@liuhui0803
2018-03-15T01:30:47.000000Z
字数 3902
阅读 4687
如何通过深度学习技术使用Python实现iPhone X的面容ID
机器学习 深度学习 人工智能 数据科学
摘要:
本文探讨了面容ID功能是如何在设备本地,仅通过少量训练就能实现极高识别率的,并介绍了基于面容嵌入和连体卷积网络,使用Python代码实现类似机制的方法。
正文:
对iPhone X的全新解锁机制进行逆向工程。

围绕新款iPhone X最热议的话题之一就是用于取代触控ID的全新解锁机制:面容ID。
为了顺利打造出无边框的全面屏手机,Apple必须开发一种能快速简单地解锁手机的全新方法。虽然很多竞品依然在全面屏手机上使用指纹传感器,但必须将传感器放置在其他位置,而Apple决定通过创新为手机开发一种革命性的全新解锁方式:注视一眼就够了。借助先进(并且体积非常小巧)的前置原深感摄像头,iPhone X可以为用户的面孔创建3D面谱,此外还会使用红外镜头捕获用户面孔照片,这样便可更好地适应环境光线与色彩的变化。借助深度学习技术,这款手机可以学习用户面容的细节变化,确保用户每次拿起自己的手机后都能快速解锁。令人惊讶的是,Apple宣称这种方法甚至比触控ID更安全,错误率可低至1:1,000,000。
我对Apple实现面容ID所用的技术很好奇,尤其是考虑到这个功能完全是在设备本地实现的,只需要通过用户面容进行少量训练,就可以在用户每次拿起手机后非常流畅自然地完成识别。于是我研究了如何使用深度学习技术实现这一过程,并对每个步骤进行优化。本文我将介绍如何使用Keras实现类似于面容ID的算法。我会介绍在选择最终架构时的考虑因素,以及通过Kinect这一流行的RGB和景深摄像头(能获得与iPhone X的前置摄像头非常类似的输出结果,但体积略大)进行实验的过程。找个舒适的姿势坐下来,端起茶杯,开始进行Apple创新功能的逆向工程吧。
理解面容ID
“…驱动面容ID的神经网络并不仅仅是执行分类操作那么简单。”
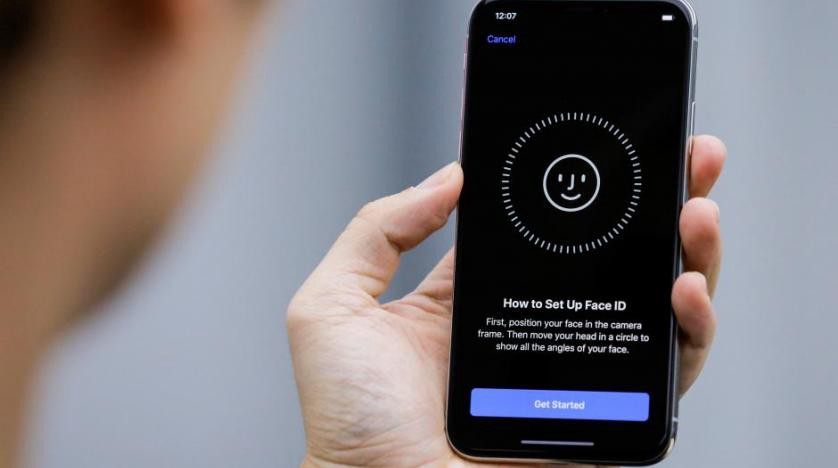
面容ID的配置过程
首先需要细致分析一下iPhone X中面容ID的工作原理。Apple提供的白皮书可以帮助我们理解有关面容ID的基础机制。在使用触控ID时,用户首先要触碰传感器多次,以注册自己的指纹。在进行过大约15–20次触碰后,即可完成注册过程,随后就可以使用了。类似的,使用面容ID时,用户也要注册自己的面孔信息。整个过程非常简单:按照正常使用时的操作注视自己的手机,随后缓慢旋转头部画圈,通过不同姿态注册自己的面孔即可。就这么简单,随后就可以用自己的面孔解锁手机。这个极为快速的注册过程可以让我们深度了解该技术底层的学习算法。例如,驱动面容ID的神经网络并不仅仅是执行分类操作那么简单,下文会介绍具体原因。

Apple Keynote演示文稿中展示的iPhone X和面容ID
对于神经网络来说,执行分类操作意味着需要学着预测自己看到的面孔是否就是用户本人的面孔。因此基本上,神经网络需要通过一些训练数据来预测“真”或“假”,但是与很多其他深度学习用例不同的地方在于,此时使用这种方法是不可行的。首先,网络需要通过从用户面孔新获得的数据,从头开始重新进行训练,这将需要花费大量时间并消耗大量电力,而不同面孔会产生数量多到不切实际的训练数据,这也会产生消极的影响(就算使用迁移学习或对已训练网络进一步优化,效果也不会有太大改善)。此外,这种方法将无法让Apple以“脱机”方式训练更复杂的网络,例如在实验室中训练网络,然后将训练好的网络包含在产品中交付给用户使用。因此我认为,面容ID是由一种连体(Siamese-like)卷积神经网络驱动的,该网络由Apple“脱机”训练而来,可将面孔映射为低维隐空间(Low-dimensional latent space),并通过形状调整,使用对比损失(Contrastive loss)的方式获得不同用户面孔间的最大距离。借此打造的架构只需要通过一张照片即可学习,这一点在发布会的演讲上也有提到。我知道,这其中涉及的某些技术可能对很多读者而言还显得挺陌生,下文将循序渐进地进行介绍。

面容ID似乎会成为继触控ID之后的新标准,Apple是否会让以后的所有设备都支持它?
使用神经网络实现从面容到数据的转换
简单地说,连体神经网络实际上由两个完全相同的神经网络组成,这两个网络会共享所有权重。这种架构可以学着计算特定类型的数据,例如图片间的距离。而其主要目的在于,向连体网络传递一对数据(或向同一个网络传递处于两个不同阶段的数据),网络会将其映射至一个低维特征空间,例如n维阵列,随后训练网络实现所需映射关系,让来自不同类的数据点能够尽可能远离,同时让来自同一个类的数据点能够尽可能接近。通过长时间运行,网络即可学习从数据中提取最有意义的特征,并用这些特征产生阵列,创建出有意义的映射。为了更直观地理解这一过程,可以假设你自己使用小向量描述狗的种类的方法,越是类似的狗,它们就会有越接近的向量。你可能会使用某个数字代表狗毛颜色,用另一个数字代表狗的大小,并用其他数字代表狗毛长度,以此类推。通过这种方式,相似的狗将获得相似的向量。很聪明对吧!而连体神经网络可以通过学习帮助我们做到这一点,这也有些类似autoencoder的功能。
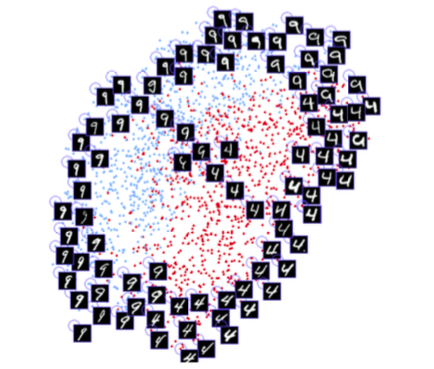
Hadsell、Chopra和LeCun撰写的论文《Dimensionality Reduction by Learning an Invariant Mapping》中提供的插图。请留意该架构学习不同数字之间相似性,并将其自动分组为两个维度的方法。类似的方法也可以用于处理面容信息。
通过这种技术,我们可以使用大量面容照片训练类似的架构来识别哪些面孔是相似的。只要(像Apple那样)有足够的预算和运算能力,任何人都可以使用难度越来越大的样本改善网络的健壮性,成功应对双胞胎、对抗性攻击(面具)等场景。使用这种方式的最终优势是什么?我们终于可以通过一个即插即用模型直接识别不同用户,而无需任何进一步的训练,只要在初始配置时拍摄一些照片,随后计算用户的面孔与面孔的隐映射(Latent map)之间的距离就行了。(按照上文所述,这个过程可以类比为:对新出现的狗记录下品种的相关向量,随后将其存储在某个地方。)此外面容ID还可以适应用户面容的变化,例如突发的变化(眼镜、帽子、化妆等)以及缓慢的变化(面部毛发)。这实际上是通过在映射中添加基于新外貌计算出的参考性质的面容向量实现的。

面容ID可以适应用户外表的变化
最后,让我们一起来看看如何使用Python在Keras中实现这一切。
在Keras中实现面容ID
对于所有机器学习项目,首先我们需要有数据。自行创建数据集需要花费大量时间,还需要很多人配合,这可能不太好实现。因此我在网上搜索现成的RGB-D面容数据集,并且还真找到了一个非常适合的。其中包含一系列RGB-D形式的人脸图片,图片采用不同角度和表情拍摄,完全符合iPhone X的实际用例。
为了直接看到最终效果,可以访问我的GitHub代码库,我在这里提供了一个Jupyter Notebook。此外我还试验过使用Colab Notebook,你自己也可以试试。
随后我创建了一个基于SqueezeNet架构的卷积网络。该网络可以接受RGBD格式的四通道人脸图片作为输入,并输出两个图片之间的距离。该网络使用对比损失的方式训练,借此在同一个人的不同照片之间获得最小距离,并在不同人的照片之间获得最大距离。
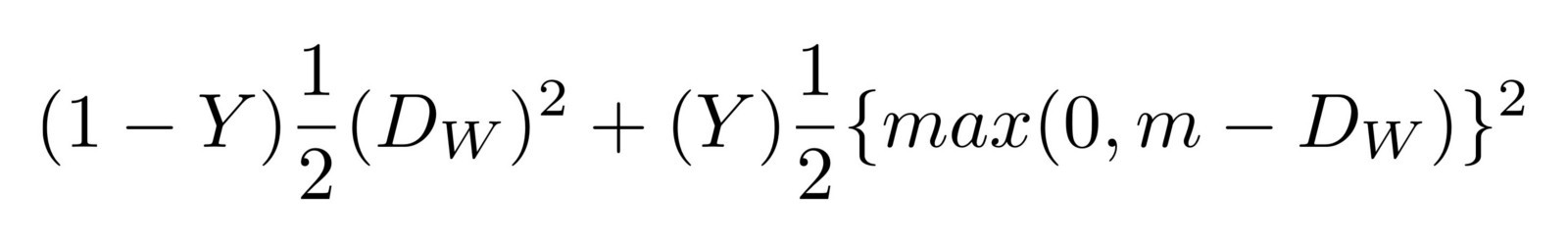
对比损失
训练之后,该网络可将面容映射为128维度的阵列,同一个人的不同照片可分组在一起,并会拉开不同人的照片之间的距离。这意味着如果要解锁你的设备,网络只需要计算解锁时所拍摄的照片以及注册阶段所存储的照片间的距离即可。如果距离低于某个阈值(阈值越小,安全性越高),设备即可顺利解锁。
我使用t-SNE算法对128维度的嵌入空间进行二维可视化,并用每个颜色对应一个人员。如你所见,网络已经可以学着将图片进行尽可能紧密的分组。(使用t-SNE算法时,聚类间的距离已不再重要)。在使用PCA降维算法时还出现了一种有趣的分布。
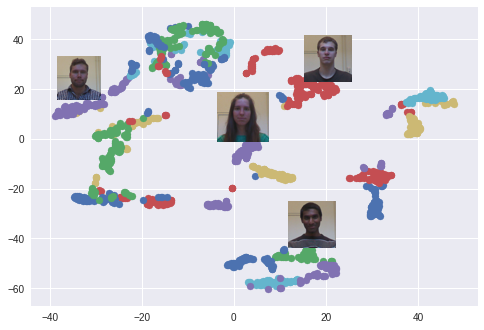
使用t-SNE在嵌入空间中创建的面容聚类。每个颜色代表一个不同的人脸(不过颜色有重复使用)
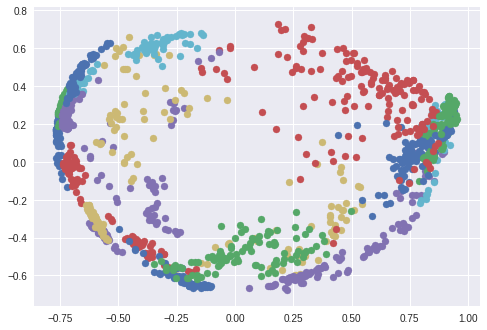
使用PCA在嵌入空间中创建的面容聚类。每个颜色代表一个不同的人脸(不过颜色有重复使用)
开始实验!
接着可以试试这个模型的效果了,我们将模拟面容ID的操作过程:首先注册用户面容,随后分别使用用户本人(应该能成功)以及他人的面容(应该会失败)试着解锁。正如上文所述,两种情况的差异在于,网络对解锁时以及注册时拍摄的面容计算出的距离,以及这个距离到底是低于还是高于某个阈值。
首先注册:从数据集中挑选同一个人的不同照片,然后模拟注册过程。随后设备会开始计算不同姿势的嵌入,并将其存储在本地。

模拟面容ID的新用户注册环节

景深摄像头在注册阶段看到的内容
接着看看用户本人解锁设备时会发生什么。同一个人的不同姿势和面部表情产生的距离很小,平均仅为大约0.30。

同一用户在嵌入空间中的面容距离。
然而不同用户的RGBD照片的平均距离高达1.1。

不同用户在嵌入空间中的面容距离。
因此将阈值设置为0.4左右就足以防止陌生人解锁你的设备。
结论
本文介绍了基于面容嵌入和连体卷积网络,从概念证实的角度实现面容ID解锁机制的方法。希望本文对你有所帮助。本文涉及到的Python代码可在这里获取。
作者:Norman Di Palo,阅读英文原文:How I implemented iPhone X’s FaceID using Deep Learning in Python.
