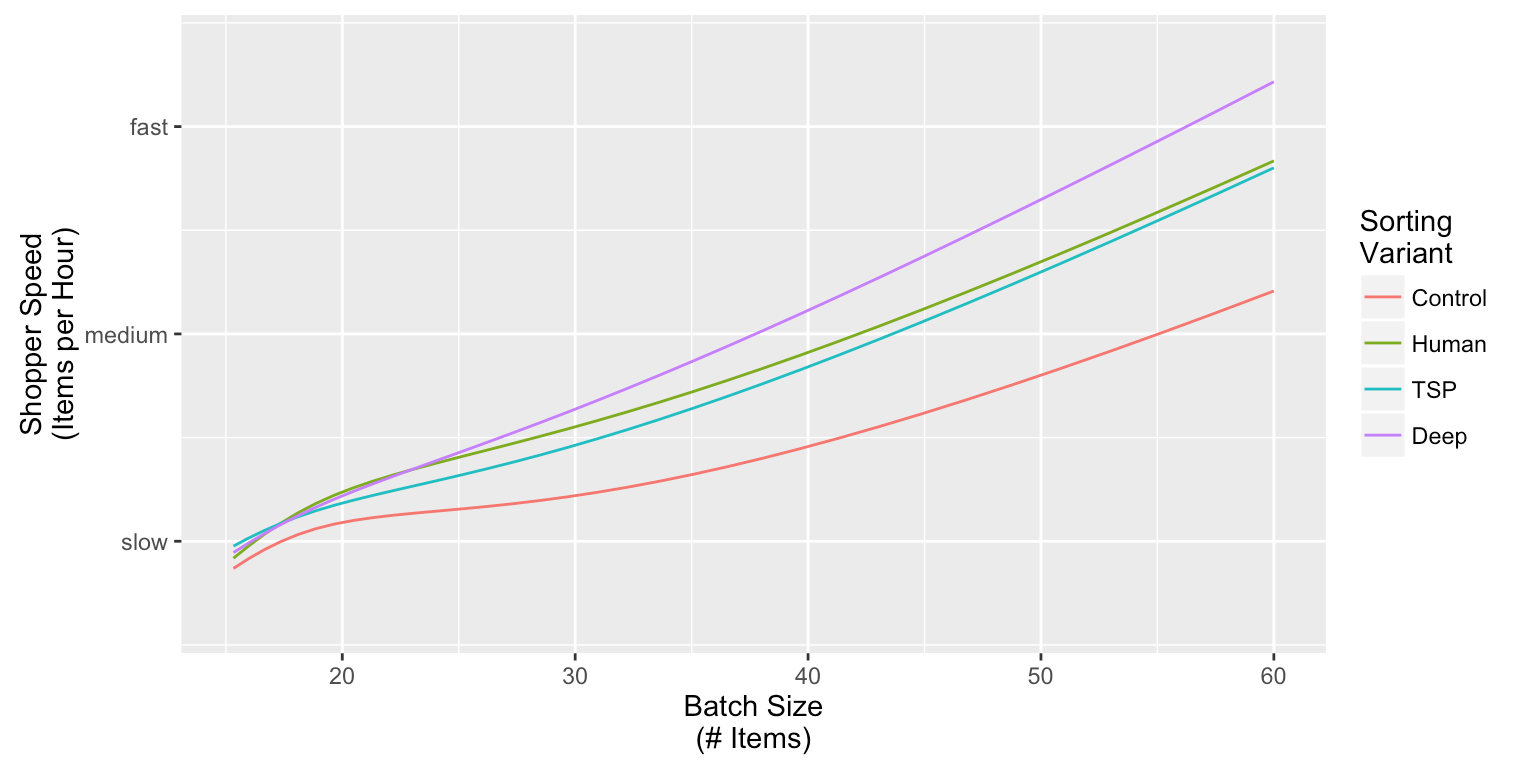
请注意,我们隐藏了实际的商品挑选速度,因为对Instacart的竞争力来说这是个非常敏感的KPI。
Control排序方式表现最差(意料之中)。TSP和Human的表现好很多,但从统计结果来看两者没有太大差异。
深度学习模型远远胜出其他排序方式,对于包含商品较多的订单,在挑选速度方面,从Human到深度学习方式的提升幅度比从Control到Human方式的提升幅度超过了50%。
下文将介绍我们所面临的问题(当然会使用emoji表情来介绍),以及最初使用的并不成熟的架构。下文将详细分析该架构并列举一些重要的缺陷,随后介绍更高效,效果也更好的最终架构。
通过Keras进行清单排序
问题定义
假设某位顾客订购了10件商品,购物顾问按照下列顺序拿取这些商品:

随着购物顾问对所拿取商品进行称重或扫码,我们可以看到下面这样的顺序。为了更好地了解整个顺序,需要将其转换成一种监管式的学习问题。假设稍后再重新审视这个订单,并在顾问拿取了🍞之后暂停:

我们想要预测顾问接下来会拿取的商品(本例中是🍪),考虑到顾问刚刚拿到🍞,因此预测工作可以在剩余的五个待购商品(🍪🍫🍕🍖☕)中进行。你饿了吗?
通过emoji数学(就职于Instacart的好处之一就是可以用emoji解决数学问题),我们可以将其重新写作:

请注意,这可能是一个很重要的计算问题。单单考虑拿取面包之后再拿取饼干这种做法的频率是不够的。饼干也许太过于普通了(几乎每家都有),因此这个看似简单的概率可能会变得相当高。考虑到接下来需要拿取的商品是固定不变的,我们希望衡量接下来选择拿取饼干的概率会有多高。
初始架构
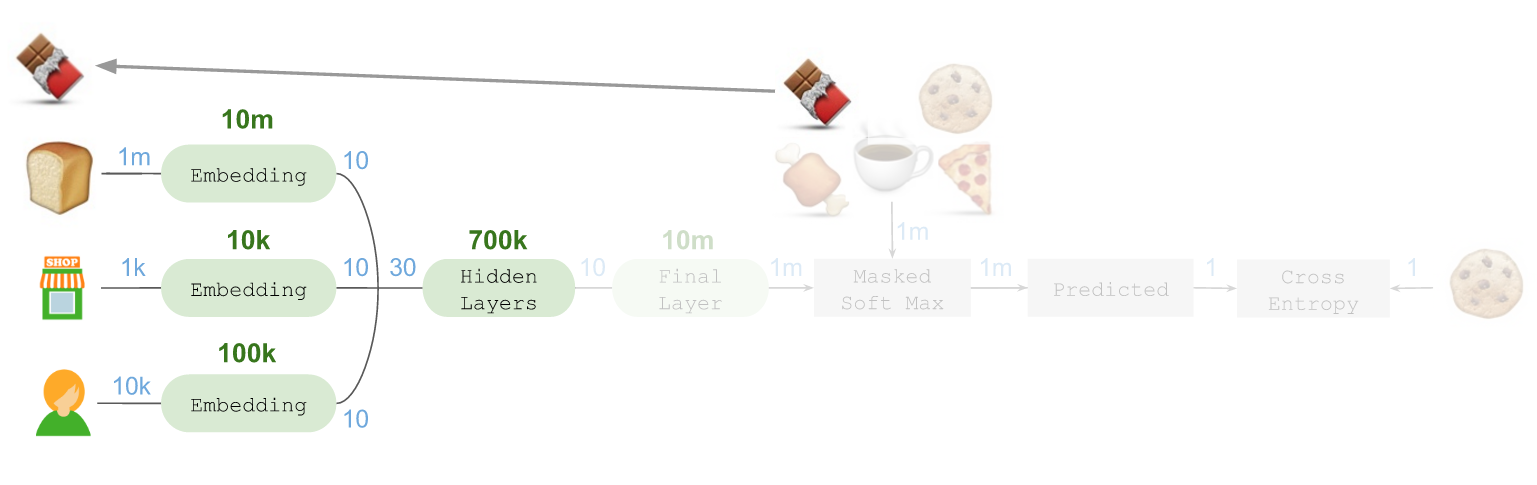
我们最初的深度学习架构使用Keras通过Tensorflow实现,如下图所示:
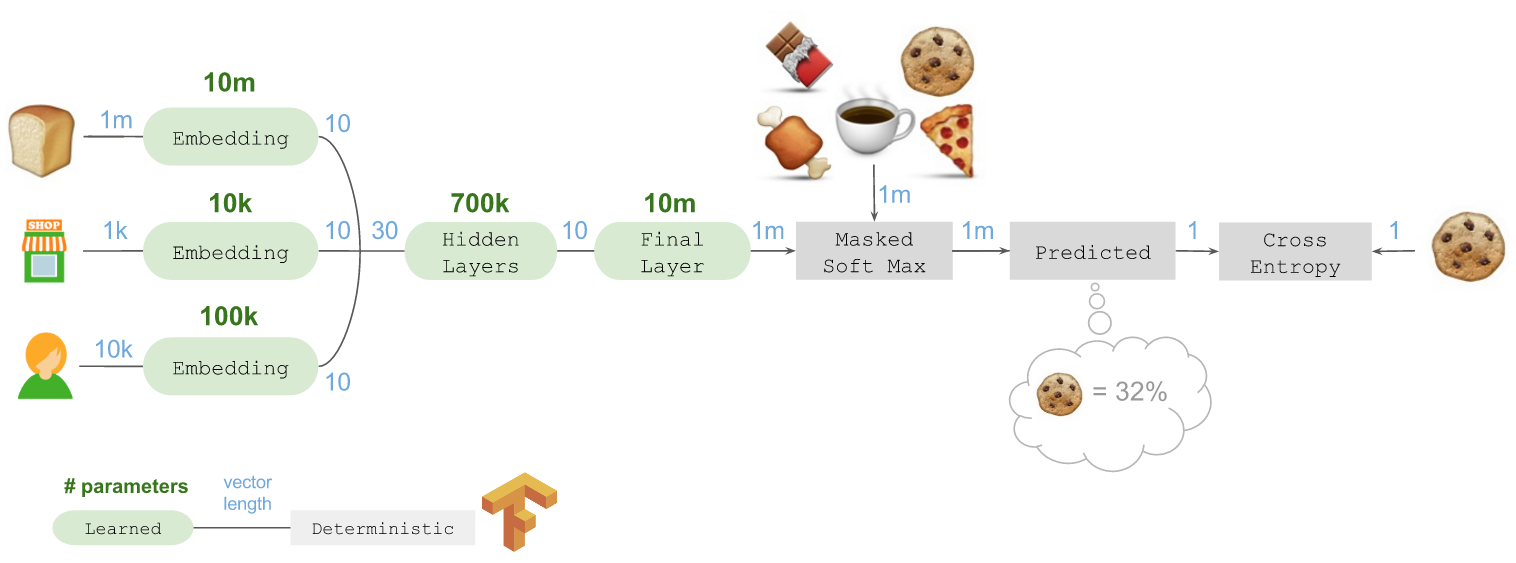
从左边开始,需要拿取的商品是🍞,最后到右边,预测到接下来要拿取的商品是🍪。这一过程中需要预测接下来要拿取的不同商品。
首先要谈谈“嵌入”:
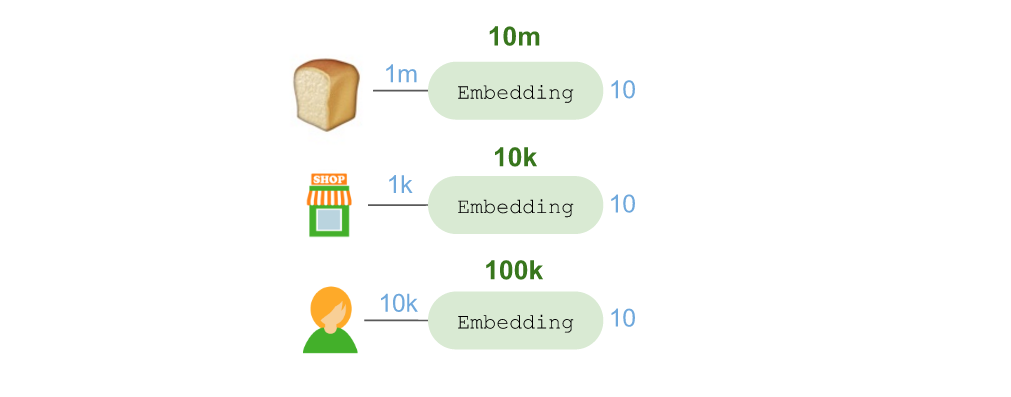
通过使用Keras的Embedding层,我们将🍞嵌入到一个10维向量空间。这其中共使用了1千万个参数,因为需要考虑1百万种可能需要购买的商品。同理,我们还嵌入了店铺位置(1千个店铺 = 1万个参数)和购物顾问(1万个顾问 = 10 万个参数)。
嵌入的店铺位置使得这个模型可以学习店铺布局,对零售商和位置进行归纳总结与学习。嵌入的购物顾问可以学习顾问在店铺内所选择的五花八门的路线。
随后将嵌入的所有内容连接在一起组成了一个30维向量,将其传入非线性激活(relu),全面互联的Dense隐藏层(70万个参数)序列。借此生成一个长度为10的最终向量,进而获取有关前序商品、店铺位置,以及购物顾问的所有相关信息,并确定接下来最后可能要拿取的商品。
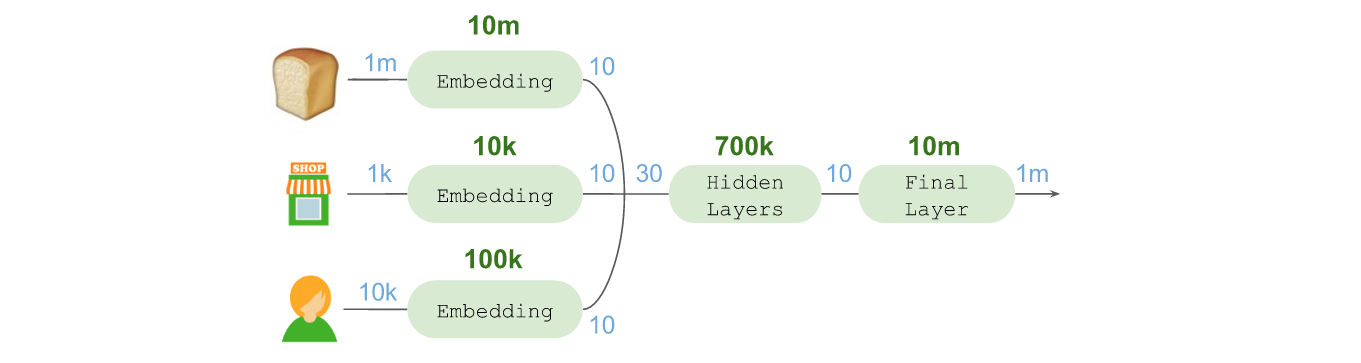
为了进行预测,我们还需要在最终层进行“扇出(Fan out)”,这类似于一种反向嵌入。借此可将我们的10维向量投射到后续可能拿取的商品所在的空间中。这是通过使用linear激活函数的Dense层实现的。
随后可以计算遮罩(Mask)后的Soft max,借此将所有非候选商品长度上百万的候选商品向量降低至“零”,并估算出5个候选商品的正向概率。这是通过将负责指数化的Lambda层,与对候选商品进行遮罩的Merge层结合在一起,并连接至另一个确保概率总和等于100%的Lambda层实现的。
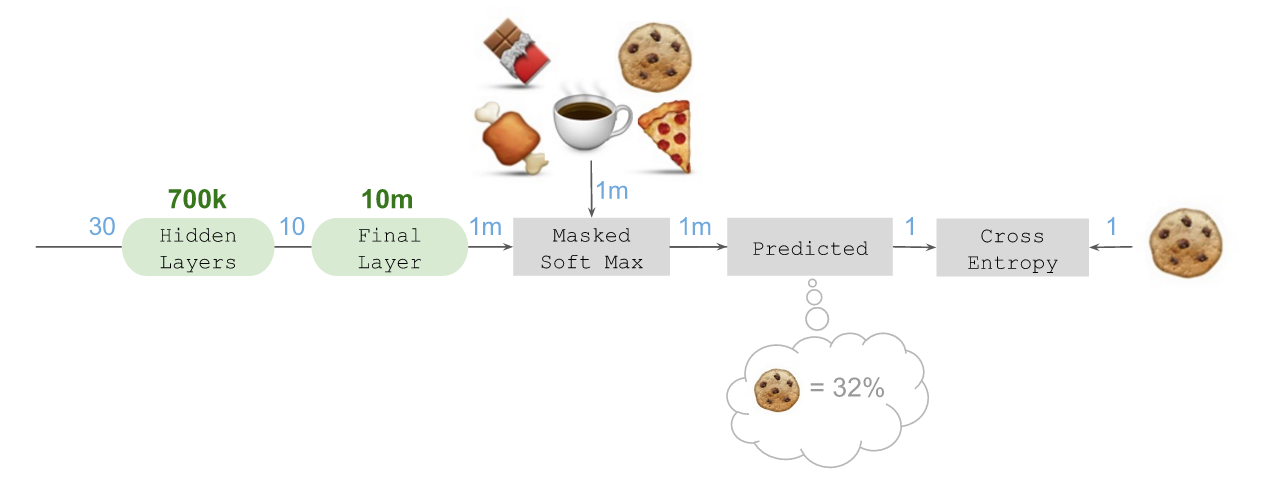
假设本例中预测到接下来拿取🍪(正确答案)的概率为32%,该预测会送入一个categorical_crossentropy损失函数(Loss function),同时送入的还有代表本例中接下来会选择🍪作为待拿取的下一个商品的指标。随后Tensorflow会对错误信息运用反向传播(Backpropogate)算法,借此对隐藏的最终嵌入层进行训练,我们便可以在大规模环境中学习。
Keras代码
该架构可通过下列代码用Keras实现:
from keras.models import Modelfrom keras.layers.core import Dense, Reshape, Lambdafrom keras.layers import Input, Embedding, mergefrom keras import backend as K# Number of product IDs availableN_products = 1000000N_stores = 1000N_shoppers = 10000# Integer IDs representing 1-hot encodingsprior_in = Input(shape=(1,))store_in = Input(shape=(1,))shopper_in = Input(shape=(1,))# Dense N-hot encoding for candidate productscandidates_in = Input(shape=(N_products,))# Embeddingsprior = Embedding(N_products, 10)(prior_in)store = Embedding(N_stores, 10)(store_in)shopper = Embedding(N_shoppers, 10)(shopper_in)# Reshape and merge all embeddings togetherreshape = Reshape(target_shape=(10,))combined = merge([reshape(prior), reshape(store), reshape(shopper)],mode='concat')# Hidden layershidden_1 = Dense(1024, activation='relu')(combined)hidden_2 = Dense(512, activation='relu')(hidden_1)hidden_3 = Dense(256, activation='relu')(hidden_2)hidden_4 = Dense(10, activation='linear')(hidden_3)# Final 'fan-out' into the space of future productsfinal = Dense(N_products, activation='linear')(hidden_4)# Ensure we do not overflow when we exponentiatefinal = Lambda(lambda x: x - K.max(x))(final)# Masked soft-max using Lambda and merge-multiplicationexponentiate = Lambda(lambda x: K.exp(x))(final)masked = merge([exponentiate, candidates_in], mode='mul')predicted = Lambda(lambda x: x / K.sum(x))(masked)# Compile with categorical crossentropy and adammdl = Model(input=[prior_in, store_in, shopper_in, candidates_in],output=predicted)mdl.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
initial_architecture.py代码托管于❤ GitHub
训练模型的过程中,最后一个诀窍在于使用fit_generator将长度上百万的candidate输入内容计算范围限制为小规模的批运算。
检测和局限
这个网络最有趣的地方在于左侧所嵌入的商品。我们可以使用t-SNE进行维度缩减,将嵌入的内容投射至一个2维空间:
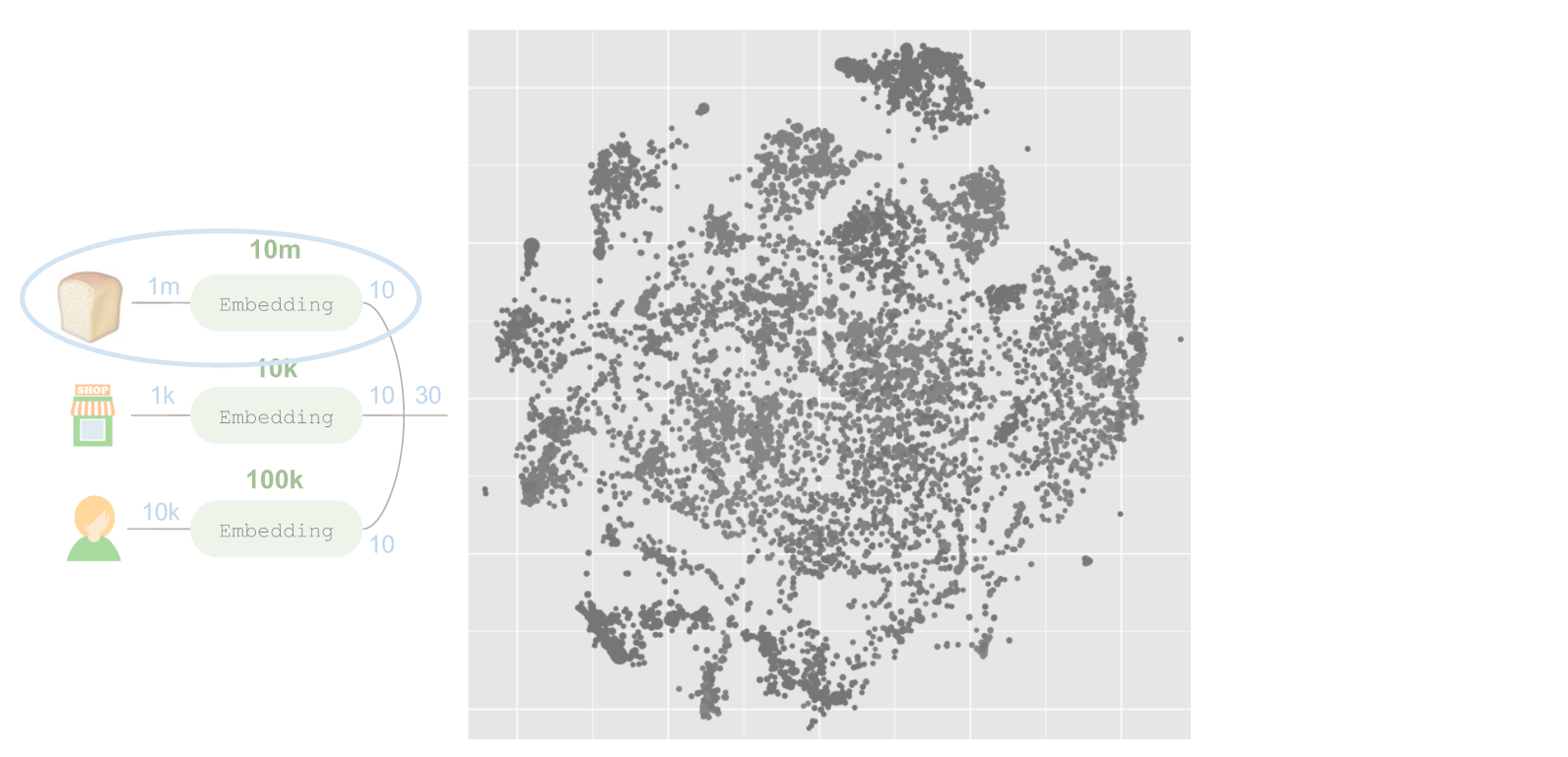
上述每个圆圈代表一个商品,圆圈的大小与对应商品被拿取的频率成比例。很明显,这个模型学习了一种极为有趣的结构。我们可以通过对每个部门的代码应用不同颜色的方式呈现其中的大部分结构:
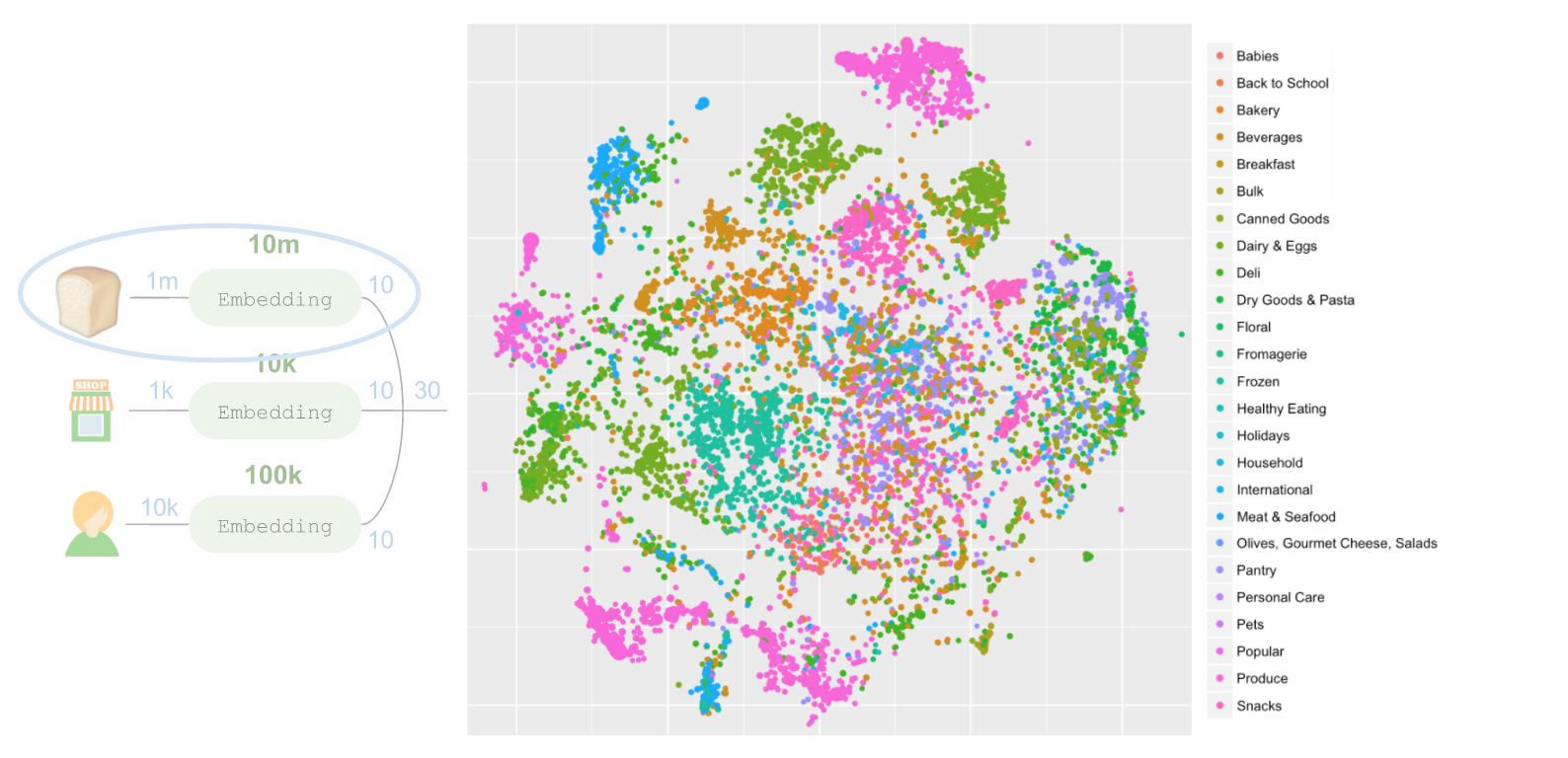
这些簇中大部分内容对应了不同部门,但完全没有将每个部门的数据用于学习嵌入。此外我们可以放大至其中一个区域,例如左上角用蓝色代表的肉类和海产品部门。肉类和海产品部门周围还有其他商品,但并不是肉类或海产品。这些产品(例如辣椒、香料和熟食等)也是在肉类和海产品柜台上销售的。在店内商品陈列规律的学习方面,这个模型的效果比之前用过的部门排序和走道排序算法更出色。
虽然这样的架构已经可以投入使用,但依然存在三个不足:
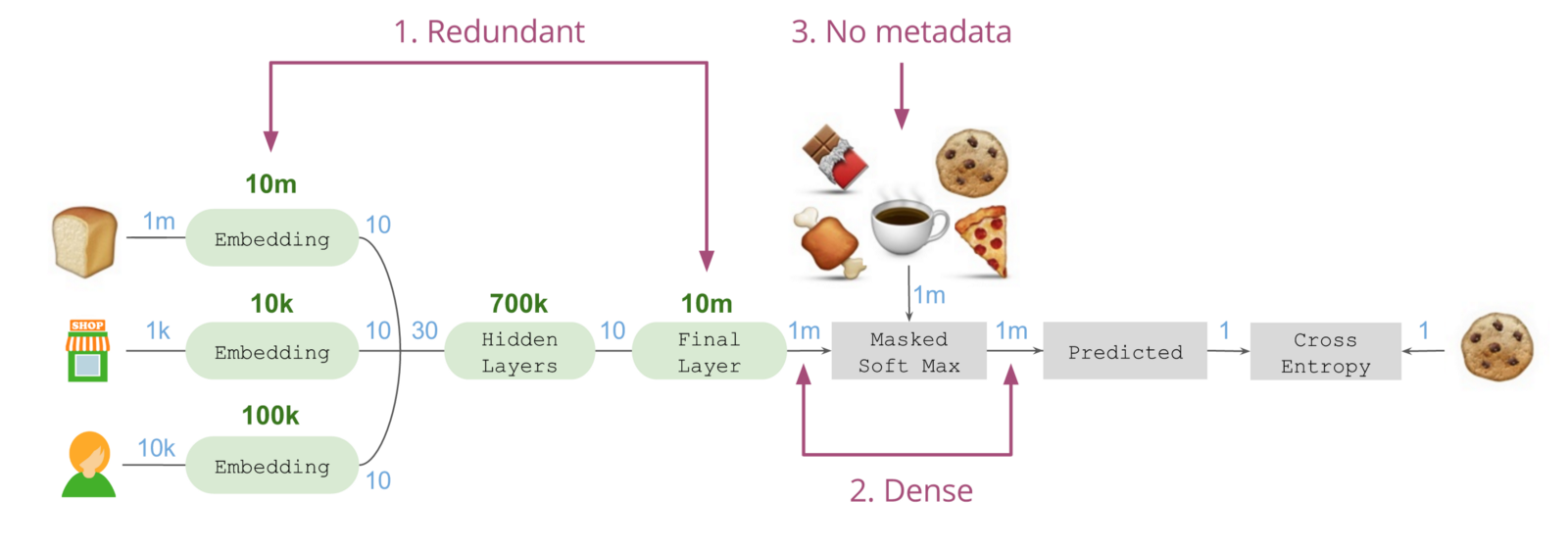
首先,我们在左侧将商品嵌入到10个维度,随后所实现的效果类似于在最终层中对这个嵌入进行逆转,借此投射至“下一个商品”空间,因此商品的嵌入和最终层会试着学习相似的关系。
其次,中间环节需要处理十分长,十分密集的1百万长度向量,但本例中上百万个值中,只有5个值是与最终结果相关的。这意味着需要无谓地耗费大量内存和计算资源。
最后,无法将有关候选商品的其他元数据注入该架构。如果希望从产品所关联的走道和部门信息中学习,可将其放入网络中最新产品(面包)的左侧。但如果饼干也在同一个走道上,将无法在该架构中体现这个信息。候选商品实际上是一种应用给上百万长度计分向量的二进制遮罩(Binary mask)。
最终架构
我们最终使用的架构解决了这些问题,同时还在性能与效率方面有了很大改进。
我们会创建一个“scoring generator”,并在Keras的TimeDistributed层为每个候选商品重复运用。为了演示这一做法,可以用🍫作为例子,将其放在架构的左侧:
随后可以使用functional API中的Keras共享层,使得针对🍞的产品嵌入也能将🍫投射至相同的10维度空间:
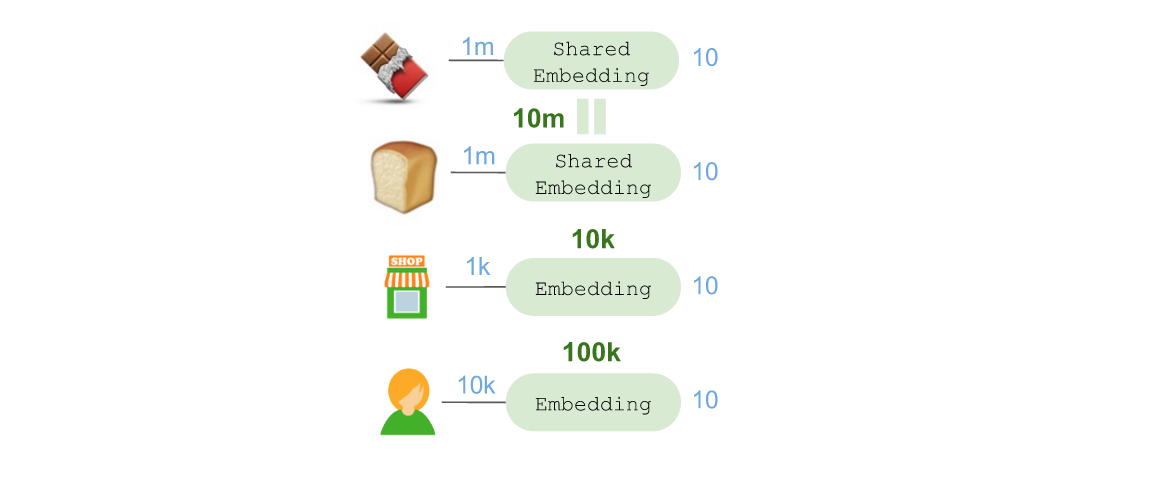
这里需要注意:这样做时参数的数量并未增加,因为实际上这等于是将这些参数针对不同用途反复使用(并能结合在一起进行优化)。随后我们可以使用一个Merge层将所有这些嵌入汇总在一起,组成一个40维向量,并将其放入隐藏层,进而获得评分:
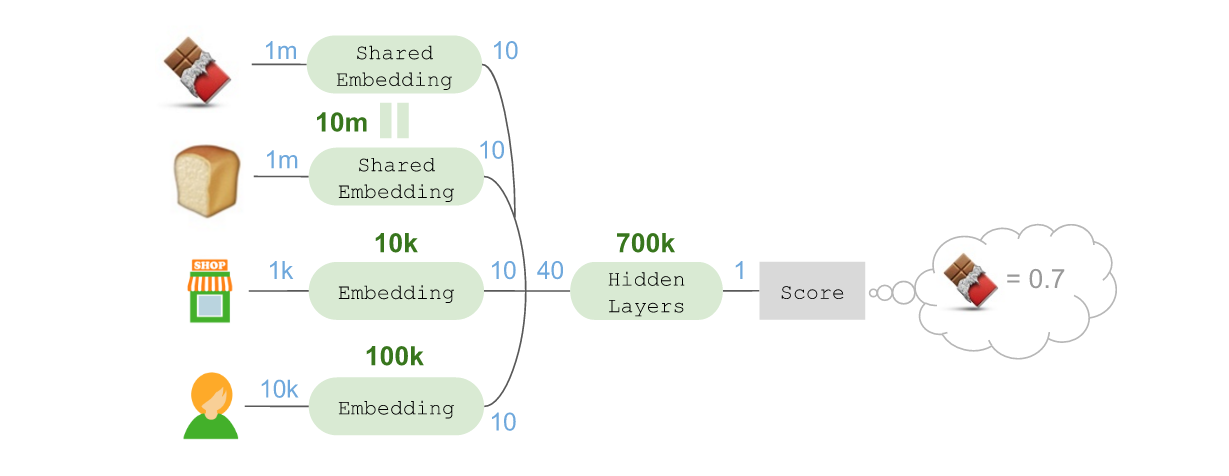
本例中,🍫的分数为0.7,我们会对架构的其他部分进行调整,使得这个分数可以用作代表在拿取过🍞之后,接下来拿取🍫的概率到底有多大的实值指标(Real-valued indicator)。值为正数的商品最有可能接下来拿取,值为负数的商品接下来被拿取的概率非常小。
随后将组件中这一架构的复杂性全部用“score generator”模块掩盖起来:
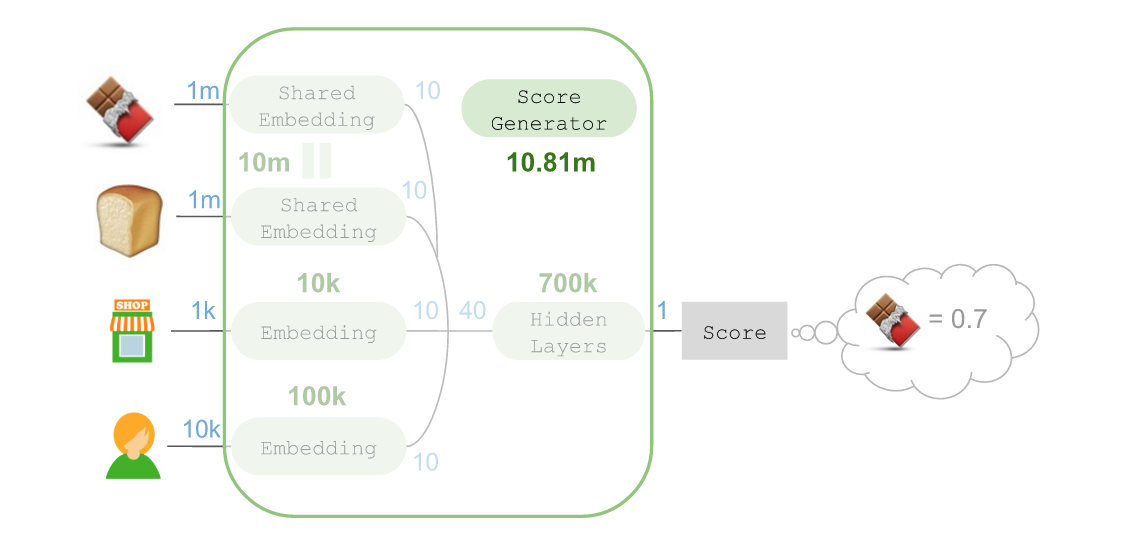
虽然参数总数高达1081万,但也可将其简化为:
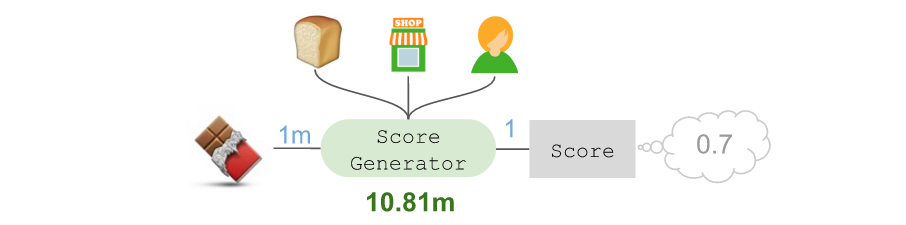
这个计分器需要依赖候选商品(🍫)、前序商品(🍞),店铺,以及购物顾问。我们可以通过这样的过程对其余候选商品进行打分:
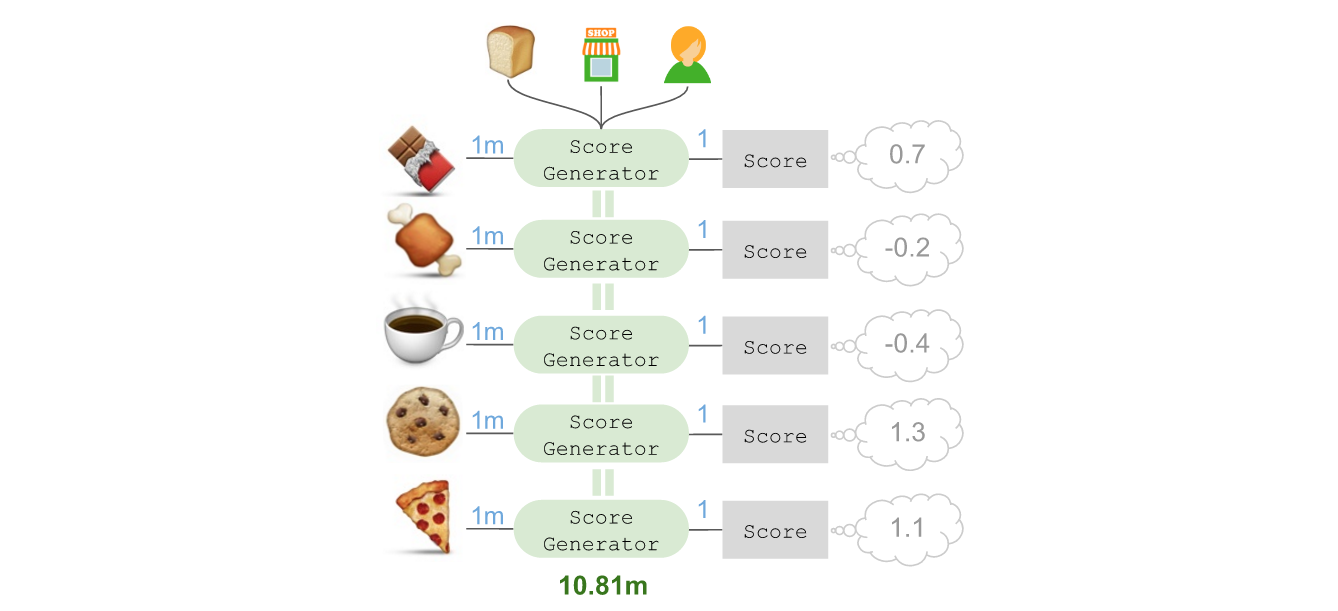
假设发现随后几乎不可能拿取🍖(-0.2),随后最不可能拿取☕(-0.4),而随后最有可能拿取🍪(1.3),接下来第二有可能拿取的是🍕(1.1)。
所有这些分数都可放入一个简单的Soft-max层,借此预测出接下来拿取🍪的概率为36%:
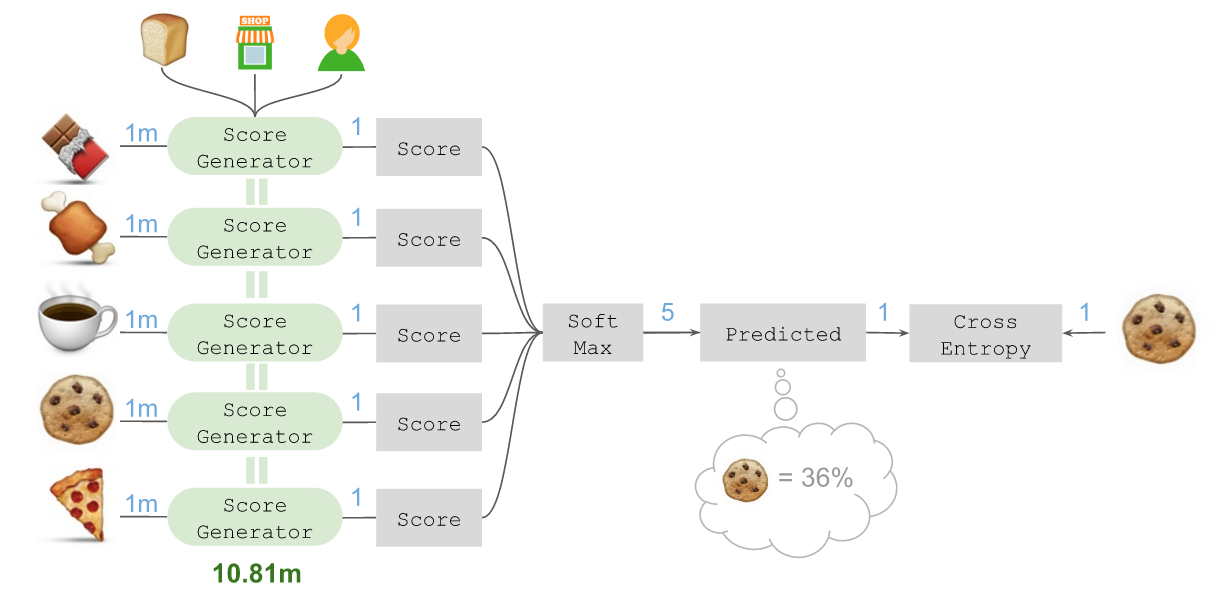
接下来,将这个预测放入交叉熵(Cross-entropy)损失函数,并判断实际上接下来需要拿取的正是🍪。
这个架构的关键在于,借助Keras中的TimeDistributed层,可以针对所有候选商品共享同一个计分器。因此我们依然使用了1081万个参数,而TensorFlow也可以计算相对于单一顺序位置,所有候选商品的计分器整体交叉熵损失的坡度更新。
至此,读者也可以通过我们提供的这些Keras代码试着构建一个最终架构😉。
最终结果
通过这样的架构,我们的初始架构在多个方面得以改进:

模型训练速度加快10倍,因为:(a),可将参数总数减半;(b),不需要再奢侈地使用1百万长度的中间向量。由于可以注入有关已拿取的前序商品,以及随后需要拿取的商品的走道和部门元数据,预测的准确度也提高了10%。
最后,为了给一个包含20件商品的订单生成完整的预测顺序(需要调用predict20次),我们的预测工作所需的时间延长了大约一倍,由大约50ms增加至100ms。但这是可接受的,考虑到具体的生产需求,其实并不需要对清单进行实时排序。
尽管预测速度慢了一些,但面对训练时间和精确度方面的改进,我们依然感到十分激动!

过去四个月来,该项目进展和迭代速度飞快。有好几次我们带着一台运行该模型早期版本的Jupyter笔记本,把它放在购物车上逛Whole Foods超市,借此对所生成的结果进行测试。旁人对此完全无动于衷,毕竟我们是在湾区!
目前我们正在测试能否针对每位购物顾问对清单进行个性化定制,以便让每位顾问能够达到比速度最快顾问更好的成绩。后续我们还计划使用LSTM嵌入产品描述,并使用CNN嵌入产品图片,借此提高低销量产品的预测效果。此外我们还计划测试使用LSTM对整个取货顺序进行建模。
在这里要对专注于改进购物应用清单排序工作的核心团队致以谢意:

本文在大家的反馈下质量有了大幅提高。在这里要特别感谢Greg Brockman、Ilya Sutskever,以及来自OpenAI的Andrej Karpathy和来自Y Combinator的Daniel Gross提供的宝贵意见!
谢谢Max Mullen。
作者:Jeremy Stanley,阅读英文原文:Deep Learning with Emojis (not Math)
