@liuhui0803
2017-05-13T08:45:48.000000Z
字数 3561
阅读 5876
MXNet API入门 —第5篇
机器学习 深度学习 神经网络 MXNet AWS
摘要:
Apache MXNet是一种功能全面、可以灵活编程并且扩展能力超强的深度学习框架,支持包括卷积神经网络(CNN)与长短期记忆网络(LSTM)在内的顶尖深度模型。这一系列文章介绍了MXNet的基本概念和使用方法。本篇主要介绍不同模型的对比结果。
正文:
在第4篇中,我们介绍了如何轻松地使用预训练版Inception v3模型进行物体识别。本文将使用另外两个著名的卷积神经网络(CNN)模型(VGG19和ResNet-152),并将其与Inception v3的效果进行对比。
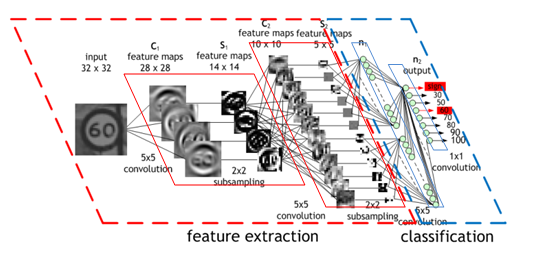
CNN的架构(来源:Nvidia)
VGG16
诞生于2014年的VGG16是一种16层模型(研究论文),该模型以低至7.4%的物体识别错误率赢得了2014年度ImageNet挑战赛。
ResNet-152
诞生于2015年的ResNet-152是一种152层模型(研究论文),在物体识别方面,该模型以破纪录的3.57%错误率赢得了2015年度ImageNet挑战赛。这一准确率甚至超过了普通的人工识别,人工识别的错误率通常为5%左右。
下载模型
首先再次访问Model zoo。与Inception v3类似,我们需要下载模型的定义和参数。这三个模型都针对相同的分类进行了训练,因此可以继续使用之前的synset.txt文件。
$ wget http://data.dmlc.ml/models/imagenet/vgg/vgg16-symbol.json$ wget http://data.dmlc.ml/models/imagenet/vgg/vgg16-0000.params$ wget http://data.dmlc.ml/models/imagenet/resnet/152-layers/resnet-152-symbol.json$ wget http://data.dmlc.ml/models/imagenet/resnet/152-layers/resnet-152-0000.params
加载模型
这三个模型都使用ImageNet数据集进行过训练,该数据集中图片通常为224x224像素大小。由于数据形态和分类完全相同,因此也可以继续重用之前的代码。
这次只需要更改模型的名称 :) 我们可以为loadModel()和init()函数添加一个参数。
def loadModel(modelname):sym, arg_params, aux_params = mx.model.load_checkpoint(modelname, 0)mod = mx.mod.Module(symbol=sym)mod.bind(for_training=False, data_shapes=[('data', (1,3,224,224))])mod.set_params(arg_params, aux_params)return moddef init(modelname):model = loadModel(modelname)cats = loadCategories()return model, cats
预测结果对比
我们可以通过同一批图片对三个模型的结果进行对比。

*** VGG16[(0.58786136, 'n03272010 electric guitar'), (0.29260877, 'n04296562 stage'), (0.013744719, 'n04487394 trombone'), (0.013494448, 'n04141076 sax, saxophone'), (0.00988709, 'n02231487 walking stick, walkingstick, stick insect')]
可能性最高的两个分类判断结果让人满意,但后续三个结果错得离谱。似乎竖立放置的麦克风支架干扰了模型的识别。
*** ResNet-152[(0.91063803, 'n04296562 stage'), (0.039011702, 'n03272010 electric guitar'), (0.031426914, 'n03759954 microphone, mike'), (0.011822623, 'n04286575 spotlight, spot'), (0.0020199812, 'n02676566 acoustic guitar')]
排名第一的预测非常准确,但接下来的四个预测风马牛不相及。
*** Inception v3[(0.58039135, 'n03272010 electric guitar'), (0.27168664, 'n04296562 stage'), (0.090769522, 'n04456115 torch'), (0.023762707, 'n04286575 spotlight, spot'), (0.0081428187, 'n03250847 drumstick')]
前两个分类的结果与VGG16极为类似,另外三个结果良莠不齐。
再换张图片试试看。

*** VGG16[(0.96909302, 'n04536866 violin, fiddle'), (0.026661994, 'n02992211 cello, violoncello'), (0.0017284016, 'n02879718 bow'), (0.00056815811, 'n04517823 vacuum, vacuum cleaner'), (0.00024804732, 'n04090263 rifle')]*** ResNet-152[(0.96826887, 'n04536866 violin, fiddle'), (0.028052919, 'n02992211 cello, violoncello'), (0.0008367821, 'n02676566 acoustic guitar'), (0.00070532493, 'n02787622 banjo'), (0.00039021231, 'n02879718 bow')]*** Inception v3[(0.82023674, 'n04536866 violin, fiddle'), (0.15483995, 'n02992211 cello, violoncello'), (0.0044540241, 'n02676566 acoustic guitar'), (0.0020963412, 'n02879718 bow'), (0.0015099624, 'n03447721 gong, tam-tam')]
三个模型排名第一的预测分数都很高。不过也可以理解,毕竟小提琴的外形在神经网络看来还是很有特点的。
很明显,单凭少数例子还不能得出准确的结论。如果要挑选预训练模型,那么绝对要先准备好训练数据集,使用自己的数据进行测试并酌情决定!
技术指标对比
不同模型的详细评测结果可参阅现有研究论文,例如这一篇。对开发者来说,也许更需要考虑另外两个重要因素:
- 模型需要多少内存?
- 模型的预测能有多快?
为了回答第一个问题,可以通过参数文件的大小进行一个粗略的猜测:
- VGG16:528MB(约1.4亿个参数)
- ResNet-152:230MB(约6000万个参数)
- Inception v3:43MB(约2500万个参数)
可见,目前的趋势是使用参数较少的更深度的网络。这样做有两方面收益:训练速度更快(因为网络需要学习的参数更少),并且可以降低内存使用*。
第二个问题更复杂一些,并且取决于很多因素,例如批大小。所以我们对预测调用进行计时然后再次运行看看。
t1 = time.time()model.forward(Batch([array]))t2 = time.time()t = 1000*(t2-t1)print("Predicted in %2.2f microseconds" % t)
结果就是这样(结果对多次调用取平均值获得)。
*** VGG160.30微秒完成预测*** ResNet-1520.90微秒完成预测*** Inception v30.40微秒完成预测
总结来说(请自行套用标准免责声明):
- 所有三个网络中(目前)ResNet-152准确率最高,但速度也慢了2–3倍。
- VGG16速度最快(莫非因为层数少?)但内存用量最高并且准确率最差。
- Inception v3几乎最快,同时在准确率和内存使用方面较为平均。这也使得该模型成为某些条件受限的环境中最佳的选择。最后一篇文章中,还将进一步讨论这个问题 :)。
代码已发布至GitHub:mxnet_example3.py, 请自行尝试。
后续内容:
- 第6篇:通过树莓派进行实时物体检测(并让它讲话!)
作者:Julien Simon,阅读英文原文:An introduction to the MXNet API — part 5
