@liuhui0803
2017-06-14T03:11:31.000000Z
字数 3637
阅读 2710
Dropbox推出实时异步处理框架:Cape
async Cape sfj Dropbox edgeStore
摘要:
Cape是一种实时异步处理框架,每天可处理数十亿条事件,Dropbox的很多功能都用到了这项技术。本文概括介绍了Cape的特点与架构。
正文:
每天,Dropbox需要存储数十亿个文件,为了响应这些操作并实现Dropbox所提供的各类功能,我们需要运行大量异步作业。例如需要通过异步作业为文件创建索引,借此提供内容搜索功能,为文件生成预览并显示在Dropbox展示这些文件的网页上,以及在文件有改动时为使用Dropbox开发者API的第三方应用发出通知。这些地方都可以用到Cape。Cape是一种实时异步处理框架,每天可处理数十亿条事件,Dropbox的很多功能都用到了这项技术。
我们最初于2016年底发布Cape,并用它取代了早在2014年就在使用的Livefill。本文将概括介绍Cape的主要功能,高层架构,以及Dropbox内部的不同用例。
需求
按照设计,Cape是一种通用框架,可用于处理不同来源的事件流,开发者可执行自定义业务逻辑对这些事件做出响应。因此这个框架需要满足很多前提需求:
低延迟
为了驱动用户通过移动设备,实时并且不断进行的内容协作和共享,Cape必须能在不到一秒的延迟内完成处理任务。例如,我们希望用户能够在上传了文件之后,立刻能够搜索或查看所上传的文件,并能立刻分享给他人。
支持多种事件类型
与原本使用的Livefill类似,Cape需要足够通用,能够处理不同类型的事件,而不仅仅是Dropbox文件事件本身。这样Dropbox产品才能实时响应与文件元数据改动无关的事件,例如文件分享、共享文件夹权限改动,或针对文件添加的备注。随着Dropbox逐渐从一个单纯的文件同步解决方案转变成一种协作平台,这样的功能会变得越来越重要。
规模
Cape的吞吐率必须足够高,以支持每秒上万个与文件有关和无关的事件。另外,同一个事件可能会触发很多不同类型的工作负载,这也进一步放大了我们所要支持的规模。
多变的工作负载
从数毫秒到数十秒,甚至某些情况下数分钟,取决于工作负载的类型以及所处理的事件,不同时段的工作负载可能有所差异。
隔离
Cape必须能在不同Cape用户的事件处理代码中实现合理程度的隔离,这样一个用户处理过程中出现的问题才不会对其他所有使用该框架的用户产生太大的不利影响。
“至少一次”的保证
Cape必须能够确保每个事件至少被处理一次,对很多用例来说,这是确保整个体验准确一致的关键。
数据模型
Cape中的每个事件流可称为一个域(Domain),其中会包含某一特定类型的事件。每个Cape事件都有一个自己的主题(Subject)和一个序列号(Sequence ID)。主题是指发生该事件的主体,对应的主题ID则可用于区分不同主题。序列号是一种单调递增(Monotonically increasing)的编号,可为某一主题范围内的多个事件提供严格的顺序保证。
第一版Cape支持两个事件源,这两个事件源承担了Dropbox很多非常重要的用户事件。继续介绍前,我们会首先简要介绍一下这些事件源。
第一个事件源是SFJ(Server File Journal,服务器文件日志),这是Dropbox中文件的元数据数据库。对用户的Dropbox中存储的每个文件所做的每个改动都会被关联一个名称空间ID (NSID)和一个日志ID (JID),这两个ID结合在一起即可用于标识SFJ中的每个事件。可支持的第二个事件源是Edgestore,这是一种面向非文件元数据的元数据存储,Dropbox的很多服务和产品都用到了该事件源。针对特定Edgestore实体(Entity)或关联(Association)类型进行的所有改动都可通过配合使用GID(全局ID)和Revision ID(修订ID)的方式进行唯一区分。
下表介绍了SFJ和Edgestore事件融入Cape事件抽象的具体方法:
| 源 | 域 | 主题ID | 序列号 |
|---|---|---|---|
| SFJ | SFJ(所有SFJ事件) | 名称空间ID | 日志ID |
| Edgestore | 实体或关联类型 | GID | 修订ID |
以后,Cape除了支持SFJ和Edgestore事件,还将支持处理自定义事件流。例如流入Kafka集群的事件可以按照下列方式融入Cape的事件流抽象:
| 源 | 域 | 主题ID | 序列号 |
|---|---|---|---|
| Kafka | 一个Kafka集群 | {Topic, Partition} | 偏移量 |
架构
下图概括展示了Cape的架构:
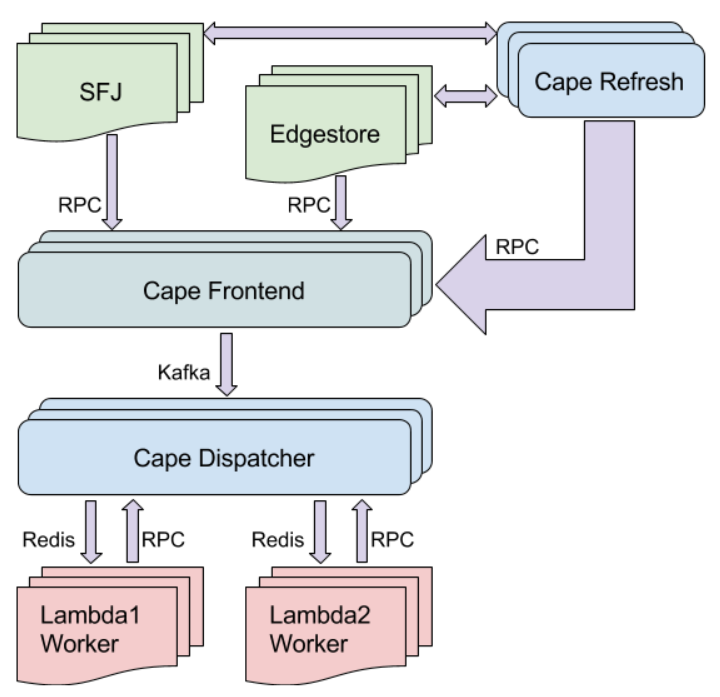
Cape系统架构
SFJ和Edgestore服务在事件发生时,通过RPC向Cape前端发送包含相关事件元数据的Ping。这些Ping并不位于关键的SFJ和Edgestore路径上,因此可以异步发送。这样的设计可将对重要Dropbox服务整体可用性的影响降至最低(当Cape或所依赖的服务遇到问题时),同时依然可以在常规情况下实现实时事件处理。Cape前端会将这些Ping发布至Kafka队列,并在队列中持久保存,直到处理完成。
上文提到的Kafka队列的Cape调度器(Dispatcher)订户会收到事件Ping,并开始进行必要的处理。调度器中包含了Cape的所有智能业务逻辑,会根据用户的Cape配置,酌情调度事件至相应的Lambda工作进程(Worker)。此外调度器还会为Cape的其他保证提供支撑,例如不同事件的顺序,以及Lambda之间的依赖性。
Lambda工作进程通过Redis收到来自调度器的事件,执行用户的业务逻辑,并使用处理状态作为对Cape调度器的响应:如果成功处理完成,该事件的处理过程就算告一段落。
正如上文所述,来自SFJ和Edgestore的Ping会以异步的方式发送,并会独立于Cape前端的关键路径之外,当然这就意味着无法确保每个事件都能发送。你可能发现,这似乎会导致Cape无法保证每个事件至少被处理一次。例如可能一个文件已经同步至Dropbox,但我们可能错过了随后需要进行的所有异步处理。因此我们设计了Cape Refresh,这些工作进程会持续扫描SFJ和Edgestore元数据中可能错过的最新事件,并将必要的Ping发送至Cape前端,借此确保所有事件都被处理。此外这也为我们提供了一种机制,使得我们可从Cape所处理的数十亿个主题中检测到用户应用程序代码中可能存在的永久性失败。
Cape的使用
为了实现与Cape的集成,开发者需要执行下列操作:
- Lambda:编写执行后可对事件做出响应的代码,借此实现一个妥善定义的接口(目前支持使用Python或Go),这也叫做Lambda。
- 部署:使用Dropbox的标准部署和监视工具部署Cape工作进程,借此接受事件并运行新创建的Lambda。
- 配置:通过指定域,将需要处理的事件集包含在Cape的配置中,随后即可运行Lambda对其做出响应。
上述操作完成后,新部署的Cape工作进程即可收到与相关Lambda有关的事件,并酌情处理这些事件,随后使用处理状态响应Cape调度器。用户还可以访问一个自动生成的监视仪表盘,其中显示了特定Lambda所执行事件处理工作的相关基本指标。
总结
Cape目前每天已经可以处理数十亿条事件,对于SFJ和Edgestore,95%的情况下延迟分别低于100毫秒和400毫秒。该延迟是通过衡量从Cape前端收到事件,到Lambda工作进程开始处理该事件这一过程之间的时间确定的。对于SFJ,端到端延迟(例如从变更提交至SFJ再到Lambda工作进程开始处理)更高一些,分别为大约500毫秒和1秒,这是由于SFJ服务自身的批处理造成的。
目前Cape已经在Dropbox内部获得了广泛应用,下文将列举一二:
- 审计日志:Cape可用于对Dropbox与审计日志有关的事件进行实时索引,这样Dropbox Business的管理员就可以随时搜索这些日志。
- 搜索:在Dropbox中存储的文件有改动时,Cape可进行实时索引,方便用户搜索文件的内容。
- 开发者API:Cape可为使用Dropbox开发者API的第三方应用提供有关文件改动的实时通知。
- 共享权限:Cape可用于以异步方式执行开销巨大的操作,例如针对包含大量内容或具备较深结构的共享文件夹应用更改后的权限。
鉴于该框架的通用性极强,并且Dropbox的大部分重要事件都可使用,我们预计未来Cape还将用来巩固Dropbox的其他各种功能。
本文对Cape的架构进行了概括的介绍,但并未涉及太多细节和设计方面的决策。稍后我们还将发布更多文章,深入探讨Cape的技术细节和与Cape的架构、设计,以及实现有关的内容。
感谢为Cape的诞生做出奉献的人们:Bashar Al-Rawi、Daisy Zhou、Iulia Tamas、Jacob Reiff、Peng Kang、Rajiv Desai,以及Sarah Tappon。
作者:Neeraj Kumar,阅读英文原文:Introducing Cape
