@liuhui0803
2016-11-02T08:30:46.000000Z
字数 6253
阅读 4949
优步工程团队对容器化MySQL的应用
架构 Docker MySQL 容器 GTID
摘要:
优步工程团队的Schemaless存储系统驱动着优步内部一些最大规模的服务,例如Mezzanine。Schemaless是一种基于MySQL集群的可缩放、高可用数据存储。当我们最初只有16个集群时,这些集群的管理工作相当简单,但是目前我们有超过1000个集群,其中承载了超过4000个数据库服务器,我们的管理工具也需要与时俱进了。
正文:
优步工程团队的Schemaless存储系统驱动着优步内部一些最大规模的服务,例如Mezzanine。Schemaless是一种基于MySQL[1]集群的可缩放、高可用数据存储。当我们最初只有16个集群时,这些集群的管理工作相当简单,但是目前我们有超过1000个集群,其中承载了超过4000个数据库服务器,我们的管理工具也需要与时俱进了。
最初所有集群都通过Puppet管理,我们根据需要陆续编写了大量脚本,但这种手工的操作方式已经无法跟上优步快速扩张的节奏。在为数量逐渐增加的MySQL集群选择更适合的管理方式时,我们也确立了一些基本需求:
- 在每台宿主机上运行多个数据库进程
- 一切操作实现自动化
- 跨越多个数据中心,通过一个位置管理并监控所有集群
我们设计了一种名为Schemadock的解决方案。所有MySQL均运行在Docker容器内,我们通过在配置文件中定义的集群拓扑为目标状态(Goal state)对其进行管理。集群拓扑决定了MySQL集群的组成方式,例如集群A应包含3个数据库,其中某个数据库为主数据库。随后通过代理(Agent)将定义好的拓扑应用给每个数据库。我们会通过一个集中化的服务维持并监视每个实例的目标状态,并对偏差做出响应。
Schemadock包含多个组件,其中的Docker虽小但很重要。换为使用缩放性更强的解决方案,这样的过程需要付出诸多努力,本文将介绍我们如何借助Docker实现这个目标。
为何一开始就选择使用Docker?
以容器化的方式运行进程,使得我们可以轻松地用一台宿主机同时运行多个不同版本和配置的MySQL进程。此外我们也可以将多个小规模群集共置在一台宿主机上,这样即可在确保集群数量不变的情况下减少宿主机数量。最终,我们可以消除对Puppet的依赖,将所有宿主机以相同的角色进行供应。
对于Docker本身,我们的工程师已经开始全面采用Docker构建无状态(Stateless)服务。这意味着我们针对Docker积累了大量工具和知识。Docker虽不完美,但至少目前比其他备选技术更优秀。
为何不使用Docker?
可以取代Docker的技术包括完整虚拟化技术、LXC容器,以及通过Puppet等工具管理宿主机上直接运行的MySQL进程。对我们来说,选择Docker是一种很自然的做法,因为该技术可以融入我们现有的基础架构。然而如果你目前尚未开始使用Docker,单纯为了MySQL就上马Docker这样的做法有些得不偿失:需要处理镜像的构建和分发,监控,Docker的升级,日志收集,网络等一系列繁琐工作。
这一切也意味着,只有在愿意投入不菲的资源前提下,Docker对你来说才是可行的。此外你应该将Docker视作一种技术,而非应对所有问题的终极解决方案。优步通过大量慎重的规划设计才使得Docker能够成为MySQL数据库管理这一庞大系统中的一个小组件,然而并非所有公司能有优步这样的规模,对这些公司来说,也许更简单直接的Puppet或Ansible等方式是最适合的做法。
Schemaless MySQL Docker镜像
作为其他所有内容的基础,我们的Docker镜像会下载并安装Percona Server,然后启动mysqld—这一过程与现有的Docker MySQL镜像相差无几。然而在下载和启动过程之间我们的镜像会执行很多其他操作:
- 如果挂载的卷中不包含数据,则可以确定这是一个自举(Bootstrap)场景。对于主数据库(Master),将运行
mysql_install_db并创建一些默认用户和表。对于从属数据库(Minion),将会通过备份或集群中的其他节点发起数据同步操作。 - 容器包含数据后,将会启动mysqld。
- 如果数据复制过程失败,容器将重新关闭。
容器的角色可通过环境变量来配置。这里比较有趣的地方在于,角色仅控制了初始数据的获取方式,Docker镜像本身不包含用于设置复制拓扑或执行状态检查等操作的任何逻辑。由于逻辑的变化可以比MySQL自身的变化更频繁,因此将两者区分开来是一种合理的做法。
MySQL数据目录将从宿主机的文件系统直接挂载,这意味着Docker不会产生写操作的负担。不过我们会将MySQL的配置直接放入镜像中,使其成为常量。虽然可以更改配置,但由于Docker容器绝对不会重新使用,因此配置的改动也绝对不会生效。如果因为某些原因必须关闭一个容器,我们不会将这样的容器重新启动。我们会删除容器,使用最新镜像通过相同参数(如果目标状态有变化则使用新参数)重建一个容器,然后重新启动实例。
这样的做法为我们提供了多个收益:
- 更易于控制配置漂移。有变化的最多只是Docker镜像的版本,并且我们会密切监视版本变化。
- MySQL的升级过程更简单。我们会新建一个镜像,随后按顺序关闭老的容器。
- 如果任何地方出错,只须重头再来。不再需要考虑该如何打补丁,抛弃原有的一切新建所需容器即可。
镜像的构建工作也是通过驱动无状态服务的同一个优步基础架构完成的。该基础架构会将镜像复制到所有数据中心,使其可在每个数据中心的本地注册表(Registry)中使用。
用一台宿主机运行多个容器也有相应的劣势。由于容器间无法进行恰当的I/O隔离,一个容器可能占用掉所有可用的I/O带宽,导致其他容器开始卡顿。Docker 1.10引入了I/O配额功能,但我们尚未对该功能进行过测试。目前我们主要通过避免超额订阅(Oversubscribing)宿主机,以及对每个数据库进行持续监控等方式降低这一问题的影响。
Docker容器的调度和拓扑的配置
在具备了可作为主数据库(Master)或从属数据库(Minion)配置并启动的Docker镜像后,需要通过某种方式启动这些容器并配置恰当的复制拓扑。为此我们在每台数据库宿主机上运行了一个代理(Agent)。该代理可以获取每台宿主机上应该具备的所有数据库的目标状态信息。一个典型的目标状态是类似这样的:
“schemadock01-mezzanine-mezzanine-us1-cluster8-db4”: {“app_id”: “mezzanine-mezzanine-us1-cluster8-db4”,“state”: “started”,“data”: {“semi_sync_repl_enabled”: false,“name”: “mezzanine-us1-cluster8-db4”,“master_host”: “schemadock30”,“master_port”: 7335,“disabled”: false,“role”: “minion”,“port”: 7335,“size”: “all”}}
从这些信息中可以看出,宿主机schemadock01上通过7335端口运行了一个Mezzanine从属数据库,该数据库的主数据库位于schemadock30:7335。这个数据库的尺寸为“all”,意味着这是该宿主机上运行的唯一数据库,因此可以获得全部的可分配内存。
如何确定这样的目标状态,这是另一个完全不同的话题,随后我们还将撰文介绍,此处暂且不表,继续介绍下一个步骤:宿主机上运行的代理会接收这些信息,将其存储在本地,然后开始进行必要的处理。
这个处理过程实际上是一种无穷无尽的环路,每30秒进行一次,这有些类似于每30秒运行一次Puppet。该处理环路会通过下列操作检查目标状态与系统的实际状态是否匹配:
- 检查是否有一个容器已经在运行。如果没有,则使用配置创建一个并将其启动。
- 检查该容器是否应用了正确的复制拓扑。如果不正确,则尽量修复。
- 如果本应是主数据库但实际为从属数据库,首先确认能否安全地更改其角色。为此我们会检查原本的主数据库是否为只读的,并且所有GTID均已收到并应用。一旦符合要求,即可安全地删除到原本主数据库的链接并启用写入。
- 如果是主数据库但本应禁用,则开启只读模式。
- 如果是从属数据库但复制未运行,则设置复制链接。
- 根据具体角色检查各种MySQL参数(
read_only、super_read_only、sync_binlog等)。主数据库应当是可写的,从属数据库应当是只读的。此外我们会关闭binlog fsync以及其他类似参数[2]以降低从属数据库的负载。 - 启动或关闭任何其他用于提供支持的容器,例如pt-heartbeat和pt-deadlock-logger。
这里需要注意,我们会尽可能采用单进程、单用途容器这种做法。这样就无需重新配置运行中的容器,并且升级的过程也更易于控制。
如果任何一点出现错误,执行过程将抛出错误信息并将其忽略。整个过程会在下次运行时重试。我们会尽可能确保不同代理之间只需要最少量的协调。这意味着我们并不关心具体顺序,例如供应新集群时的供应顺序。如果用手工的方式供应新集群,可能需要执行类似下面的操作:
- 创建MySQL主数据库并等待其就绪
- 创建第一个从属数据库,并将其连接至主数据库
- 针对其余从属数据库重复该操作
当然,最终获得的效果与上述操作类似,但我们并不需要明确关注操作的执行顺序,只需要根据需求创建能反映最终结果的目标状态即可:
“schemadock01-mezzanine-cluster1-db1”: {“data”: {“disabled”: false,“role”: “master”,“port”: 7335,“size”: “all”}},“schemadock02-mezzanine-cluster1-db2”: {“data”: {“master_host”: “schemadock01”,“master_port”: 7335,“disabled”: false,“role”: “minion”,“port”: 7335,“size”: “all”}},“schemadock03-mezzanine-cluster1-db3”: {“data”: {“master_host”: “schemadock01”,“master_port”: 7335,“disabled”: false,“role”: “minion”,“port”: 7335,“size”: “all”}}
上述信息会以随机的顺序推送给相关代理,随后代理会开始执行操作。为达到目标状态可能需要重试多次,者主要取决于执行顺序。通常可以在几次重试或实现目标状态,但某些操作可能需要重试上百次。举例来说,如果首先处理的是从属数据库,此时将无法连接至主数据库,并只能稍后重试。由于主数据库可能要等一段时间才能启动并正常运行,因此从属数据库可能需要重试多次:
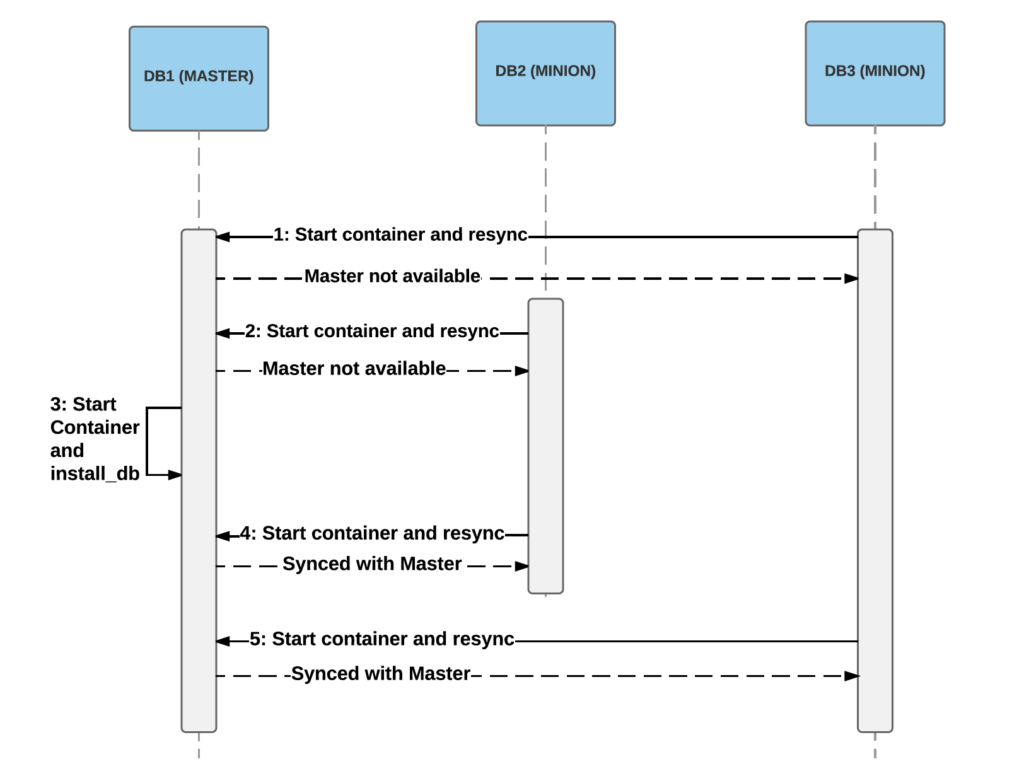
两个从属数据库先于主数据库启动的范例。最初的启动阶段(第1和第2步)中,从属数据库无法从获得主数据库的快照,因此启动过程失败。随后主数据库在第3步中顺利启动,从属数据库即可通过第4和第5步连接并同步数据。
Docker运行时的使用体验
我们的大部分宿主机运行了Docker 1.9.1,并使用LVM中的devicemapper作为存储。我们发现使用LVM中的devicemapper在执行效果方面要比回调(Loopback)的devicemapper更好。devicemapper在性能和可靠性方面有不少问题,但AuFS和OverlayFS等替代品的问题也不少[3]。这意味着整个社区对最佳存储选项方面还有不少的争议。目前OverlayFS的改进最多,似乎已经逐渐变得稳定了,因此我们准备在升级到Docker 1.12.1之后切换为使用OverlayFS。
升级Docker最大的痛苦之一在于需要重启动,并且需要重启动所有容器。这意味着升级过程必须进行必要的控制,确保升级宿主机时没有处于运行状态的主数据库。希望Docker 1.12能成为我们必须关注这个问题的最后一个版本。1.12提供了在不重启动容器的前提下重启动并升级Docker守护进程(Daemon)的选项。
每个新版本在带来大量改进和新功能的同时,也不可避免引入了一些瑕疵和问题。1.12.1看起来比老版本改进了很多,但我们依然面临一些局限:
- Docker成功运行多天后,遭遇
docker inspect时不时挂起的情况。 - 配合Userland代理(Proxy)使用桥接网络会遇到TCP连接终止的怪异问题。无论配置多长的超时值,客户端连接有时候会完全无法收到RST信号并始终保持打开状态。
- 容器进程偶尔会重置(Reparented)至Pid 1(init),这意味着Docker与容器的连接丢失。
- 我们经常看到Docker守护进程新建容器所需的时间变得很长。
总结
优步对存储集群的管理有下列几个需求:
- 同一台宿主机运行多个容器
- 自动化
- 单点管理和访问
现在我们已经可以通过一个界面用简单的工具执行日常维护操作,所有操作均不需要直接访问宿主机:

管理控制台截图。在这里可以追踪目标状态进度,本例中我们首先添加第2个集群,随后断开复制链接,借此将一个集群一分为二。
通过在一台宿主机上运行多个容器,可以更充分地利用宿主机资源,借此即可用受控的方式对整个环境进行升级。Docker的使用让我们可以更快速实现这一切,Docker还使得我们能够在本地测试环境中运行完整的集群配置工作,借此对各种操作过程进行实验。
我们从2016年初开始向Docker迁移,目前共运行了约1500台生产用Docker服务器(仅用于运行MySQL),同时我们已经供应了大约2300个MySQL数据库。
有关Schemadock可说的还有很多,但Docker组件为我们提供了极大的帮助,使得我们可以更快速地演进并尝试各种实验,同时还能很好地融入现有的优步基础架构。我们的整个行程数据库每天会收到数百万条行程信息,现在我们可以将这样的数据库通过Docker化的MySQL与其他数据库环境共置一处。换句话说,Docker已成为向乘客提供服务过程中的一个关键组件。
Joakim Recht是优步工程团队位于阿尔路斯办公室的一名软件工程师,同时也是Schemaless基础架构自动化技术的技术负责人。
作者:JOAKIM RECHT,阅读英文原文:DOCKERIZING MYSQL AT UBER ENGINEERING
[1] 严格来说应为Percona Server 5.6 ↩
[2]
sync_binlog = 0以及innodb_flush_log_at_trx_commit = 2 ↩[3] 部分问题见这里:https://github.com/docker/docker/issues/16653 ,https://github.com/docker/docker/issues/15629 ,https://developerblog.redhat.com/2014/09/30/overview-storage-scalability-docker/ ,https://github.com/docker/docker/issues/12738 ↩
